はじめに
この記事は以下のような人を対象としています。
- リアルタイム性が重視されるPyTorchの推論環境をオンプレに構築したが、AWSに移行したい人
- SageMakerでトレーニングしたPyTorchモデルをSageMakerのリアルタイム推論エンドポイントにデプロイしたい人
前提
- 推論可能なPyTorchのモデルファイル及びそれを使った推論用のPythonコードが既に手元にあること
- 開発環境でJupyter Notebookが使えること
- 開発環境でBoto3を使用するための認証情報が設定されていること
- SageMakerの操作に必要な権限が付与されていること
Amazon SageMakerとは
AWS環境上でMLパイプラインを構築できるサービスです。
機械学習モデルのトレーニングや推論に必要な環境の構築を、専用のコンピューティング環境(Amazon SageMaker MLインスタンス上で稼働するコンテナ)上でフルマネージドに行うことができます。
公式デベロッパーガイド:Amazon SageMakerとは
リアルタイム推論エンドポイントとは
SageMakerでホストできる推論環境のオプション(全4種類)の内の1つです。
低レイテンシーまたは高スループットが要求されるオンライン推論に最適なオプションです。
リアルタイム推論の他に、サーバーレス推論、非同期推論、バッチ変換というオプションが存在します。
詳細:推論オプション
PyTorchとは
オープンソースの深層学習フレームワークです。
公式ページ
PyTorchではトレーニングしたモデルのパラメータをモデルファイルとして保存することができます。
今回は推論可能なPyTorchのモデルファイルが既に手元にあることを前提としています。
今回の手順の概要
今回の手順の概要は以下です。
- モデルアーティファクトを作成しアップロードする
- SageMakerの実行ロールを作成する
- SageMakerモデルを作成する
- SageMakerエンドポイント設定を作成する
- SaegMakerエンドポイントを作成する
- 動作確認
それでは順番に見ていきます。
1. モデルアーティファクトを作成しアップロードする
モデルアーティファクトとは、SageMakerエンドポイントでモデルをホストするために、SageMakerの利用者が準備する必要のあるファイル一式(モデルファイルやPythonファイルなど)を格納した圧縮ファイル(ファイル名:model.tar.gz)のことです。
SageMakerではこのモデルアーティファクトをS3に置いて、そのURLを指定して推論エンドポイントをデプロイします。
モデルアーティファクトを使用する仕組み

上図は公式のBlackBelt資料から拝借した、SageMaker推論エンドポイントの構成要素を示す図です。
要点として、ECRから取得したコンテナイメージを使ってコンテナが立ち上がり、そのコンテナ上でS3から取得したモデルアーティファクトを展開して推論を行う、ということが押さえられればOKです。
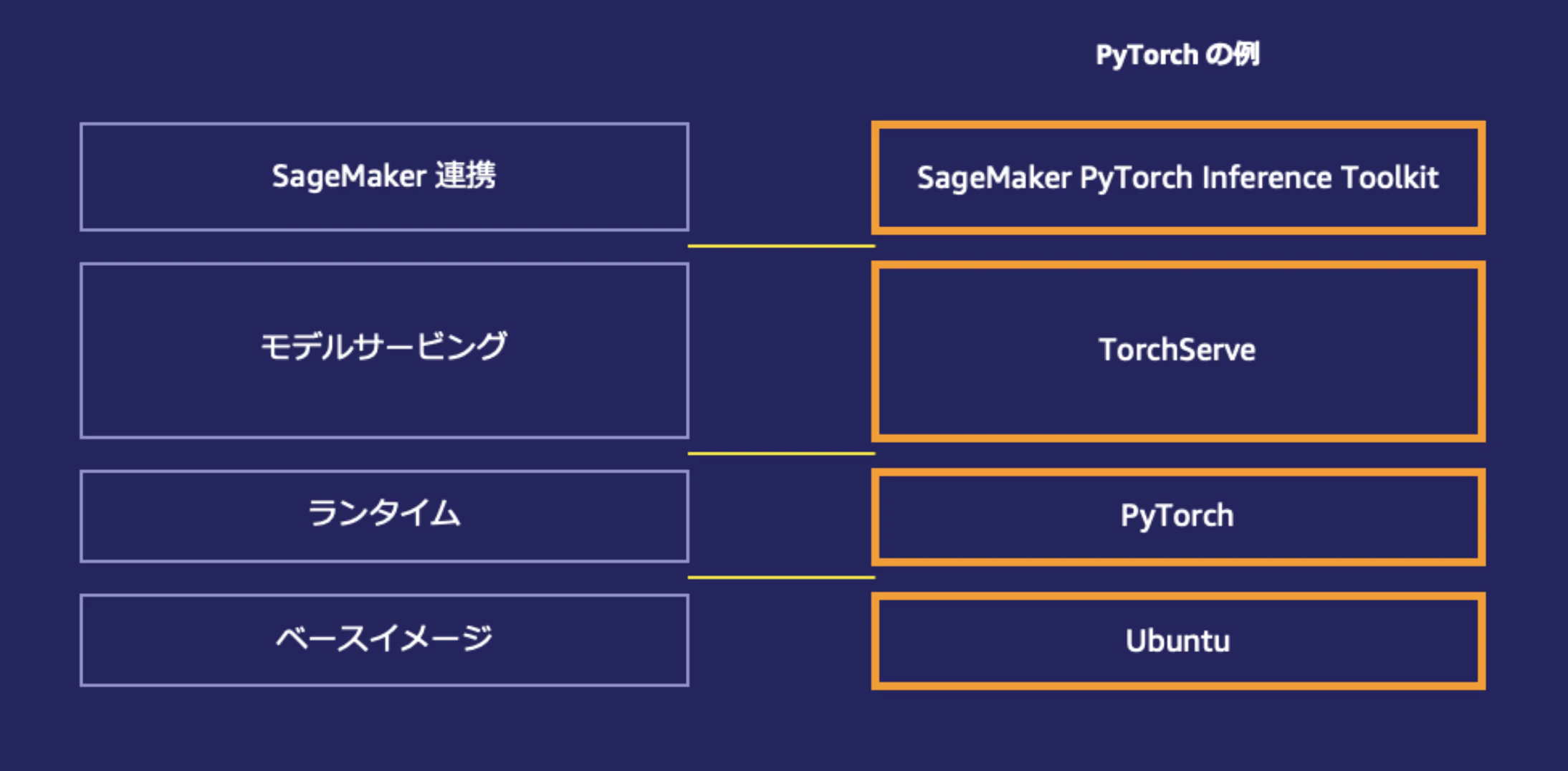
また上図は公式のブログから拝借した、SageMakerのコンテナ上でホスティングするPyTorchの推論環境のレイヤー構成を示した図です。
OS(上図の場合はUbuntu)上の各レイヤーは以下の役割を担っています。
| レイヤー | 役割 |
|---|---|
| PyTorch | 推論ランタイムのレイヤー(1回の推論を実行するのに最低限必要) |
| TorchServe | モデルサービングのレイヤー(プロセスプーリングやHTTPリクエストの終端、リクエストのルーティングなどを行う) |
| SageMaker PyTorch Inference Toolkit | SageMakerと連携するレイヤー(SageMakerのコントロールプレーンから送信されるヘルスチェックへの応答や、入出力データのserialize/deserialize、コンテナ起動時・終了時の処理などを行う) |
SageMaker PyTorch Inference Toolkit(実体はPythonパッケージ)内で、モデルアーティファクトに格納したモデルファイルやPythonファイルが呼び出される、ということが押さえられればOKです。
モデルアーティファクトのディレクトリ構成
PyTorchのモデルアーティファクトの最小限のディレクトリ構成は以下です。
model.tar.gz/
|- モデルファイル
|- code/
|- inference.py
|- requirements.txt
複数のモデルファイルやPythonファイルを使用する場合は、以下のように並列にファイルを配置します。
model.tar.gz/
|- モデルファイル1
|- モデルファイル2
|- code/
|- inference.py
|- hoge.py
|- fuga.py
|- requirements.txt
中身を1つずつ見ていきます。
モデルファイル
今回使うPyTorchのモデルファイルです。
PyTorchのモデルファイルにはどんな拡張子でも付けることができますが、一般的には.ptか.pthを使うことが多いようです(ソース)。
inference.py
モデルファイルを読み込んで推論するためのPythonファイルです。
inference.pyには以下の4つの関数を必ず定義する必要があり、関数内の処理も自前で実装する必要があります。
| 関数名 | 引数 | 説明 |
|---|---|---|
| model_fn() | 第1引数:モデルディレクトリのパス、第2引数:追加情報(オプション) | モデルアーティファクトに含めたモデルファイルを読み込む関数 |
| input_fn() | 第1引数:リクエストデータのボディ、第2引数:リクエストデータのMIMEタイプ、第3引数:追加情報(オプション) | クライアントが送信したリクエストデータを取得し、推論で利用できる形式に変換する関数 |
| predict_fn() | 第1引数:input_fn()でreturnしたオブジェクト、第2引数:model_fn()でreturnしたオブジェクト、第3引数:追加情報(オプション) | 推論を行う関数 |
| output_fn() | 第1引数:predict_fn()でreturnしたオブジェクト、第2引数:レスポンスデータのMIMEタイプ、第3引数:追加情報(オプション) | レスポンスデータのMIMEタイプに従って推論結果を変換し、クライアントに返す関数 |
各関数の実行タイミング
推論エンドポイントをデプロイ後の初回の推論リクエスト処理時のみ、model_fn()→input_fn()→predict_fn()→output_fn()の順で実行されます。
それ以降の推論リクエスト処理時は、input_fn()→predict_fn()→output_fn()の順で実行されます。
inference.pyの実装例
以下は.wavのデータを入力とし.jsonのデータを出力とする場合の例です。
<>部分やMIMEタイプは適宜書き換えてください。
import json
import os
import torch
def model_fn(model_dir):
# model_dir: SageMakerのコンテナ上の、モデルファイルが設置されるディレクトリのパス
model = <使用するPyTorchのモデルのインスタンスを生成する>
# モデルファイルに保存されたパラメータをモデルのインスタンスに読み込む
params = torch.load(os.path.join(model_dir, 'モデルファイル名'), map_location='cpu')
model.load_state_dict(params)
# model_fn()の戻り値の型は明確に定義されていない
# ここでreturnした値がpredict_fn()の第2引数に渡される
return model
def input_fn(request_body, request_content_type):
# request_body: クライアントが指定したリクエストデータのボディ
# request_content_type: クライアントが指定したリクエストデータのMIMEタイプ
# 適宜入力チェックを行う
if request_content_type != 'audio/wav':
# 例外をraiseすると、クライアントには500エラーが返る
raise ValueError('Content type must be audio/wav!')
# 一時ファイル置き場が必要な場合は、'/home/model-server/tmp'を使用する
file_path = os.path.join('/home/model-server/tmp', 'request_body.wav')
with open(file_path, 'wb') as f:
f.write(request_body)
input_data = <入力データを必要に応じて前処理する>
# input_fn()の戻り値の型は明確に定義されていない
# ここでreturnした値がpredict_fn()の第1引数に渡される
return input_data
def predict_fn(input_data, model):
# input_data: input_fn()でreturnした値
# model: model_fn()でreturnした値
prediction = <modelにinput_dataを入力して推論する>
# predict_fn()の戻り値の型は明確に定義されていない
# ここでreturnした値がoutput_fn()の第1引数に渡される
return prediction
def output_fn(prediction, response_content_type):
# prediction: predict_fn()でreturnした値
# response_content_type: クライアントが指定したレスポンスデータのMIMEタイプ
output_data = <predictionを必要に応じて後処理する>
# output_fn()の戻り値の型は明確に定義されていない
# 以下のようにreturnすることで、response_content_typeの型でレスポンスとして返る
return json.dumps(output_data), response_content_type
requirements.txt
推論に必要なパッケージを指定するファイルです。
推論環境で用いるコンテナイメージは、AWSが提供しているAWS Deep Learning Containersを使うことができます(必要に応じて拡張したり、独自に準備したコンテナを用いることも可能、後述します)。
このコンテナ環境には、推論で必要になりそうな大抵のPythonパッケージがあらかじめインストールされています。そこには含まれないPythonパッケージをinference.pyやその他のPythonコード内で使いたい場合は、requirements.txtに記載します。
コンテナ環境にあらかじめインストールされるパッケージを確認したい場合は、AWS Deep Learning ContainersのPyTorch推論用のDockerFileを参照します。
モデルアーティファクトを作成する
以下はLinux/Unixな環境の場合の例です。
例えば現在以下のようなディレクトリ構成なら、
model
|- モデルファイル
|- code/
|- inference.py
|- requirements.txt
以下のコマンドを実行します。
# モデルアーティファクトのルートディレクトリに移動する
cd model
# model.tar.gzという名前で圧縮する
tar zcvf model.tar.gz ./*
モデルアーティファクトをS3にアップロードする
適当な名前のS3バケットを作成して、モデルアーティファクト(ファイル名:model.tar.gz)をアップロードします。
アップロードしたオブジェクトのURLはデプロイ時に使用します。
2. SageMakerの実行ロールを作成する
こちらのページを参考にSageMakerの実行ロールを作成します。
作成したIAMロールのARNはデプロイ時に使用します。
3. SageMakerモデルを作成する
ここから先はBoto3(AWSのPython SDK)を使ってAWSを操作します。
SageMaker Python SDKというSageMaker専用のPython SDK(実体はBoto3のラッパー)でも同じ操作が可能ですが、より本質的に理解するために今回はBoto3を使います。
以下のPythonコードをJupyter Notebookのセルにコピペして実行し、SageMakerモデルを作成します。
import boto3
from sagemaker import image_uris
# リアルタイム推論エンドポイントを立てるリージョン
aws_region='ap-northeast-1'
# インスタンスタイプ
instance_type = 'ml.g4dn.xlarge'
# 推論環境で使用するコンテナイメージのイメージURIを取得する
container = image_uris.retrieve(
region=aws_region,
framework='pytorch', # 機械学習フレームワーク
version='1.12.1', # 機械学習フレームワークのバージョン
image_scope='inference', # 推論用(inference) or 学習用(training)
instance_type=instance_type,
py_version='py38' # Pythonバージョン
)
# Boto3のSageMakerクライアントを取得する
sagemaker_client = boto3.client('sagemaker', region_name=aws_region)
# 作成するSageMakerモデルの名前(任意)
model_name = 'pytorch-predictor-model'
# SageMakerモデルを作成する
create_model_response = sagemaker_client.create_model(
ModelName = model_name,
ExecutionRoleArn = '<SageMakerの実行ロールのARN>',
PrimaryContainer = {
'Image': container,
'ModelDataUrl': '<S3にアップロードしたモデルアーティファクトのURL>',
}
)
数秒でSageMakerモデルが作成されます。
4. SageMakerエンドポイント設定を作成する
以下のPythonコードをJupyter Notebookのセルにコピペして実行し、SageMakerエンドポイント設定を作成します。
# 作成するSageMakerエンドポイント設定の名前(任意)
endpoint_config_name = 'pytorch-predictor-endpoint-config'
# SageMakerエンドポイント設定を作成する
sagemaker_client.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=[
{
'VariantName': 'variant1', # 実稼働バリアントの名前(任意)
'ModelName': model_name,
'InstanceType': instance_type,
'InitialInstanceCount': 1 # 初期のインスタンス数
}
]
)
数秒でSageMakerエンドポイント設定が作成されます。

5. SageMakerエンドポイントを作成する
以下のPythonコードをJupyter Notebookのセルにコピペして実行し、SageMakerエンドポイントを作成します。
# 作成するSageMakerエンドポイントの名前(任意)
endpoint_name = 'pytorch-predictor-endpoint'
# SageMakerエンドポイントを作成する
create_endpoint_response = sagemaker_client.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name
)
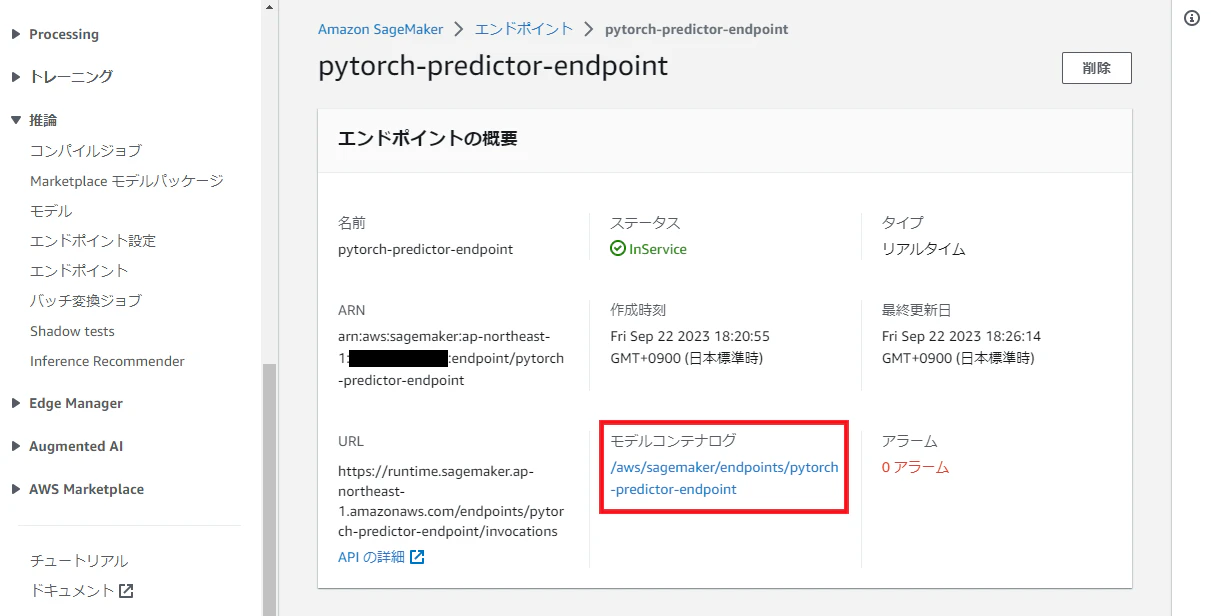
SageMakerエンドポイントの作成には数分かかります。
以下のようにステータスが「InService」になったら作成完了です。

エンドポイントの作成によりコンテナ環境が起動するので、CloudWatchのログが確認できるようになります。
コンテナ環境の起動時にPythonパッケージがインストールされたことがわかります。
6. 動作確認
以下は.wavのデータを入力とし.jsonのデータを出力とする場合の例です。
MIMEタイプは適宜書き換えてください。
以下のPythonコードをJupyter Notebookのセルにコピペして実行し、動作確認します。
import json
# Boto3のSageMakerランタイムクライアントを取得する
sagemaker_runtime_client = boto3.client('sagemaker-runtime')
# ローカルにある音声ファイルをバイナリデータに変換する
with open('test.wav', 'rb') as file:
fileDataBinary = file.read()
# 推論エンドポイントを呼び出す
response = sagemaker_runtime_client.invoke_endpoint(
EndpointName=endpoint_name, # SageMakerエンドポイントの名前
ContentType='audio/wav', # リクエストデータのMIMEタイプ、input_fn()の第2引数に渡される
Body=fileDataBinary, # リクエストデータのボディ、input_fn()の第1引数に渡される
Accept='application/json' # レスポンスデータのMIMEタイプ、output_fn()の第2引数に渡される
)
# 推論結果がJSONで返ってくることを確認する
result = json.loads(response['Body'].read().decode())
print(result)
このとき、inference.py内でprint()したものはCloudWatchのログに出力されます。
その他
推論環境のコンテナ内にアクセスする
AWS System Manager経由で推論環境のコンテナにアクセスすることができます。
これにより、コンテナへのシェルレベルのアクセスが可能になり、コンテナ内で実行されているプロセスをデバッグしたり、CloudWatchでコマンドや応答を記録したりできます。
この機能を利用するには、カスタマーサポートに連絡して、アカウントをホワイトリストに登録する必要があります。
カスタムコンテナの実装
推論環境で用いるコンテナイメージはAWS Deep Learning Containersで用意されているものが使えますが、それを必要に応じて拡張したり、代わりに独自で準備したコンテナを用いることも可能です。
AWS Deep Learning ContainersのPyTorch推論用のDockerFileを取得することで、コンテナイメージの拡張が可能です。
詳細:Amazon SageMaker におけるカスタムコンテナ実装パターン詳説 〜推論編〜