2016/11/22 現在の Introduction - Apache Kafka を読んだメモ。
Kafka? is a distributed streaming platform. What exactly does that mean?
- ストリーミングプラットフォームとは:
-
- Pub&Sub できるメッセージキュー的な機能をそなえたもの
-
- レコードのストリームを耐障害性のあるやり方で保存できるもの
-
- ストリームのレコードが発生したらそれを処理できるもの
-
- 2 種類のアプリケーションで利用される
-
- システム・アプリ間でデータをやりとりするようなリアルタイムのデータパイプライン
-
- ストリームデータを変形したりそれに反応したりするリアルタイムストリームアプリケーション
-
- Kafka のいくつかのコンセプト
- 1台~複数台のサーバー上のクラスタとして実行される
- クラスタはトピックごとにストリーム・レコードを保存する
- それぞれのレコードはキー、値、タイムスタンプを保持する
- Kafka の 4 つのコア
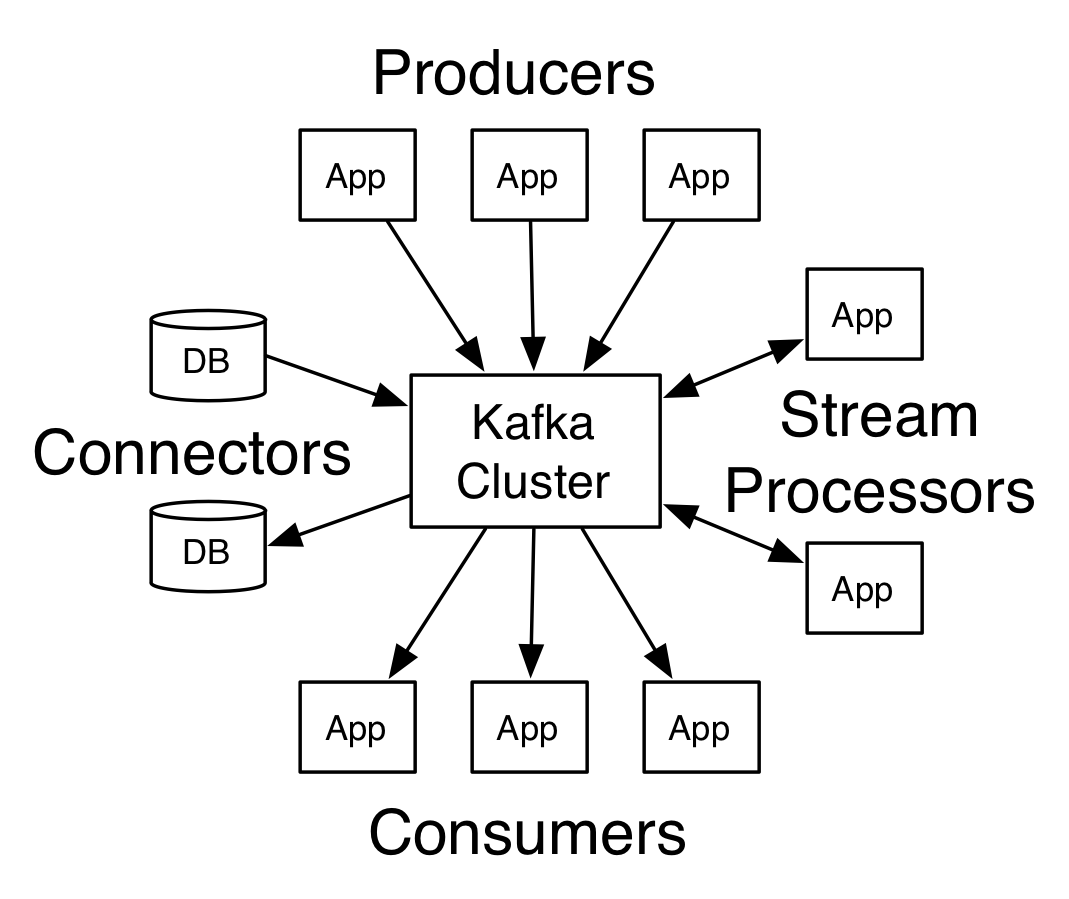
- Producer API: 1~複数の Kafka トピックに対してストリーム・レコードを発行できる
- Consumer API: 1~複数のトピックを購読し、ストリーム・レコードが発行されたらそれを処理できる
- Streams API: ストリーム・プロセッサーを実現できる
- 1~複数のトピックから入力ストリームを consume
- 1~複数のトピックへと出力ストリームを produce
- その過程で入力ストリームを役立つような形で出力ストリームへと変換
- Connector API: トピックと既存のアプリ・システムを接続させるような producer/consumer を実現できる
- RDB のテーブルに対する変更を逐次キャプチャするコネクタ等
Topics and Logs
- トピックはレコードが発行されるカテゴリまたはフィードのようなもの
- トピックはいつでも複数の consumer から購読することができる
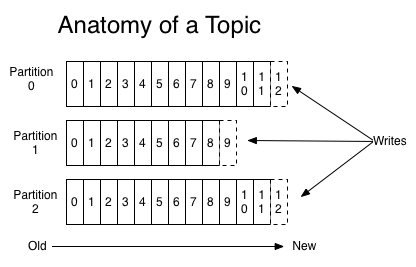
- それぞれのトピックについて Kafka クラスタはパーティション・ログを保持する、こんな感じ
- それぞれのパーティションログは順序があり immutable なレコードの連続であり、絶え間なく「構造化されたコミットログ」へと追記される
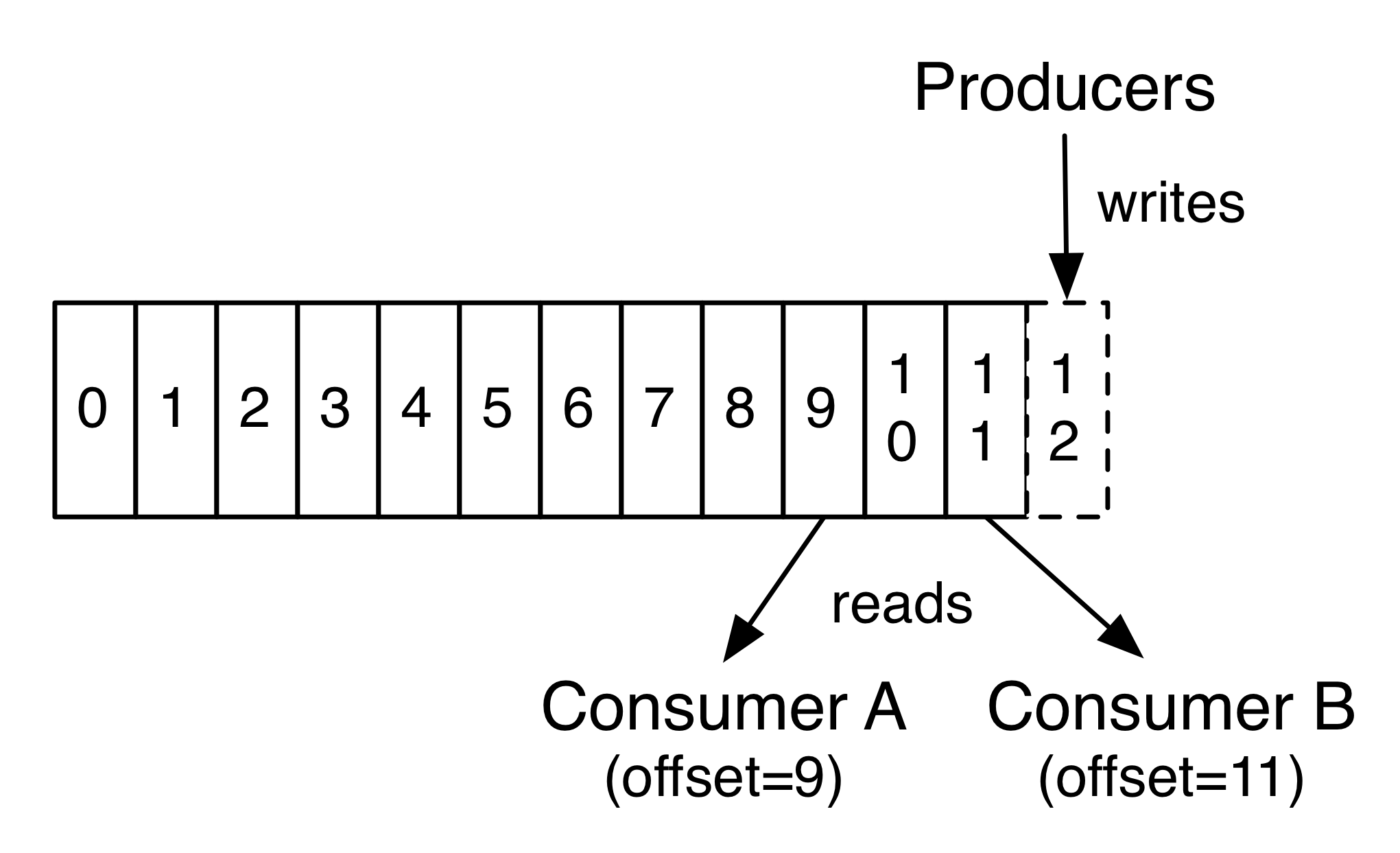
- パーティション中のレコードはそれぞれ offset と呼ばれるシーケンシャルな ID を割り振られる
- この ID は 1 つのパーティションの中でユニークな ID である
- Kafka クラスタは consume されたかどうかに関わらず、設定可能な一定の期間のあいだ、すべての発行されたレコードを保持する
- たとえば 2 日に設定されていたら、レコードが発行されてから 2 日の間はいつでも consume することができ、2 日が経つとスペースを開放するために削除される
- Kafka のパフォーマンスはデータ量に関わらず一定なので、長期間データ保存することは問題ではない
- 実際、consumer ごとに保持される唯一のメタデータは、その consumer のログ上の offset だけである
- offset は consumer によって管理され、通常は読み進めるにつれて offset が先に進むが、どんな順番に読むことも可能である
- たとえば、consumer は offset を古いものにリセットして昔のレコードから処理しなおすこともできる
- もっとも最近のレコードまでスキップして「現在」時点から consume しはじめることもできる
- この特徴を組み合わせると Kafka consumer が非常に安価だということが分かる
- クラスタや他の consumer にほとんど影響を与えず増減させることができる
- たとえば、どんな topic の内容でも、既存の consumer が購読しているものに影響を与えず、 tail することができる
- ログの中のパーティション群にはいくつかの目的がある
- 1 台のサーバーにはおさまらないサイズになってもログをスケールさせることができる
- それぞれのパーティションは 1 つのサーバー上におさまらなければならない
- しかしトピックには複数のパーティションを持たせることができるので、どんな量のデータでも扱うことができる
- 並列の単位として機能する (これについてはこのあとすぐ説明する)
- 1 台のサーバーにはおさまらないサイズになってもログをスケールさせることができる
Distribution
- ログのパーティション群は Kafka クラスタの中で複数サーバーに分散され、それぞれのサーバーが割り振られたパーティションについてデータ・リクエストを扱う
- それぞれのパーティションは耐障害性のため設定可能な数の複数サーバーへと複製される
- それぞれのパーティションは "leader" として機能する 1 サーバーと、0~複数台の "followers" サーバーを持つ
- leader はそのパーティションのすべての read/write リクエストを処理する
- followers は受動的に leader を複製する
- leader が死ぬと、followers のうちの 1 サーバーが新しい leader となる
- それぞれのサーバーはいくつかのパーティション群の leader かつ、別のパーティション群の follower として機能する
- クラスタ内ではいいバランスとなる
Producers
- producer は自分で選んだトピックにデータを発行する
- producer はトピック内のどのパーティションにレコードを割り当てるかを選ぶ責任がある
- 負荷対策のために単純な round-robin で行うこともできる
- また、(レコードのキーのような) なんらかの意味がある分割のやり方にしたがって行うこともできる
- パーティションの利用についてはこのあとすぐ説明する
Consumers
- consumer は consumer group 名をラベルとして持ち、トピックに発行されたそれぞれのレコードはそのトピックを購読している複数の consumer group のそれぞれの中で、1 つの consumer インスタンスに発行される
- consumer インスタンスは別々のプロセスとして、または別々のサーバー上に、存在することができる
- もしすべての consumer が同じ consumer group に所属していれば、レコードはその consumer 群の中でうまく負荷分散される
- もしすべての consumer がちがう consumer group に所属していれば、それぞれのレコードはすべての consumer にブロードキャストされる
- 2 サーバーから構成され、4 つのパーティション (P0~P3) をホストし、2 つの consumer group を持つ Kafka クラスタ
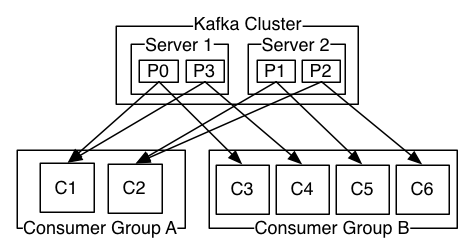
- consumer group A は 2 つの consumer を持ち、group B は 4 つの consumer を持つ
- しかし、もっと一般的に言うと、トピックは少数の consumer group を持ち、それぞれが「論理的なサブスクライバー」ということになる
- それぞれの group はスケーラビリティおよび耐障害性のためにたくさんの consumer を持つ
- これは sub が 1 プロセスではなく consumer のクラスタとなっている pub-sub のセマンティクスとまったく同じものである
- Kafka での consume の実装は、consumer にまたがってログ内のパーティションを分割することで、それぞれのインスタンスがどんなときでも「平等な分け前」分のパーティションを持つ排他的な consumer であるようになっている
- この group 内でのメンバー一覧を維持するプロセスは、kafka のプロトコルによって動的に行われる
- もし新しいインスタンスが group に入ってきたら、group 内のほかのメンバーからパーティションを引き継ぐことになる
- 1 つのインスタンスが死んだら、そのインスタンスが受け持っていたパーティションは残された他のインスタンスに分配される
- Kafka はパーティション内でだけ完全にレコードの順番を保持し、トピック内のパーティションをまたいでは順番は保持されない
- パーティションごとの順番保持と、キーによってデータを分割できる能力を組み合わせれば、たいていのアプリケーションにとっては十分なものとなるだろう
- しかし、すべてのレコードで完全な順番を保持する必要があるなら、1 つのパーティションだけを持つトピックで実現することもできる (ただし consumer group ごとに 1 consumer しか存在しないということになってしまう)
Guarantees
- 高いレベルで Kafka は下記を保証している
- producer から特定の topic パーティションへ送信されたメッセージは、送信された順番で append される
- すなわちレコード M1 と M2 が同じ produducer から送信され、M1 が先に送信されたなら、M1 は M1 よりも値の小さい offset を持ち、ログのより最初のほうに現れる
- consumer はログに蓄積された順番にレコードを見る
- レプリケーション・ファクター N のトピックについて、N-1 台のサーバーが死んでも、ログにコミットされたレコードは失われず、障害に耐えうる
- producer から特定の topic パーティションへ送信されたメッセージは、送信された順番で append される
- これらの保証の詳細についてはドキュメントの "design" セクションに書いてある
Kafka as a Messaging System
- Kafka のストリームの概念は伝統的なエンタープライズ・メッセージング・システムとどのように比べてどうだろうか?
- メッセージングには伝統的に 2 つのモデル queuing と publish-subscribe がある
- queue ではプールされた consumer がサーバーから読み出し、それぞれのレコードは consumer のいずれかに届く
- publish-subscribe ではレコードはすべての consumer に届く
- 2 つのモデルにはメリットとデメリットがある
- queuing のメリットはデータの処理を複数の consumer にまたがって分割し、処理をスケールさせることができること
- 残念なことに queue は複数のサブスクライバーを持てない、つまり 1 つのプロセスがデータを読むとデータは消えてしまう
- publish-subscribe なら複数のプロセスすべてにデータを送ることができるが、すべてのメッセージはそれぞれのサブスクライバに送信されてしまうため、スケールさせる方法がない
- Kafka の consumer group の概念はこの 2 つの概念を一般化したものだ
- queue に関して、consumer group なら処理をいくつかのプロセス (= consumer group のメンバーたち) に分割することができる
- publish-sbscribe に関して、Kafka なら複数の consumer group すべてに対してメッセージを送信することができる
- Kafka のモデルの利点は、すべてのトピックが両方の性質を持っているということだ
- 処理をスケールさせることもできるし、複数のサブスクライバーを持たせることもできる
- どちらかをえらぶ必要はない
- Kafka は伝統的なメッセージング・システムよりも強力に順番を保証している
- 伝統的な queue はサーバー上で順番を保持したレコードの一覧を保持しており、複数の consumer が queue から consume した場合にはサーバーは保存された順番にレコードを分配する
- しかし、サーバーは順番通りにレコードを分配するのだが、レコードが consumer に非同期的に分配されてしまうので、ことなる consumer 群に届くころには順番が乱れてしまっている
- これは並列的な consume を行うとレコードの順番が失われてしまうことを意味している
- メッセージングシステムでは、「排他的な consumer」の概念を持つことでこの問題を回避してきた
* 1 つのプロセスだけが 1 つのキューから consume できるようにするというもの
* しかし当然ながら並列的な処理は不可となってしまう - Kafka ならもっとうまくやれる
- トピックに並列性 (= パーティション) の概念を持たせることで、Kafka は順番の保証もできるし、プールされた consumer プロセス間で負荷分散を行うこともできる
- これはトピック内のパーティションを consumer group 内の consumer に割り当て、それぞれのパーティションが必ず group 内の 1 つの consumer にだけ consume されるようにすることで、実現されている
- これを行うことで、その consumer だけがパーティションを読んでおり、順番にデータを consume していることを保証できる
- たくさんのパーティションを用意すれば、consumer インスタンス間で負荷を分散させることもできる
- しかし、consumer group 内にはパーティションの数より多くの consumer を所属させることはできないことに注意してほしい
Kafka as a Storage System
- どんなメッセージキューでも、メッセージの publish が consume と分離されていれば、やりとりされているメッセージにとってのストレージシステムとして機能はするだろう
- Kafka がちがうのは、それが非常にすぐれたストレージ・システムであるということだ
- Kafka に書き込まれるデータは、ディスクに書かれ、耐障害性のために複製される
- Kafka は producer を待たせ、書き込みが完全に複製され、書き込んだ先のサーバーが死んでもデータが生き続けることが保証されてから ACK を送ることができる
- Kafka が使うディスク構成はうまくスケールする
- Kafka はサーバー上に 50KB の永続的なデータがある場合でも、50TB のデータがある場合でも、同じパフォーマンスを発揮する
- ストレージに真剣に取り組み、クライアントが読み出しの位置を制御できるようにしたことで、Kafka は高性能で低レイテンシーなコミットログのストレージを備え、レプリケーション・伝播が可能な、一種の特殊な分散ファイルシステムとして捉えることができる
Kafka for Stream Processing
- 単にストリーム・データを読み、書き、保存するだけでは不十分で、目的はリアルタイムのストリーム処理を行うことだ
- Kafka にはストリームプロセッサー機能があり、連続したストリーム・データを入力トピックから受け取り、その入力に対してなんらかの処理を行い、出力トピックへと連続したストリーム・データを produce する
- たとえば、小売店のためのアプリケーションでは、入力のストリームとして売り上げと出荷のデータを受け取り、そのデータをもとに計算された再注文と価格のデータを出力するだろう
- 直接 producer/consumer API を使うことでシンプルな処理が可能となるが、もっと複雑なデータ変形のために Kafka は完全に統合された Streams API が備えている
- これにより、ストリームの aggregations を計算したりストリームを join するといったような難しい処理を行うことができる
- この機能はこの種のアプリケーションが直面する難しい問題を解決する助けとなる
- ソートされていないデータを扱ったり
- コードの変更があるごとに入力を再処理したり
- ステートフルな計算を行ったり、等々
- streams API は Kafka が提供するコア基本機能をもとに作られている
- producer/consumer API が利用され、Kafka のステートフルストレージが利用され、ストリーム・プロセッサーのインスタンス間では consumer group と同じ耐障害メカニズムが利用されている
Putting the Pieces Together
- メッセージング、ストレージ、ストリーム処理の組み合わせは異常に見えるかもしれないが、streaming platform として Kafka の役割にとっては重要なものだ
- HDFS のような分散ファイルシステムでは、バッチ処理にとって非常に強く静的なファイルを利用することができる
- このようなシステムは過去からの歴史的なデータを保存し処理することができる
- 伝統的なエンタープライズ・メッセージング・システムでは購読したあとに届く未来のメッセージを処理することができる
- このように作られたアプリケーションでは届いた順に未来のデータを処理する
- Kafka は両方の能力を組み合わせており、この組み合わせは Kafka をストリーミングアプリケーションのプラットフォームとして使うにしても、ストリーミング・データ・パイプラインとして使うにしても重要なものだ
- ストレージと低レイテンシーな購読を組み合わせることで、ストリーミング・アプリケーションは過去と未来の両方のデータを同じように扱うことができる
- 1 つのアプリケーションが、歴史的な保存されたデータを扱い、しかも最後のデータが届いたときに処理が終了するのではなく、未来のデータが届くにつれて処理をしつづけるのだ
- これは一般化されたストリーム処理の概念であり、バッチ処理とメッセージ駆動アプリケーションの両方を包含している
- 同じようにストリーミング・データ・パイプラインにとっては、リアルタイムなイベントの購読を組み合わせることによって、Kafka を非常に低レイテンシーなパイプラインといして使うことができる
- しかし、データ保存に信頼性があるので、データ到達性の保証がマストだったり、定期的にしかデータをロードしなかったり、長期間メンテナンスで落ちることがあるようなオフライン・システムとのインテグレーションに使うこともできる
- ストリーム処理機能により、データが到達するにつれて変形処理を行うことが可能である
- 信頼性、API、Kafka が提供する機能についての詳細は、documentation を参照してください
英単語メモ
- of one's choice = 自分で選んだ
- in flight = 飛行中の
- propagation = 伝播
- retail = 小売店
- subsume = 包含する