概要
本論文では、最先端の文埋め込みを大きく前進させる、シンプルな対照学習のフレームワークであるSimCSEを紹介する。まず教師なしアプローチを説明する。これは入力文を受け取り、標準的なドロップアウトのみをノイズとして用い、対照的な目的でそれ自身を予測するものである。この単純な方法は驚くほどよく機能し、これまでの教師ありの対応策と同等の性能を発揮する。我々は、ドロップアウトが最小限のデータ補強として働き、それを除去すると表現が崩壊することを見出した。次に、自然言語推論データセットから注釈されたペアを対照学習フレームワークに組み込み、「含意」ペアをポジティブ、「矛盾」ペアをハードネガティブとして使用する教師ありアプローチを提案する。その結果、BERTbaseを用いた教師なしモデルと教師ありモデルで、それぞれ平均76.3%と81.6%のスピアマン相関を達成し、これまでの最高値と比較して4.2%と2.2%の改善を示した。また、対照学習は、事前に学習した埋め込みの異方性空間をより均一化し、教師あり信号が利用可能な場合に正対をより良く揃えることを理論的、経験的に示している.
図表の詳細

(a): contrastive learning (近づけたい2つのベクトルペアのコサイン類似度を大きく,それ以外のペアのコサイン類似度を小さくするような学習手法) を用いる.同じ文に対して別々のdropoutをかけて出てきたベクトル類似度を大きく,他の文とのベクトル類似度を小さくするように学習を行う.
(b): 2文の [含意, 中立, 矛盾] を判定するタスク (NLI) を応用して文ベクトルを得る.最近は優れた文ベクトル (ちゃんと意味的に似た文ベクトルのコサイン類似度が大きく,そうでなければ小さくなる)を得る効果的な方法としてNLIがよく使われる.(Conneau et al., 2017; Reimers and Gurevych, 2019).含意ラベルがpositive,矛盾ラベルがnegativeとして学習される.

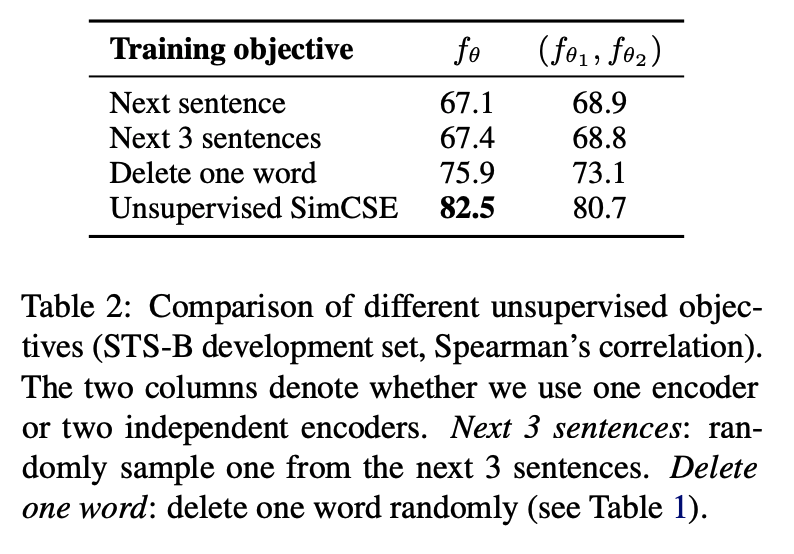
Unsupervisedなモデル学習で,2文の等価判定タスクを行う.
dropout を用いた contrasive learning を他のデータ拡張手法と比較する.
STS-B は以下のようなデータセットであり,この similarity_score について相関係数を評価指標とする.

contrasive learning を行う際に2つのベクトルを同じモデルから取り出すか,別々のモデルから取り出すかという違いを試した.提案法は同じモデルから取り出した方がうまくいった.

dropoutの値は0.1が一番良かった.2つのベクトルを出力する際に同じdropoutのマスクを使うと著しく精度が下がった.

align and uniform の指標で評価した.
uniform はすべてのモデルで良くなっているが,alignはdropoutなしや同一だと悪化している.
align and uniformの説明
対比的表現学習は、実際に顕著な成功を収めている。本研究では,対照的損失に関連する2つの重要な性質,すなわち,(1)正対からの特徴の整列(近接),(2)超球面上の(正規化)特徴の誘導分布の一様性を明らかにする.我々は,漸近的に対比損失がこれらの性質を最適化することを証明し,下流タスクに対するこれらの正の効果を分析する.経験的に、各特性を定量化するための最適化可能な指標を導入する。標準的な視覚と言語のデータセットに対する広範な実験により、両メトリクスと下流のタスクの性能の間に強い一致があることを確認する。驚くべきことに、これら2つの指標を直接最適化することで、対比学習と同等以上の下流タスクの性能を持つ表現が導かれる。

さまざまなデータセットで教師あり学習をした結果,NLIが最も良かった.
理由
NLIデータセットは高品質でクラウドソーシングされたペアから構成されているため,これは妥当であると考えられる.また,人間のアノテーターは前提条件に基づいて手作業で仮説を書くことが想定されており,2つの文の語彙的な重複は少ない傾向にある.例えば,内包ペア(SNLI + MNLI)の語彙的重複度(2つの単語袋の間で計測したF1)は39%であるのに対し,QQPとParaNMTでは60%,55%であることが分かる

SBERTなどの文ベクトルを取得するいろんなモデルを比較した.
STS系のさまざまなタスクにおける相関係数をとった.
特にNLIの教師ありモデルは83.76のスコアを達成した.

[CLS]トークン後の変換を試した.
そんなに変わらない.

SimCSEを異なるαの値で学習させ、STS-Bの開発セットで学習したモデルを評価する。また、中立的な仮説をハードネガティブとすることも検討した。表7に示すように、α=1が最も性能がよく、中立的な仮説はそれ以上の利益をもたらさない。

SBERTbaseとSimCSE-BERTbaseを用いて、小規模な検索実験を行った。Flickr30kデータセットから150kのキャプションを使用し、任意のランダムな文をクエリーとして、類似文を検索する(コサイン類似度に基づいて)。表8に示すように、SimCSEによって検索された文は、SBERTによって検索された文と比較して高い品質を持っている。

図3は、異なる文埋め込みモデルの均一性とアライメントを、平均化したSTSの結果とともに示したものである。一般に、アライメントと一様性の両方が良好なモデルが高い性能を示し、Wang and Isola (2020)の知見を裏付けている。また、(1)事前学習された埋め込みはアライメントが良いが、均一性が悪い(つまり、埋め込みが非常に異方的)、(2)BERT-flowやBERT-whiteningなどの後処理法は均一性を大きく改善するが、アライメントも悪化する、(3)教師なしSimCSEは事前学習した埋め込みの均一性を改善しつつ、アライメントは良くする、(4)SimCSEのデータを教師ありとして取り込むとアライメントはさらに改善されるということが分かった。