概要
URL: https://storage.googleapis.com/deepmind-media/DeepMind.com/Blog/tackling-multiple-tasks-with-a-single-visual-language-model/flamingo.pdf
institute: DeepMind
公開日:2022年11月1日
ほんの一握りのアノテーションされた例を用いて、多数のタスクに迅速に適応できるモデルを構築することは、マルチモーダル機械学習研究の大きなチャレンジです。
このような能力を持つ視覚言語モデル(Visual Language Model, VLM)ファミリーであるFlamingoを紹介します。
Flamingoのモデルは、
(i)強力な事前学習済みの視覚専用モデルと言語専用モデルの橋渡し、
(ii)テキストデータの任意の場所に挟み込まれた視覚データを統合したシーケンス処理、
(iii)入力として画像やビデオをシームレスに取り込む、
などの革新的なアーキテクチャを持ちます。
その柔軟性により、Flamingoモデルは、任意に挟み込まれたテキストと画像を含む大規模なマルチモーダルWebコーパスで学習することができました。これは、in-context few-shot 学習機能を持たせる上で重要です。
提案したFlamingoモデルの徹底的な評価を行い、様々な画像・映像理解ベンチマークに迅速に適応する能力を探求・測定しました。これらのタスクには、ビジュアル質問応答のようなオープンエンドのタスクが含まれ、モデルでは質問に答える必要があります。また、シーンやイベントを説明する能力を評価するキャプションタスクや、複数選択のビジュアル質問応答のようなクローズエンドタスクが含まれます。このようなタスクに対して、Flamingoのモデル1台で、タスクに特化した例を与えるだけで、few-shot学習のSOTAを達成できることを実証しています。これらのベンチマークの多くで、Flamingoは、数千倍のタスク固有データでfine-tuneされたモデルの性能を実際に上回りました。
マルチモーダルの関連研究
Contrasive dual encoder approaches
画像をエンコードしたベクトルとテキストをエンコードしたベクトルについて、contrasive loss を用いて同じ埋め込み空間に配置する手法です。ベクトルのコサイン類似度を計算することにより、zero-shot で vision-text間の検索や分類が行えるようになります。この手法はオープンエンド(選択肢がない状態で答えを出力する)には対応できません。提案法はオープンエンドにも対応できる手法となっています。また、提案法でも contrasive学習を利用して、テキスト説明付きの数十億枚のウェブ画像からビジョンエンコーダを事前学習させています。
Visual language models
マルチモーダルモデルの初期は画像をエンコードしてキャプションのテキストをデコードするタイプ(下図)でした。
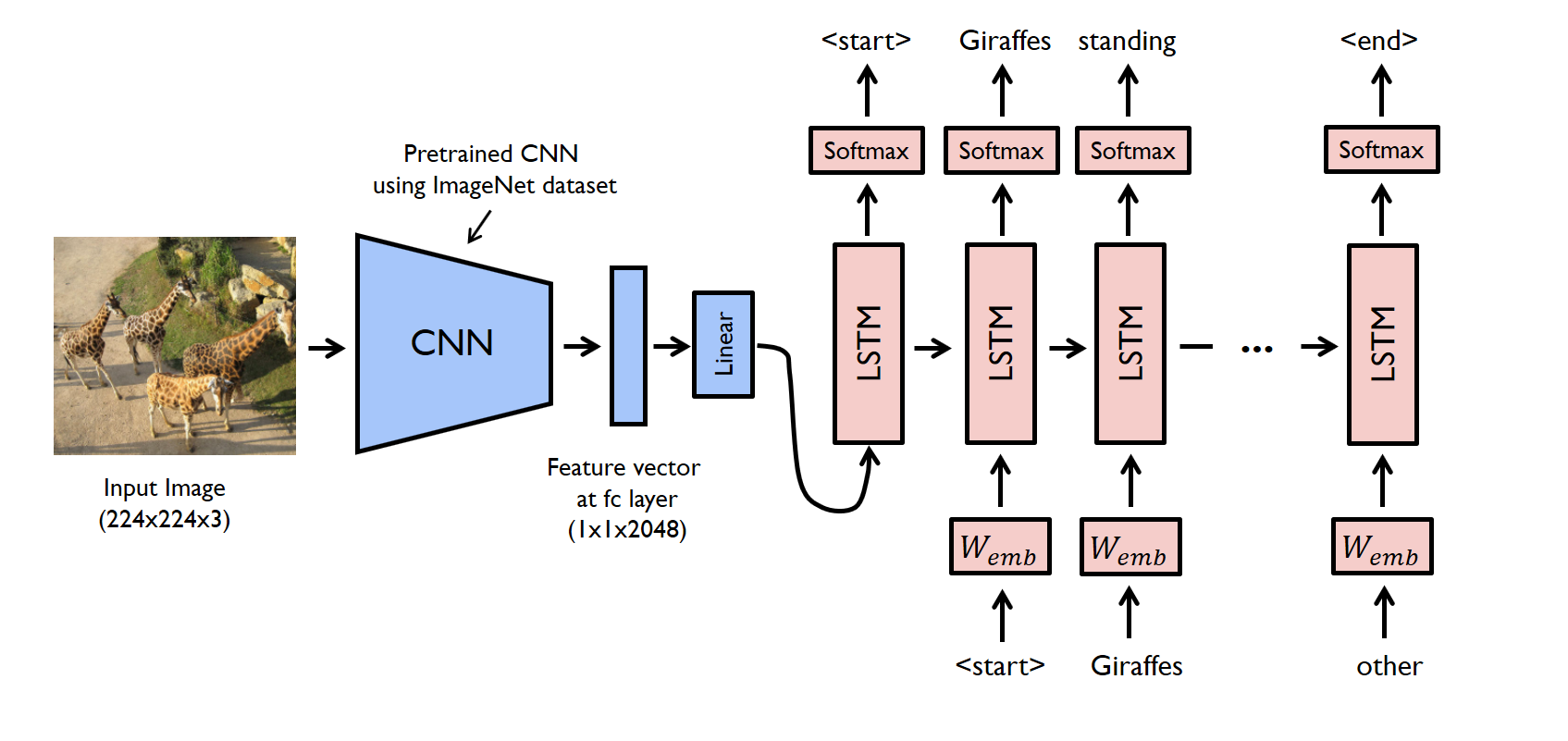
VisualGPTという手法(下図)は、事前学習したLMの重みを用いて、キャプショニングタスクを行うことで精度を向上させました。
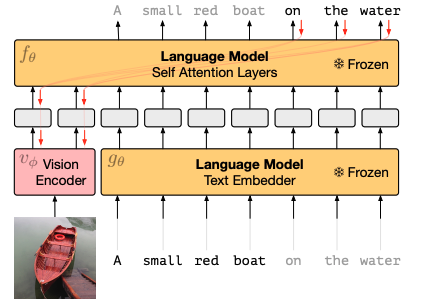
(Tsimpoukelli et al., 2021) の手法は、学習済みLMのweightを凍結(更新しない)ようにして、Vision Encoderを学習させています。
このような学習法は、prefix tuning (prompt tuning) の手法と似通っています。prefix tuningとは、プロンプトの先頭に適当なトークン列を配置しておいて、目的とするタスクの精度が高くなるようにトークン列を更新するという手法です。
学習済みLMの強力な力を保持することでキャプショニング精度を高めようと試みています。
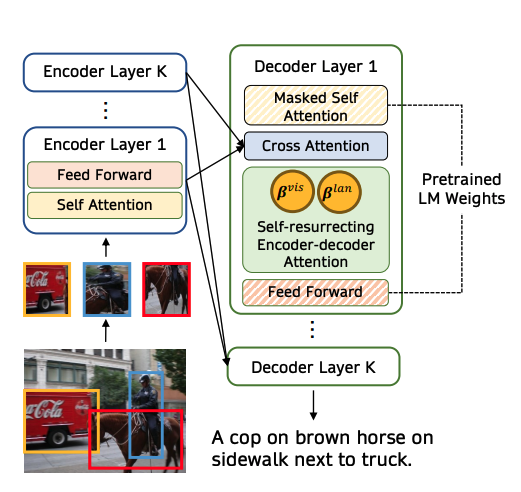
LMを凍結させたマルチモーダル学習手法は他に以下のようなものがあります:
- MAGMA (Eichenberg et al., 2021) : adds bottleneck adapters within the frozen LM
- ClipCap (Mokady et al., 2021): use vision-to-prefix transformer
- VC-GPT (Luo et al., 2022): 凍結した言語モデルに新しい学習層を移植することで、凍結した言語モデルを調整する
- PICA, Socratic Models: 既製の視覚言語モデルを用いた言語記述を用いて画像の内容をGPT-3に伝達する
提案法モデルは、前述のVLMと多くのアイデアを共有しています:
(i)事前に学習した凍結言語モデルに依存する、
(ii)ビジョンエンコーダと凍結言語モデル間のtransformerベースのmapperを利用する、
(iii) 凍結言語モデル層とインターリーブしたクロスアテンション層を学習する。
(インターリーブ:挟み込む的な意味)
また、既存の研究とは以下のように異なります:
- Flamingoのモデルは、Few-shotの例を用いて新しいタスクにfine-tuneすることなく迅速に適応させることができ、完全な教師ありタスク固有の最新モデルを凌駕しています。
- Flamingoモデルのアーキテクチャは、任意にインターリーブされたテキスト、ビデオ、画像のシーケンスを取り込むのに十分な汎用性を持っています。
ウェブスケールの視覚・言語トレーニングデータセット
手動でアノテーションした視覚と言語のデータセットは入手にコストがかかるため、規模が(10k~100k)と、比較的小さいです。
いくつかのアプローチは、画像または動画を利用できるaltテキスト(Webサイトに含まれる画像の代わりになるテキストのこと)または動画説明とペアにしています。これらの手法は、単一の画像/動画とテキスト説明文のペアを学習データとして考慮しただけです。このようなペアのデータに加えて、インターリーブされた画像とテキストを含む(画像とテキストがサンドイッチ構造になっている)マルチモーダルなウェブページ全体を1つのシーケンスとしてトレーニングすることの重要性を提案法は示します。
CM3 (Aghajanyan et al., 2022) は同様のアプローチで、さらにページから完全なHTMLマークアップを生成します。一方、提案法はウェブページのタイトルと本文から自然言語テキストのみをスクレイピングすることにより、ベースLMのテキスト予測タスクを単純化します。
最後に、Flamingoは、VQAv2、COCO、ImageNetのような一般的に使用されているデータセットで学習することなく、幅広いベンチマークで最先端の性能を達成したことを強調します。その代わりに、Flamingoはタスクにとらわれないウェブスクレイプデータのみを用いて学習します。
アプローチ
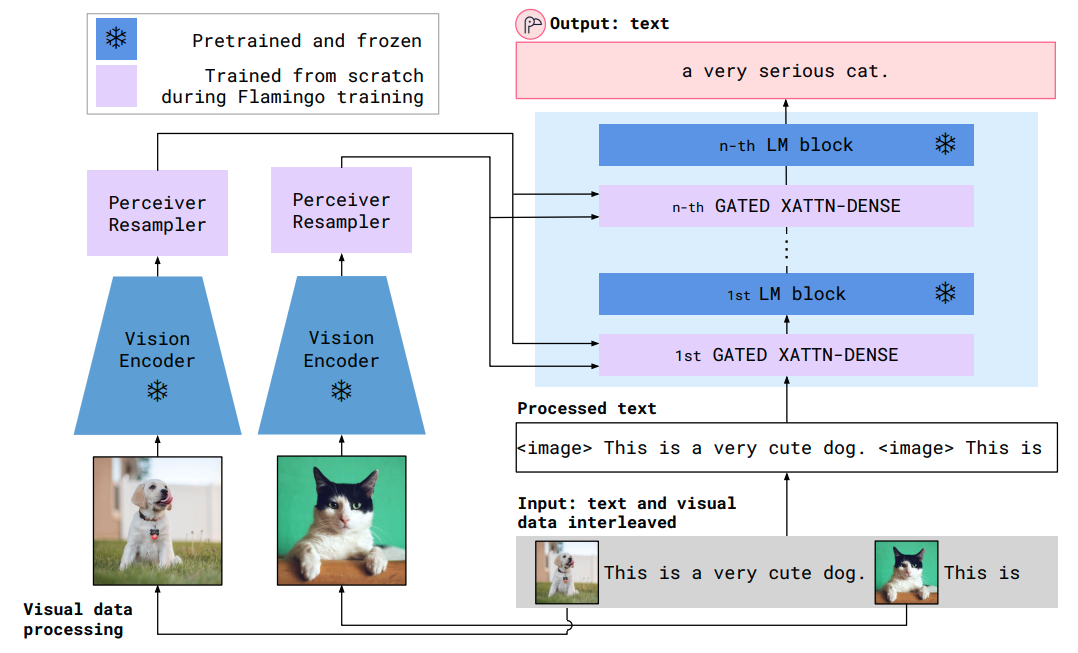
アーキテクチャは上図のようになっています。
画像エンコーダにはcontrasive学習を行った CLIP (Radford et al., 2021) を用いています。また、LMにはDeepMind社で開発した Chinchilla (Hoffmann et al., 2022) を用いています。
マルチモーダルモデルの実現のためには、これらの事前学習済みモデルの情報をうまく調和させる必要があります。学習済みモデルの能力を損なわないために、青色の部分で表すように重みを凍結します。また、次の2つの学習可能なコンポーネントを持ちます。これらの新しいレイヤーは、LMが次のトークンを予測するタスクのために視覚情報を取り入れるための表現方法を提供します。
- Perceiver Resampler: エンコードされた視覚情報を固定長のビジュアルトークンに変換
- ビジュアルトークンをLMに cross attention で入力
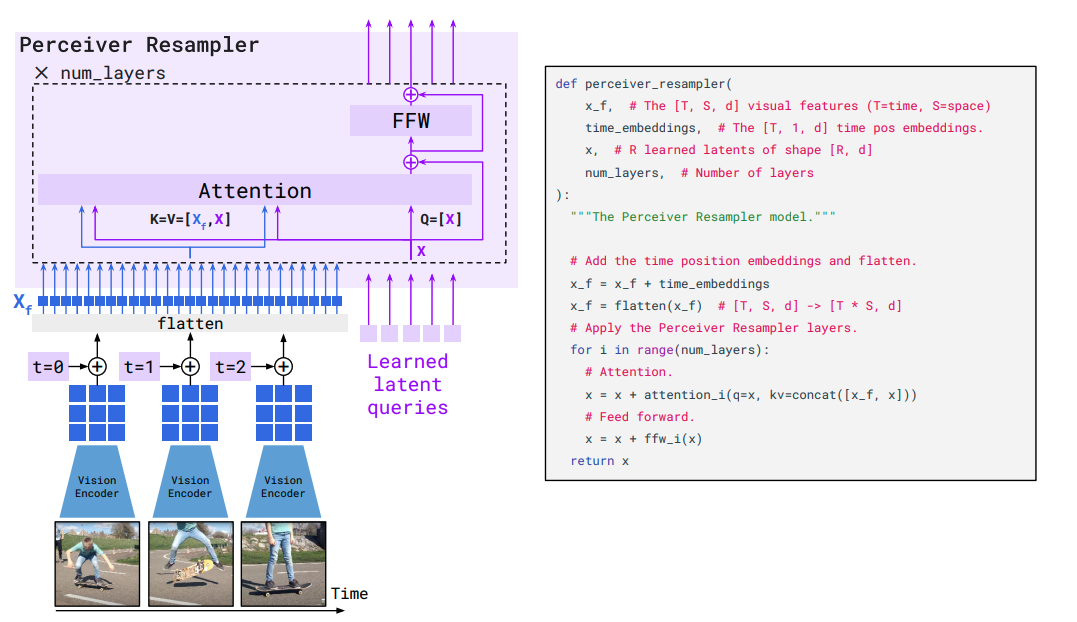
Perceiver Resamplerは上図のような仕組みです。画像から抽出した特徴量にtime position embeddingを加え、空間・時間でflattenすることで、d次元の特徴を一列に入力して、学習可能な固定長トークン(長さは64)Queryに対して、画像の特徴をKey, ValueとしてXATTN (cross attention) で各層ごとに繰り返し計算します。
これによって、解像度や動画データも固定長のトークン列(ビジュアルトークン列)に変換することができます。
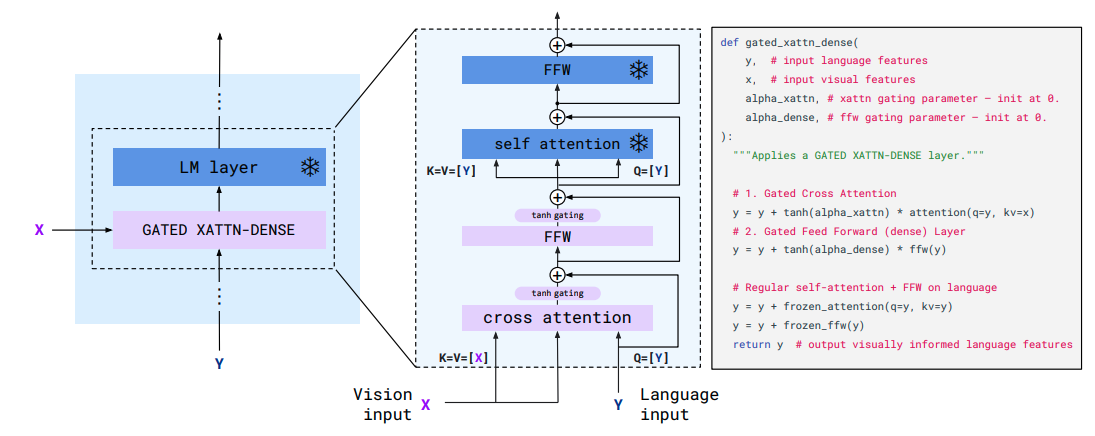
次に、得られたビジュアルトークンをLMにどのように渡すかです。
Perceiver Resamplerで得られたビジュアルトークン列を入力として、下図のように各層のテキストトークン列とcross attention 計算し、FFWに渡します。その後は凍結したLMで self attantion の計算をします。
これを繰り返すことで画像情報をLMに渡します。
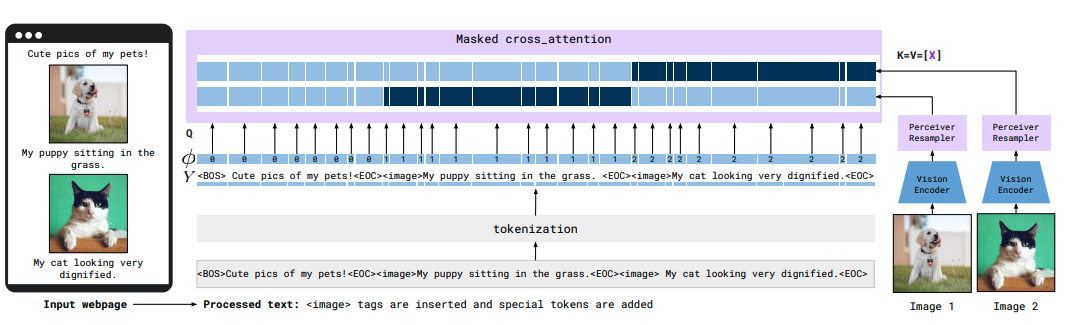
画像を含むwebpageのデータを用いて学習をするわけですが、LM側の入力テキストは、画像部分に <image> トークンに置き換えます。
また、各画像に対応するテキストとの間でのみ cross attention 計算を行うようにテキストトークンにマスクをかける工夫を行います。

次に、用いたデータセットについてです。
上図のような3種類のテキスト - 画像(動画)ペアを用いています。
訓練時には最大で N=5 だったのに対し、Few-shot推論時には少なくとも N=32 までモデルが取り込むことができる汎化が確認されたそうです。
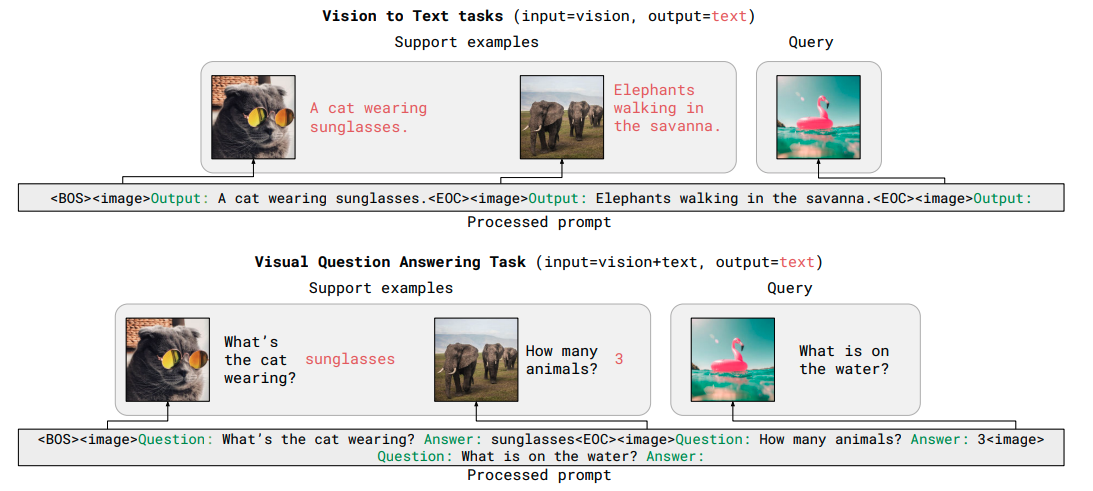
上図はFew-shotタスクの入力例です。
キャプショニングタスク、ビジュアル質問応答のそれぞれについて、fine-tuneすることなく簡易な形式でタスクを解くことができます。
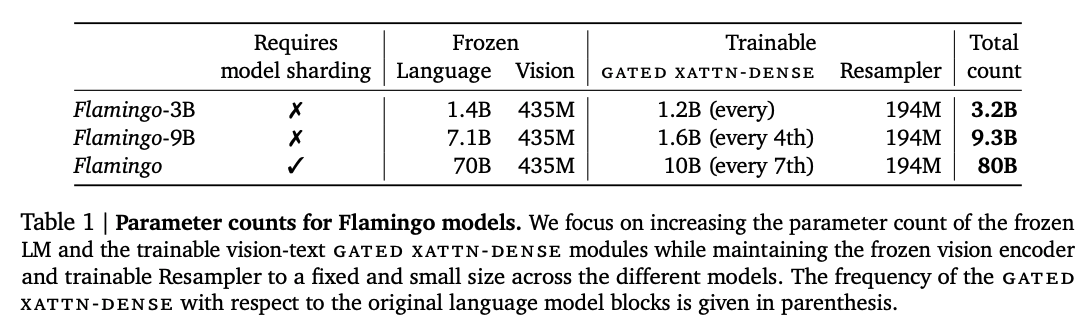
モデルパラメータについてです。
最大規模のモデルでも学習するパラメータ数は100億程度となっています。
実験結果
実験結果は膨大なので割愛しますが、画像とテキストを入力とし、テキストを出力とするあらゆるマルチモーダルタスクにFew-shotで対応できるようになったという結果です。
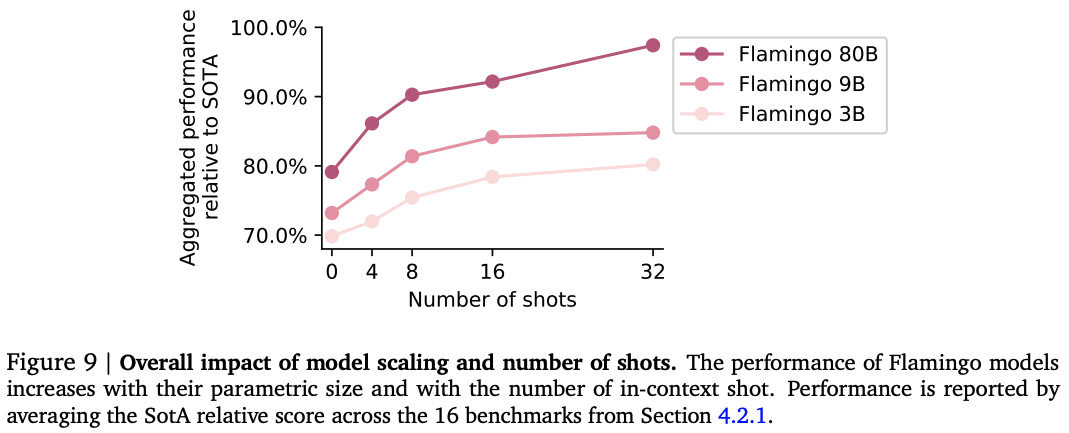
モデルサイズを大きくするほど精度が上がるのは、LLMでもVLMでも同じようです。

画像について1ターンの応答だけではなく、複数ターンで応答できています。
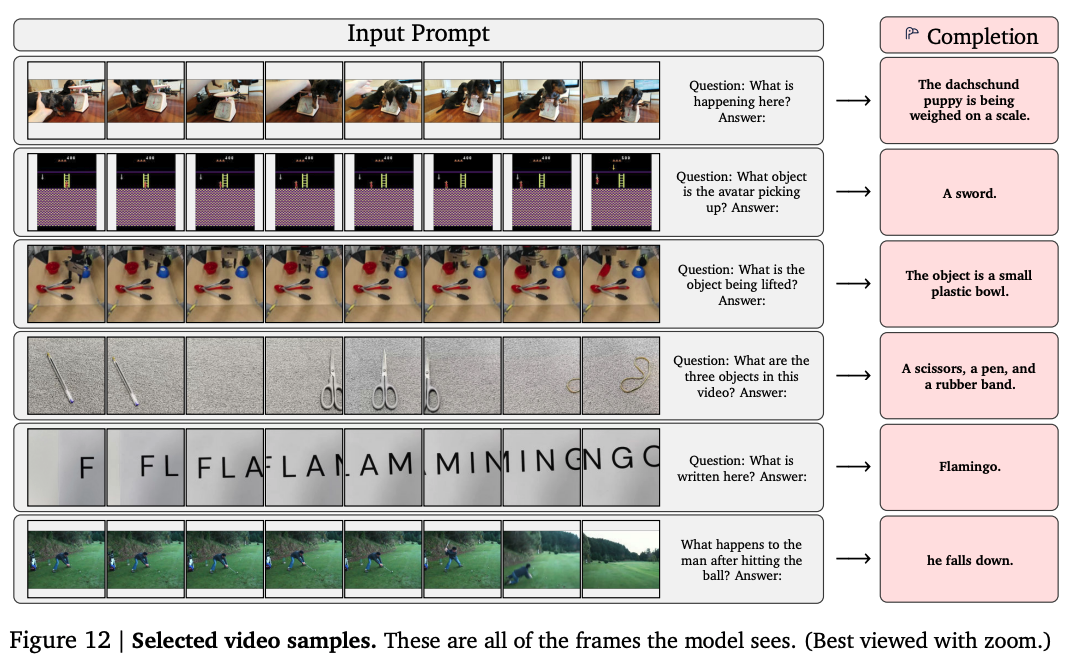
動画に対する質問にも正しく応答できるものもあります。