自然音の50クラス分類
自然音に関する50カテゴリの音声データセットであるECS-50を用いて畳み込みによる学習を行った。
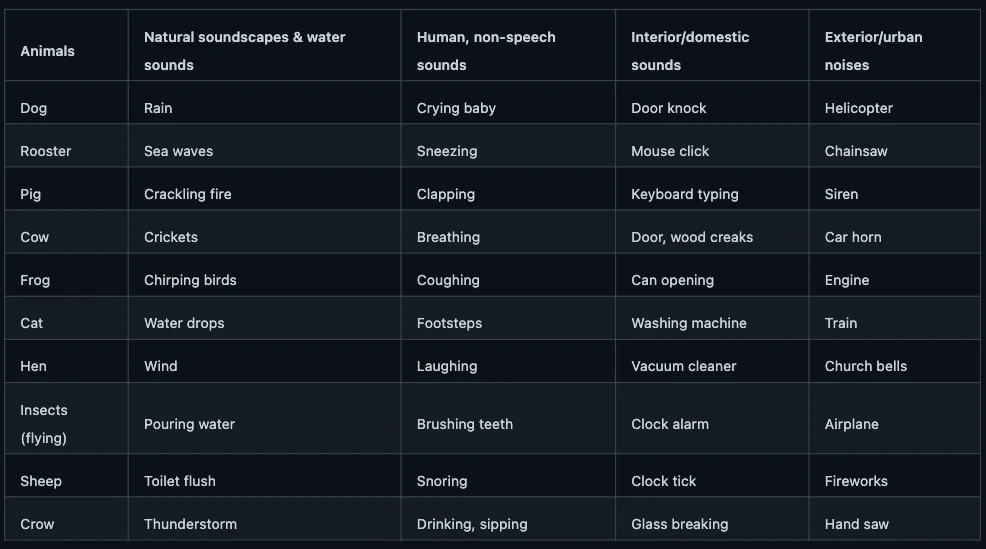
全カテゴリは以下の通り。
犬の鳴き声や風の音、人の笑い声、マウスのクリック音、花火など様々なジャンルの音声がある。
以下のコードを google colab にコピペして、GPUで実行すると約3分で終わる。
まずは、データの事前加工を行う。ダウンロードに1分、サウンドスペクトログラム化に40秒かかる。
import zipfile
import glob
import requests
import librosa
import librosa.display
import numpy as np
import matplotlib.pyplot as plt
import itertools
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
def sound_download():
# urlからデータをダウンロードする
download_url = "https://github.com/karoldvl/ESC-50/archive/master.zip"
filename = "master.zip"
content_ = requests.get(download_url).content
with open(filename, 'wb') as f: # wb でバイト型を書き込める
f.write(content_)
# 解凍すると master ディレクトリが現れる
with zipfile.ZipFile('master.zip') as existing_zip:
existing_zip.extractall('master')
def sound_preprocess(path):
# 音声の読み込み
y, sr = librosa.load(path, sr=None)
# メルスペクトログラム(人間の聴覚に適したスペクトログラム)
S = librosa.feature.melspectrogram(y=y, sr=sr)
S_dB = librosa.power_to_db(S, ref=np.max)
return S_dB
# 音声データのダウンロードと解凍(1分かかる)
sound_download()
# recordingsに入っている数字の音声データ2000個をサウンドスペクトログラムとして取り出す
path_list = glob.glob("master/ESC-50-master/audio/*")
# ラベルでまとまるようにソート
path_list = sorted(path_list, key=lambda x: int(x.split('-')[-1].replace('.wav', '')))
# サウンドスペクトログラムを取得
dB_list = [sound_preprocess(path) for path in path_list]
# スペクトログラムを3つ表示
# for i in range(3):
# librosa.display.specshow(dB_list[i], sr=sr, x_axis='time', y_axis='mel')
# plt.colorbar()
# plt.show()
# Conv2Dを適用できるように最後に軸を追加 X.shape = (2000, 128, 431, 1)
X = np.array(dB_list)
X = X[:, :, :, np.newaxis]
# ディレクトリ内はラベル1からラベル50まで40個ずつ並んでいる
_y = [[i] * 40 for i in range(50)]
y = list(itertools.chain.from_iterable(_y))
y = np.array(y) # [0, 0, ..., 1, 1, ... ... 9, 9]
# ラベルのone hot encodeを行う
enc = OneHotEncoder(sparse=False)
y = enc.fit_transform(y[:, np.newaxis])
# データの分割
X_train, X_test, y_train, y_test = train_test_split(X, y)
次に、モデルの学習を行う。
from keras.layers import Input, Dense, Conv2D, Activation, Dropout, BatchNormalization, Flatten, MaxPool2D
from keras.models import Model
# (データサイズ、時系列、隠れ層)の順
inputs = Input(shape=X.shape[1:])
x = inputs
x = Conv2D(32, (4, 4), strides=2)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPool2D()(x)
x = Dropout(0.5)(x)
x = Conv2D(64, (4, 4), strides=2)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPool2D()(x)
x = Dropout(0.5)(x)
x = Conv2D(128, (4, 4), strides=2)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPool2D()(x)
x = Dropout(0.5)(x)
x = Flatten()(x)
x = Dense(256, activation='relu')(x)
x = Dense(50)(x)
x = Activation('softmax')(x)
model = Model(inputs, x)
model.summary()
model.compile(loss='categorical_crossentropy', optimizer="adam", metrics=['accuracy'])
# GPUを使うと早い
model.fit(X_train, y_train, batch_size=32, epochs=150, validation_data=(X_test, y_test))
pd.DataFrame(model.history.history).loc[:, ['accuracy', 'val_accuracy']].plot(ylim=(0, 1))
学習エポックとaccuracyのグラフはこのようになった。GPUを用いると150エポックでも1分20秒で学習できた。

データは波形 or サウンドスペクトログラムから、モデルはLSTM or 1次元畳み込み or 2次元畳み込みから組み合わせて試すと、サウンドスペクトログラムと2次元畳み込みを用いた場合が60〜70%と、群を抜いて一番精度が高かった。他のパターンは10%〜40%の精度だった。2000のデータで50クラス分類ということと、精度上位の論文ではかなり複雑なモデルにしていたことを踏まえれば、健闘したほうだと思う。
次はデータ拡張をして精度が上がるかを試してみたい。
追記:データの拡張やモデルとoptimizerを改良して精度向上
まず、音声波形のデータ拡張を行う。訓練データ1500個に対して、以下の処理をそれぞれ行うことで7500個に拡張した。
- ガウスノイズを加える
- 時間をシフトする
- 音の高さを変更
- 倍速再生
検証データは拡張していないオリジナルの音声を500個切り分けた。
import zipfile
import glob
import requests
import librosa
import librosa.display
import numpy as np
import matplotlib.pyplot as plt
import itertools
from sklearn.preprocessing import OneHotEncoder
import IPython.display
from tqdm import tqdm
import random
def sound_download():
# urlからデータをダウンロードする
download_url = "https://github.com/karoldvl/ESC-50/archive/master.zip"
filename = "master.zip"
content_ = requests.get(download_url).content
with open(filename, 'wb') as f: # wb でバイト型を書き込める
f.write(content_)
# 解凍すると master ディレクトリが現れる
with zipfile.ZipFile('master.zip') as existing_zip:
existing_zip.extractall('master')
# ガウスノイズを加える
def noise_injection(data, noise_factor=0.002):
# ランダムなので呼び出すたびに変わる
noise = np.random.randn(len(data))
augmented_data = data + noise_factor * noise
# Cast back to same data type
augmented_data = augmented_data.astype(type(data[0]))
return augmented_data
# 時間をシフトする
def shift_time(data, sampling_rate, shift_max=1.5, shift_direction='left'):
# ランダムなので呼び出すたびに変わる
shift = np.random.randint(sampling_rate * shift_max)
if shift_direction == 'right':
shift = -shift
elif shift_direction == 'both':
direction = np.random.randint(0, 2)
if direction == 1:
shift = -shift
augmented_data = np.roll(data, shift)
# Set to silence for heading/ tailing
if shift > 0:
augmented_data[:shift] = 0
else:
augmented_data[shift:] = 0
return augmented_data
# 音の高さを変更
def change_pitch(data, sampling_rate, pitch_factor=1.1):
return librosa.effects.pitch_shift(data, sampling_rate, pitch_factor)
# 倍速再生
def change_speed(data, speed_factor=1.1):
input_length = len(data)
data = librosa.effects.time_stretch(data, speed_factor)
if len(data) > input_length:
return data[:input_length]
else:
return np.pad(data, (0, max(0, input_length - len(data))), "constant")
# データ拡張してリスト形式で返す
def data_augmentation(y, sr):
# ここを変えればいくらでもデータを増やせる
augmented_wave_list = []
augmented_wave_list.append(y)
augmented_wave_list.append(noise_injection(y, noise_factor=0.002))
augmented_wave_list.append(shift_time(y, sr, shift_max=1.5))
augmented_wave_list.append(change_pitch(y, sr, pitch_factor=1.5))
augmented_wave_list.append(change_speed(y, speed_factor=1.5))
return augmented_wave_list
def display_augmented_sound(y, sr):
IPython.display.display(IPython.display.Audio(y, rate=sr))
print('ガウスノイズを加える')
IPython.display.display(IPython.display.Audio(noise_injection(y, noise_factor=0.002), rate=sr))
print('時間をシフトする')
IPython.display.display(IPython.display.Audio(shift_time(y, sr, shift_max=1.5), rate=sr))
print('音の高さを変更')
IPython.display.display(IPython.display.Audio(change_pitch(y, sr, pitch_factor=1.5), rate=sr))
print('倍速再生')
IPython.display.display(IPython.display.Audio(change_speed(y, speed_factor=1.5), rate=sr))
def wave2melspectrogram(y, sr):
# メルスペクトログラム(人間の聴覚に適したスペクトログラム)
S = librosa.feature.melspectrogram(y=y, sr=sr)
S_dB = librosa.power_to_db(S, ref=np.max)
return S_dB
def path_list2path_label_list(path_list):
# ラベルでまとまるようにソート
path_list = sorted(path_list, key=lambda x: int(x.split('-')[-1].replace('.wav', '')))
# ディレクトリ内はラベル1からラベル50まで40個ずつ並んでいる
_y = [[i] * 40 for i in range(50)]
y = list(itertools.chain.from_iterable(_y))
y = np.array(y) # [0, 0, ..., 1, 1, ... ... 9, 9]
# ラベルのone hot encodeを行う, Falseだとメモリを食うがすべてを表示
enc = OneHotEncoder(sparse=False)
y = enc.fit_transform(y[:, np.newaxis])
# 連続したラベルを混ぜる
path_label_list = list(zip(path_list, y))
random.shuffle(path_label_list)
return path_label_list
def path_label_list2augmented_wave_train_and_y_train(path_label_list):
augmented_wave_train = []
y_train = []
for path, label in tqdm(path_label_list[:1500]):
y, sr = librosa.load(path, sr=None)
augmented_wave_list = data_augmentation(y, sr)
augmented_wave_train.extend(augmented_wave_list)
y_train.extend([label] * 5)
wave_test = []
y_test = []
for path, label in tqdm(path_label_list[1500:]):
y, sr = librosa.load(path, sr=None)
wave_test.append(y)
y_test.append(label)
# 5連のラベルを混ぜる
random_train = list(zip(augmented_wave_train, y_train))
random.shuffle(random_train)
augmented_wave_train, y_train = zip(*random_train)
random_test = list(zip(wave_test, y_test))
random.shuffle(random_test)
wave_test, y_test = zip(*random_test)
return augmented_wave_train, np.array(y_train), wave_test, np.array(y_test)
# 音声データのダウンロードと解凍
sound_download()
# mp3ファイルのパスのリストを取得
path_list = glob.glob("master/ESC-50-master/audio/*")
# データ拡張の例を表示
x, sr = librosa.load(path_list[0], sr=None)
display_augmented_sound(x, sr)
# パスとラベルを取得
path_label_list = path_list2path_label_list(path_list)
# データ拡張とメルスペクトログラム化を行う
augmented_wave_train, y_train, wave_test, y_test = path_label_list2augmented_wave_train_and_y_train(path_label_list)
X_train = np.array([wave2melspectrogram(x, sr) for x in augmented_wave_train])[:, :, :, np.newaxis]
X_test = np.array([wave2melspectrogram(x, sr) for x in wave_test])[:, :, :, np.newaxis]
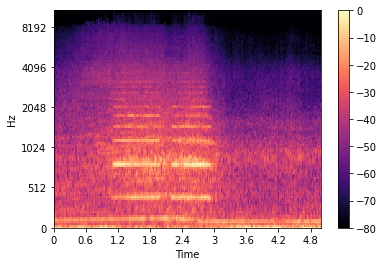
# メルスペクトログラムの例を表示
librosa.display.specshow(X_train[0, :, :, 0], sr=sr, x_axis='time', y_axis='mel')
plt.colorbar()
plt.show()
加工した音声を聴くことができる。
サウンドスペクトログラムはこのようになった。
次に、2つの音声を組み合わせることでデータ拡張する。
# 2つの音声を組み合わせるデータ拡張、ラベルも重み付きで足し合わせるのが特徴
# https://qiita.com/yu4u/items/70aa007346ec73b7ff05
class MixupGenerator():
def __init__(self, x_train, y_train, batch_size=16, alpha=0.2, shuffle=True):
self.x_train = x_train
self.y_train = y_train
self.batch_size = batch_size
self.alpha = alpha
self.shuffle = shuffle
self.sample_num = len(x_train)
def __call__(self):
while True:
indexes = self.__get_exploration_order()
itr_num = int(len(indexes) // (self.batch_size * 2))
for i in range(itr_num):
batch_ids = indexes[i * self.batch_size * 2:(i + 1) * self.batch_size * 2]
x, y = self.__data_generation(batch_ids)
yield x, y
def __get_exploration_order(self):
indexes = np.arange(self.sample_num)
if self.shuffle:
np.random.shuffle(indexes)
return indexes
def __data_generation(self, batch_ids):
_, h, w, c = self.x_train.shape
_, class_num = self.y_train.shape
x1 = self.x_train[batch_ids[:self.batch_size]]
x2 = self.x_train[batch_ids[self.batch_size:]]
y1 = self.y_train[batch_ids[:self.batch_size]]
y2 = self.y_train[batch_ids[self.batch_size:]]
l = np.random.beta(self.alpha, self.alpha, self.batch_size)
x_l = l.reshape(self.batch_size, 1, 1, 1)
y_l = l.reshape(self.batch_size, 1)
x = x1 * x_l + x2 * (1 - x_l)
y = y1 * y_l + y2 * (1 - y_l)
return x, y
training_generator = MixupGenerator(X_train, y_train)()
print("one-hotラベルが連続値になっている\n", next(training_generator)[1][0])
作成した音声をもとに、まずはざっくりと20エポックの学習を行う。(GPUで40分)
from keras.layers import Input, Dense, Conv2D, Activation, BatchNormalization, Flatten, Add, GlobalAveragePooling2D
from keras.models import Model
import tensorflow as tf
import keras
from keras.callbacks import EarlyStopping
import pandas as pd
def cba(inputs, filters, kernel_size, strides):
x = Conv2D(filters, kernel_size=kernel_size, strides=strides, padding='same')(inputs)
x = BatchNormalization()(x)
x = Activation("relu")(x)
return x
inputs = Input(shape=(X_train.shape[1:]))
x_1 = cba(inputs, filters=32, kernel_size=(1,8), strides=(1,2))
x_1 = cba(x_1, filters=32, kernel_size=(8,1), strides=(2,1))
x_1 = cba(x_1, filters=64, kernel_size=(1,8), strides=(1,2))
x_1 = cba(x_1, filters=64, kernel_size=(8,1), strides=(2,1))
x_2 = cba(inputs, filters=32, kernel_size=(1,16), strides=(1,2))
x_2 = cba(x_2, filters=32, kernel_size=(16,1), strides=(2,1))
x_2 = cba(x_2, filters=64, kernel_size=(1,16), strides=(1,2))
x_2 = cba(x_2, filters=64, kernel_size=(16,1), strides=(2,1))
x_3 = cba(inputs, filters=32, kernel_size=(1,32), strides=(1,2))
x_3 = cba(x_3, filters=32, kernel_size=(32,1), strides=(2,1))
x_3 = cba(x_3, filters=64, kernel_size=(1,32), strides=(1,2))
x_3 = cba(x_3, filters=64, kernel_size=(32,1), strides=(2,1))
x_4 = cba(inputs, filters=32, kernel_size=(1,64), strides=(1,2))
x_4 = cba(x_4, filters=32, kernel_size=(64,1), strides=(2,1))
x_4 = cba(x_4, filters=64, kernel_size=(1,64), strides=(1,2))
x_4 = cba(x_4, filters=64, kernel_size=(64,1), strides=(2,1))
x = Add()([x_1, x_2, x_3, x_4])
x = cba(x, filters=128, kernel_size=(1,16), strides=(1,2))
x = cba(x, filters=128, kernel_size=(16,1), strides=(2,1))
x = GlobalAveragePooling2D()(x)
x = Dense(50)(x)
x = Activation("softmax")(x)
model = Model(inputs, x)
# model.summary()
batch_size = 16
training_generator = MixupGenerator(X_train, y_train, batch_size)()
opt = keras.optimizers.Adam()
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
# 学習の実行
model.fit(training_generator,
steps_per_epoch=X_train.shape[0] // batch_size,
validation_data=(X_test, y_test),
epochs=20,
verbose=1,
shuffle=True,
)
pd.DataFrame(model.history.history).loc[:, ['accuracy', 'val_accuracy']].plot(ylim=(0, 1))
横軸をエポックとして、訓練データと検証データの正解率のグラフはこのようになった。
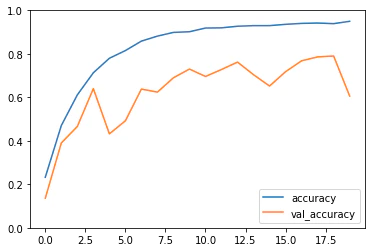
optimizerを変えてさらに20エポックのファインチューニングを行うと、80%から90%とより高い正解率となった。(GPUで40分)
ファインチューニングするほうで全部の学習を行うと時間がかかりすぎるので、学習速度と正解率を最適化するために2ステップに分けて学習を行った。
# optimizerを変えてファインチューニング
opt = keras.optimizers.Adam(learning_rate=0.00001, decay=1e-6, amsgrad=True)
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
# 精度が上がらなければ終了
es_cb = EarlyStopping(monitor='val_loss', patience=3, verbose=1, mode='auto')
# 学習の実行
model.fit(training_generator,
steps_per_epoch=X_train.shape[0] // batch_size,
validation_data=(X_test, y_test),
epochs=20,
verbose=1,
shuffle=True,
callbacks=[es_cb]
)
pd.DataFrame(model.history.history).loc[:, ['accuracy', 'val_accuracy']].plot(ylim=(0, 1))
