環境
・ macOS Ventura 13.2
・ python 3.10.0
・ pandas 1.5.3
・ selenium 4.8.2
このプログラムを組んだ理由
最近、「Amazon」や「えきねっと」を騙って下のようなメールがちょくちょく来るようになった。
なりすましかどうか検証するのに参考となるHPが無いかと調べていたら、4つほど参考になる検証WEBがあったので、今勉強中のseleniumで一度に検索できるプログラムを組んでみた。
差出人だけ見れば、実在する会社名そのものだし信用しそうになるが、見える部分は表面だけで色々な処に仕掛(サイトに誘う)がしてあることが分かった。
(手紙の封筒に書く差出人の住所は出鱈目でも、郵便は出せるのと同じです。)
重要なのは、リンクのaddressです!!
■記述する内容は以下の通りです。
とても長いですが、コピペしてください。(まだ経験が浅いため、非効率な部分があると思いますが、ご容赦ください。)
#詐欺メールの検証prigram
import os #OSに依存しているさまざまな機能を利用するためのモジュール
import signal
import time #ブラウザを操作した際に一定時間待つのに使う
# --------------------------------------
# seleniumオブジェクトのimport
# 様々なブラウザを制御するためのクラスを提供(主にWebアプリケーションのテストやスクレイピングなどに使用するモジュール)
from selenium import webdriver
# find_element() メソッドを呼び出す際に要素を見つける方法を指定するために使用
from selenium.webdriver.common.by import By
# 要素が特定の条件を満たすまで待機するために使用
from selenium.webdriver.support.ui import WebDriverWait
# WebDriverWait と組み合わせて、要素が特定の条件を満たすまで待機するために使用
from selenium.webdriver.support import expected_conditions
# Serviceクラスは、ブラウザのドライバーを実行するためのサービスを管理するためのクラス
# 通常、直接使用することはありませんが、カスタム設定が必要な場合に便利
from selenium.webdriver.chrome.service import Service as ChromeService
# ------------------------------------------------------
# 例外をインポート
from selenium.common.exceptions import StaleElementReferenceException
'''特定のウェブ要素がページ上で更新または変更された後に、それに対する操作を試みた場合に発生します。要素の参照が古くなった(stale)ため、操作が失敗するときにこの例外がスローされます。この例外をキャッチして適切に処理することで、スクリプトやテストの健全性を確保し、ウェブページ上の要素を操作する際の安定性を向上させることができます。'''
# ------------------------------------------------------
'''chromedriver_binaryの記述例またはwebdriver-managerの記述例のどちらかをコメントアウト'''
# ------------------------------------------------------
# webdriver-managerの記述例
# Selenium WebDriver用のドライバーを自動的にダウンロードして管理するためのツール(パッケージ)
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
# ------------------------------------------------------
'''
# chromedriver_binaryの記述例
# Chromedriverを簡単にインストール・管理できるようにするためのパッケージ
#Driverの場所:/Users/itoutoshio/.pyenv/versions/3.10.4/lib/python3.10/site-packages/chromedriver_binary
import chromedriver_binary
# Chromedriverを使用してChromeブラウザを起動
driver = webdriver.Chrome()
'''
# ------------------------------------------------------
# ヘッドレスモード設定
options = webdriver.ChromeOptions()
options.add_argument("--headless")
# --------------------------------------
#browser = webdriver.Chrome(options=option)# <--不要につき削除
#================================================================
#<url>
url_1 = "https://www.aguse.jp" #sgude
url_2 = "https://global.sitesafety.trendmicro.com/?cc=jp" #trendMicro
url_3 = "https://tech-unlimited.com/whois.html" #tech
url_4 = "https://domain.sakura.ad.jp/whois/?" #sakura
#<xpath>
xpath_1 = "//*[@id='url']" #sgude
xpath_2 = "//*[@id='urlname']" #trendMicro
xpath_3 = "//*[@id='init_focus_box']" #tech
xpath_4 = "//*[@id='whois']/main/div[3]/section[1]/div/div/div/input"#sakura
try:
#============================================================
#「aguse.jp- ウェブ調査」・「Trend Micro Site Safety Center」・「WHOIS検索 Tech-Unlimited」
def web1(driver, option, xpath_X, url):# browserを削除
# 要素がステール(無効)になった場合に、一時的に待機し、要素が再びアタッチ可能になるまでリトライするようなメカニズムを実装する(time.sleep()を使用して一時的に待機)
retry_attempts = 3
retry_delay = 1
for _ in range(retry_attempts):
try:
# 検索ボックスのオブジェクトを取得
#search_bar= driver.find_element_by_xpath(xpath_X)#<-selenium3以前
search_bar= driver.find_element(By.XPATH,xpath_X)#<-selenium3以降
# キーを検索ボックスに送信
search_bar.send_keys(url)
# フォームを送信
search_bar.submit()
break
except StaleElementReferenceException:
# ステールな要素が見つかった場合、一時的に待機してリトライする
time.sleep(retry_delay)
# ---------------------------------------------------------
#Whois検索 | 「さくらのドメイン」
def web2(driver, options, xpath_4, url):# browserを削除
# 検索ボックスのオブジェクトを取得
#search_bar= driver.find_element_by_xpath(xpath_4)
search_bar= driver.find_element(By.XPATH,xpath_4)#<-selenium3以降
# キーを検索ボックスに送信
search_bar.send_keys(url)
# 「検索buttonをクリック」
#driver.find_element_by_xpath("//*[@id='whois']/main/div[3]/section[1]/div/div/div/div/button").click()#<-selenium3以前
driver.find_element(By.XPATH,"//*[@id='whois']/main/div[3]/section[1]/div/div/div/div/button").click()#<-selenium3以降
#============================================================
#調査するURL
#Beep音を鳴らす(web画面展開中にTerminalに出現するため注意喚起)
print('\a')
#--------------
print('')
print('-'*50)
print('検索するURL(@以下の部分またはhttp://以下の部分)を入力してください。')
#--------------
#下記の2つのprintが不要であれば、削除してください。
print('例えば:最近の例ではAmazonを騙って、『amazon@member-amazon.shop』が来ました。')
print('TESTで行う時は member-amazon.shop と入力して試してみてください')
#--------------
url = input('検索するドメイン:')
print('')
print('-'*50)
#------------------------------------------------------------
#self-made founction(aguse.jp- ウェブ調査)
driver.get(url_1)
web1(driver, options, xpath_1, url)# browserを削除
# javascriptで新しいページを開く
driver.execute_script("window.open(arguments[0], '_blank')", url_2)
driver.switch_to.window(driver.window_handles[-1])
#-------------------------------------
# self-made founction(Trend Micro Site Safety Center)
web1(driver, options, xpath_2, url)# browserを削除
# javascriptで新しいページを開く
driver.execute_script("window.open(arguments[0], '_blank')", url_3)
#ウィンドウハンドルを取得し、seleniumで操作可能なdriverを切り替える
driver.switch_to.window(driver.window_handles[-1])
#-------------------------------------
#self-made founction(WHOIS検索 Tech-Unlimited)
web1(driver, options, xpath_3, url)
# javascriptで新しいページを開く
driver.execute_script("window.open(arguments[0], '_blank')", url_4)
#ウィンドウハンドルを取得し、seleniumで操作可能なdriverを切り替える
driver.switch_to.window(driver.window_handles[-1])
#-------------------------------------
#self-made founction(Whois検索 | さくらのドメイン)
web2(driver, options, xpath_4, url)
# seleniumで操作可能なdriverを切り替える(先頭のTabをactiveにする)
driver.switch_to.window(driver.window_handles[0])
print('')
print('『aguse.jp- ウェブ調査』は検索完了まで少々時間がかかります。')
print('少々お持ちください')
print('='*40)
time.sleep(3)
print('終了しました。')
finally:
os.kill(driver.service.process.pid,signal.SIGTERM)
<えきねっとの例>
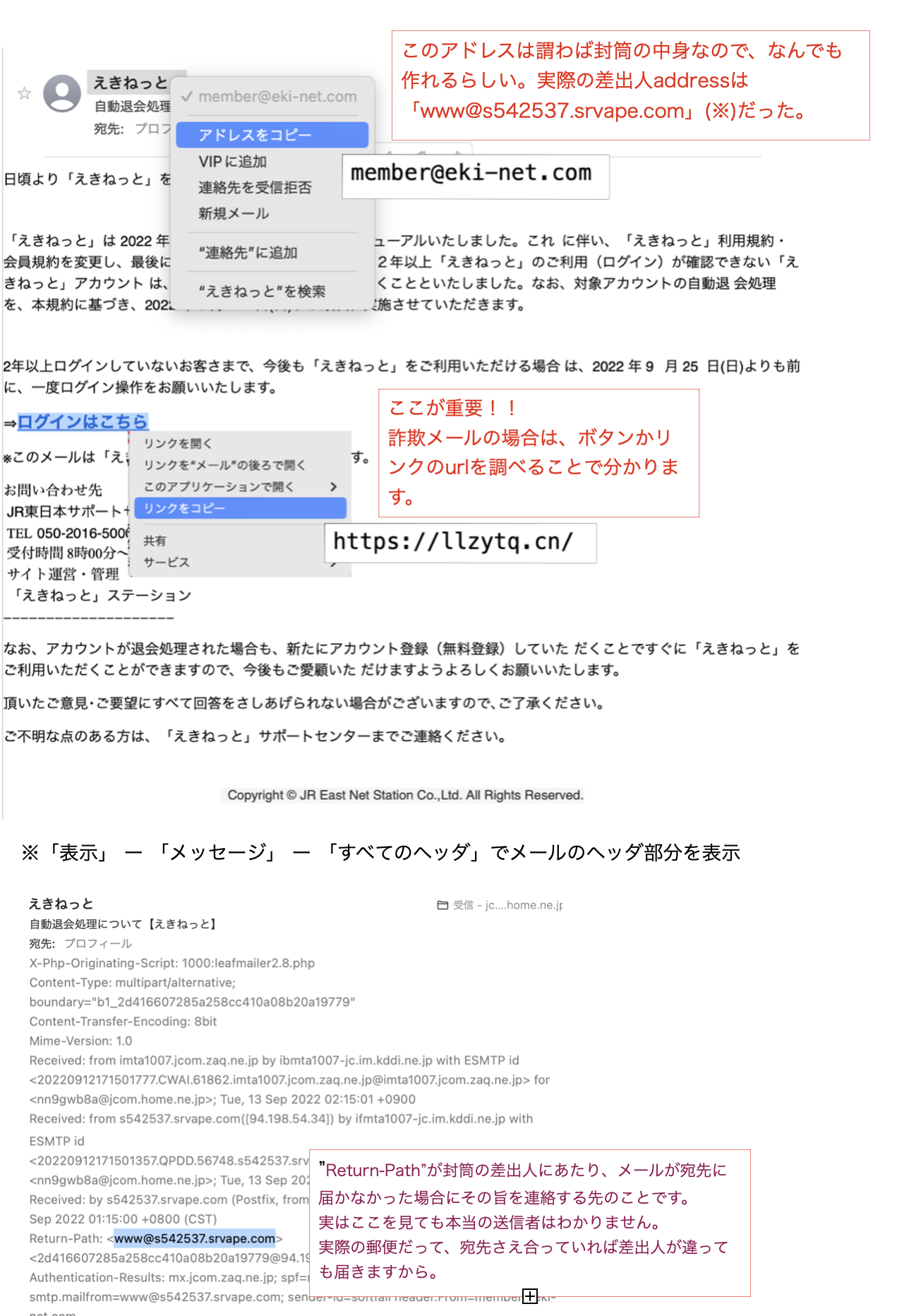
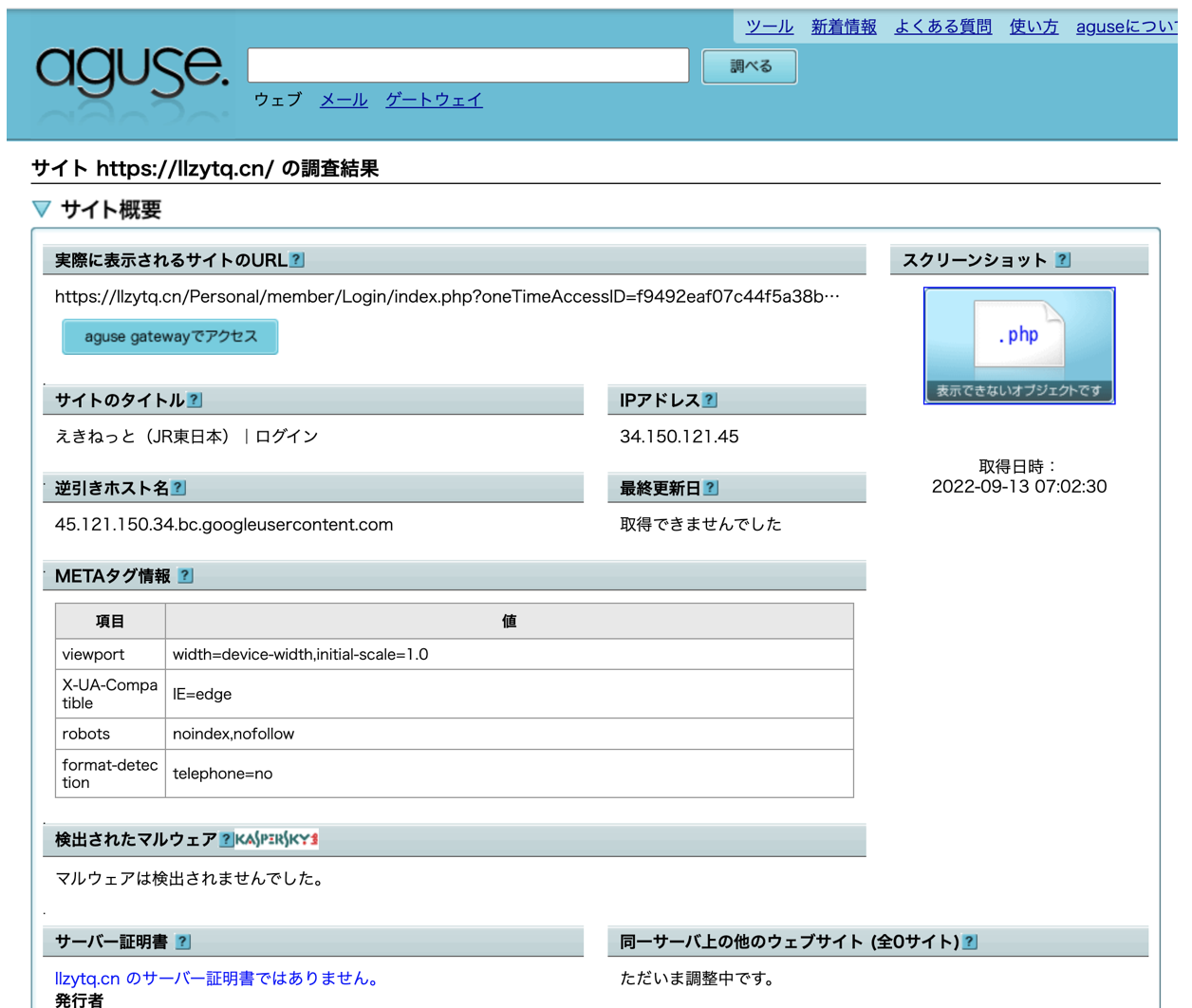
aguseの結果はサイトのタイトルで騙されて一見問題なさそうに見えるが、そもそもurlのドメイン名が「.cn(中国)」なのがが怪しい。(中国とJR?
トレンドマイクロによる安全性の評価によれば危険の評価になった。

これで決定的に詐欺メールと判断。リンクをクリックしては危険。
<Amazonの例>
「Amazon.com」とあるから最初ドキッとしたけど、差出人の 「Amazon.com」部分を右クリック -「アドレスをコピー」をクリック - テキストエディットに貼り付け てみると、http://amazon@member-amazon.shopとなっていた。(99%怪しい)

でも、amazon.shop 部分が気になるので、参考となるHPが無いかと調べていたら、4つほど参考になる検証WEBがあったので、今勉強中のseleniumで一度に検索できるプログラムを組んでみた。
ちなみに現在では、
.cn
.top
.shop
の3つのトップレベルドメインを受診拒否登録したら来なくなった。
このプログラムを実行すると以下のホームページが表示されるので、怪しいかどうか検討する。
例えば、
1, aguse.jp- ウェブ調査 では 検出されたマルウエアがあるかとか、サーバーの位置情報とか(中国.cnは絶対怪しい)
2, Trend Micro Site Safety Center では安全性の評価
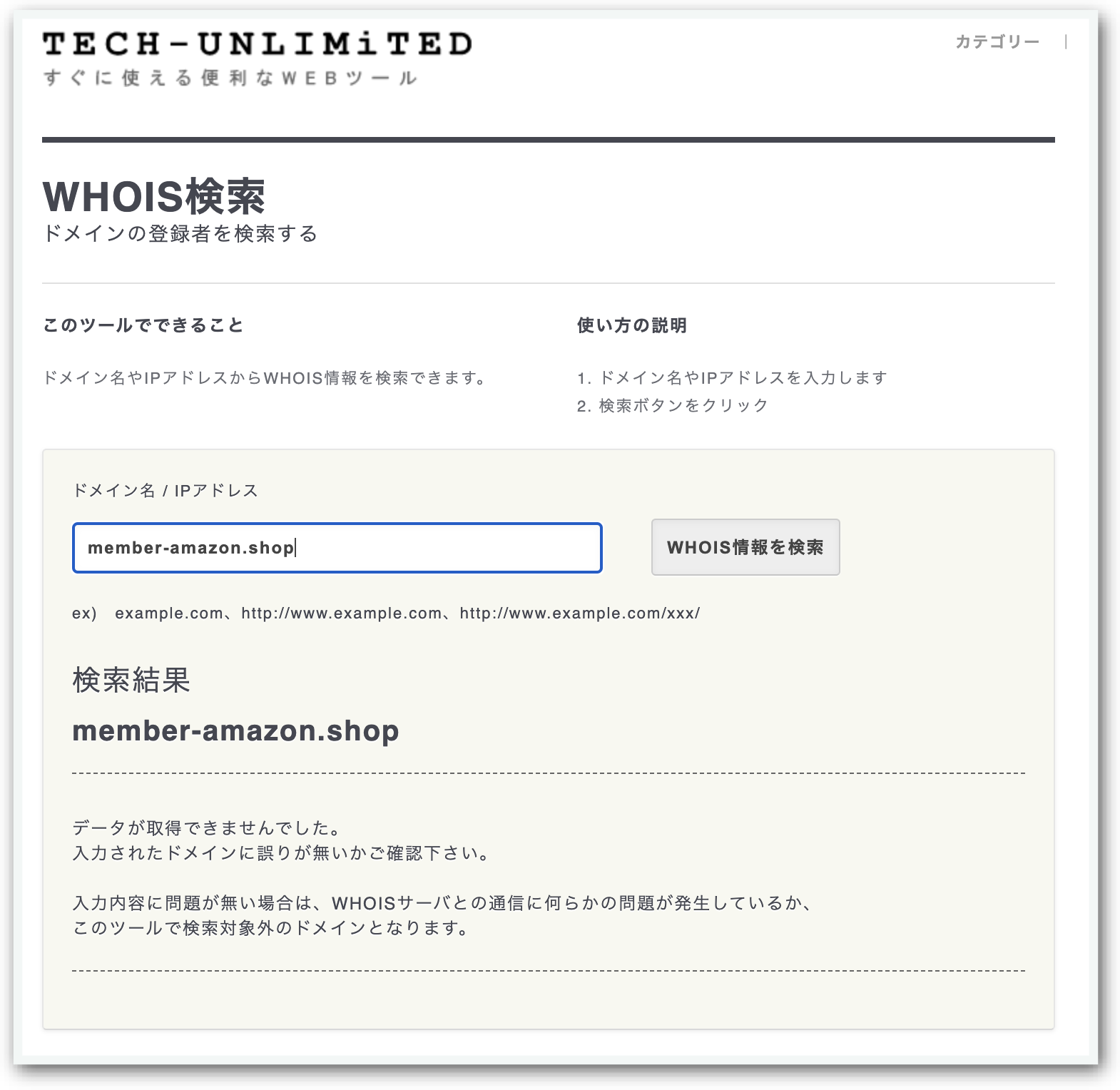
3, WHOIS検索 | ドメインの所有者情報を簡単検索 | すぐに使える便利なWEBツール | Tech-Unlimited では WHOISの内容をざっとみて、中国(.ch)やロシア(.ru)などのトップレベルドメインがないか?
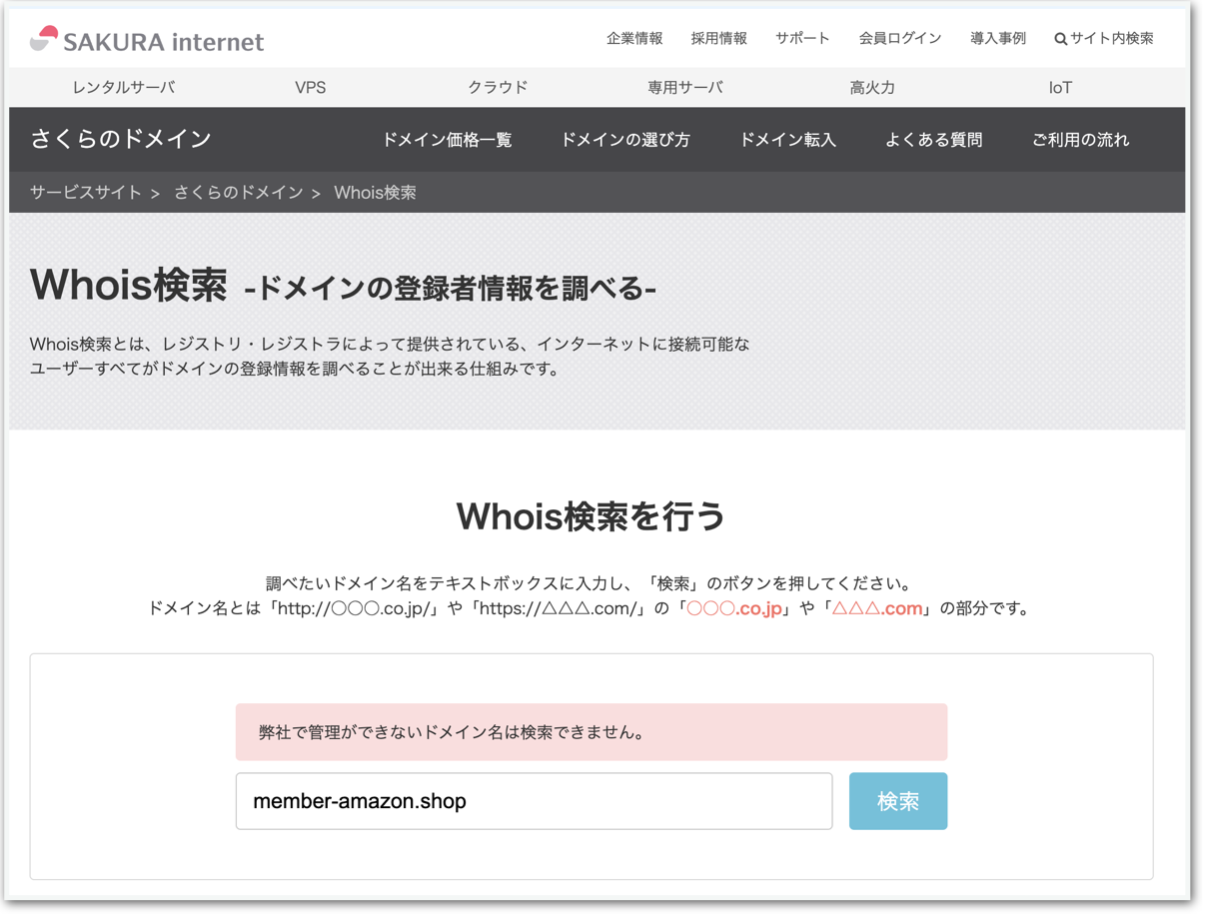
4, Whois検索 | さくらのドメインも同じ。ざっと見た感じから怪しさを感じないかを見る。
aguse.jp- ウェブ調査
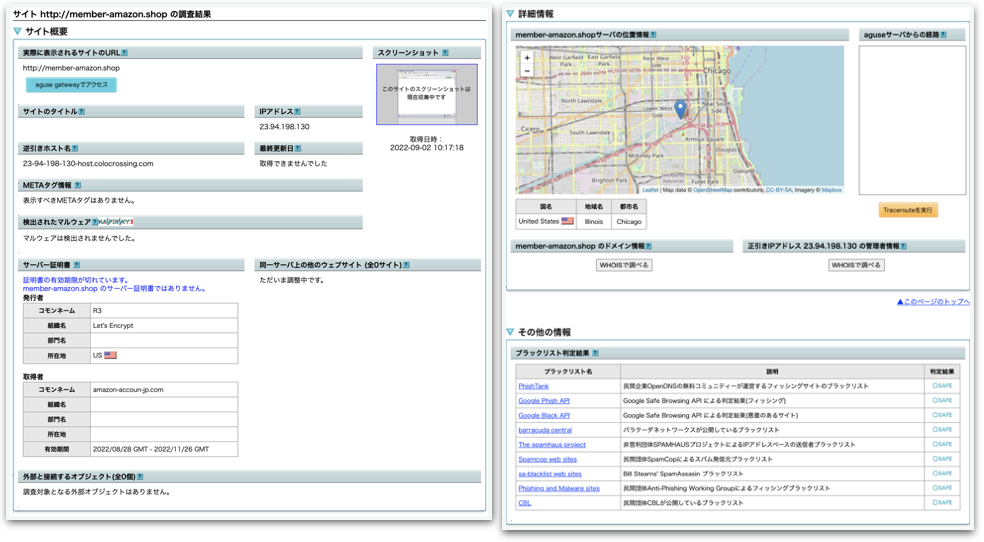
Trend Micro Site Safety Center
*「続行するには、自動入力ではないことの確認が必要です。」とポップアップが出た場合は、チェックして送信してください。(同じ内容で何回も実行すると出るようだ!)

WHOIS検索 | ドメインの所有者情報を簡単検索 | すぐに使える便利なWEBツール | Tech-Unlimited
Whois検索 | さくらのドメイン
<参考にさせてもらったサイトです・>
後書き
□Webdriver managerを使用していても、Google Chrome のバージョンをサポートしていないとメッセージが出た場合の対処方法
以下のサイトを参考にさせて頂きました。
修正記録
2023-05-12の修正内容
"Selenium.common.exceptions.StaleElementReferenceException"(要素がページのDOM構造から削除され、参照が無効になった場合に発生する一般的なエラー。)
が、出現したため「要素が見つかるまで待機するリトライメカニズム」を追加しました。
import time
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import StaleElementReferenceException
を追加するとともに
def web1(driver, option, xpath_X, url):部分のcodeにtry文を追加しました。
for _ in range(retry_attempts):
try:
--通常の操作--
break
except StaleElementReferenceException:
# ステールな要素が見つかった場合、一時的に待機してリトライする
time.sleep(retry_delay)
2023-03-07の修正内容
browser = webdriver.Chrome(options=option)は不要であった為削除
また、これに関連して def web1並びにdef web2とその関連からも変数(browser)を削除しました。
2023-03-03の修正内容
WebDriver の executable_path 使用に伴う非推奨機能に対する警告メッセージ(DeprecationWarning)回避の為の修正
# Serviceのインポート(selenium4での修正 )
以下のサイトを参考にさせて頂きました。
webdriverのselenium4での修正内容
selenium3以前
driver = webdriver.Chrome(ChromeDriverManager().install(), options=options)
selenium4以降
from selenium.webdriver.chrome.service import Service # executable_pathを指定
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=options)
2023-02-20内容修正
python3.10.0 へVersion移行とともに、各種のPacageを入れ替えた際、seleniumについて以前の3.141.0から4.8.2へ変更となりました。
これにより、
①.find_element_by_xpathの記述方法が変わったこと②GoogleChromeがProgramが立ち上がると同時にGoogleChromeがCloseする様になりました。
なお、②ついては「shobota」さんの
を参考に修正しました。
(修正内容)
■①selenium3.141.0から4.8.2へ変更に伴う修正
driver.find_element_by_xpath(xpath_X)を,
driver.find_element(By.XPATH,xpath_X)へ修正
■②GoogleChromeがProgramが立ち上がると同時にCloseする問題の修正
以下を追加
import os
import signal
try:
# ~いろいろな処理~
finally:
os.kill(driver.service.process.pid,signal.SIGTERM)
を追加
これにより、GoogleがCloseしない他に、メモリに残ったGoole関連のプロセスが、Googleを終了すると同時に、削除されるようにもなりました。
(実行直後)

(Googleを手動で終了した段階)