Scaling Laws for Neural Language Models
[Kaplan+, 2020] (OpenAI)
Transformer機構を用いた言語モデルの性能は、パラメータ数N・データセットサイズD・計算予算Cを変数とした冪乗則に従うという法則が示されました。
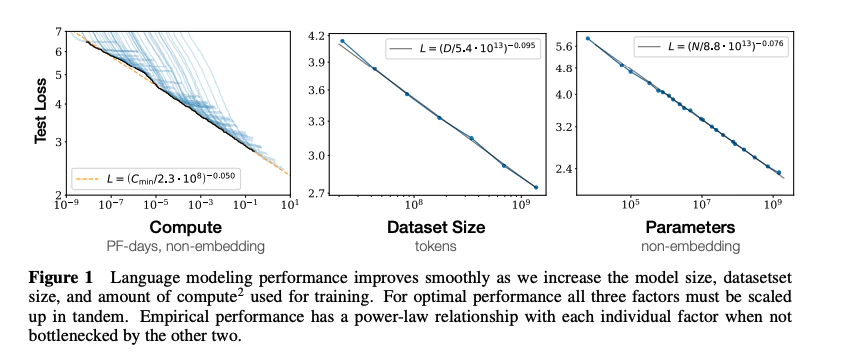
例えば上図の左のグラフは、データセットモデルパラメーターのサイズがボトルネックになっていない場合 (自由にサイズを増やし続けられる場合)に、計算予算を変化させたときのTest Lossの推移です。
PF-daysは、AIの計算に使われる単位の一つです。1 PF-dayは、$10^{15}$回(ペタフロップ)の演算を1秒間に行うコンピュータノードが1日間稼働したときの計算量を表します。
例えば、1750億パラメーターのGPT-3は、3640 PF-dayかかって訓練されました。
Training Compute-Optimal Large Language Models
[Hoffmann+, 2022] (DeepMind)
この論文は、与えられた計算予算の下で、Transformer言語モデルの最適なモデルサイズと学習トークン数のトレードオフを最適化したものです。
実験的に、70M以下から16B以上のパラメータ、5Bから400B以上のトークンで学習させた400以上のモデルの損失に基づいて、最適なモデルサイズと学習トークン数を推定しました。
Gopher (280B) と同じ計算予算で、70Bのパラメータと4倍以上の訓練データで学習させたChinchillaモデルは、Gopherを上回る精度を示しました。
3つのアプローチを提案しています。
アプローチ1
一定のモデル群(パラメータ数70Mから10B以上)に対して、学習ステップ数を変化させ、各モデルを4種類の学習シーケンス数で学習させました。
これらの実行から、与えられた学習FLOP数で達成される最小損失の推定値を直接抽出することができます。
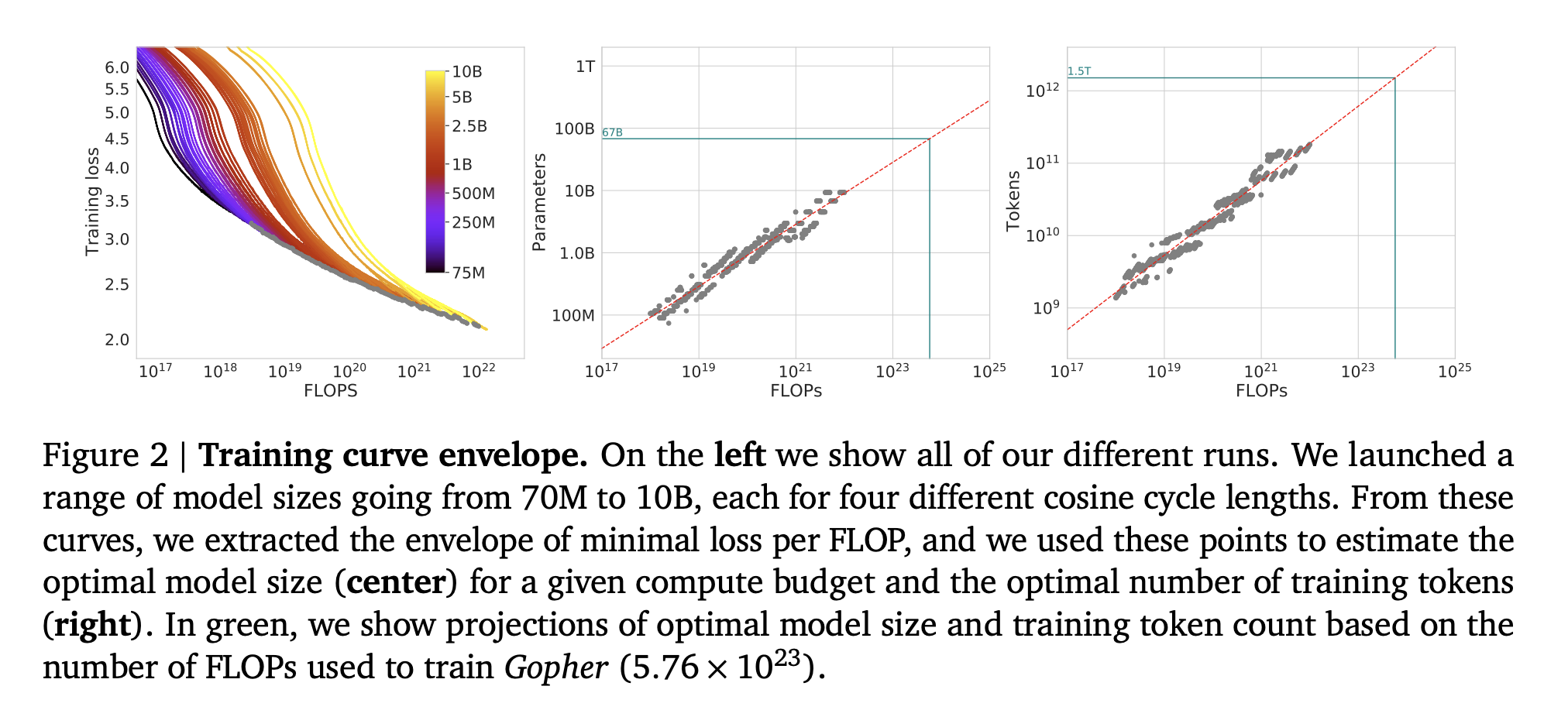
Figure 2 の左はモデルサイズを変えたときの訓練損失カーブを表しています。
このうち訓練損失が最小となる灰色の点に対応するパラメータ数とトークン数を真ん中と右の図に示しています。
アプローチ2
学習FLOP数を固定(9パターン)し、モデルサイズを変化させたときの訓練損失カーブを調べます。
損失カーブの谷となるモデルサイズを取り出し、対応するトークン数を取得します。
FLOP一定のときにモデルサイズが大きくなると、訓練できるトークン数が少なるため、このようなカーブを描きます。

アプローチ3
アプローチ1と2の実験からのすべての最終的な損失を、モデルパラメータ数と確認したトークンの数のパラメトリック関数としてモデル化します。

結果
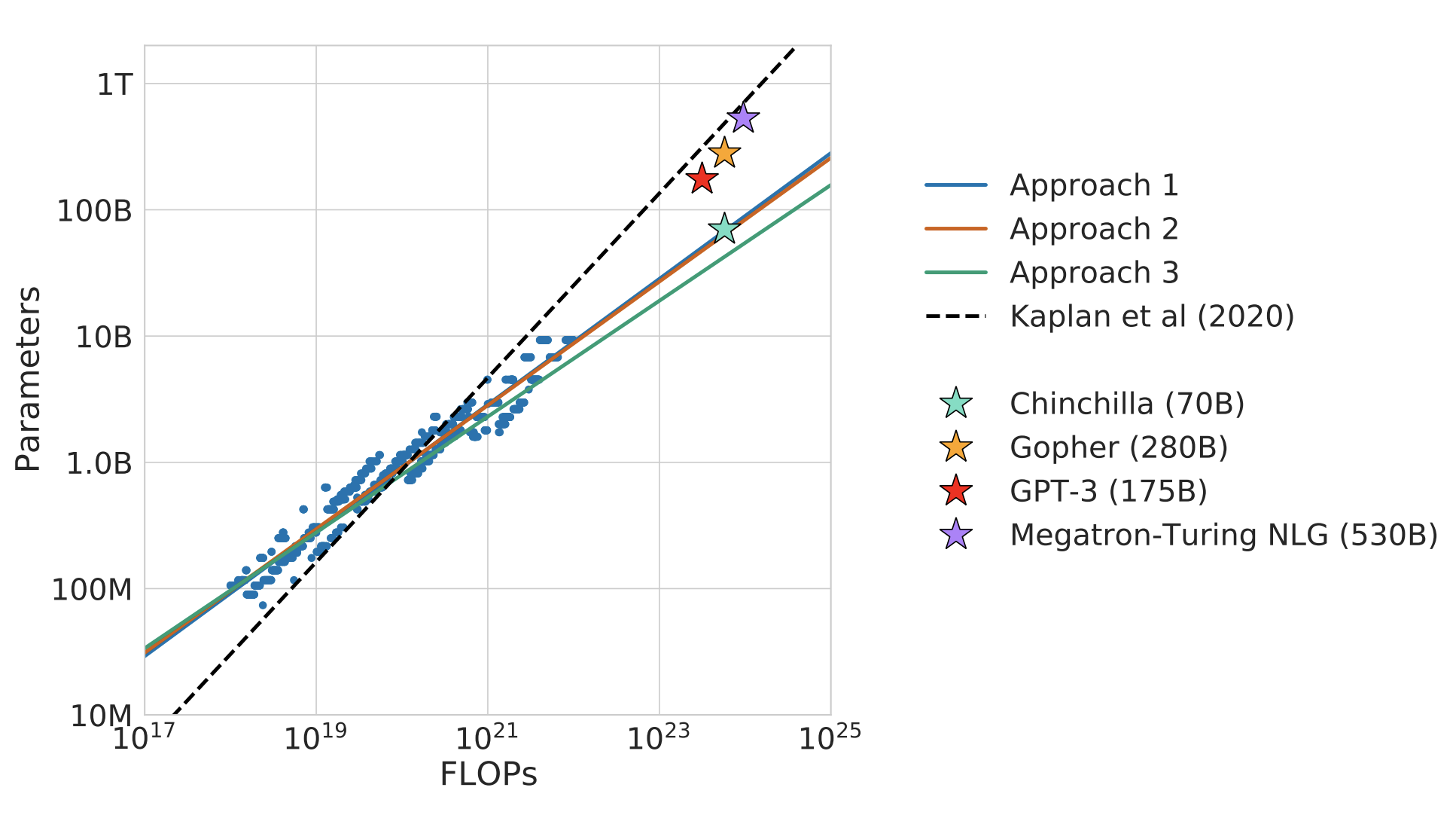
提案法で最適なモデルパラメータ数と学習トークン数を特定して学習させたChinchillaは、同じFLOPsで他手法と比較したときに少ないパラメータ数を実現していることがわかります。(データ数は他の手法の4倍くらいです)
なお、点線は300億トークンに固定してモデルサイズを大きくしていった既存研究です。

また、様々なタスクにおいて既存法のGopherよりも高い精度となっています。
これは、同じFLOPsでモデルパラメータ数と学習トークン数のバランスを最適化した提案法の有効性を示しています。
学習トークン数がこれより多くなるとFLOPs一定の制約によりモデルパラメータ数を小さくする必要があり、トータルでは精度が下がります。
また、学習トークン数がこれより少なくなると、Gopherのようにパラメータ数は大きくできますが、トータルでは精度が下がります。
議論
学習には300Bトークンが広く使われますが、これまでは300Bトークンを固定としてモデルサイズを大きくし続けていました。
このアプローチはある一定のモデルサイズまでは有効ですが、それ以上のモデルサイズでは精度の伸びが鈍化してしまいます(べき乗則に従わなくなります)。
そこで、提案法により適切なモデルサイズを得ることが可能になります。
なお、学習はすべて1エポック未満のデータで行われたものです。
そのため、数エポックの学習の影響については今後の課題となります。