※本Qiita は
(1)「初心者からちゃんとしたプロになるPython基礎入門 大津 真・田中賢一郎 共著 MdN社」
(2)「確かな力が身につくPython「超」入門 鎌田正浩 著 SB Creative社」👈個人的にはPythonの最初の1冊として最適でした
(3)https://qiita.com/python_academia/items/62aefbf4e373cd2aa496
を主に利用した学習をもとに作成しました。(なお、私は(1)の途中で一旦、tkinterって結局何なん??(´д`)?? ⇒(2)を読んでから(1)あぁ(・∀・)みたいな感じでした。「~入門」にも甘辛が存在するようです。)
なお以下、Anaconda(※3)を使わずに
Visual Studio CodeのみでScrapyを使用する方法
を記述しました。少し長くなったため、本編(A)・(B)と補足編((C)~(F))に分けましたまた、Pythonでしか使わないような単語を使わないと、説明がそれこそニシキヘビが如く超長くなりそうなので、できるだけ本Qiitaを短くするため、また、備忘録としても意味合いを兼ね今後個人的に謎単語であったものには一番下に注釈をつけました。(※~の数字部分がそれぞれ対応します)
少し使ってみた感想
・そもそも「スクレイピング」は自分の成果物にかけても効果を発揮する???
・Scrapyは比較的スクレイピングそのものにかかる時間が少なそう
・yield文とかいう謎言語さえクリアすれば、Scrapyはリファクタリング(refactoring、再設計)の際のコードの重複を調べるのに重宝しそう。jsonが作れるのは便利
・以外とAnacondaなしでも結構使えそう。やっぱりPythonって無理にAnacondaを使う必要はないんじゃないか??(真のよわよわにとって環境構築って本当に面倒いんで(´д`))
・Scrapyは比較的スクレイピングそのものにかかる時間が少なそう
・yield文とかいう謎言語さえクリアすれば、Scrapyはリファクタリング(refactoring、再設計)の際のコードの重複を調べるのに重宝しそう。jsonが作れるのは便利
・以外とAnacondaなしでも結構使えそう。やっぱりPythonって無理にAnacondaを使う必要はないんじゃないか??(真のよわよわにとって環境構築って本当に面倒いんで(´д`))
・以外とAnacondaなしでも結構使えそう。やっぱりPythonって無理にAnacondaを使う必要はないんじゃないか??(真のよわよわにとって環境構築って本当に面倒いんで(´д`))
補足編 https://qiita.com/thinking-weed/private/1f6671694f96fc3fbd1e
(A)Scrapyは蠱毒の壺で蜘蛛を飲み込んだ蛇~> ̄ )~~~~~~~~~~~~~~~~~~~~~~~
「クローリング&スクレイピングを行うプログラム(=ウェブ上の文書や画像などを周期的に取得し、自動的にデータベース化するプログラム)」のことを
「クローラー」「Web Spider(Web(インターネット(net?)上に巣を張る)蜘蛛)」「Spider(蜘蛛)」
などと呼ぶようです。※以下スパイダーとします。ChatGPTにもスパイダーが組み込まれているものと思われます。そして、
Scrapyは、Webページの取得からデータの抽出、保存までをサポートしてくれるスクレイピングによるデータ収集に特化したPythonのフレームワーク
みたいです。
なお、Pythonは英語で「ニシキヘビ属」を指しますが、Anacondaは実はニシキヘビ属ではないみたいです。
(B)Laravelで作った自分のポートフォリオ(のresources の .blade.php)をサンプルにScrapyでスクレイピングしてみた実際の様子
(i)フレームワークっぽくない(プロジェクト)を作らない方法によるスクレイピング
①スクレイピングしたい対象のHP等の スクレイピングに関する規約(※補足編(D)参照)を調べる(※今回は自分のポートフォリオで個人情報に繋がるところは鍵をつけてある外部リンクのため必要なし)
▽
((規約に反しなければ)各タグなどを確認するためにソースコードかデベロッパーツール(=検証ツール)のElementsパネルの階層化されたHTMLを開く(今回は、.blade.phpファイルを開くことになる))
▽
③ 補足編の(E)等の方法でScrapyをインストールしたのち、Visual Studio Codeでターミナルを開いて(powershell か zsh(※学習に利用していた民間スクールのチーム開発で一緒だった人がMacで、対応するのがzshだったので、たぶんzshです))
scrapy shell
で、Enterクリック(※終了時はexit()でEnterクリック)し、Scrapy Shell(対話モード)を開始する。つまり、
ScrapyはPythonならでは??のinteractive(※6)shell(対話モード)が存在するという変な?フレームワーク
です。(※自分がまだ実務未経験なのであくまで「変な」というのは主観です)
なお、ターミナルに貼り付けをするときは、Windowsの場合、VScodeなら、コピーをしてある状態で、所定の位置にカーソルを合わして、マウスで右クリックするとペーストできます。
※Scrapy Shellを開始すると以下のようになります。

▽
④ 以下のコマンドで、対象のページからHTMLが、responseというオブジェクトに格納されるみたいです。 (内蔵のスパイダーが起動する??)
fetch("https:~対象のWebページのURL~")
⑤ 取得したresponseオブジェクトから、HTMLファイル全体をテキストとして取り出す(※ここでは「text」というオブジェクトに新たに格納することを指すと思われます )には、上のfetchコマンドの後に
response.text
でEnterクリック(結果、こんな感じになりました。)

ターミナルのところに取得したとされているHTMLが表示されるのですが、タグを見た感じ
ホーム画面の.blade.php(LaravelにおけるHTMLに変換されるファイル形式)しか読み込まれていない... (〃_ _)σ)Д`) ソリャソウヵ。だって、よく考えたら、ルーティングの関係でURLちがうんだもの・・・
(他の.blade.phpファイルも当然ポートフォリオ(=1プロジェクト)には含まれているため(SPA(※)ではないです。))
なお、fetchコマンドで格納した後は、beautifulsoup4(※補足編(C)を参照)等と同様、Scrapy も
response.css("セレクタ名(h2など)")
等のメソッドを使って諸々できそうです(全部のメソッドを書くと冗長すぎるのでここでは割愛します。※補足編(E)の公式ドキュメント参照)
(ⅱ)フレームワークっぽい(プロジェクト)を作る方法によるスクレイピング
① プロジェクトを以下のコマンドで作成する
フレームワークというぐらいなんで、同じフレームワークであるLaravelと同様に「プロジェクト」という一定のまとまった単位でプログラムを作成して+@として「スクレイピング」の要素が加えられるみたいです。
cd プロジェクトを保存したいディレクトリのパス
scrapy startproject プロジェクト名
結果、こんなのができます。(以下、portfolio_check_spidersという名前でプロジェクトを作って実験してみた結果)

▽
② 日本語がエンコード化された形式で表示されない(=文字化け)ように
上記のsettings.pyに追記
FEED_EXPORT_ENCODING='utf-8'
▽
③ 上の作成したプロジェクト内のspidersフォルダの中に各サイトをスクレイピングするスパイダーを以下のコマンドで作る
(上記のプロジェクトのフォルダを開いた状態で、もしくはcdコマンドで移動した状態で)
scrapy genspider スパイダー名 スクレイピングをかけたいWebサイトのURLから「https://」を除いたもの
例えば、(※今回は自分のポートフォリオのホームページをモルモットにしました)
scrapy genspider HomePageSpider 該当のURLからhttps://を除いたもの
で結局以下みたいなやつがでてきます

▽
④ 上記の青枠のメソッドの部分をいじり、スパイダーを動かして、jsonで保存してみる。
ポートフォリオのホーム画面の一部
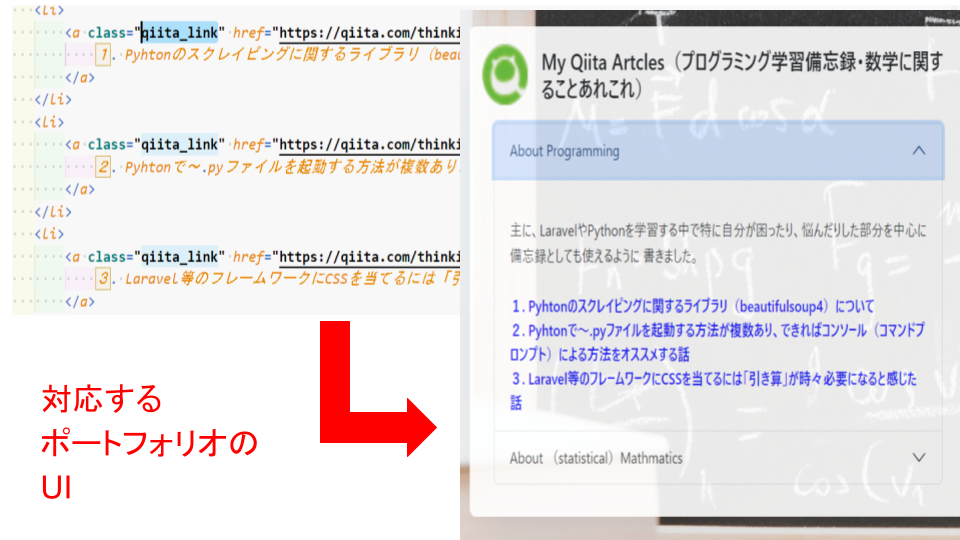
これに対し、以下の図のようにいじったスパイダーに対して
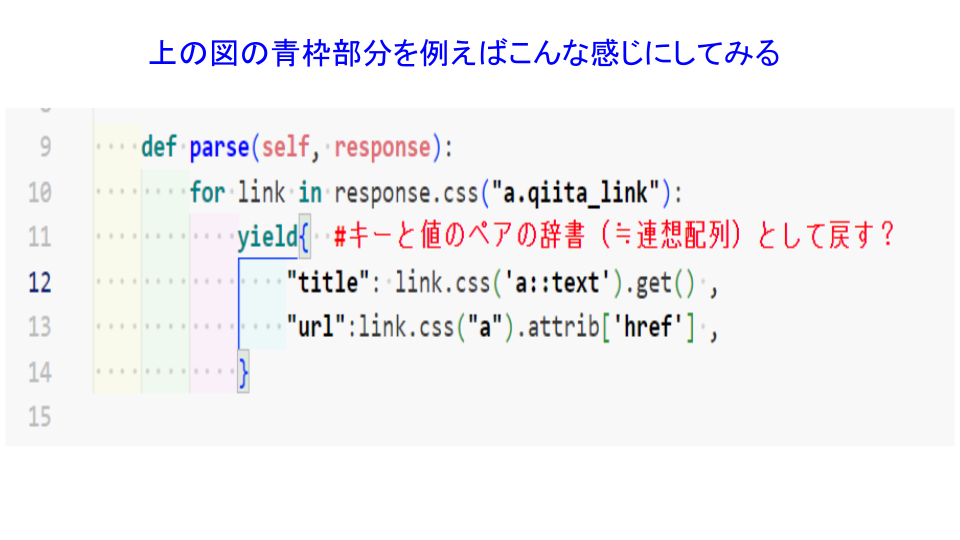
次のコマンドを実行すると、不格好ではありますが、一応確かにjsonファイルがプロジェクト内にできました。
(※プロジェクトのフォルダを開いた状態で、ターミナルで実行)
scrapy crawl HomePageSpider -o qiita_links.json
なお、
scrapy crawl スパイダー名(-o 作成するjsonファイルにつけるファイル名.json)
で、()部分はない場合は出力結果がただターミナルに表示されるだけでした。
※スパイダーは動く
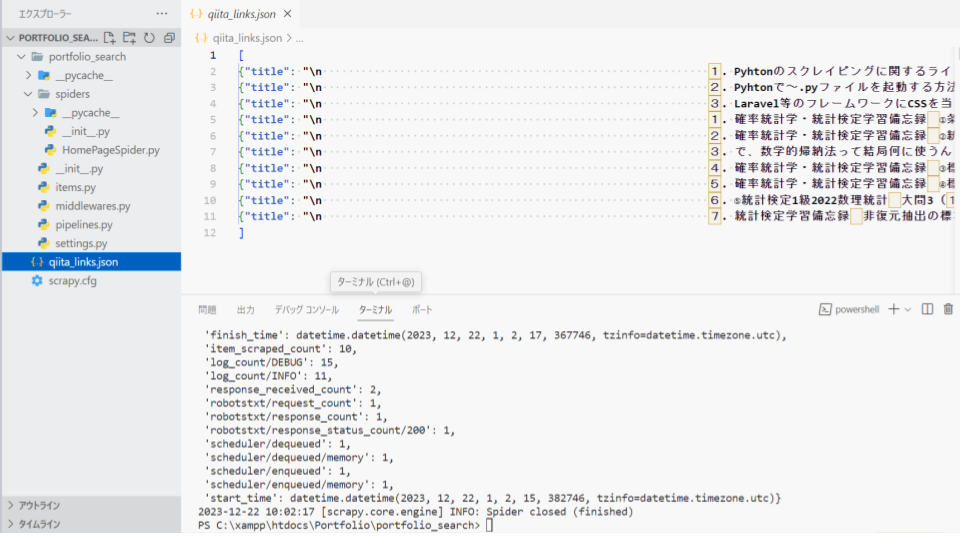
上のコマンドで プロジェクト内にできた.json が以下の図(なぜ、余分な改行の消し方とかはまだ謎です(たぶん、yield文のせい))

個人的に謎だった単語リスト
(※1)(Pythonにおける)仮想環境:(用途に応じた)実行環境を提供する機能。必要に応じて切り替えて使用できる。
(※2)ディストリビューション:Python本体に加えて様々なモジュールやツール類をまとめた配布形態
(※3)Anaconda:アナコンダ、Python本体に加えてデータサイエンスに有益な様々なパッケージが追加されたディストリビューション
(※4)パーソナライズ:企業側がそれぞれのユーザーの属性、趣味嗜好、行動データ履歴といったデータにあわせて情報提供すること (例 各ユーザーに合うような広告が出てくる)
(※5)サードパーティクッキー:訪れたサイト以外のドメインから発行されるクッキー。もうすぐ廃止されるらしいので代替策の検討が必要。参考資料 https://infinity-agent.co.jp/lab/thirdpartycookie_2024/
(※6)interactive:「相互の」「双方向の」を意味する英単語。このモード(対話モード)にすると、1行ずつプログラムを入力していくことになります。なお、打ち間違いをした場合、そこで一旦処理が止まる?ため再度打ち直すと、またそこから「ターミナルを開いている以上は」そこから処理が続きます。
(※7)SPA:(Single Page Applicaitonの略)単一の html ファイル上で javascript を使って画面遷移することなくユーザの操作に応じて動的に変化する Web アプリケーション (Web サイト) 。