HttpClient使って、なーんも考えずにコード書いて、
でかいファイル(1GBとか、2GBとか、それ以上とか)をダウンロードしようとすると、
メモリ消費ひどかったり、例外出たりするので、その対策メモです。
※ 例示コードは、C#になってます。
※ 接続先とかファイルパスとか、読みやすさ重視で、あえてハードコードで例示しています。
1. なーんも考えなかったコード
private static readonly HttpClient httpClient = new HttpClient();
private async Task DownloadAsync()
{
using (var request = new HttpRequestMessage(HttpMethod.Get, new Uri("https://127.0.0.1:8443/test.dat")))
using (var response = await httpClient.SendAsync(request))
{
if (response.StatusCode == HttpStatusCode.OK)
{
using (var content = response.Content)
using (var stream = await content.ReadAsStreamAsync())
using (var fileStream = new FileStream(".\\test.dat", FileMode.Create, FileAccess.Write, FileShare.None))
{
stream.CopyTo(fileStream);
}
}
}
}
単純に、HttpRequestMessage作って、HttpClient.SendAsync(request)してるだけです。
HttpRequestMessageを使わずに、HttpClient.GetAsync(Uri)とか使っても同様です。
成功したときには、
レスポンスのストリームと、ファイルのストリームを作って、
Stream.CopyTo(Stream)で、ファイルに書き込んでいます。
(Stream.CopyToAsync(Stream)も存在しますが、
この場合は、どっちみちファイル読み込みまで待っているので、使うメリットは、ほぼないと思います。)
2. どうなるか考えたり、実測してみる
特になにも指定しない場合、
await HttpClient.SendAsync(request)とかawait HttpClient.GetAsync(Uri)とかは、
HTTPのヘッダーとBodyを全部読み取ってから結果を返します。
(実際には、Task絡みなので、上だと微妙な表現ですが、その辺は適当に汲み取ってもらえればと。)
例えば、2GB近いファイルをダウンロードしようとすると、
HttpClientの内部処理で、2GB近いメモリが利用されます。
実際には、(HTTPのヘッダー) + (HTTPのBody) + α(その他いろいろ処理に必要分)の
メモリが消費されることになります。
プロファイラで見るとこんな感じです。
ダウンロード開始直後に、2GB近いメモリが消費されています。

なお、HttpClient.MaxResponseContentプロパティ(デフォルトで2GB)を超えるサイズのファイルを読み込もうとした場合、
HttpClientの内部処理にて、HTTPレスポンスのContent-Lengthヘッダーを処理した時点で、
System.Net.Http.HttpRequestExceptionが発生します。
また、上記のプロパティのサイズを超えない場合でも、内部処理で扱うバッファの制限上、
System.OutOfMemoryExceptionが発生する場合があります。
3. 解決策と実測
対策は単純で、
『HttpClientがHTTPのヘッダーとBodyを全部読み取ってから結果を返す』
という部分の動作を変えるだけです。
オプション指定で行けます。
HttpClient.SendAsync(request)とかHttpClient.GetAsync(Uri)などには、
HttpCompletionOptionを指定できるオーバーロードがあります。
HttpCompletionOption.ResponseContentReadだと、
『HttpClientがHTTPのヘッダーとBodyを全部読み取ってから結果を返す』
になります。
HttpCompletionOption.ResponseHeadersReadだと、
『HttpClientがHTTPのヘッダーを読み取った時点で結果を返す』
になります。
でかいファイルをダウンロードする目的では、
HttpCompletionOption.ResponseHeadersReadが都合がよさそうです。
こんな感じのコードになります。
最初のコードとの違いは、1か所のみで、
var response = await httpClient.SendAsync(request, HttpCompletionOption.ResponseHeadersRead))
のように、HttpCompletionOption.ResponseHeadersReadを指定するように変更しただけです。
private static readonly HttpClient httpClient = new HttpClient();
private async Task DownloadAsync()
{
using (var request = new HttpRequestMessage(HttpMethod.Get, new Uri("https://127.0.0.1:8443/test.dat")))
using (var response = await httpClient.SendAsync(request, HttpCompletionOption.ResponseHeadersRead)))
{
if (response.StatusCode == HttpStatusCode.OK)
{
using (var content = response.Content)
using (var stream = await content.ReadAsStreamAsync())
using (var fileStream = new FileStream(".\\test.dat", FileMode.Create, FileAccess.Write, FileShare.None))
{
stream.CopyTo(fileStream);
}
}
}
}
プロファイラで見るとこんな感じです。
最初のコードを実行した場合は、2GB近いメモリが消費されていましたが、
対策版では、15MB程度になっています。
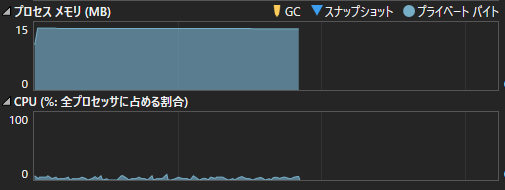
実際には、このうち、
HttpClientとかファイルのダウンロード関連の処理で必要なメモリは、数MB程度だと思います。
Stream.CopyTo(Stream)内部で使うバッファもデフォルトでは、80KB程度です。
バッファのサイズを大きく設定すると、その分、消費メモリも大きくなります。
また、対策版の場合は、
HttpClient.MaxResponseContentプロパティを超えるサイズのファイルもダウンロード可能です。