Abstract
7Bから65Bのパラメータを持つLLMであるLLaMAを紹介します。
数兆個のトークンを使ってモデルを学習し、独自でアクセスできないデータセットに頼ることなく、一般に入手可能なデータセットのみを用いて最先端のモデルを学習することが可能であることを示しています。
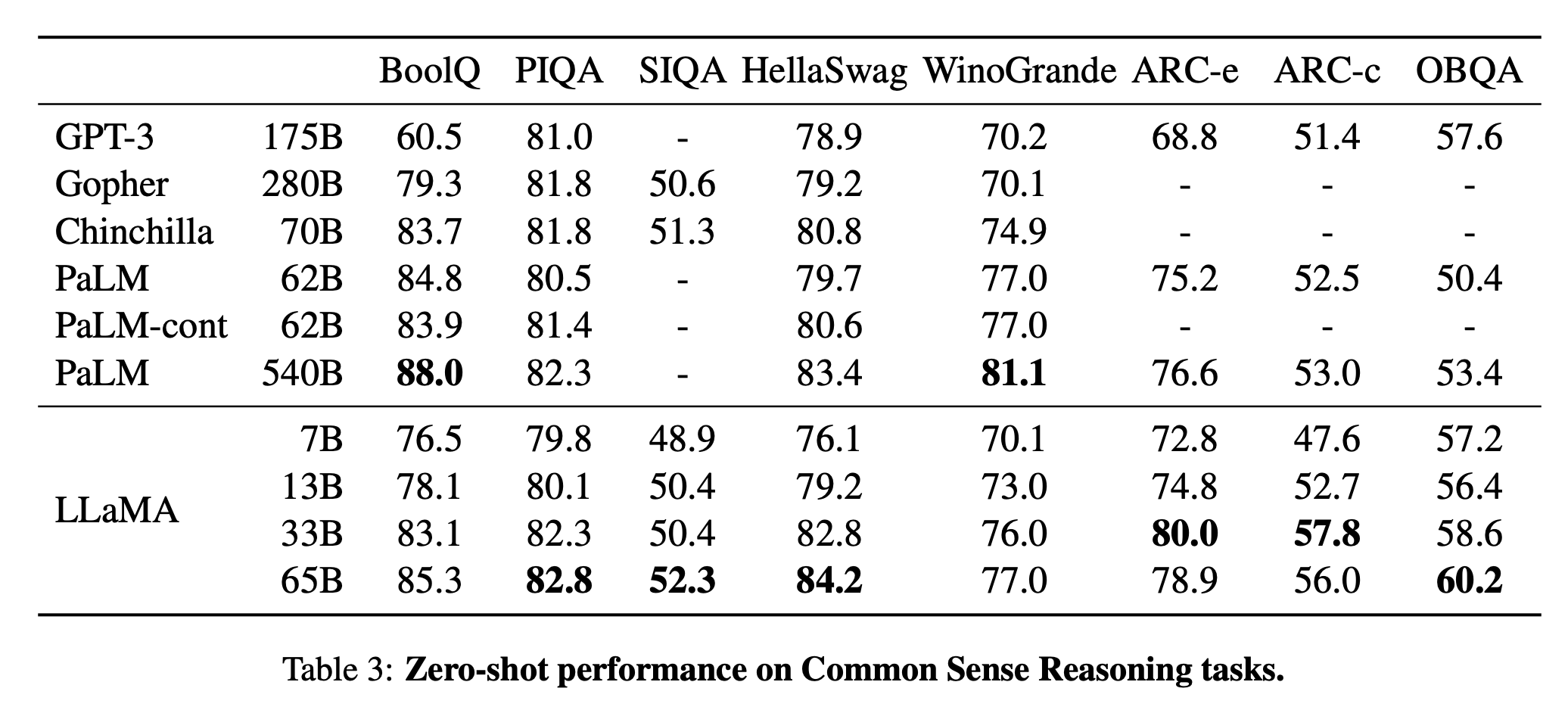
特に、LLaMA-13BはほとんどのベンチマークでGPT-3(175B)を上回り、LLaMA-65Bは最高のモデルであるChinchilla70BやPaLM-540Bに匹敵する性能を有しています。
Introduction
LLMのスケールが続いている
膨大なテキストコーパスで学習させた大規模言語モデル(LLM)は、テキストの指示や少数の例から新しいタスクを実行する能力を示してきました。
このようなFew-shotの特性は、モデルを十分なサイズにスケールアップしたときに初めて現れ、その結果、これらのモデルをさらにスケールアップすることに焦点を当てた一連の研究が生まれました。
与えられた計算予算において最適なデータセットとモデルサイズのバランスを得る
しかし、(Hoffmann+, 2022)は、与えられた計算予算において、最高の性能は最大のモデルによってではなく、より多くのデータで訓練されたより小さなモデルによって達成されることを示します。
(Hoffmann+, 2022)のスケーリング則の目的は、特定の学習計算バジェットに対して、データセットとモデルサイズをどのように拡張するのが最適かを決定することです。
推論コストまで考えると、最適なバランスよりもモデルサイズを小さくした方が良い
しかし、この目的は、言語モデルを大規模に提供する際に重要となる推論バジェットを無視します。
この文脈では、目標とする性能レベルがある場合、望ましいモデルは学習速度が最も速いものではなく、推論速度が最も速いものです。
ある性能レベルに到達するためには、大きなモデルを学習する方が安いかもしれませんが、長く学習した小さなモデルの方が、最終的には推論速度が安くなります。
例えば、Hoffmannら(2022)は200Bトークンに対して10Bモデルの学習を推奨していますが、我々は7Bモデルの性能が1Tトークン後でも向上し続けることを発見しています。
学習トークンを増やすと小さなモデルでも精度が向上
本研究の焦点は、一般的に使用されているものより多くのトークンで学習することにより、様々な推論バジェットで最高の性能を達成する一連の言語モデルを学習することです。
その結果、LLaMAと呼ばれるモデルは7Bから65Bのパラメータを持ち、既存のLLMと比較しても遜色のない性能を発揮します。例えば、LLaMA-13Bは10倍小さいにもかかわらず、ほとんどのベンチマークでGPT-3を上回ります。
このモデルは、単一のGPUで実行できるため、LLMへのアクセスや研究の民主化に貢献すると考えています。
また、65Bパラメータモデルは、ChinchillaやPaLM-540Bなどの大規模言語モデルにも匹敵する性能を有しています。
学習データの概要
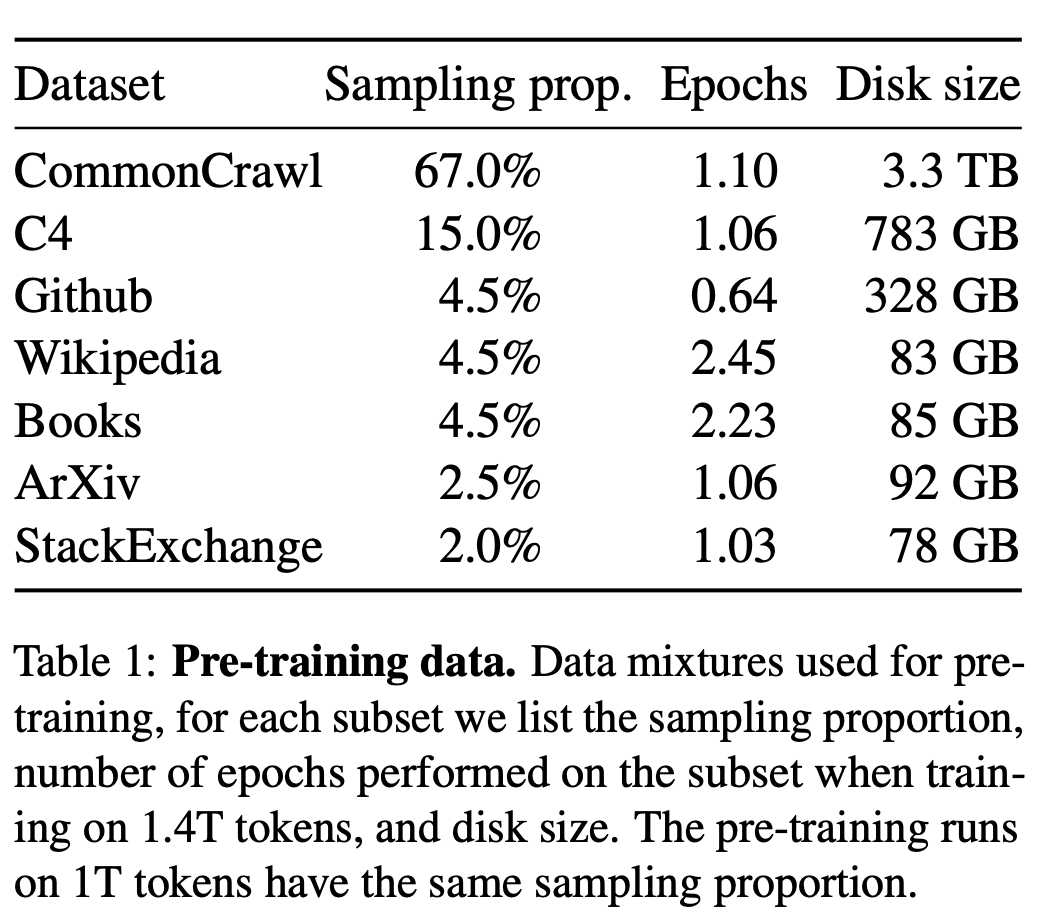
Chinchilla、PaLM、GPT-3とは異なり、我々は一般に入手可能なデータのみを使用しており、我々の研究はオープンソースと互換性があります。
OPT (Zhang et al., 2022), GPT-NeoX (Black et al., 2022), BLOOM (Scao et al., 2022), GLM (Zeng et al., 2022) などの例外もありますが、PaLM-62BやChinchillaに対して競争力のあるものは存在しないのです。
本論文の残りの部分では、我々はTransformerアーキテクチャ(Vaswani et al., 2017)に対して行った修正の概要と、我々の学習方法を紹介します。
次に、我々のモデルの性能を報告し、標準的なベンチマークのセットで他のLLMと比較します。
最後に、責任あるAIコミュニティからの最新のベンチマークのいくつかを用いて、我々のモデルにエンコードされたバイアスと毒性をいくつか明らかにします。
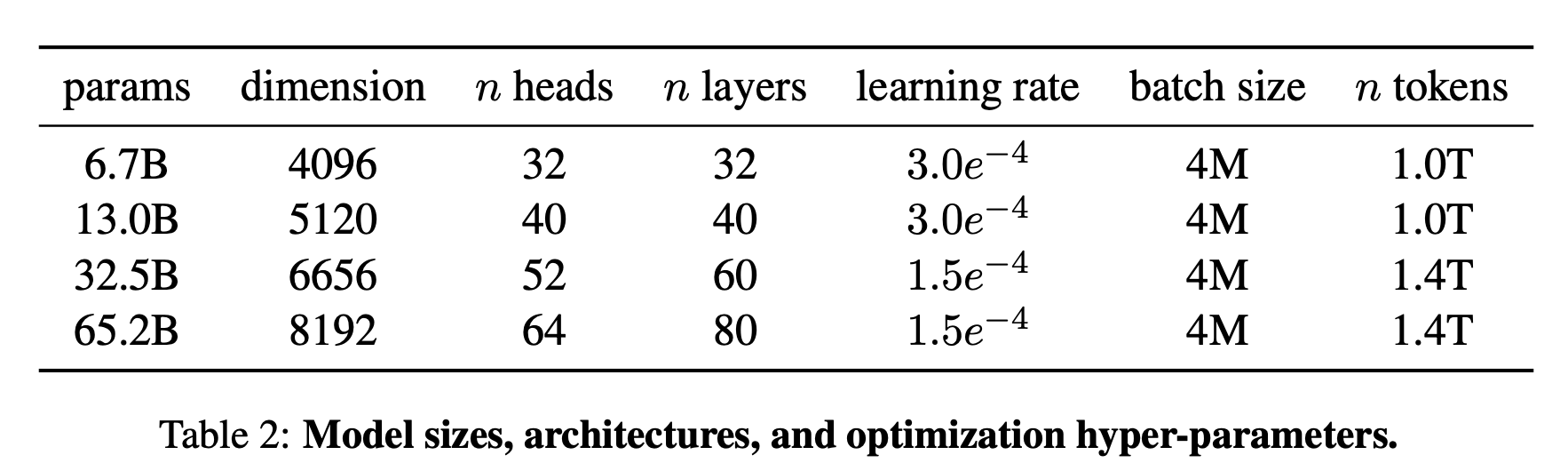
モデルサイズなどの情報
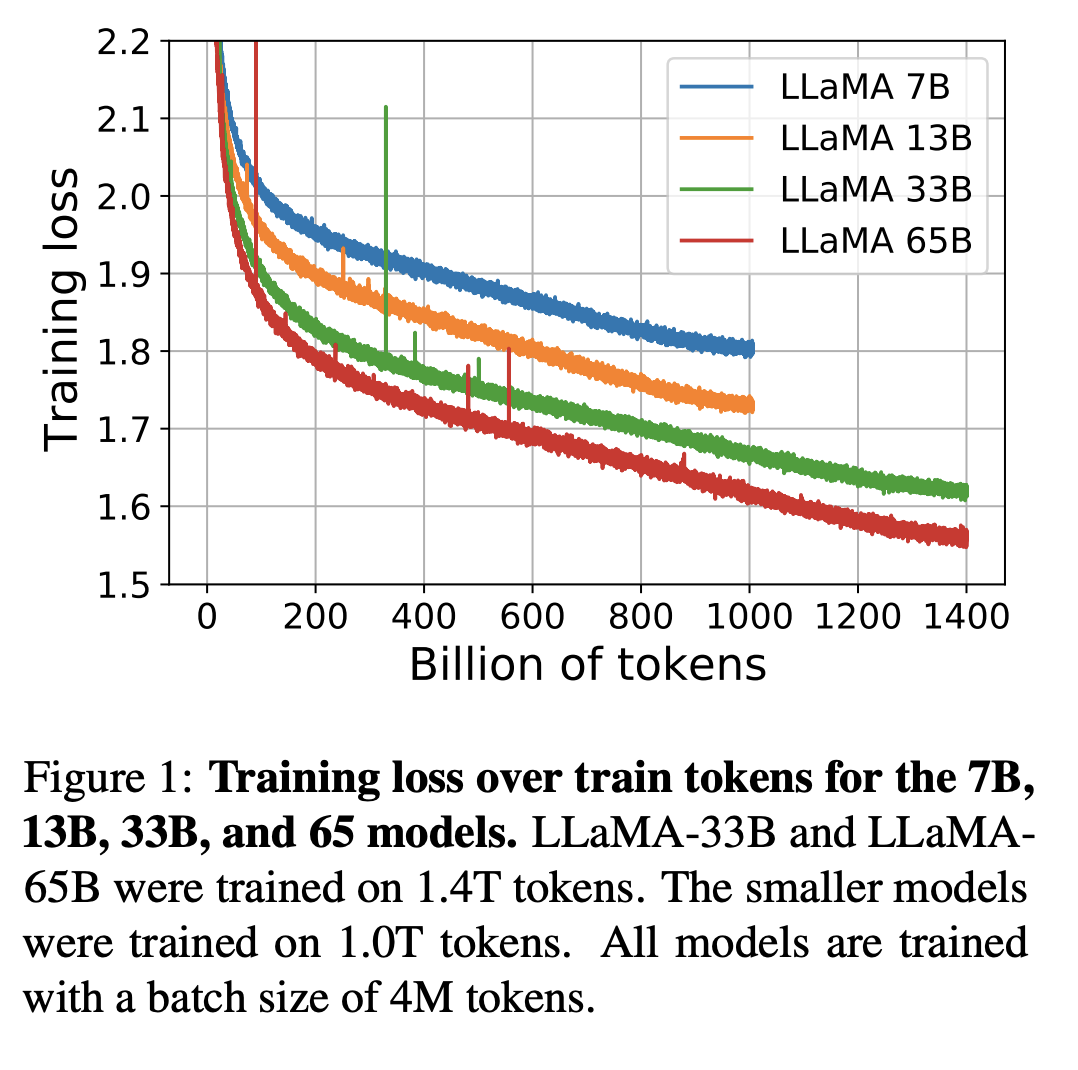
Lossの推移
精度1
精度2