背景
2018年発表のBERTから、分類や回帰タスクは、マスク学習等で事前学習したモデルをfine-tuningすることが一般的になりました。2019年にはT5という、翻訳や要約等のseq2seqタスクにおいても有効な事前学習手法が提案されました。このあたりでは、パラメータを大きくしたり、事前学習に用いるデータを大きくすることで、fine-tuning後の精度が向上する傾向が続いています。
2020年発表の「Language Models are Few-Shot Learners」は、上記の枠組みとは大きく異なるアプローチでNLPの個別タスクに適用します。これによって、fine-tuning (モデルのパラメータ更新) なしで 各タスクを行えるようになりました。
論文を発表したOpenAIは、GPTモデルの事前学習の大規模化を進めていました。GPTはトークンの系列が与えられた時に、その次に続くトークンを予測するというタスクを事前学習として行っています。このタスクを1,750億パラメータまで大きくしたモデルで学習させると、タスクの説明といくつかの例示により、さまざまなタスクにおいて高精度を出すようになりました。
具体的には以下のようにタスク説明と例示を与えます。翻訳タスクを行う旨と、いくつかの翻訳ペアの例を与えたのち、翻訳したいテキストを入力とすることで、欲しい翻訳結果が得られます。

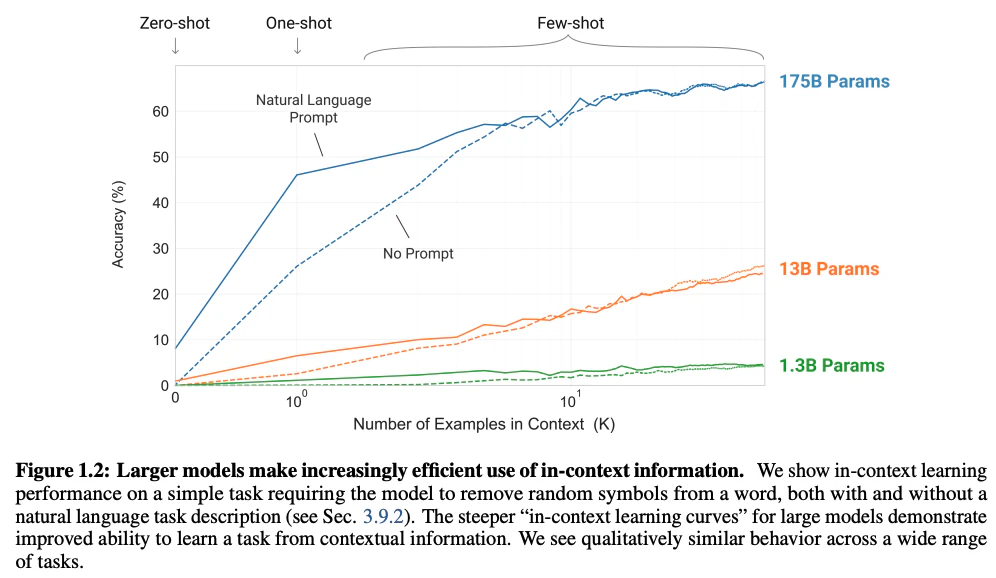
面白いのは、同じ事前学習データを使っていても、モデルサイズが異なることにより、飛躍的に精度が向上している点です。
以下はあるタスクの結果です。
緑線の13億パラメータでは精度はかなり低いですが、1,750億パラメータとなると精度が大きく向上します。
こうした新しい Few-shotの精度評価は次のようなタスクで行うことが多いです。
- BIG Bench [Srivastava et al., 2022]
- MMLU evaluation [Hendrycks et al., 2021]
- TruthfulQA [Lin et al., 2021]
- LogiQA [Liu et al., 2020]
- QuALITY [Pang et al., 2021]
- TriviaQA [Joshi et al., 2017]
- Lambada [Paperno et al., 2016]
- Codex HumanEval [Chen et al., 2021]
- GSM8k [Cobbe et al., 2021]
また、大規模言語モデル (LLM) の能力についてもいろいろな研究が進んでおり、以下のものが有名です。
- Multi-step reasoning: 算数の文章問題などを解く際に答えだけでなく解く過程を出力することで精度を上げるテクニック (chain-of-thought)
- Program execution: 足し算の位上げを例として与えて計算させたり、コードの出力を得る際に一行ずつ計算過程を出力することで精度を上げるテクニック (scratchpad)
- Model calibration: モデルに回答と共に、正しく回答できている確率 (自信) を出力させる方法
そのほかのLLMの能力はこちらにまとめられています。
概要
言語モデルが自身の主張することの正当性を評価したり、どの質問を正しく回答できるかを予測できるかどうかを研究した論文です。
それについて、以下の観点から説明しています。
- Calibration
- Self-Evaluation of Generated Samples
- Finetuning to Identify the Questions Models Can Correctly Answer
- Glossary
P(True)を用いた回答選択
キャリブレーション
2クラス分類をするときに各クラスのデータ数に偏りがある場合、アンダーサンプリングしてデータの比率を1:1にすることがあったりしますが、それでは実際の発生確率と異なる発生確率のデータ分布を学習することになってしまいます。
現実のクラス発生分布に対する偏った予測を補正すること (したもの) をキャリブレーションと呼びます。
本論文でFew-shotで多肢選択問題を解いてキャリブレーションを調べました。
多肢選択問題は次のようなものです。
Question: Who was the first president of the United States?
Choices:
(A) Barack Obama
(B) George Washington
(C) Michael Jackson
Answer:
Reliability Diagram
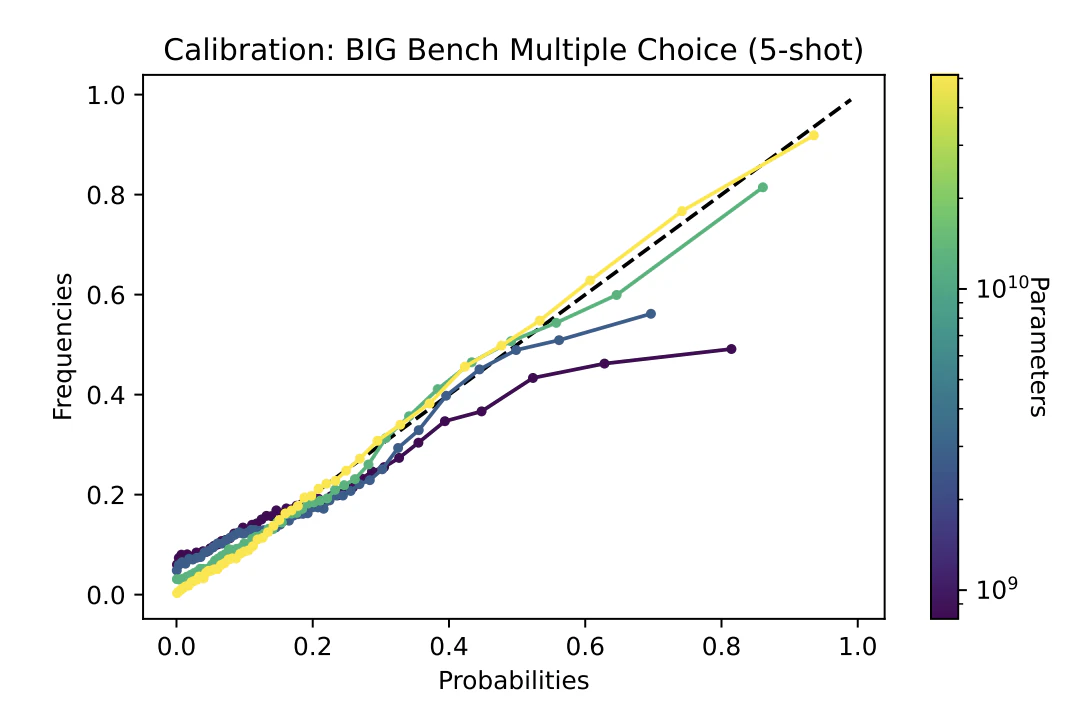
Reliability Diagramとは予測モデルによって得られたスコア値に対してプロットされた事象の観測頻度のグラフとなります.キャリブレーションの可視化では頻繁にこのグラフが用いられます. 横軸にはビン毎の予測されたスコア値の平均を,縦軸には各ビン毎のポジティブなラベルの割合を示したものになります.要するに,y=x 上にプロットが近くにつれて予測値を確率として扱う信頼度が高いということが言えます.
Reliability Diagramは次のようになりました。
モデルのパラメータが大きくなるほどより良いキャリブレーションとなっています。
次に、質問と答えのペアを与えたときに、TrueかFalseで答えるようにして、キャリブレーションを調べました。
Question: Who was the first president of the United States?
Proposed Answer: George Washington
Is the proposed answer:
(A) True
(B) False
The proposed answer is:
結果として、正しくキャリブレーションされることがわかりました。
以上の結果をふまえて、オープンエンドの質問応答タスクについて、まずいくつか回答を言語モデルに作らせて、それらが正しい確率 P(True) を評価させ、大きいものを選択するアプローチを考えます。
Question: Who was the third president of the United States?
Here are some brainstormed ideas: James Monroe
Thomas Jefferson
John Adams
Thomas Jefferson
George Washington
Possible Answer: James Monroe
Is the possible answer:
(A) True
(B) False
The possible answer is:
この方法をとると、最初から1つの答えを出させるよりも精度があがったそうです。
P(IK) を用いたモデル知識の確認
次に、モデルが質問に対する答えをモデル自身が知っているかの確率 P(IK) を学習できるかどうかを調査しました。
以下の2つのアプローチを考えました。
- Value Head: モデルに追加された value head の logit をもとに訓練する方法
- Natural Language: モデルに「どれくらいの自信を持って回答しましたか?」と聞いて、「30%」のように答えさせる方法
論文では Value Head の方法を取ります。
Natural Language の方法はうまくいかなかったので、将来再トライするそうです。
Value Head はモデルアーキテクチャに変更を加えるため、fine-tuningする必要があります。
最後のトークンからP(IK)を求めて、1に近いほど答えに自信を持っていることを表します。
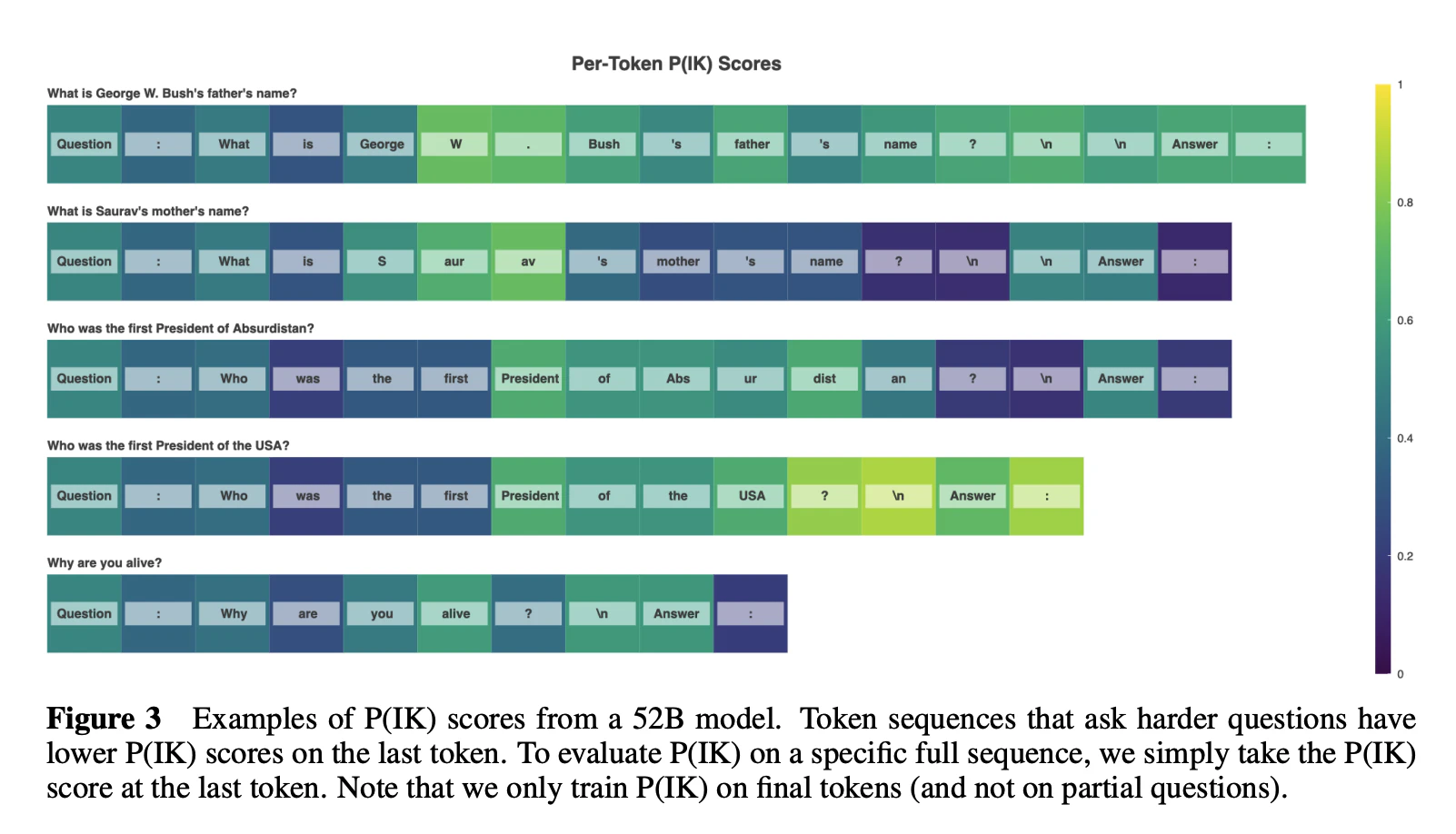
TriviaQAデータセットが大規模なデータセットであるため、こちらでfine-tuningしました。
TriviaQAの各質問ごとにモデルで30個の回答サンプルを作成します。
回答のうち正しいもの (ground truth?) が20個、正しくないものが10個だった場合、それらをValue Headで識別するようにfine-tuningします。これらのラベルに対してクロスエントロピー損失を用いて学習します。
結果として、モデルはP(IK)の予測に成功し、タスク間で部分的に汎化しましたが、新しいタスクでのP(IK)のキャリブレーションに苦労しました。
また、予測されたP(IK)確率は、文脈中の関連する資料を加えることで、適切に増加することがわかりました。
例えば、以下の問題は難しく、P(IK)は 18% ほどですが、
What state’s rodeo hall of fame was established in 2013?
次のようにwikipediaの情報を加えることでP(IK)は 78% まで増加しました。
Wikipedia: The Idaho Rodeo Hall of Fame was established as a 501 (c)(3) nonprofit organization on May 6, 2013. Lonnie and Charmy LeaVell are the
founders of the organization. The actual charitable nonprofit status was
received from the IRS on February 19, 2014. The IRHF hosts a reunion and
induction ceremony annually every October. The Idaho Hall of Fame preserves
and promotes the Western lifestyle and its heritage. The hall exists to
dedicate the men and women in rodeo who contribute to ranching and farming
through their sport. It also extends its reach to continue these western
ways to the youth in the communities to ensure that these traditions
continue for many generations. In 2015, the hall was awarded the Historic
Preservation Recognition Award by National Society of the Daughters of the
American Revolution.
What state’s rodeo hall of fame was established in 2013?