はじめに
2021年にOpenAIによって公開された、テキストを画像に変換する「DALL-E」についてまとめました。
生成した画像
「バレリーナの衣装を着て、犬の散歩をする赤ちゃん大根」の画像です。データセットにない画像も生成できるのが強みのようです。

GANを用いた既存手法と比較しても生成画像の精度の高さが分かります。

要約
テキストから画像を生成する従来の研究は、以下のような問題がありました。
- ドメイン特化のデータセットを利用
- 複雑なアーキテクチャになりがち
- セグメントマスクや物体ラベルなどの副次的な情報が必要
本研究では、テキストと画像のトークンを単一のデータストリームとして自己回帰的にTransformerで学習することで、シンプルなアーキテクチャながらも既存法に匹敵する精度を出しました。
結論
- ドメイン特化の手法と比較したり、単一の生成モデルとしての能力を調べると、いい精度でした
- パラメータ数を増やすとさらに精度が上がります
アーキテクチャ
モデル
Sparse Transformerを利用しています。これは、通常のTransformerに対してマスクをかけて自己回帰的に学習するよりもメモリにやさしい手法です。
データセット
COCOなどのデータセットに加え、2.5億のtext-imageペアをインターネットから収集して学習させました。
学習方法
ピクセルを一列に入力するのは、高解像度画像の場合メモリオーバーになってしまうため、2段階の学習を行うことで解決しました。
- discrete variational autoencoder (dVAE) を用いて256×256のRGB画像を32×32=1,024に圧縮し、画像vocabulary(コードブック)を8,192とします。離散VAEについてはこちらが分かりやすいです。
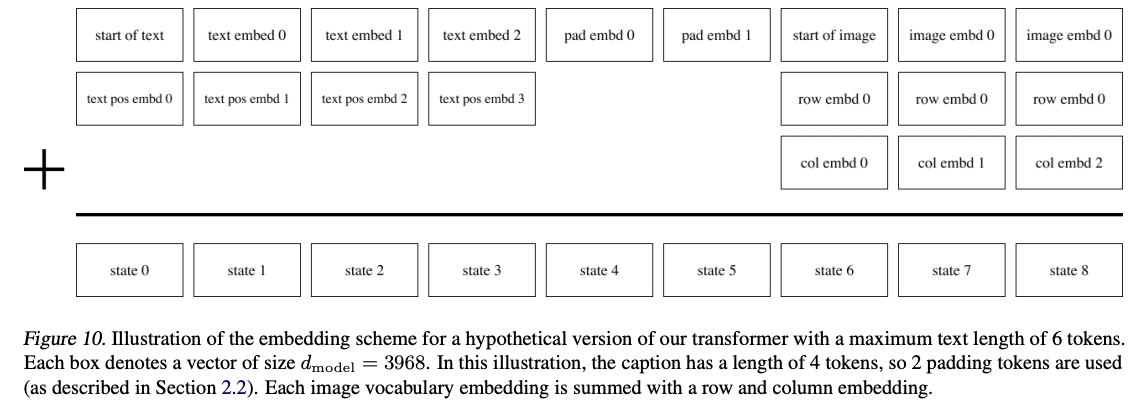
- 256個のテキストトークンと、1,024個の画像トークンを結合して、joint distribution (テキストのvocabulary: 16,384、画像のvocabulary: 8192) から自己再帰的学習を行います。単語embeddingも画像embeddingもサイズは3,968とします。
その他、attention layerは64層で、attention headは62個としています。
また、position embeddingは以下のように足し合わせています。