はじめに
華麗なるGAN一族のサーベイを行いました。GANの名称・論文URL・概要・ネットワーク構造・結果(生成画像)のフォーマットで記載しています。
初代GAN
概要
ガウスノイズから偽物画像を生成するGeneratorと、本物画像と偽物画像を識別するDiscriminatorの二つのネットワークを競わせるように学習します。偽物画像が本物画像と見分けがつかないようになることが目標となります。理論的な保証はMin-Max-GANという定式化で行われますが、実際は非飽和GAN(NS-GAN)という独立した損失関数として定式化する方法で学習させています。
ネットワーク構造
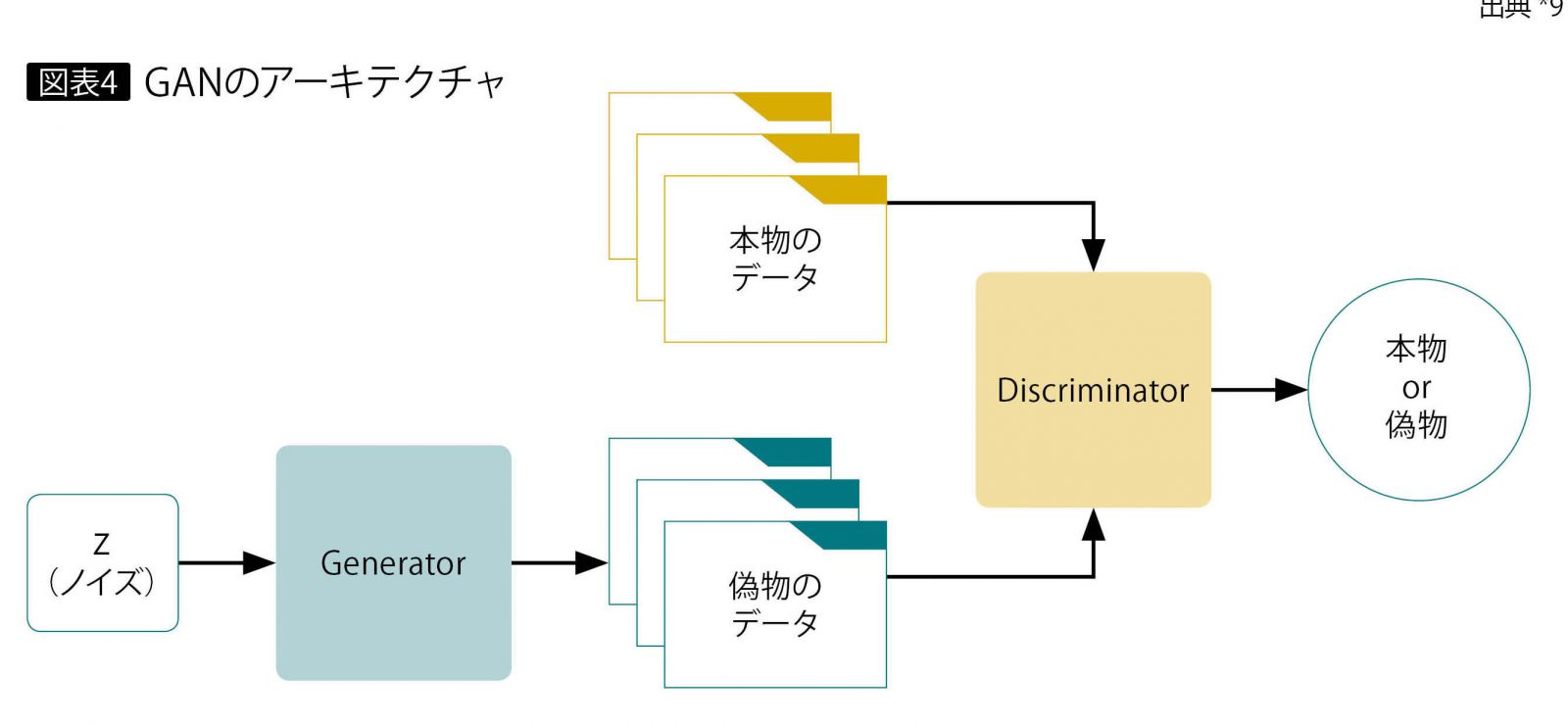
結果

DCGAN
概要
ネットワーク全体をCNNにしています。バッチ正規化や転置畳み込み(deconvolution)、Leaky ReLUなどを導入しています。
ネットワーク構造
generatorにdeconvolutionを利用しています。
結果

WGAN
概要
GANの損失関数の設計において、Wasserstein距離を用いることで、学習を高速化及び安定させました。GANを語る上で避けては通れず、損失関数のデファクトスタンダードとなっています。
ネットワーク構造
通常のGANと特に変わりません。
結果

WGAN-gp
概要
WGANでのクリッピングの問題等を解決するために、評価関数にペナルティ項を加えました。
ネットワーク構造
通常のGANと変わりません.
結果

PGGAN(Progressive GAN)
概要
GANの学習において段階的に高解像度の学習がするように学習の過程を工夫することで1024×1024の高解像度な画像を生成できるようになりました。その他以下の工夫を行っています。
- ミニバッチ標準偏差
- 学習率の平滑化(Equalize)
- ピクセルごとの特徴正規化
ネットワーク構造
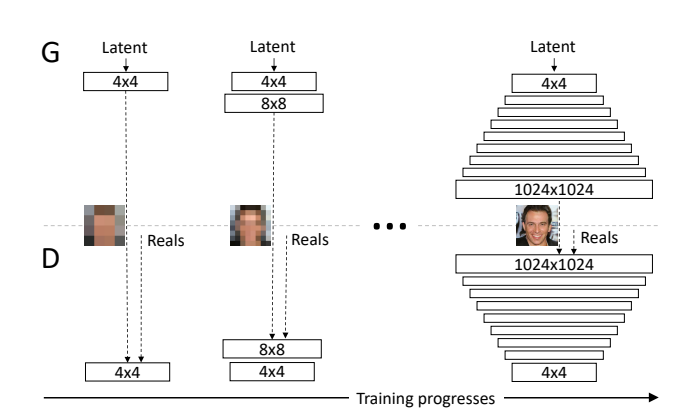
結果

SGAN(Semi-Supervised GAN、半教師ありGAN)
概要
ラベルの付いていないデータに対してGANで学習しつつ、ラベル付きのデータで画像分類の学習を行います。GAN識別機と分類モデルのネットワークを共有することでこれを実現します。医療分野など少量のラベル付きデータしかない場合でも、高精度を出すことが期待されます。
ネットワーク構造
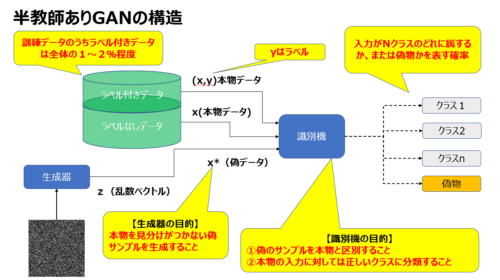
結果
Street View House Numbers (SVHN) ベンチマークにおいて、わずか2,000のラベル付きデータからおよそ94%の精度を達成しました。
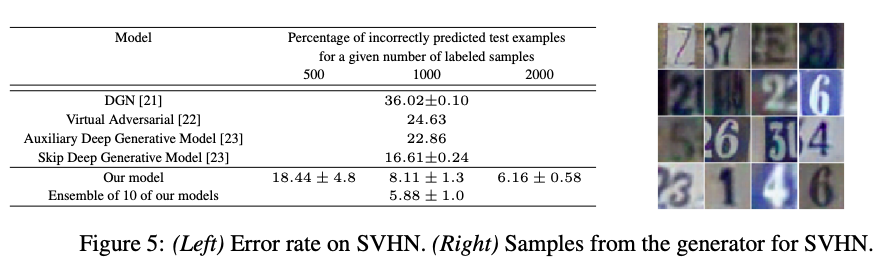
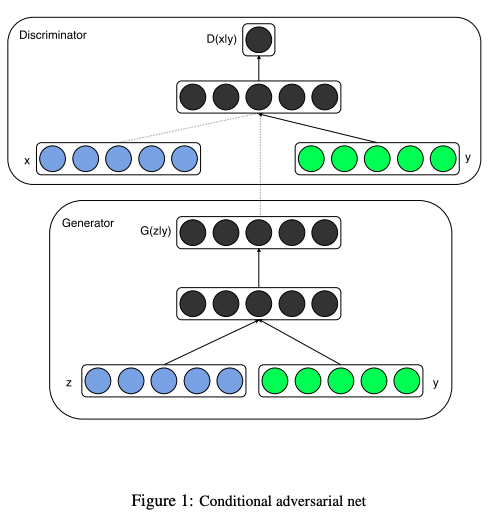
CGAN (Conditional GAN、条件付きGAN)
概要
GANの学習を行う際にクラスのラベルも一緒に入れて学習することで、画像生成時にラベルを指定することで、そのラベルの画像を生成することができます。
ネットワーク構造
結果

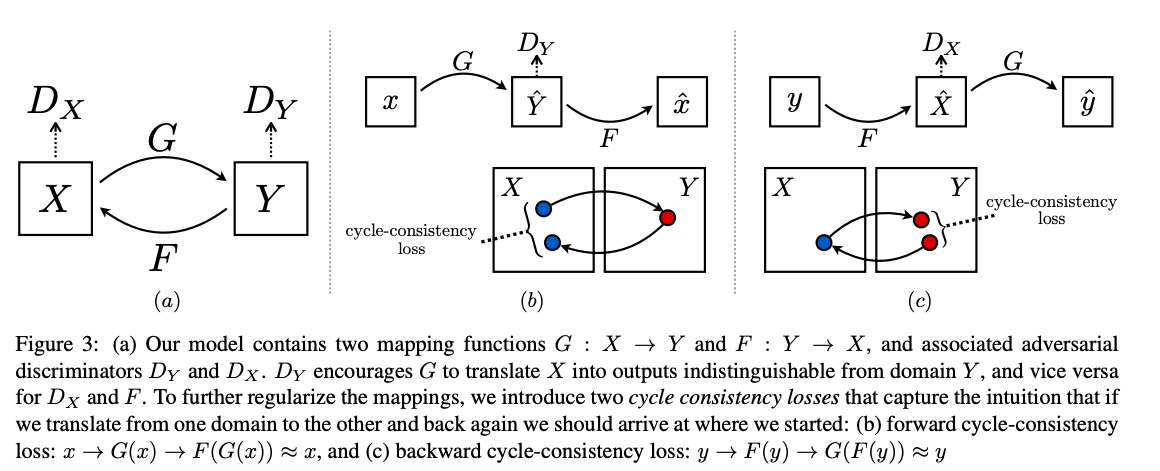
CycleGAN
概要
二つの、例えばりんごの画像とオレンジの画像を変換するように学習したGANです。特徴的なのは学習時に対応する画像が必要なく、あくまでりんごの画像群とオレンジの画像群があればよく、りんごと同じ姿勢の似たような対応の取れているオレンジの画像が必要ではないです。ネットワークがぐるぐる回った形になっており、オレンジ画像からりんご画像を生成して、そのりんご画像を再度オレンジ画像に戻したときの精度が高くなるように学習させます。
ネットワーク構造
結果

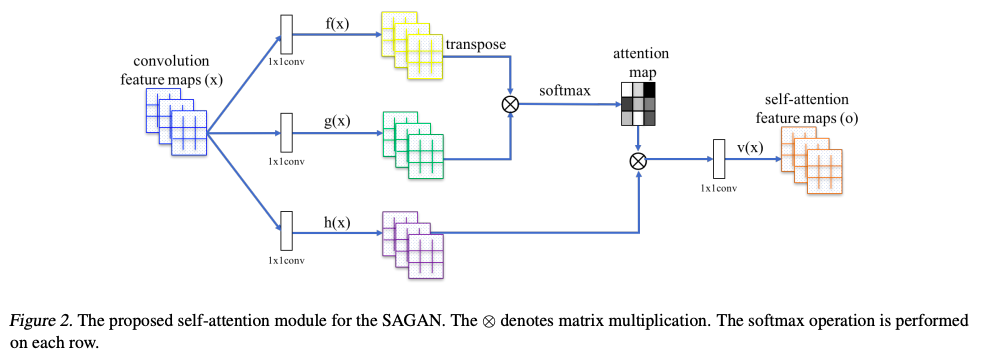
SAGAN(Self-Attention GAN、自己アテンションGAN)
概要
CNNは小さな畳込み領域(最も使われる最大の畳込み領域の値は7)に依存しており、これによって頭や胴体が複数ある牛などを生成してしまうことがあります。アテンションは、画像の多くの部分を無視することで、CNNの問題解決の助けになります。
ネットワーク構造
結果

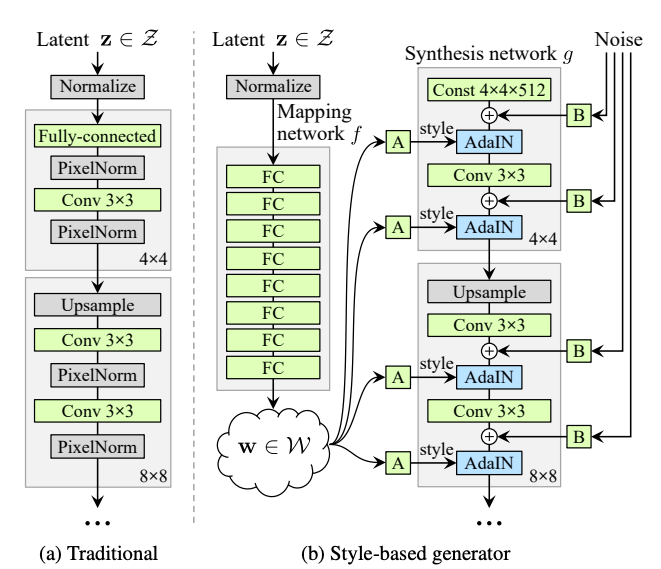
StyleGAN
概要
GANのアイデアと伝統的なスタイル変換を組み合わせることで、生成画像をさらにコントロールできるようにするものです。
ネットワーク構造
- 各転置畳み込み処理後にstyleの調整を行う
- 細部の特徴はノイズによって生成される
- 潜在変数zを潜在空間wに非線形変換する
結果

Differentiable Augmentation for Data-Efficient GAN Training [Zhao+, 2020]
概要
単純に画像分類の場合と同様にリアル画像だけをデータ拡張(カットアウト(画像をランダムな正方形でマスキング)、色・コントラスト・彩度のランダム変化など)を行うと、Discriminatorが変換後の画像も実際の画像の分布に含まれていると勘違いしてしまうため、あまり強い変換をかけることが出来ません。そこで、フェイク画像も変換することで、強い変換をかけられるようになったというのがポイントです。これによって、少量のデータでGANの学習が可能になります。
ネットワーク構造
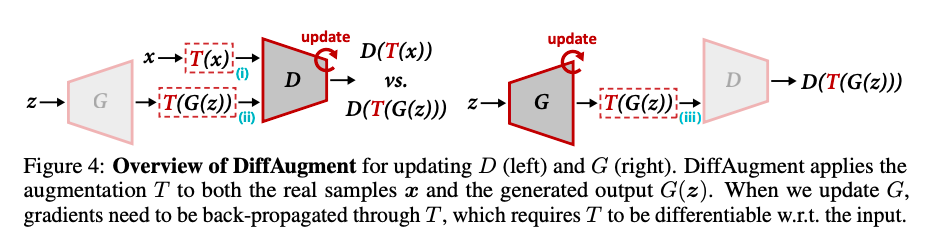
結果

BigGAN
概要
512×512の非常にリアルな画像の生成を、ImageNetの1,000クラスすべてに対して達成しました。BigGANはSAGAN(自己アテンションGAN)に基づいており、信じられないサイズにスケールアップしました。
学習した画像データセット(3億枚画像を含むJFT-300M)や使用したグラフィックボードの枚数(512GPU)、バッチサイズ(2048)、訓練するのにかかる費用が600万円近くなど、色々と大規模です。
ネットワーク構造
ベースはSAGAN
結果

pix2pix
概要
画像の対応のペアを入力としてそれがペアとして正しいかどうかを判定することで、汎用的な画像の変換を行うGANを作成しました。通常のGANはベクトルを入力に一枚の画像を判定していたのに対して、pix2pixでは画像を入力に(条件に)出力画像を得て、入力画像と出力画像のペアを本物かどうか判定しているのが特徴です。画像を条件に画像を生成しているため、ConditionalGANの一種です。
ネットワーク構造
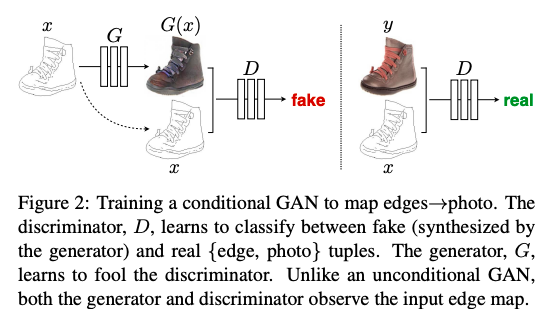
結果

pix2pixHD
概要
2048×1024の高解像な画像を生成することができるGANです。Generatorでは以下のように二段構造になっていて、1024×512を生成するGeneratorとそれを囲むようにしてさらに解像度を2倍にするGeneratorを用意しています。Residual Blockの挿入やDiscriminatorの複数のスケール、さらにFeatureMatchingを行うなど学習の工夫も含めて実現しています.
ネットワーク構造
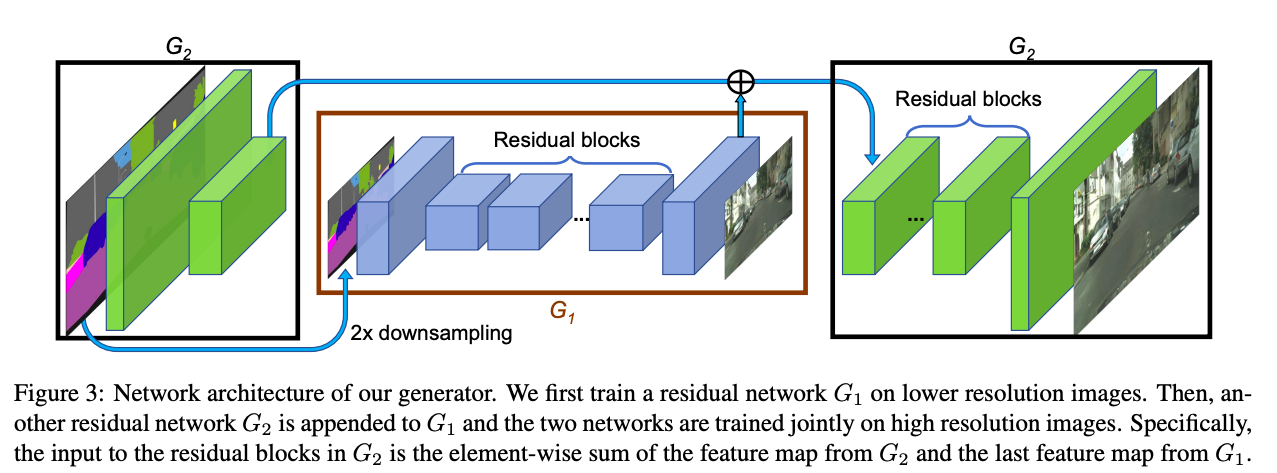
結果

StackGAN
概要
テキストから画像を生成するGANです。
pix2pixHDでもありましたが、StackGANも二段のGANで構成されています。一つ目は文章から画像を生成するネットワーク、二つ目は一つ目で大方書かれた画像を高精度にするGANです。
ネットワーク構造
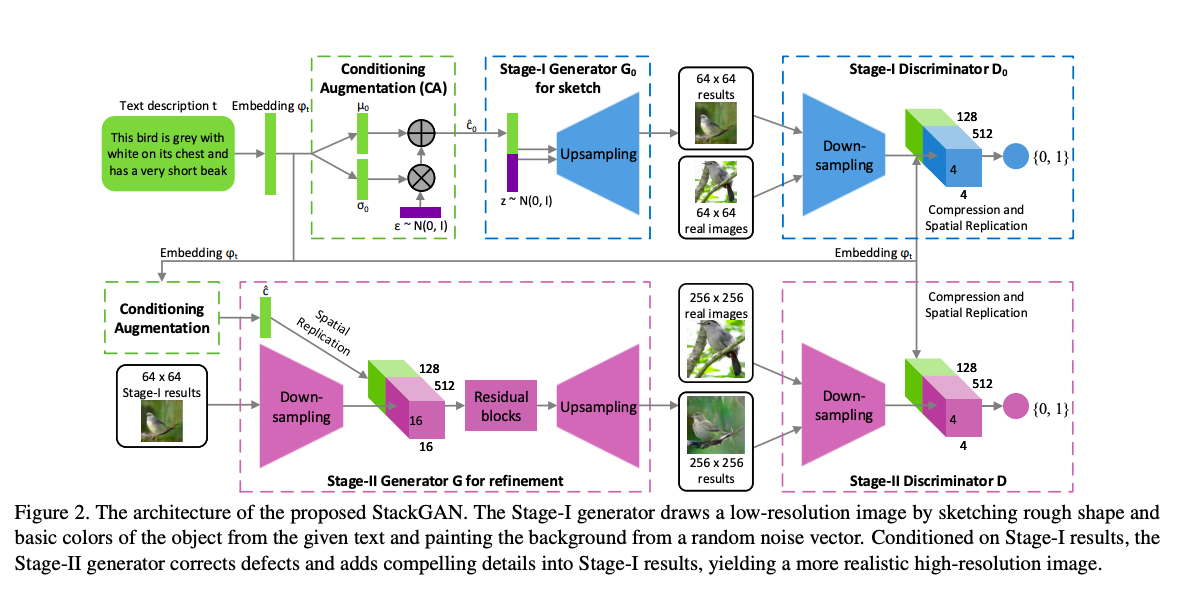
結果

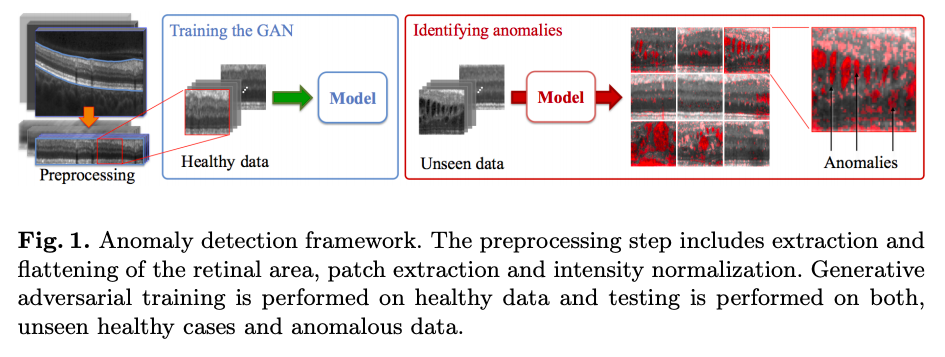
AnoGAN
概要
画像の異常検出を試みるGANです。入力画像の潜在変数に対応するzを探し、Generatorで画像を復元します。このとき入力画像を比較して差があったら異常、そうでなければ正常として異常検出をしています。
ネットワーク構造
DCGANと同様です。
結果
赤い部分が異常として出ています。
追加予定
おわりに
GANはまだまだ進化すると思うので、サーベイを続けてまた更新したいと思います。