はじめに
Deep Learning 初心者が、 YOLOv5 の環境構築をしていてつまったポイントと、その解決方法をまとめました。
YOLOv5 とは
物体の位置と種類を検出する機械学習アルゴリズムです。
既に学習済みのモデルを使って物体検出したり、一からモデルに学習させたりすることができます。
GitHubで公開されています。
環境構築でつまったところ
今回は少し古めのバージョン4.0で環境を構築しました(最新はバージョン6.1)。
当方のPC環境は Windows10 で、 RTX3080 Ti を積んでいます。
Linuxな環境(WSL等)は使わずに、コマンドプロンプトのみで構築しました。
pip install -U -r requirements.txt 実行時に ERROR: Could not build wheels for pycocotools, which is required to install pyproject.toml-based projects と言われる
pipコマンドを使ってインストールする際、途中でC/C++でのコンパイルが必要になります。
しかし、利用中のWindows環境には必要なバージョンのコンパイラがないので、このエラーが出ています。
ダウンロードページから Microsoft Visual C++ vs_buildtools をインストールし、pip install -U -r requirements.txtを再実行することで解決しました。
detect.py 実行時に AttributeError: Can't get attribute 'SPPF' on <module 'models.common' from '~\\yolov5\\models\\common.py'> と言われる
detect.py の初回実行時に、検出に使用する学習済みモデル(.pt)を指定しなかった場合、その時点での最新の学習済みモデルがダウンロードされ使用されます。
その際、今回構築した v4.0 の環境と v6.1 の最新のモデルで、何かしらの整合性が取れていないのだと思われます。
v4.0 のリリースノートから v4.0 時点の学習済みモデルをダウンロードして、差し替えることで解決しました。
train.py 実行時にUnicodeDecodeError: 'cp932' codec can't decode byte 0x99 in position 78: illegal multibyte sequenceと言われる
Windows は str型(UTF-8)を byte型(cp932)に勝手に変換しようとしますが、何らかの理由で変換できないため UnicodeDecodeError が発生しています。
私の場合は、現在使用している Python のデフォルトエンコーディングを UTF-8 にしたら解決しました。
参考: Windows 上の Python で UTF-8 をデフォルトにする
学習や物体検出がGPU動作ではなくCPU動作になってしまう
- YOLOv5のプログラムが GPU or CPU のどちらで動作しているか
- 使用している pytorch のバージョン
は、detect.py や train.py を実行した時のログで確認できます ↓
ここにGPUの名前が出てこない場合は、使用する GPU と pytorch、Driver、CUDA、CuDNN のバージョンを合わせる必要があります。
yolov5>python train.py --data data.yaml --cfg yolov5m.yaml --weights '' --epochs 100
Using torch 1.10.2+cu113 CUDA:0 (NVIDIA GeForce RTX 3080 Ti, 12287.5MB)
以下を参考に、バージョンが合ってないものをインストールし直します。
Pytorch – GPU と対応するドライバ、CUDA、CuDNN のバージョン
バージョンを合わせたら、CUDA と CuDNN の PATHが通っていることを確認します。
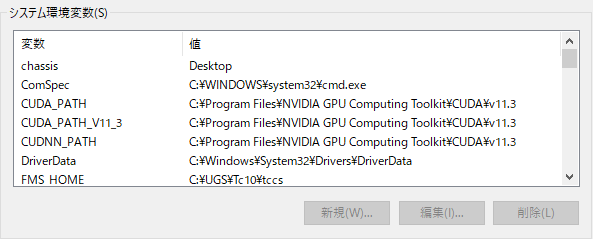
システム環境変数がこんな感じになっていたらOKです。
train.py 実行時に OSError: [WinError 1455] ページング ファイルが小さすぎるため、この操作を完了できません。 と言われる
仮想メモリサイズを増やしたら解決しました。
参考: 仮想メモリのサイズを変更する方法 | ドスパラ サポートFAQ よくあるご質問|お客様の「困った」や「知りたい」にお応えします。
仮想メモリが大きければ学習のスピードは上がりますが、その分ストレージを圧迫するのでバランスを考える必要があります。