AIが画像生成してくれる、Python OSSであるSatableDiffusionを使ってみた
1. Anacondaが必要なのでこちらを参考にインストール
https://qiita.com/thithi7110/items/fd273fb7ae148b5335bc)
2. githubからstable-diffusionをクローン
github: stable-diffusion
3. Anaconda promptを起動し、ルートフォルダで以下を実行
conda env create -f environment.yaml
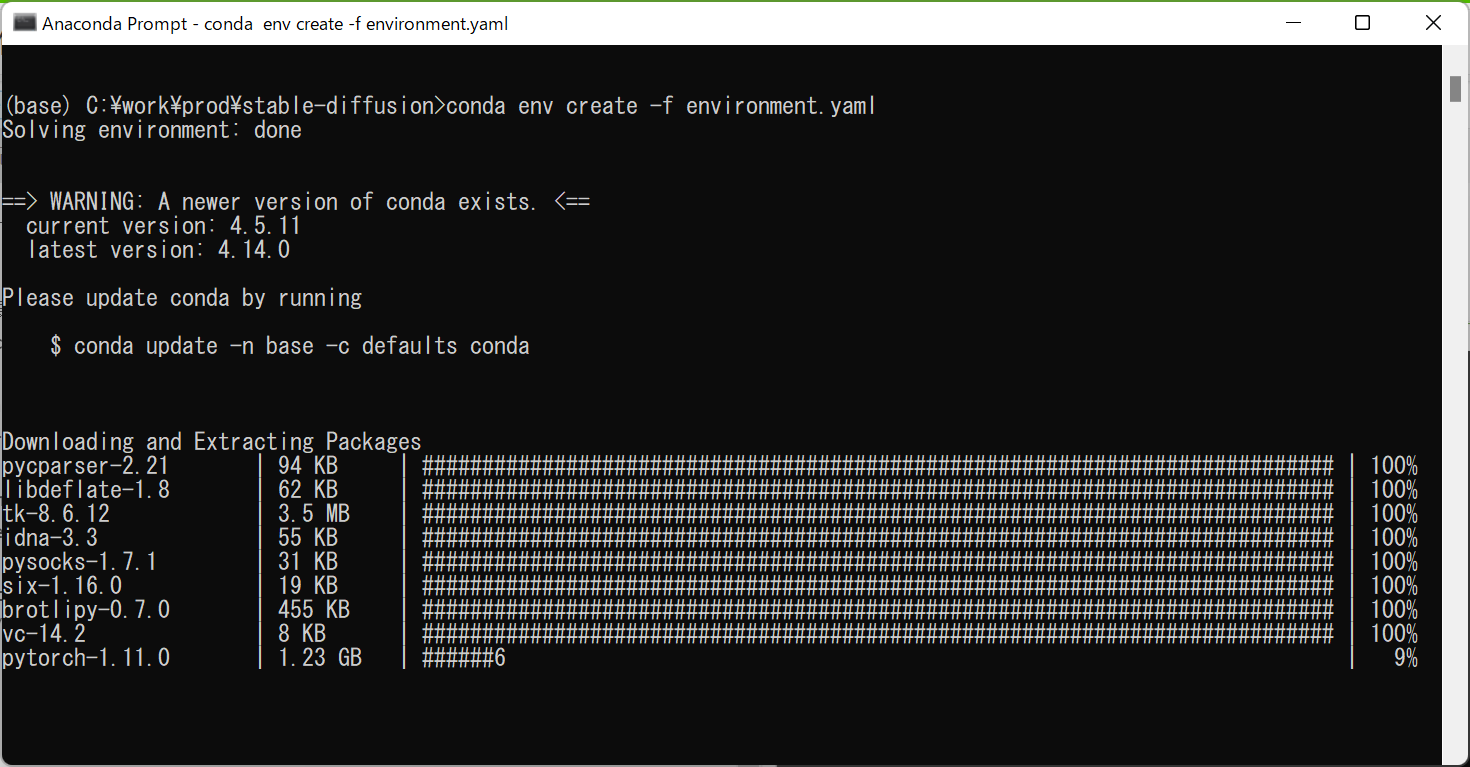
何やらエラーが・・
WARNING: pip is configured with locations that require TLS/SSL, however the ssl module in Python is not available.
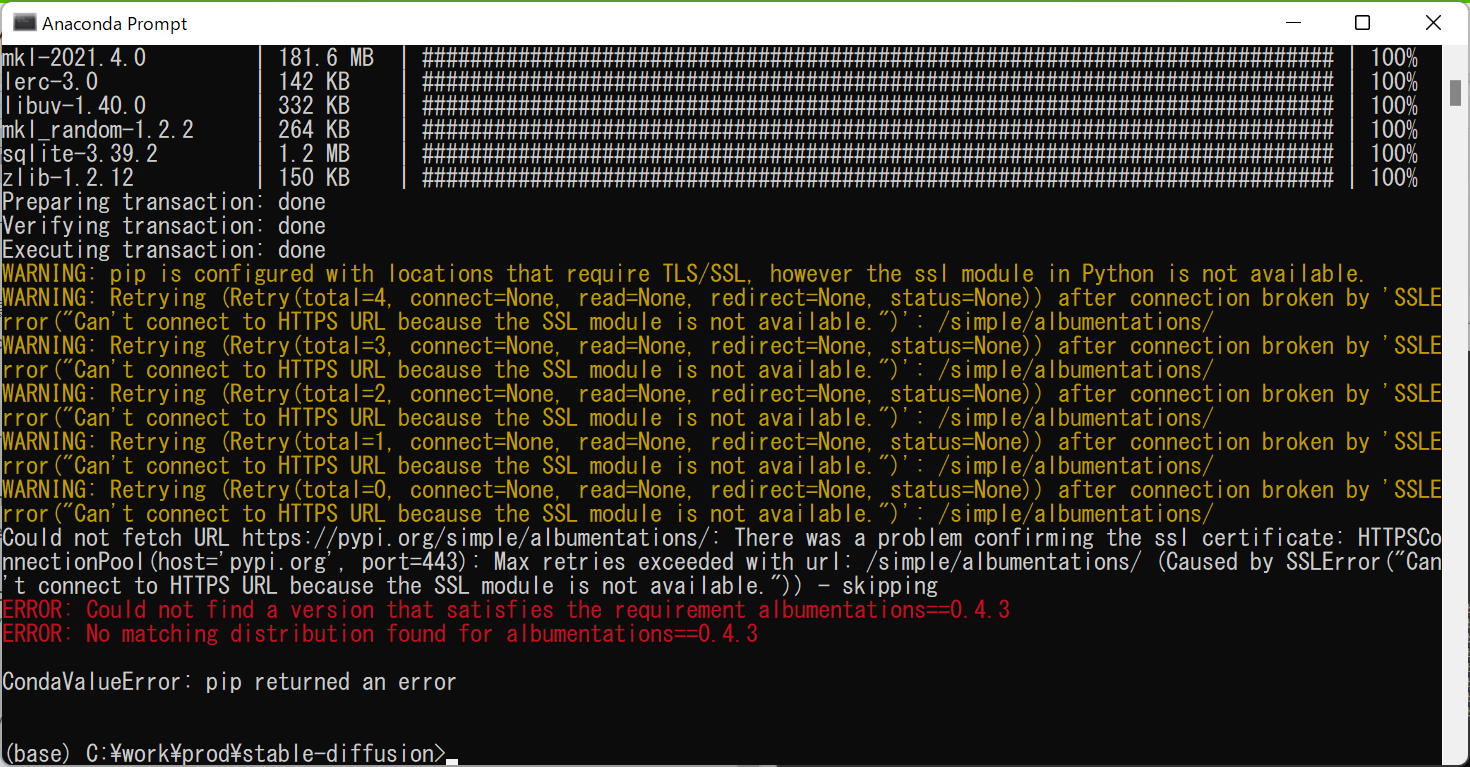
環境変数追加したり、dll移動したりとやったけどAnacondaが古かったことが原因のよう。
(上記のAnacondaは最新のものに変えたバージョンのリンクを記載しております)
次に発生したエラーはコマンド実行できるgit入っていない・・(soucetree使ってたのでgitコマンド使えるようにしていなったため)
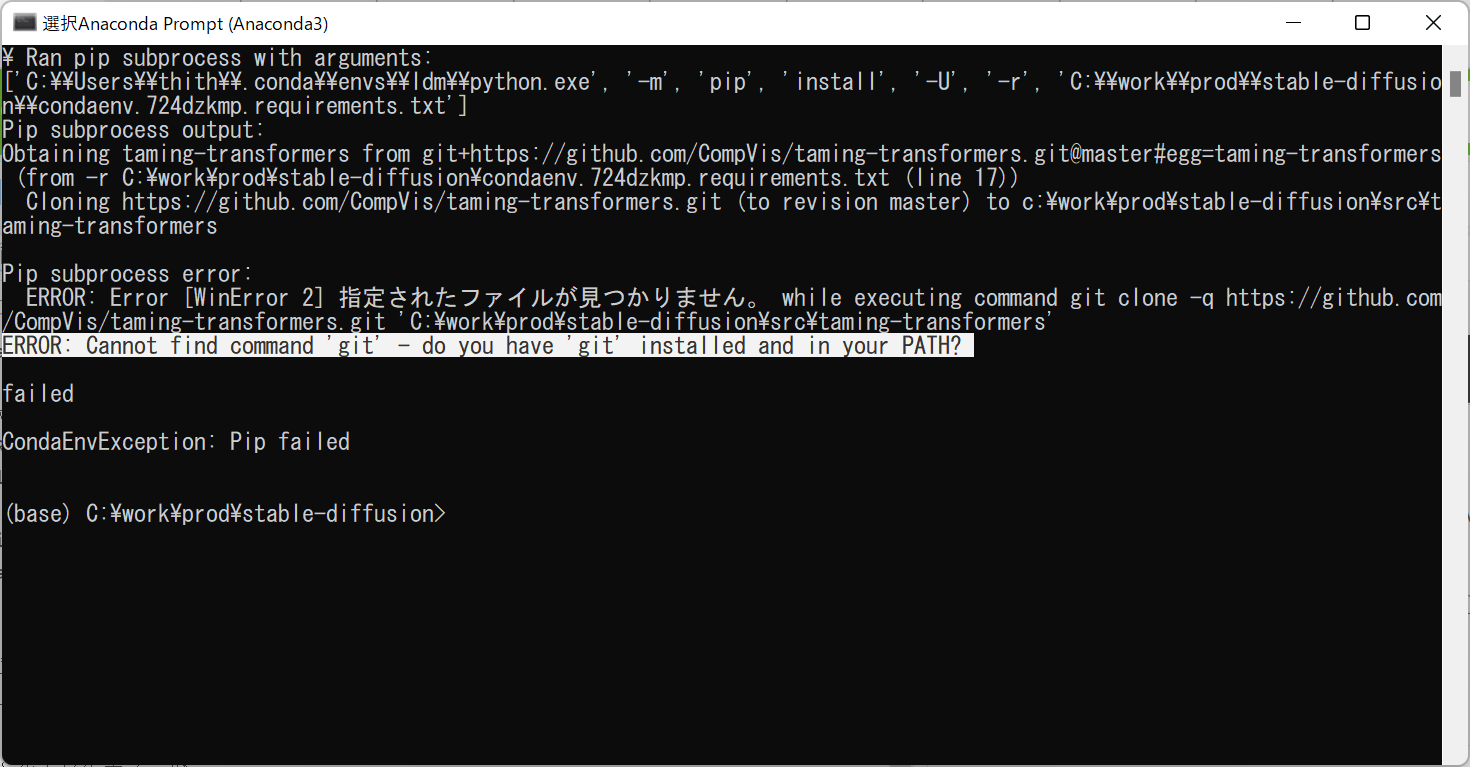
git入れときます。
https://qiita.com/taiponrock/items/632c117220e57d555099
再度実行、別窓でくるくる めちゃ時間がかかる・・あとサイズ約600MBと大きいので注意
4. ldmを有効にする
conda activate ldm
5. pytorchのインストール 1GBほどあるので注意
conda install pytorch torchvision -c pytorch
6. transformersのinstallとeditable mode実行
pip install transformers==4.19.2 diffusers invisible-watermark
pip install -e .
7.試しに動かすためのckpt(チェックポイント)ファイルを取得
the CompVis organization at Hugging Face から取得
https://huggingface.co/CompVis
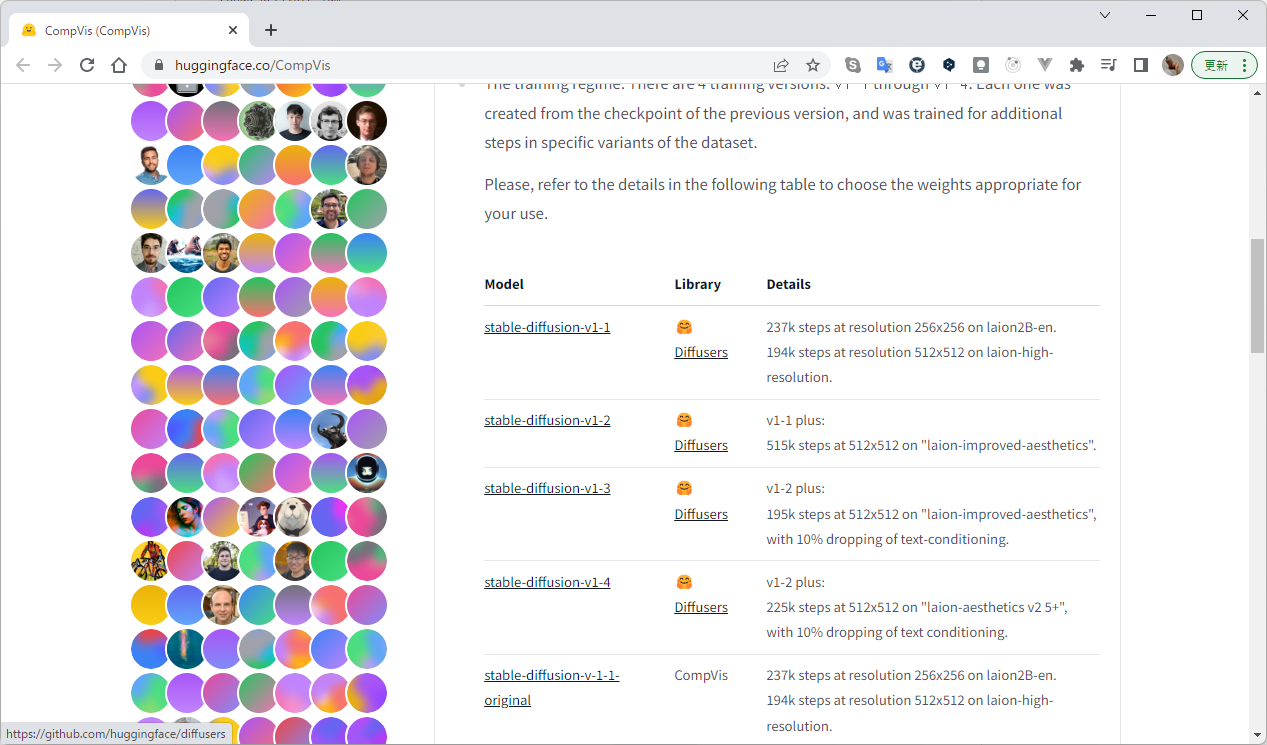
Modelの欄のstable-diffusion-v1-1-original
https://huggingface.co/CompVis/stable-diffusion-v-1-1-original
※サインアップとライセンスへの同意が必要。
Files and versionsの欄のsd-v1-1.ckptファイルを選択し、download実施
※4gbほどの大きいファイル
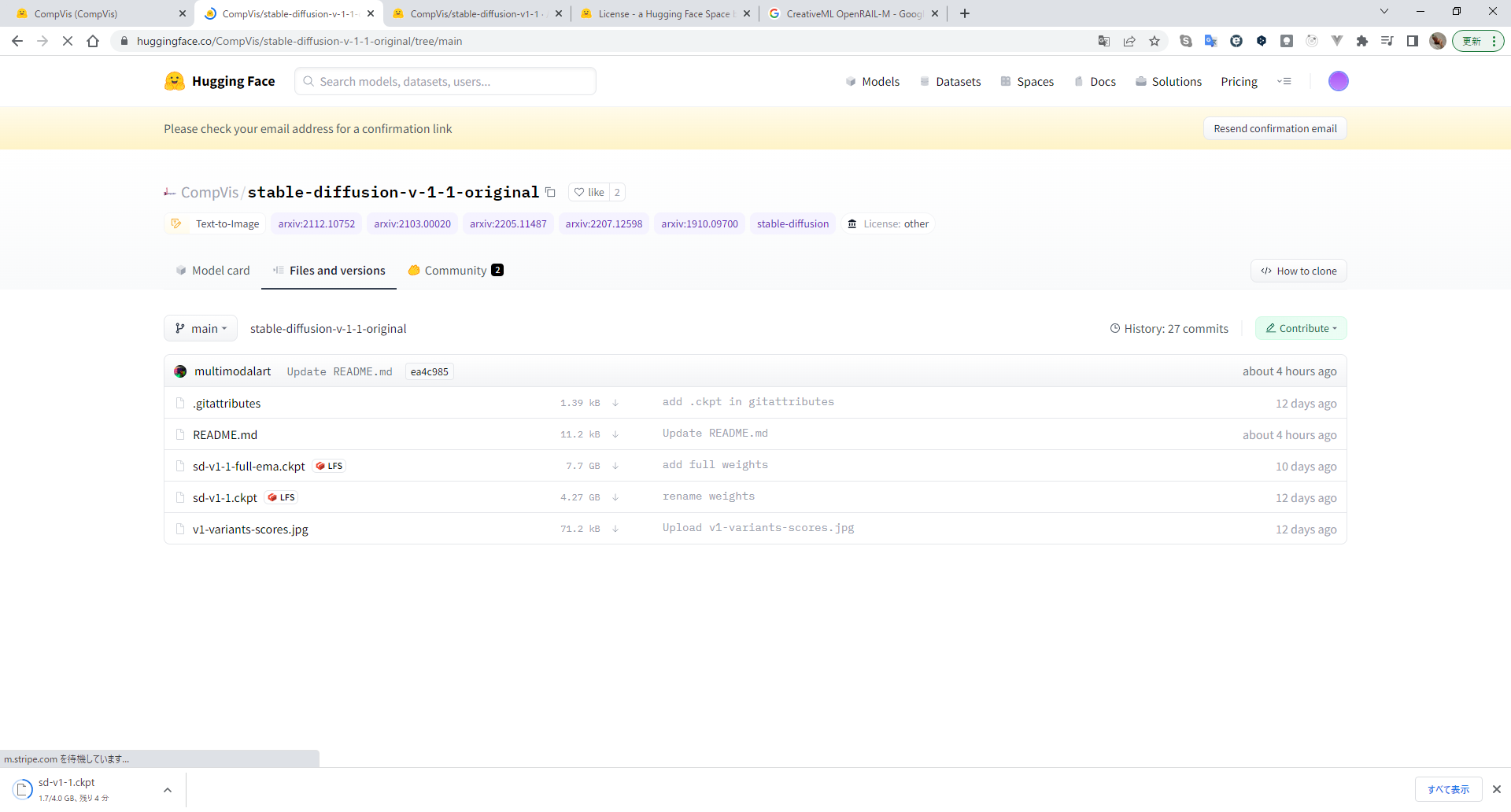
ダウンロードしたファイルを以下に移動
C:\work\prod\stable-diffusion\models\ldm\stable-diffusion-v1
名前をmodel.ckptに変更