はじめに
GraphQLのPython用フレームワークgrapheneのチュートリアルとflask-graphene-sqlalchemyがとてもよかったので自分なりにの構成と環境構築をまとめました。
grapheneではなくFlaskとSQLAlchemyを使用を前提としたライブラリFlask-Graphene-SQLAlchemyのチュートリアルを参考に行なって行きます。
そんなにGraphQL詳しくないのでとりあえず写経から初めて、ディレクトリの構成とかチュートリアルにはないが気になるところを追記しています。
作ったもの: https://github.com/thimi0412/Flask-Graphene-SQLAlchemy
環境構築
仮想環境構築にはPipenvを使用
$ pipenv install --python 3.7
$ pipenv install sqlalchemy \
graphene-sqlalchemy \
flask \
flask-graphql
データベースはsqliteを使用。サクッとチュートリアルをやってみたかったんでDocker使ってなくてすまん。
ディレクトリ構成
├── Pipfile #みんなご存知Pipfile
├── Pipfile.lock
├── README.md
├── app.py #サーバ
├── database #データベース情報
│ ├── base.py
│ ├── model_department.py
│ ├── model_employee.py
│ └── model_role.py
├── database.sqlite3
├── schema #GraphQlの中核を担う部分
│ ├── schema.py
│ ├── schema_department.py
│ ├── schema_employee.py
│ └── schema_role.py
└── setup.py #初期データ登録用
チュートリアルではdatabese, schemaはそれぞれ1ファイルに記述されていたのでモデルごとに分割。
データベース作成
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import scoped_session, sessionmaker
engine = create_engine('sqlite:///database.sqlite3', convert_unicode=True)
Base = declarative_base()
Base.metadata.bind = engine
db_session = scoped_session(sessionmaker(bind=engine, expire_on_commit=False))
Base.query = db_session.query_property()
データベースの情報を記述します。
テーブル定義
from .base import Base
from .model_department import ModelDepartment
from .model_role import ModelRole
from sqlalchemy import (
Column, DateTime, ForeignKey, Integer, String, func
)
from sqlalchemy.orm import backref, relationship
class ModelEmployee(Base):
__tablename__ = 'employee'
id = Column(Integer, primary_key=True)
name = Column(String)
hired_on = Column(DateTime, default=func.now())
department_id = Column(Integer, ForeignKey('department.id'))
role_id = Column(Integer, ForeignKey('roles.id'))
department = relationship(
ModelDepartment,
backref=backref('employees', uselist=True, cascade='delete,all'))
role = relationship(
ModelRole,
backref=backref('roles', uselist=True, cascade='delete,all'))
from .base import Base
from sqlalchemy import Column, Integer, String
class ModelDepartment(Base):
__tablename__ = 'department'
id = Column(Integer, primary_key=True)
name = Column(String
from .base import Base
from sqlalchemy import Column, Integer, String
class ModelRole(Base):
__tablename__ = 'roles'
id = Column(Integer, primary_key=True)
name = Column(String)
チュートリアルではEmployee(従業員), Department(部門), Role(役職)のテーブルを作成し、リレーションを張っています。
ここは、SQLAlchemyのテーブルの作成とかわりありません。
テストデータを入れる
from database.model_department import ModelDepartment
from database.model_role import ModelRole
from database.model_employee import ModelEmployee
from database import base
import logging
import sys
log = logging.getLogger(__name__)
logging.basicConfig(
stream=sys.stdout,
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
if __name__ == "__main__":
log.info('Create database')
base.Base.metadata.create_all(base.engine)
log.info('Insert data')
engineering = ModelDepartment(name='Engineering')
base.db_session.add(engineering)
hr = ModelDepartment(name='Human Resources')
base.db_session.add(hr)
manager = ModelRole(name='manager')
base.db_session.add(manager)
engineer = ModelRole(name='engineer')
base.db_session.add(engineer)
peter = ModelEmployee(name='Peter', department=engineering, role=engineer)
base.db_session.add(peter)
roy = ModelEmployee(name='Roy', department=engineering, role=engineer)
base.db_session.add(roy)
tracy = ModelEmployee(name='Tracy', department=hr, role=manager)
base.db_session.add(tracy)
base.db_session.commit()
チュートリアルでは対話モードでデータを入れていましたがGitHubのリポジトリではスクリプトを作成して、データを入れていたので参考にして作成。とりあえずこれを実行すればOK。
テーブルは以下のように作成されます。
sqlite> select * from employee;
1|Peter|2019-09-09 03:08:31|1|2
2|Roy|2019-09-09 03:08:31|1|2
3|Tracy|2019-09-09 03:08:31|2|1
sqlite> select * from department;
1|Engineering
2|Human Resources
sqlite> select * from roles;
1|manager
2|engineer
スキーマを作成する
from database.model_employee import ModelEmployee
import graphene
from graphene import relay
from graphene_sqlalchemy import SQLAlchemyConnectionField, SQLAlchemyObjectType
class EmployeeAttribute:
name = graphene.String(description='Name of Role')
hired_on = graphene.DateTime(description='Hired_on date')
department_id = graphene.Int(description='ID of Department')
role_id = graphene.Int(description='ID of Role')
class Employee(SQLAlchemyObjectType, EmployeeAttribute):
class Meta:
model = ModelEmployee
interfaces = (relay.Node,)
Model = ModelEmployee
from database.model_department import ModelDepartment
import graphene
from graphene import relay
from graphene_sqlalchemy import SQLAlchemyConnectionField, SQLAlchemyObjectType
class DepertmentAttribute:
name = graphene.String(description='Name of Department')
class Department(SQLAlchemyObjectType, DepertmentAttribute):
class Meta:
model = ModelDepartment
interfaces = (relay.Node,)
Model = ModelDepartment
from database.model_role import ModelRole
import graphene
from graphene import relay
from graphene_sqlalchemy import SQLAlchemyConnectionField, SQLAlchemyObjectType
class RoleAttribute:
name = graphene.String(description='Name of Role')
class Role(SQLAlchemyObjectType, RoleAttribute):
class Meta:
model = ModelRole
interfaces = (relay.Node,)
Model = ModelRole
Queryを作成
from graphene_sqlalchemy import SQLAlchemyConnectionField
from graphene import relay
import graphene
from . import schema_department
from . import schema_role
from . import schema_employee
class Query(graphene.ObjectType):
node = relay.Node.Field()
employee_list = SQLAlchemyConnectionField(schema_employee.Employee)
department_list = SQLAlchemyConnectionField(schema_department.Department)
role_list = SQLAlchemyConnectionField(schema_role.Role)
schema = graphene.Schema(query=Query)
REST APIで言うところのGET /hogehogeをここで作成指定ます。Queryクラス内でemployee_list, department_list, role_listをの関数を定義指定ます。
ちなみに関数をスネークケースで定義していますがGraphQLではキャメルケースとして解釈されます。
URLを設定
from database.base import db_session
from flask import Flask
from flask_graphql import GraphQLView
from schema.schema import schema
app = Flask(__name__)
app.add_url_rule(
'/graphql',
view_func=GraphQLView.as_view('graphql', schema=schema, graphiql=True)
)
@app.teardown_appcontext
def shutdown_session(exception=None):
db_session.remove()
if __name__ == "__main__":
app.run(threaded=True, debug=True)
GraphQLにアクセスするURLは1つだけなので/graphql配下にschemaを設定します。
Queryを投げてみる
サーバを起動
pipenv run python app.py
http://localhost:5000/graphql にアクセスするして画面左の入力画面に以下のクエリを記述して右上のRUNボタンを押すとクエリが実行されます。
ここがすごい! コピペしてもいいですが補完がすごいので比較的楽に入力できる
query{
employeeList{
edges{
node{
name
hiredOn
department{
name
},
role{
name
}
}
}
}
}

とりあえずチュートリアルの内容がここまでとなっていました。なので以降は個人的に必要そうな内容です。
[追加]従業員名で検索したい
従業員全ての情報は取得することができたので名前で検索して、情報を取得します。 個人的にここがハマって辛かった。
schema.pyを編集します。
class Query(graphene.ObjectType):
node = relay.Node.Field()
# 追加
employee = graphene.Field(lambda: schema_employee.Employee,
name=graphene.String())
employee_list = SQLAlchemyConnectionField(schema_employee.Employee)
department_list = SQLAlchemyConnectionField(schema_department.Department)
role_list = SQLAlchemyConnectionField(schema_role.Role)
# 追加
def resolve_employee(self, info, name):
query = schema_employee.Employee.get_query(info)
result = query.filter(schema_employee.Model.name == name).first()
return result
schema = graphene.Schema(query=Query)
employeeと言う関数を追加して、employeeが呼ばれた時実際に処理を行う関数resolve_employeeを作成します。これはresolve_<関数名>と解釈されるのでclassで追加した関数名と同じである必要があります。
ここで注意したいのは、resolve_employeeで実際にSQLAlchemyで名前で検索を行なっているところです。
最初はschema_employee.Employeeを使用してfilterで検索をしようとしていましたが、これはGraphQLを解釈するたのクラスのなので、SQLAlchemyで作成したクラス(databese/model_employee.py)のクラスを使用する必要があります。
なのでschema/schema_employee.pyの最後の行にdatabese/model_employee.pyクラスをModelとして定義しています。
Model = ModelEmployee
早速検索
query{
employee(name: "Roy"){
name
department{
name
}
role{
name
}
}
}

[追加]データを追加したい
データを追加する場合はMutateを使用します。REST APIのPOST/PUTに相当。 shema/schema.pyを編集します。
from graphene_sqlalchemy import SQLAlchemyConnectionField
from graphene import relay
import graphene
from . import schema_department
from . import schema_role
from . import schema_employee
from database import base # 追加 db_sessionを使用するため
# 追加
class InsertEmployee(graphene.Mutation):
# 貰うパラメータの設定
class Arguments:
name = graphene.String(required=True)
department = graphene.String(required=True)
role = graphene.String(required=True)
employee = graphene.Field(lambda: schema_employee.Employee)
# テーブルにインサートする処理
def mutate(self, info, name, department, role):
department = schema_department.Model(name=department)
base.db_session.add(department)
role = schema_role.Model(name=role)
base.db_session.add(role)
employee = schema_employee.Model(
name=name, department=department, role=role)
base.db_session.add(employee)
base.db_session.commit()
return InsertEmployee(employee=employee)
class Query(graphene.ObjectType):
node = relay.Node.Field()
employee = graphene.Field(lambda: schema_employee.Employee,
name=graphene.String())
employee_list = SQLAlchemyConnectionField(schema_employee.Employee)
department_list = SQLAlchemyConnectionField(schema_department.Department)
role_list = SQLAlchemyConnectionField(schema_role.Role)
def resolve_employee(self, info, name):
query = schema_employee.Employee.get_query(info)
result = query.filter(schema_employee.Model.name == name).first()
return result
# 追加
class Mutation(graphene.ObjectType):
insert_employee = InsertEmployee.Field()
# mutationを追加
schema = graphene.Schema(query=Query, mutation=Mutation)
InsertEmployeeのクラスを作成し、クラス内にパラメータを受け取るクラスArguments、実際に処理を行う関数mutateを作成します。
ここも先ほどの名前で検索と同様にSQLAlchemyで作成したクラスを使用します。
そしてMutationクラスを作成し、schemaに追加します。
データを追加
以下のクエリでデータを追加
mutation{
insertEmployee(name: "Kosuke", department: "R&D", role: "chief doctor"){
employee{
name
department{
name
}
role{
name
}
}
}
}

確認としてemployeeListで最後の1件を取得します。
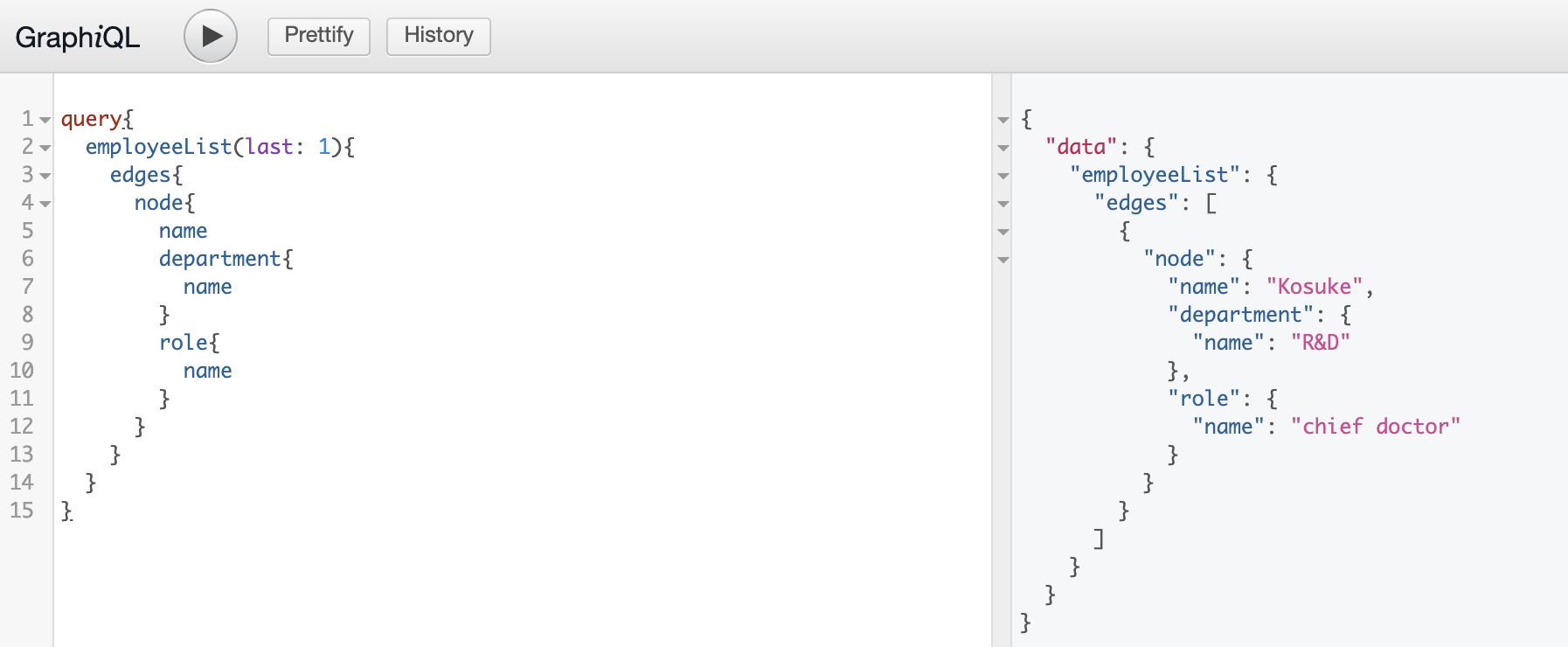
ちゃんとインサートできています。
GraphiQLがすごい
 `History`のボタンを押す今まで実行したクエリの履歴をみることができます。(地味にこれが便利)
お気に入り機能もあるのでよく使うクエリは登録することができます。
`History`のボタンを押す今まで実行したクエリの履歴をみることができます。(地味にこれが便利)
お気に入り機能もあるのでよく使うクエリは登録することができます。
ちなみにどこに履歴情報はブラウザのローカルストレージに格納されているようです。