概要
BERTのような事前に学習された言語表現モデルは、大規模なコーパスから一般的な言語表現を取得するが、ドメイン固有の知識はない。専門家はテキストを読む際に、関連する知識を用いて推論を行う。この機能を実現するために、我々は知識グラフ(KG)を用いた知識対応型言語表現モデル(K-BERT)を提案し、文の中にドメイン知識としてトリプルを注入する。しかし、知識を入れすぎると文の意味がずれてしまうことがあり、これを知識ノイズ(KN)問題と呼ぶ。KNを克服するために、K-BERTは、知識の影響を制限するために、softpositionと可視行列を導入している。K-BERTは、事前学習済みのBERTからモデルパラメータを読み込むことができるため、自ら事前学習せずにKGを搭載することで、容易にモデルへのドメイン知識の注入が可能である。我々の調査では、12の自然言語処理タスクにおいて有望な結果が得られている。特にドメイン固有タスク(金融、法律、医学など)において、K-BERTはBERTを大幅に上回り、専門家を必要とする知識駆動型問題の解決にK-BERTが優れていることが実証された。
アーキテクチャ

Knowledge layer
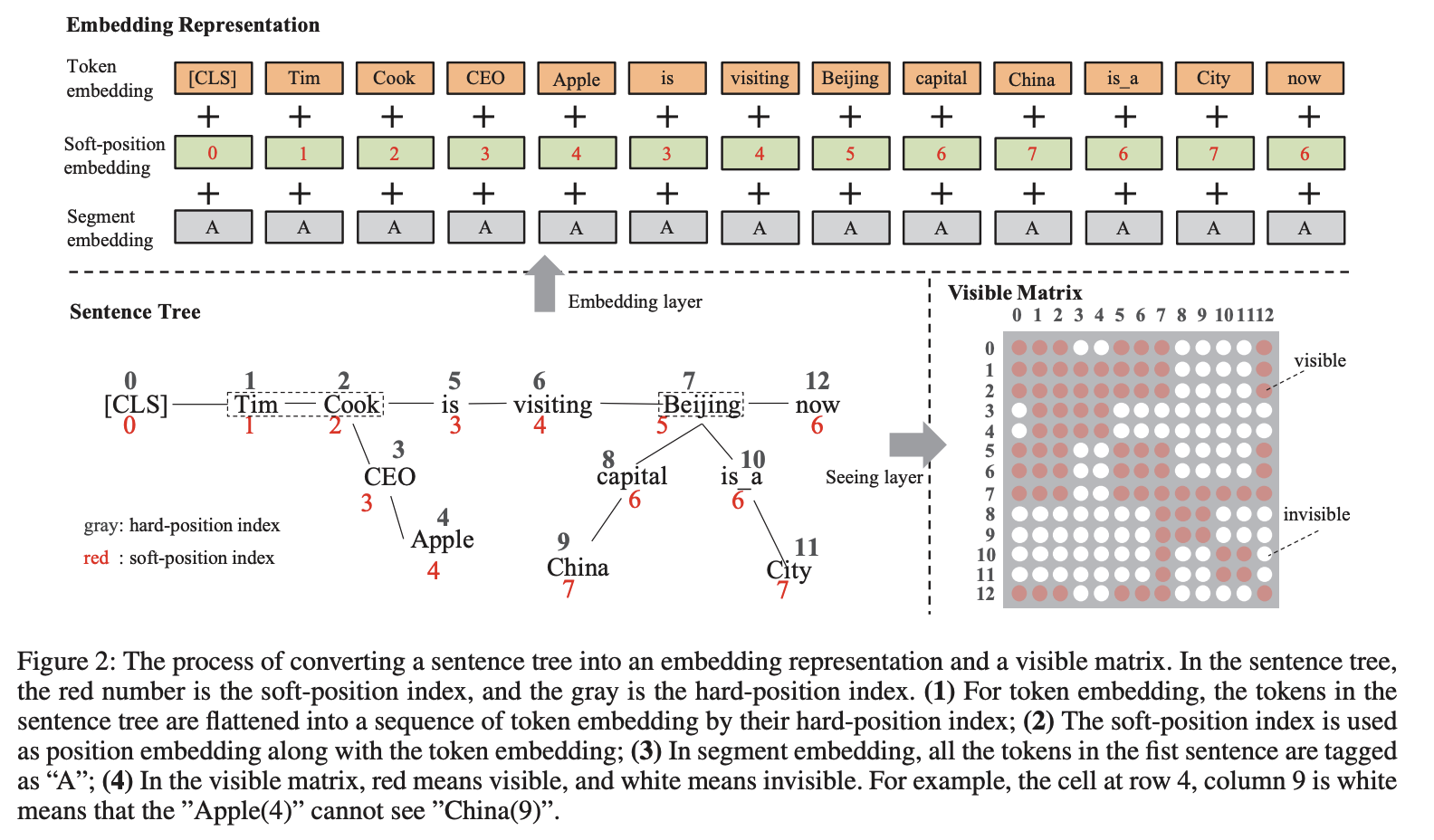
知識グラフをもとにセンテンス木に変換する。Figure 1の例では、Tim CookとBeijingについての知識が知識グラフから得られる。
Embedding layer
Soft-position embedding
センテンス木はFigure 2のようにトークンの後ろに情報をくっつける形でトークン化する。しかし、このままでは文がおかしくなってしまう(これをKnowledge Noiseと呼ぶ)。そこで、position embeddingに工夫をして、センテンス木が分岐した地点でposition embeddingの番号も分岐するように設定する。
Seeing layer
Figure 2の左下の図において、ChinaとAppleはまったく関係がない。そこで、Self-attentionを行う際に右下のように関係のないトークンは見えないようにマスクをかけて学習を行うようにする。
Mask-Transformer Encoder

Figure 4のように分岐した部分から[CLS]に直接的に情報が伝わらないようにする。元の文に影響を与えないようにすることがモチベーション。
実験
Pre-training corpora
・WikiZh
・WebtextZh
Knowledge graph
・CN-DBpedia
・HowNet
・MedicalKG
Baselines
・BERT [Devlin et al., 2018]
・Our BERT:筆者が再度学習したもの
Open-domain tasks
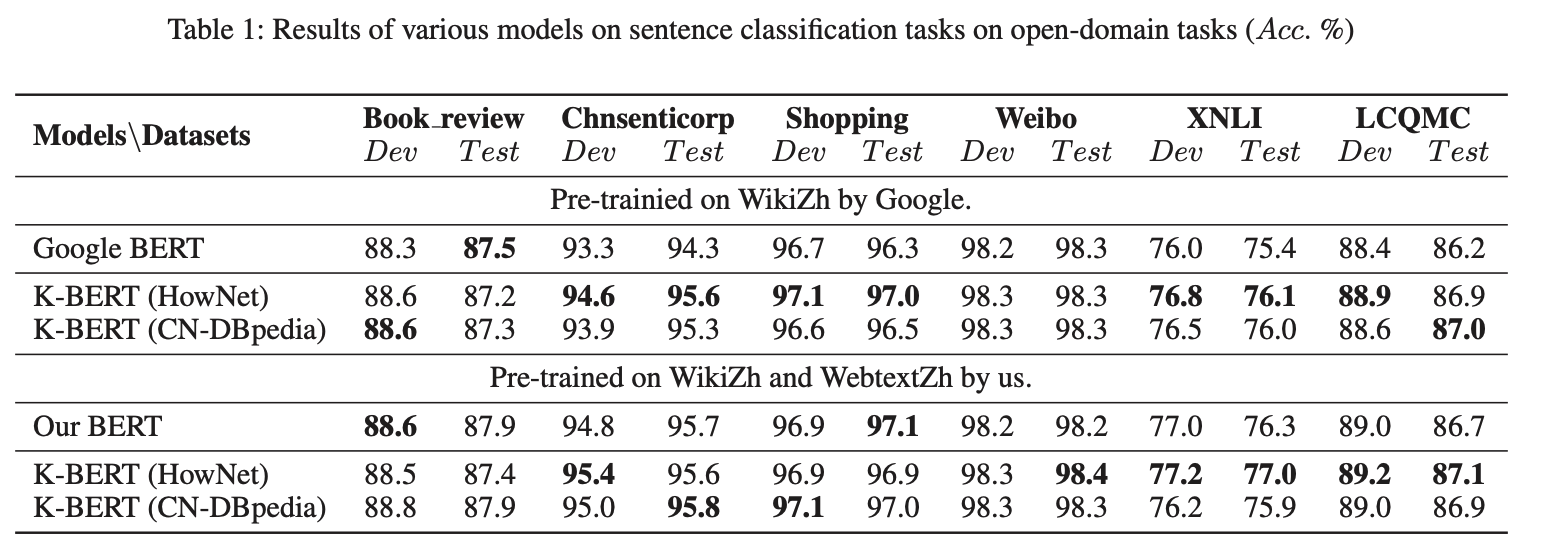
提案法とBERTを8つの中国語のopen-domain NLP tasksで実験した。
シングルセンテンスの分類問題
・Book_review:positive,negativeのレビュー
・Chnsenticorp:positive,negativeのホテルレビュー
・Shopping:positive,negativeのオンラインショッピングレビュー
・Weibo:positive,negativeのWeiboレビュー
2センテンス分類
・XNLI
・LCQMC
Q&A マッチングタスク
・NLPCC-DBQA
固有表現抽出
・MSRA-NER
Specific-domain tasks
特定のドメイン知識が必要な時に提案法は有効だと考えられる。次のような法律や金融などの特定ドメインのタスクで精度を調べる。
・Finance Q&A (質問応答選択)
・Law Q&A (質問応答選択)
・Finance NER
・Medicine NER
