はじめに
全国のMySQLerの皆様こんにちは。
まだRC版ですがMySQL8でついにウィンドウ関数が使えるようになりましたね。
ということで今までMySQL使いにとってあまり馴染みのなかったウィンドウ関数を簡単に解説してみます。
ウィンドウ関数とは
むちゃくちゃ乱暴にいうと、集約のないGROUP BYです。
と、いうのはさすがに乱暴すぎるので順を追って説明します。
その前に説明に使うテーブルを作っておきましょう。
せっかくなのでMySQLの開発者ブログでウィンドウ関数を紹介した記事 ”MySQL 8.0.2: Introducing Window Functions” からお借りします。
CREATE TABLE sales(
employee VARCHAR(50),
`date` DATE,
sale INT
);
INSERT INTO sales VALUES
('odin', '2017-03-01', 200),
('odin', '2017-04-01', 300),
('odin', '2017-05-01', 400),
('thor', '2017-03-01', 400),
('thor', '2017-04-01', 300),
('thor', '2017-05-01', 500);
| employee | date | sale |
|---|---|---|
| odin | 2017-03-01 | 200 |
| odin | 2017-04-01 | 300 |
| odin | 2017-05-01 | 400 |
| thor | 2017-03-01 | 400 |
| thor | 2017-04-01 | 300 |
| thor | 2017-05-01 | 500 |
月初に前月分の売り上げを従業員ごとに記録しているテーブルです。
このテーブルを使って元記事の内容にも触れつつ説明していきます。
GROUP BYは分割+集約
まずはGROUP BYの挙動のおさらいから。
SELECT
employee,
SUM(sale) AS sum_sale
FROM sales
GROUP BY employee;
結果はこうなりますね。
| employee | sum_sale |
|---|---|
| odin | 900 |
| thor | 1200 |
これで従業員ごとの売り上げの合計を求めることができます。
これを図で表すとこうなります。
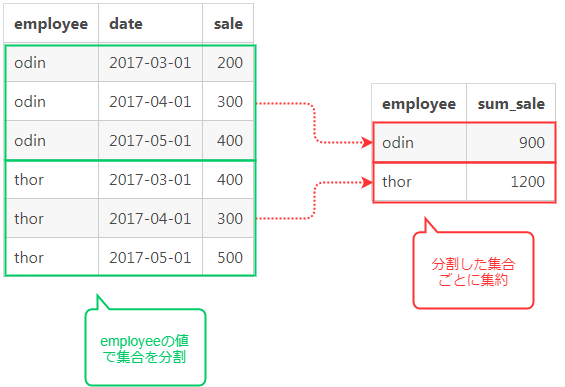
テーブルの全体集合をGROUP BYで指定したカラムの値を元に排他的な部分集合に切り分ける操作を「分割」といい、分割された部分集合ごとに1つのタプル(行)にまとめること「集約」1と言います(言うことにします)。
GROUP BYは分割と集約という2つの処理を一度にやっています。
ウィンドウ関数は分割のみ
それに対してウィンドウ関数は分割のみで行自体の集約はしません。
実際の挙動を見てみる前にウィンドウ関数の書き方を先に紹介しておきます。
まずは基本形を。
SELECT
employee, date, sale,
SUM(sale) OVER(
PARTITION BY employee
) AS sum_sale
FROM sales;
基本は 関数() OVER(・・・) という形です。
PARTITION BY句で指定するカラム(ここではemployee)が分割のキーになるカラムです。
関数の部分にはGROUP BYで併用するような通常の集約関数の他、後述する専用のウィンドウ関数を指定することができます。
では上記のSQLの結果がどうなるか見てみましょう。
| employee | date | sale | sum_sale |
|---|---|---|---|
| odin | 2017-03-01 | 200 | 900 |
| odin | 2017-04-01 | 300 | 900 |
| odin | 2017-05-01 | 400 | 900 |
| thor | 2017-03-01 | 400 | 1200 |
| thor | 2017-04-01 | 300 | 1200 |
| thor | 2017-05-01 | 500 | 1200 |
GROUP BYと同じくsum_saleの列は従業員ごとの売り上げの合計になりますが、ここで重要なことは元の行数が維持されていることです。(つまり集約によって行が減っていない)
PARTITON BYは必須ではないので省略することもできます。その場合はテーブル全体が一つのパーティションになるので、結果的にsum_saleは全従業員の売り上げの合計値になります。
SELECT
employee, date, sale,
SUM(sale) OVER() AS sum_sale
FROM sales;
| employee | date | sale | sum_sale |
|---|---|---|---|
| odin | 2017-03-01 | 200 | 2100 |
| odin | 2017-04-01 | 300 | 2100 |
| odin | 2017-05-01 | 400 | 2100 |
| thor | 2017-03-01 | 400 | 2100 |
| thor | 2017-04-01 | 300 | 2100 |
| thor | 2017-05-01 | 500 | 2100 |
いずれにせよ元の行の数には影響がないことが分かります。
これはウィンドウ関数を理解するうえで大事な特性なので覚えておきましょう。
ウィンドウフレーム
単に「ウィンドウ」または「フレーム」とも言います。簡単にいうと分割されたパーティション内でのウィンドウ関数の影響範囲です。つまり、「パーティションの中のこの行からこの行までの範囲にウィンドウ関数を適用する」というその範囲がフレームです。そして通常このフレームを指定するためにはOVER句の中でORDER BYを使用します。(なぜならソートしなければ行の位置が不定だから)
言葉で説明しても分かりにくいので実際に見てみましょう。
SELECT
employee, date, sale,
SUM(sale) OVER(
PARTITION BY employee
ORDER BY date
) AS sum_sale
FROM sales;
| employee | date | sale | sum_sale |
|---|---|---|---|
| odin | 2017-03-01 | 200 | 200 |
| odin | 2017-04-01 | 300 | 500 |
| odin | 2017-05-01 | 400 | 900 |
| thor | 2017-03-01 | 400 | 400 |
| thor | 2017-04-01 | 300 | 700 |
| thor | 2017-05-01 | 500 | 1200 |
結果を見ると分かるように、このSQLは、「従業員ごとの月ごとの売り上げを順番に加算した値」を出力します。
これを図で表すとこうなります。
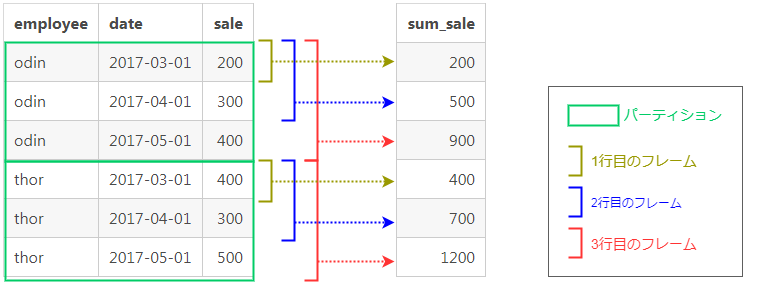
上記の挙動を言葉で説明すると、
(1) ORDER BYで指定したカラムでパーティション内をソートし、
(2) 「パーティション内の行の先頭から現在の行まで」がフレームとして設定され、
(3) それぞれのフレーム内でsale値を合計し、
(4) 現在の行のsum_sale列に出力する
といった流れになります。
フレーム定義
フレームの範囲はデフォルトでは「パーティション内の行の先頭から現在の行まで」ですが、これは任意の範囲で指定できます。
SELECT
employee, date, sale,
SUM(sale) OVER(
PARTITION BY employee
ORDER BY date
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
) AS sum_sale
FROM sales;
| employee | date | sale | sum_sale |
|---|---|---|---|
| odin | 2017-03-01 | 200 | 500 |
| odin | 2017-04-01 | 300 | 900 |
| odin | 2017-05-01 | 400 | 700 |
| thor | 2017-03-01 | 400 | 700 |
| thor | 2017-04-01 | 300 | 1200 |
| thor | 2017-05-01 | 500 | 800 |
このSQLでは、その月と前後1ヶ月の売り上げの計3ヶ月間の売り上げ合計を求めます。
フレームを図で表すとこうなります。
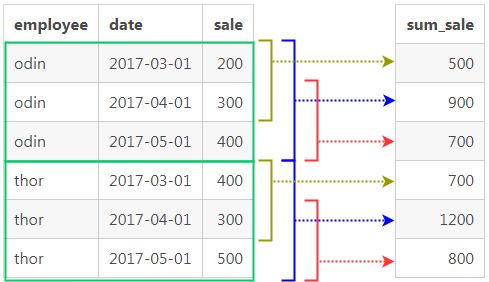
1 PRECEDINGが現在の行の1つ前の行、1 FOLLOWINGが現在の行の1つ後の行を表すので、それをBETWEENで範囲指定しているわけです。ただしフレームはパーティションを超えては影響しないので、あくまで各パーティション内でのローカル分割と思ってください。
ちなみにフレームの始点や終点の指定をパーティション内の先頭行にしたい場合はUNBOUNDED PRECEDING、末尾行にしたい場合はUNBOUNDED FOLLOWING、現在行にしたい場合はCURRENT ROWというキーワードをそれぞれ使います。
つまりフレームを明示的に指定しないデフォルトの状態というのは以下のSQLと同じ結果になります。
SELECT
employee, date, sale,
SUM(sale) OVER(
PARTITION BY employee
ORDER BY date
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS sum_sale
FROM sales;
行の位置を指定するなんて関係モデルからすれば怪しい匂いがプンプンしますが、いいんです。割り切っちゃいましょう。便利なので。
フレームの物理的な境界と論理的な境界
先ほどの例では従業員ごとの3ヶ月(当月と前後1ヶ月)の売り上げ合計を求めましたが、たとえば月初に前月の売り上げを一括で付けるのではなく、日ごとに付けている場合で同じことをするとどうでしょうか。
たとえば以下のようなテーブルです。
| employee | date | sale |
|---|---|---|
| odin | 2017-03-01 | 200 |
| odin | 2017-04-01 | 100 |
| odin | 2017-04-02 | 200 |
| odin | 2017-05-01 | 400 |
| thor | 2017-03-01 | 400 |
| thor | 2017-04-01 | 300 |
| thor | 2017-05-01 | 500 |
元のテーブルと違うのはodinの4月の売り上げ(300)が2行(100と200)に分かれている点です。
このテーブルに対して先程の例と同じ3ヶ月間の売り上げ合計を求めるSQLを流すとこうなります。
| employee | date | sale | sum_sale |
|---|---|---|---|
| odin | 2017-03-01 | 200 | 300 |
| odin | 2017-04-01 | 100 | 500 |
| odin | 2017-04-02 | 200 | 700 |
| odin | 2017-05-01 | 400 | 600 |
| thor | 2017-03-01 | 400 | 700 |
| thor | 2017-04-01 | 300 | 1200 |
| thor | 2017-05-01 | 500 | 800 |
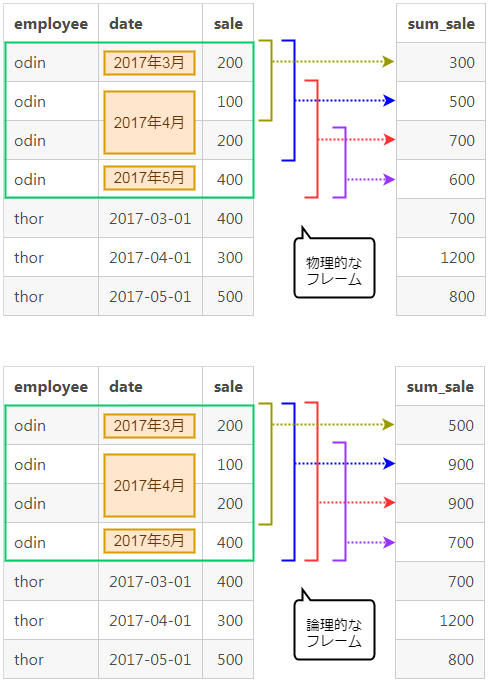
やりたいのはあくまで月単位で考えた時の3ヶ月の売り上げ合計を計算してsum_saleの列に出力することですので、これは欲しい答えと違います。(同じ月のsum_saleは同じ値になってほしい)
ROWS BETWEEN〜を使うと物理的な行の前後関係からフレームの境界を決めてしまうので、同じ月の行と行の間に境界が引かれてしまいます。
物理的な行の位置に基づいて現在行の前後をフレームの範囲とするのではなく、論理的なデータに基づいて現在行の前後をフレームの範囲としたい、という場合にはROWSではなくRANGEを使います。
SELECT
employee, date, sale,
SUM(sale) OVER(
PARTITION BY employee
ORDER BY CAST(DATE_FORMAT(date, '%Y%m') AS UNSIGNED)
RANGE BETWEEN 1 PRECEDING AND 1 FOLLOWING
) AS sum_sale
FROM sales;
| employee | date | sale | sum_sale |
|---|---|---|---|
| odin | 2017-03-01 | 200 | 500 |
| odin | 2017-04-01 | 100 | 900 |
| odin | 2017-04-02 | 200 | 900 |
| odin | 2017-05-01 | 400 | 700 |
| thor | 2017-03-01 | 400 | 700 |
| thor | 2017-04-01 | 300 | 1200 |
| thor | 2017-05-01 | 500 | 800 |
「売り上げ月」という論理的な位置関係に基づいてフレームが区切られたことがわかります。
この2つの違いを図で見てみましょう。
ウィンドウ関数いろいろ
今まではSUM()を使って合計値を求める例をあげましたが、もちろんGROUP BYで通常使うようなAVG()やCOUNT()などの他の集約関数も同じようにOVER句を持つことができます。
その他にもウィンドウ関数ならではの強力な関数も紹介しておきます。
| 関数 | 概要 |
|---|---|
| ROW_NUMBER() | 行の先頭から順番に行番号を振る |
| RANK() | 順位を計算 ※同率があった場合は同順位 ※次点の順位を飛ばす |
| DENSE_RANK() | 順位を計算 ※同率があった場合は同順位 ※次点の順位を飛ばさない |
| PERCENT_RANK() | 相対順位を計算 |
| CUME_DIST() | 相対順位を計算(累積分布) |
| NTILE() | 指定した数のグループに分割 |
| FIRST_VALUE() | 最初の行の値 |
| LAST_VALUE() | 最後の行の値 |
| LAG() | 現在の行よりN行前の値 |
| LEAD() | 現在の行よりN行後の値 |
| NTH_VALUE() | N行目の値 |
それぞれの詳細は長くなるのでここではしませんが、以下のページが分かりやすいと思います。
PostgreSQLの記事ですが、まぁ一緒です。
http://postd.cc/window_functions_postgresql/
こちらも。
https://qiita.com/kakuka4430/items/8c66e743800fcb8bc040
せっかくなのでこの場でも一例だけあげておきます。
SELECT
employee, date, sale,
RANK() OVER(
PARTITION BY employee
ORDER BY sale DESC
) AS m_rank,
RANK() OVER(
PARTITION BY date
ORDER BY sale DESC
) AS e_rank
FROM sales
ORDER BY employee, date;
| employee | date | sale | m_rank | e_rank |
|---|---|---|---|---|
| odin | 2017-03-01 | 200 | 3 | 2 |
| odin | 2017-04-01 | 300 | 2 | 1 |
| odin | 2017-05-01 | 400 | 1 | 2 |
| thor | 2017-03-01 | 400 | 2 | 1 |
| thor | 2017-04-01 | 300 | 3 | 1 |
| thor | 2017-05-01 | 500 | 1 | 1 |
このSQLは以下の2つのランキングを求めています。
- 各従業員ごとの売り上げの多い月のランキング(m_rank)
- 各月ごとの売り上げの多い従業員のランキング(e_rank)
パーティション/フレームはあくまでウィンドウ関数を適用する集合を仮想的に分割するものであるため、異なるパーティション/フレームを1つのテーブルで複数定義することができます。
名前付きウィンドウ
複数のパーティション/フレームを別々に定義できると書きましたが、同じ定義を使って異なる関数を適用したい場合にわざわざ毎回OVER句に書くのは面倒ですよね?そういう場合はFROMに続くWINDOW句でエイリアスを作ることができます。
たとえば以下の2つのSQLは同じ意味です。
SELECT
employee, date, sale,
ROW_NUMBER() OVER(
PARTITION BY date
ORDER BY sale DESC
) AS row_num,
RANK() OVER(
PARTITION BY date
ORDER BY sale DESC
) AS e_rank
FROM sales;
SELECT
employee, date, sale,
ROW_NUMBER() OVER(w) AS row_num,
RANK() OVER(w) AS e_rank
FROM sales
WINDOW w AS (PARTITION BY date ORDER BY sale DESC);
複数のエイリアスを定義したい時はカンマで区切ります。
WINDOW
w1 AS (PARTITION BY date ORDER BY sale DESC),
w2 AS (PARTITION BY employee ORDER BY sale DESC)
最後に
ウィンドウ関数って何?という人にとってはどういう原理で動くかをイメージできてないと結構詰まるポイントになるかなと思ったのでできるだけ簡単にまとめてみました。
ウィンドウ関数は分析関数とも呼ばれることもありますが、その名の通りSQLでデータ分析しようと思うと必須の機能です。他のRDBMSでは既に実装されていましたが、遅れをとっていたMySQLでも遂に次期バージョンから使えるようになりました。MySQLはOLTPに強い反面、OLAP分野などには弱かったのですが、こうやってMySQLだけでできることが増えていくのはいいですね。MySQL8の正式リリース(GA)が楽しみです。
-
SUM自体が”集約”関数なのでややこしいですが、ここでいう”集約”は値の集約ではなく行の集約という意味で使っています。 ↩