はじめに
前回Swift4で言語処理100本ノック 2015 第1章,第2章を書いて大分日が経ってしまいました。
第3章は途中までですが[^1]、折角なので得たことをまとめておこうと思います。
今回もテストコードを書きながら問題20〜24までを進めました、リポジトリはこちらです。
得たこと、良かったことなど
JSONのデコードにCodableを利用
Swift4から新しく追加されたエンコード/デコード用のプロトコルCodableを試しました。
以下はコードの一部ですが、Codableにより簡単にJSONが扱えることを実感しました。
参考: Codableについて色々まとめた[Swift4]
// 利用したい型にCodableを採用する
struct WikiItem: Codable {
let title: String
let text: String
}
/// 入力されたjsonからタイトルがイギリスのものを探し先頭の1件を返す
static func ukWikiItem(input: String) -> WikiItem {
let lines = input.components(separatedBy: CharacterSet.newlines).filter{ !$0.isEmpty }
let decoder = JSONDecoder()
let ukWiki = lines.map{
// 簡単なエンコード/デコードなら1行で出来る
return try! decoder.decode(WikiItem.self, from: $0.data(using: .utf8)!)
}.filter{ $0.title == "イギリス" }
.first!
return ukWiki
}
複数行リテラルの活用
正規表現をベタ書きする時に分かりやすいよう、複数行リテラルで改行してみました。
この例ではそこまで見やすくないですが、SQLなど状況によって活用できると思います。
let categoryNameMatches = linesHasCategory.map { (line) -> String in
let regex =
"""
\\[Category:\
(\
.+[^\\]]\
)\
\\]
"""
return line.matches(regex: regex)[1]
}
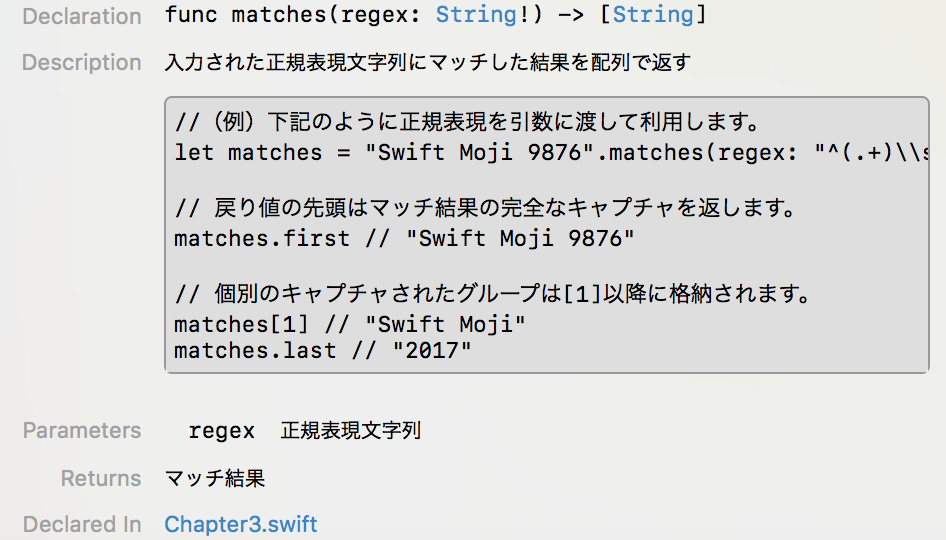
コメント内にコードサンプルを埋め込む
分かりづらい関数のコメント内にサンプルコードの利用例を追加しました。
説明の間に1行間を空け、スペース5個でインデントしたコメントは、
/// 入力された正規表現文字列にマッチした結果を配列で返す
///
/// //(例)下記のように正規表現を引数に渡して利用します。
/// let matches = "Swift Moji 9876".matches(regex: "^(.+)\\s(\\d{4})")
///
/// // 戻り値の先頭はマッチ結果の完全なキャプチャを返します。
/// matches.first // "Swift Moji 9876"
///
/// // 個別のキャプチャされたグループは[1]以降に格納されます。
/// matches[1] // "Swift Moji"
/// matches.last // "2017"
///
/// - Parameter regex: 正規表現文字列
/// - Returns: マッチ結果
このようにコード部分が整形されて表示されるようになります。
答え合わせ
答え合わせにはPythonで書かれている、素人の言語処理100本ノック:まとめ 第3章: 正規表現を参考にしました。
正規表現しっかり頑張ってて偉いなと思いました。
余談(第1章の副産物)
第1章で学んだNグラムを使って2つ文字列の類似度を出すコードを書きました。
こんな感じに使います。類似度が最も低い時0.0、もっとも高い時1.0を返します。
func testSimilarity() {
XCTAssertTrue(String.similarity("", "I") == 0.0)
XCTAssertTrue(String.similarity("I", "I") == 1.0)
XCTAssertTrue(String.similarity("I", "Y") == 0.0)
XCTAssertTrue(String.similarity("I", "IY") == 0.0)
XCTAssertTrue(String.similarity("I see", "I see") == 1.0)
XCTAssertTrue(String.similarity("I see", "I sea") >= 0.6)
XCTAssertTrue(String.similarity("I see", "IC") <= 0.5)
}
こちらの文字列の類似度を計算するgemにあるようにレーベンシュタイン距離を使うよりはパフォーマンスが出るとのことです。
コード全文
//
// Chapter3.swift
// LanguageProcessing100knock2015
//
//
import Foundation
struct WikiItem: Codable {
let title: String
let text: String
}
struct Section {
let name: String
let level: Int
}
struct Chapter3 {
//20. JSONデータの読み込み
//Wikipedia記事のJSONファイルを読み込み,「イギリス」に関する記事本文を表示せよ.問題21-29では,ここで抽出した記事本文に対して実行せよ.
static func q20(input: String) -> WikiItem {
return ukWikiItem(input: input)
}
//21. カテゴリ名を含む行を抽出
//記事中でカテゴリ名を宣言している行を抽出せよ.
static func q21(input: String) -> [String] {
let ukWiki = ukWikiItem(input: input)
let linesHasCategory = ukWiki.text.components(separatedBy: CharacterSet.newlines).filter{ $0.contains("Category") }
return linesHasCategory
}
//22. カテゴリ名の抽出
//記事のカテゴリ名を(行単位ではなく名前で)抽出せよ.
static func q22(input: String) -> Set<String> {
let linesHasCategory = q21(input: input)
let categoryNameMatches = linesHasCategory.map { (line) -> String in
let regex =
"""
\\[Category:\
(\
.+[^\\]]\
)\
\\]
"""
return line.matches(regex: regex)[1]
}
var categoryNames = [String]()
categoryNameMatches.forEach { (s) in
if s.contains("|") {
categoryNames.append(contentsOf: s.components(separatedBy: "|"))
} else {
categoryNames.append(s)
}
}
return Set(categoryNames)
}
//23. セクション構造
//記事中に含まれるセクション名とそのレベル(例えば"== セクション名 =="なら1)を表示せよ.
static func q23(input: String) -> String {
let ukWiki = ukWikiItem(input: input)
let lines = ukWiki.text.components(separatedBy: CharacterSet.newlines)
let sections = lines.flatMap { (line) -> Section? in
let matche = line.matches(regex: "^(={2,})\\s*(.+?)\\s*={2,}$")
if !matche.isEmpty {
return Section(name: matche[2], level: (matche.first?.count)! - 1)
} else {
return nil
}
}
return sections.map{ "\($0.name), \($0.level)" }.joined(separator: "\n")
}
//24. ファイル参照の抽出
//記事から参照されているメディアファイルをすべて抜き出せ.
static func q24(input: String) -> String {
let ukWiki = ukWikiItem(input: input)
let matches = ukWiki.text.matches(regex: "(ファイル:(.+?)|File:(.+?))[|]")
let matchedFileIndeices = stride(from: 2, to: matches.count, by: 3).map{$0}
return matches.enumerated().reduce("") { (combined, pair) -> String in
if matchedFileIndeices.contains(pair.offset) {
return "\(combined)\(pair.element)\n"
} else {
return combined
}
}
}
}
extension Chapter3 {
/// 入力されたjsonからタイトルがイギリスのものを探し先頭の1件を返す
static func ukWikiItem(input: String) -> WikiItem {
let lines = input.components(separatedBy: CharacterSet.newlines).filter{ !$0.isEmpty }
let decoder = JSONDecoder()
let ukWiki = lines.map{
return try! decoder.decode(WikiItem.self, from: $0.data(using: .utf8)!)
}.filter{ $0.title == "イギリス" }
.first!
return ukWiki
}
}
extension String {
/// 入力された正規表現文字列にマッチした結果を配列で返す
///
/// //(例)下記のように正規表現を引数に渡して利用します。
/// let matches = "Swift Moji 9876".matches(regex: "^(.+)\\s(\\d{4})")
///
/// // 戻り値の先頭はマッチ結果の完全なキャプチャを返します。
/// matches.first // "Swift Moji 9876"
///
/// // 個別のキャプチャされたグループは[1]以降に格納されます。
/// matches[1] // "Swift Moji"
/// matches.last // "2017"
///
/// - Parameter regex: 正規表現文字列
/// - Returns: マッチ結果
func matches(regex: String!) -> [String] {
do {
let regex = try NSRegularExpression(pattern: regex, options: [])
let results = regex.matches(in: self,
options: [],
range: NSRange(location: 0, length: self.count))
var matches = [String]()
for result in results {
for i in 0..<result.numberOfRanges {
let range = Range.init(result.range(at: i), in: self)
if let r = range {
matches.append(String(self[r]))
}
}
}
return matches
} catch let error as NSError {
assertionFailure("invalid regex: \(error.localizedDescription)")
return []
}
}
}