この記事はN/S高等学校 Advent Calendar 2022の13日目です。
N高生です。普段はBlenderでモデリングをしています。
はじめに
Stable Diffusion2.0がリリースされ人物画像の生成能力が上がったらしいので試してみたいと思い触れてみました。
ついでならファインチューニングもやってみて誰かを無限に生成したいな、と思ったのでS高校長に許可をもらいやってみました。感謝。
Stable Diffusionとは
Stable Diffusion(ステーブル・ディフュージョン)は、2022年に公開されたディープラーニング(深層学習)のtext-to-imageモデルである。主にテキスト入力に基づく画像生成(text-to-image)に使用されるが、他にもインペインティング、アウトペインティング、テキストプロンプトによって誘導される画像に基づく画像生成(image-to-image)にも使用される
[参考]
ウィキペディア
ということで、話題の画像生成AIです。
ファインチューニングとは
既存のモデル(ここではStablediffusion)に数枚の画像を追加学習させて新しい概念を学習させることです。
なので数枚画像があれば特定の人物や絵柄に寄せることができます。
Twitterなどで話題になっていたWiafu DiffutionなどはStable Diffusionをファインチューニングしたものです。
ファインチューニングには純粋な追加学習やDreambooth, Hypernetwork, DreamArtistなど様々な手法がありますが今回はDreamboothで行います。
環境
- GPU: RTX 3060
- RAM: 16G
- Docker 20.10.21
- dreambooth-gui v0.1.9 - alpha
- stable-diffusion-webui
Dreambooth-GUIのインストール
stable-diffusion-webuiの追加機能にもDreamboothはあるのですがVRAMが足らず途中で落ちてしまうためこちらを使用します。(11/30 時点)
こちらはVRAMが10Gでもぎりぎり動くそうです。
dreambooth-guiのInstallに沿って進めていきます。
- Dockerをインストール
- WSL2をインストール
- dreambooth-guiをインストール
学習元の準備
画像を10枚用意し学習したい人物以外の背景部分を白で塗りつぶします。
背景を白で塗りつぶすと学習を強くしたときに単純な背景になりやすいようですが今回は行いました。
そして背景部分に変な塗り残しがあるとそのミスも学習してしまうのできれいに切り抜くようにします。
実行
Dockerを起動しそのあとdreambooth-guiを起動します。
どちらも管理者権限で実行します。
そして用意した学習画像を読み込みます。
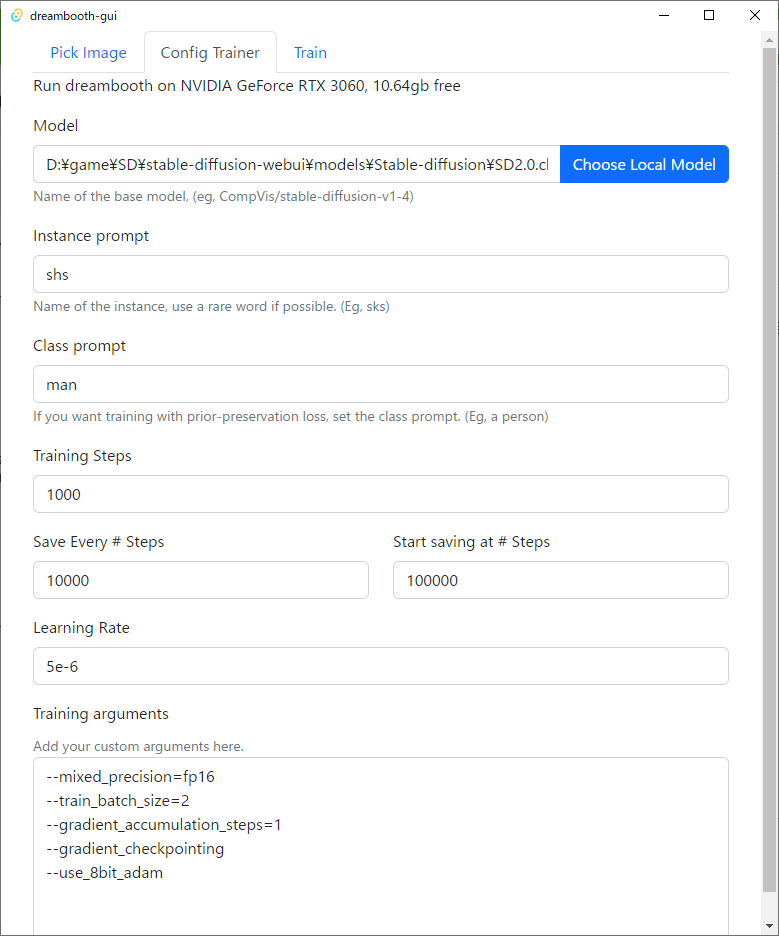
Config Trainerのタブで学習設定を行います
Model モデルを選択します
Instance prompt 学習する物の名前を決めます。既にある名前は避けることが望ましいです。
Class prompt どんなものなのかを決めます。
Training Steps どのくらい学習するのかを決めます。今回は1000でやります。
このステップを上げると再現性が上がっていきますが、一定の値を超えると過学習状態になってしまい出力される画像が崩壊してしまうので注意が必要です。
あとは実行するだけです。
結果
ここで問題が発生しました。
SD2.0ではText Encoderが大きくなっており、VRAMが12Gでは足りないことが判明しました。
なんてこったい
なのでここではSD1.5で行います。
モデルの実行
stable-diffusion-webuiでSifueDiffusionを使って画像生成します。


タコスを食べる校長とライオンと戯れる校長が生成できました。
スーツを着ている画像しか学習していないのでかなりの確率でスーツを着ます。

学習は写真で行ったのですが絵画風にしたりもできます。
まとめ
校長を無限に生成することに成功した。
改善点としては、まだ知らないおじさんが生成される確率が高いので学習を進めたり、SD2.0でor2.1での学習がある。
Slackの#ai-artでは様々なAIの話題などで交流できるので気になった方はぜひ。
参考サイト
画像生成AI「Stable Diffusion」にたった数枚のイラストから絵柄や画風を追加学習できる「Dream Booth」が簡単に使える「Dreambooth Gui」レビュー