Amazon Personalize の一般提供を開始!
先日Amazon Personalizeの一般提供を開始しました。
プレビューの段階からお試しで使っていたので作成の一連の流れを説明していきます。
今回はユーザーに商品を推薦するモデルとエンドポイントの作成を行います。
APIGatewayとLambdaを使用してAPIも作成しました。
課金体系(絶対に最初に目を通す!!!)
| 料金 | |
|---|---|
| データ取り込み | 0.05 USD/GB |
| トレーニング | 0.24 USD/トレーニング時間 |
| レコメンデーション | |
| 最初の 20K TPS-時間まで | 0.20 USD/1 TPS-時間のリアルタイムレコメンデーション |
| 次の 180K TPS-時間 | 0.10 USD/1 TPS-時間のリアルタイムレコメンデーション |
| 200K TPS-時間以上 | 0.05 USD/1 TPS-時間のリアルタイムレコメンデーション |
やらかしてしまった(大量のリクエストには気をつけて!!!)
後に記述しますがboto3を使用してレコメンドを取得します。
調子に乗ってAPIを叩きまくってしまった結果がこれです。
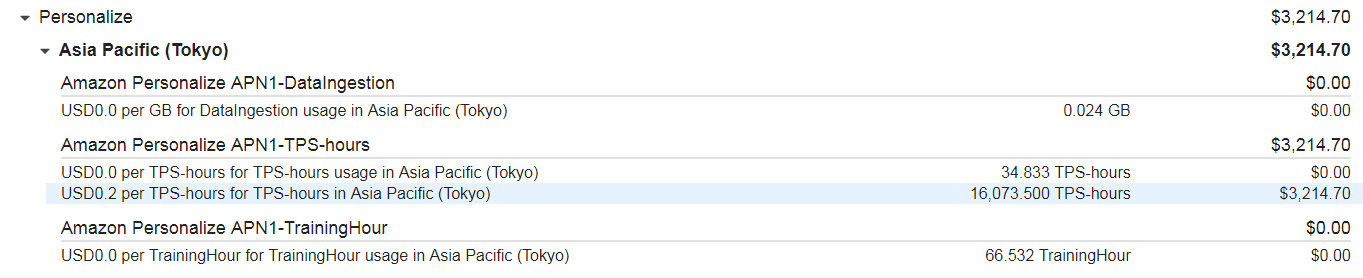

やらかしました。3124.7$って何円だっけ?(約33万円)思考停止です。
ユーザーがおよそ3万人いたのでどんな商品が推薦されるのか知りたくてこんなコードを書いたらなってしまいました。
len(users)
# およそ3万
for user in users:
recommend_item = personalizert.get_recommendations(
campaignArn="<Campaign ARN>",
userId=user['user_id'],)
personalizert = boto3.client(
'personalize-runtime',
region_name='ap-northeast-1')
のちに記述しますが、エンドポイント設定のTPSの上限値を低く設定して入れば回避できていました。(激しく後悔)
1. データを用意する
Amazon Personalizeにデータを読み込ませる際、S3にアップロードされたcsvファイルを使用します。
必要なデータ(ファイル)は以下の3つ(データセットの説明)
私はRedshiftからデータを取得し、pandas等を利用してcsvファイルを作成しました。
- ユーザーIDと商品IDが紐づいているデータ
- ユーザーIDにユーザー情報が紐づいているデータ
- 商品IDに商品情報が紐づいているデータ
それぞれ必須フィールドや予約キーワードがあります。
ユーザーIDと商品IDが紐づいているデータの例
ユーザーID、商品ID、購入時刻のUNIX時間が格納されているファイル
USER_ID,ITEM_ID, TIMESTAMP
582,456,1477897643
582,458,1477897643
582,490,1472037749
601,855,1472033257
601,451,1472033257
601,451,1472033257
602,454,1472033266
..................
USER_ID、ITEM_ID、TIMESTAMPが必須フィールドです。 予約語としてEVENT_TYPE、EVENT_VALUEが用意されています。AWSのドキュメントを読んでみた感じでは,EVENT_TYPEは購入方法(ネット購入や店舗購入)などのデータ、EVENT_VALUEは商品の値段などのデータを入れるフィールドだと感じました。
ユーザーIDにユーザー情報が紐づいているデータの例
ユーザーID、年齢、性別が格納されているファイル
USER_ID,AGE,GENDER
180,71,male
185,55,female
332,30,female
352,51,male
365,22,female
..................
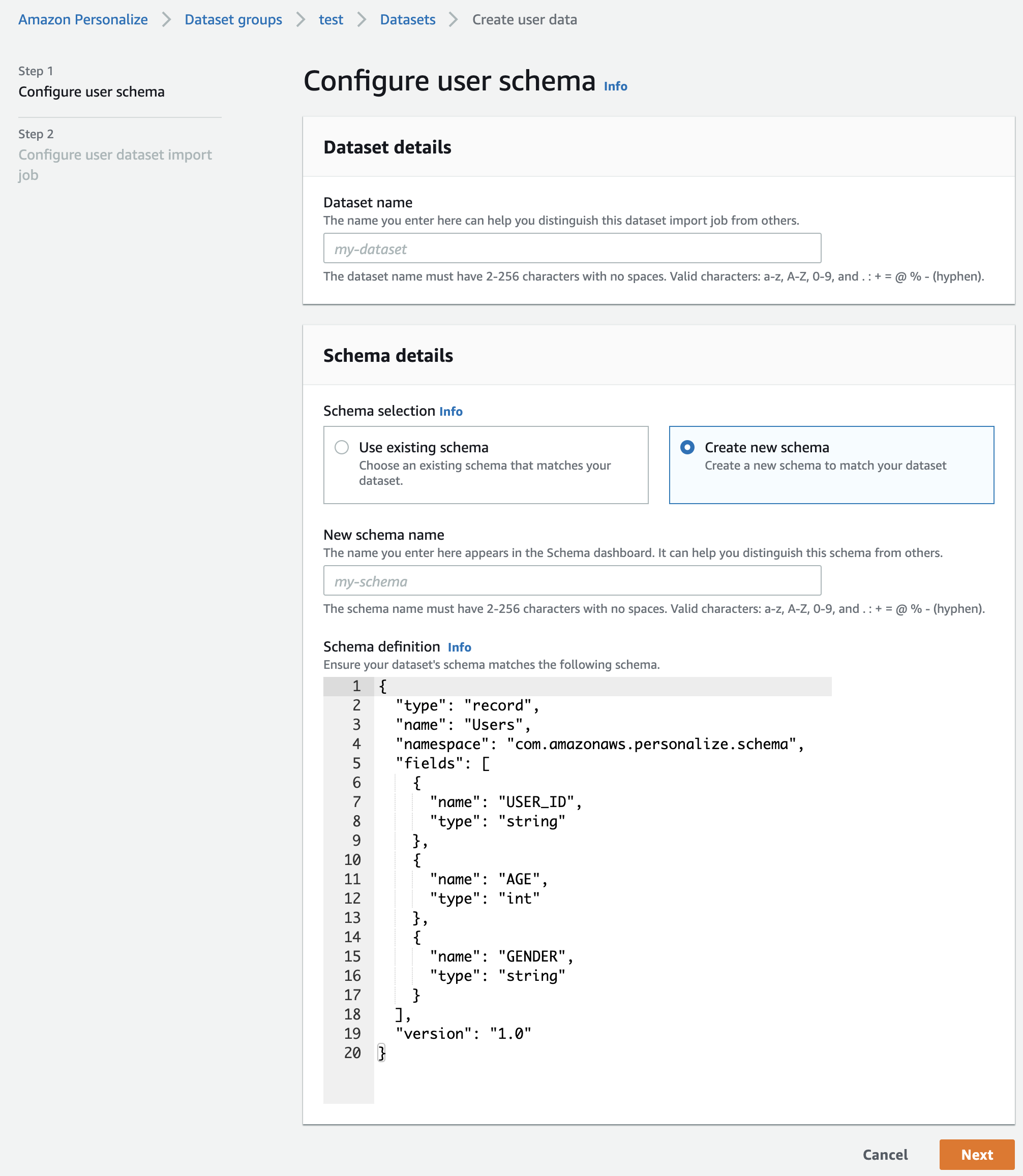
USER_IDが必須フィールドで残りのAGEとGENDERはデータセットの説明を真似しました。
商品IDに商品情報が紐づいているデータの例
商品ID、商品名、商品カテゴリーIDが格納されているファイル
ITEM_ID,ITEM_NAEM,CATEGORY_ID
461,歯ブラシ(青),1
693,オールスパイス ,10
112,赤ワイン,9
113,白ワイン,9
369,キャンドル(10本入),6
867,三角帽,15
..................
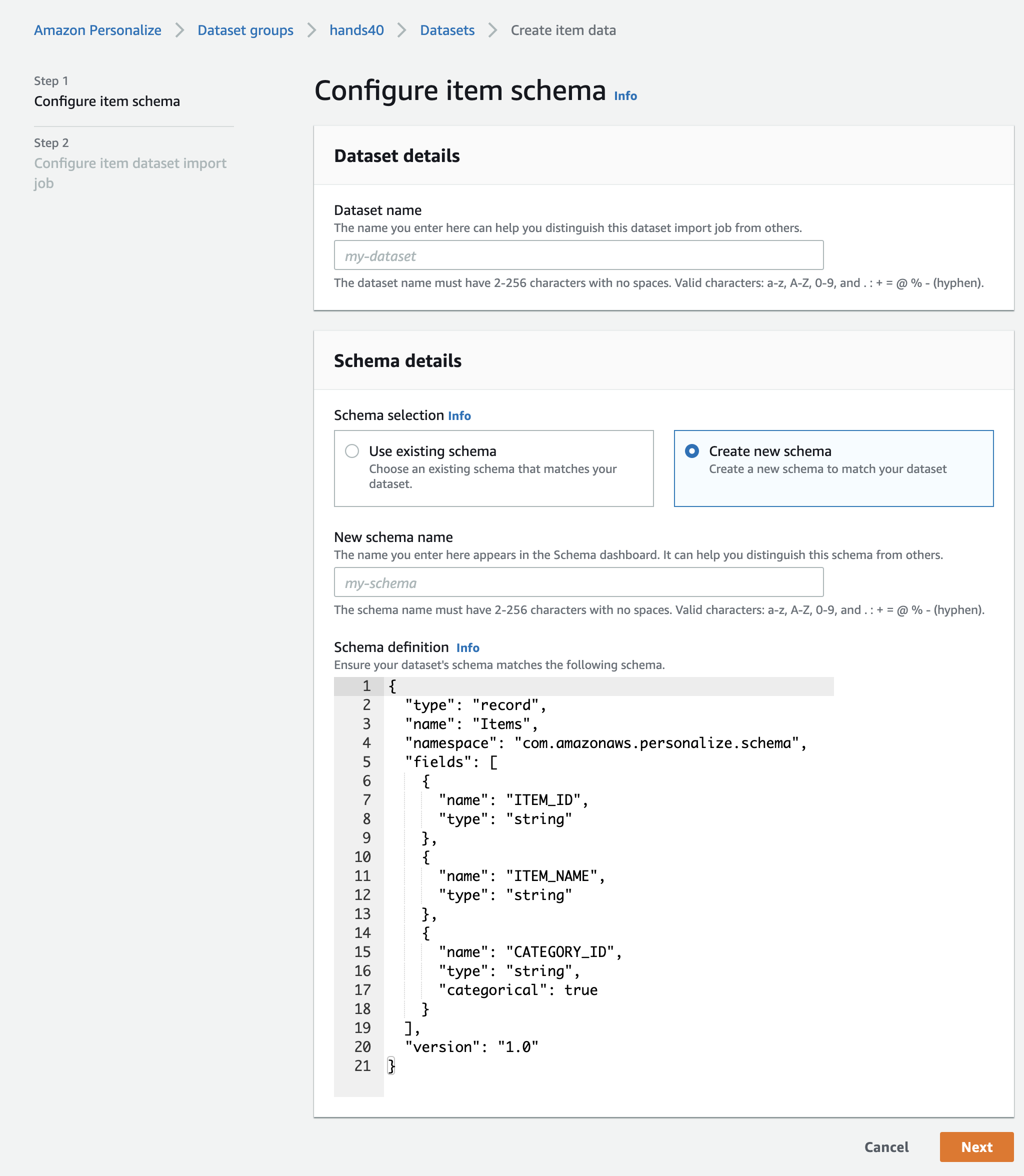
ITEM_IDが必須フィールドで残りのITEM_NAEMとCATEGORY_IDはこれもデータセットの説明をまねしてみました。フィールドを増やしても問題なさそうです。
2. S3にファイルをアップロードし、バケットポリシーを設定する
PersonalizeからS3にアクセスするためにバケットポリシーを作成します。
{
"Version": "2012-10-17",
"Id": "PersonalizeS3Bucket AccessPolicy",
"Statement": [
{
"Sid": "PersonalizeS3BucketAccessPolicy",
"Effect": "Allow",
"Principal": {
"Service": "personalize.amazonaws.com"
},
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::<作成したバケット名>",
"arn:aws:s3:::<作成したバケット名>/*"
]
}
]
}
2.データをインポートする
作成したcsvファイルをS3にアップロードしたら、Personalizeのコンソール画面からDataset groupsを作成します。
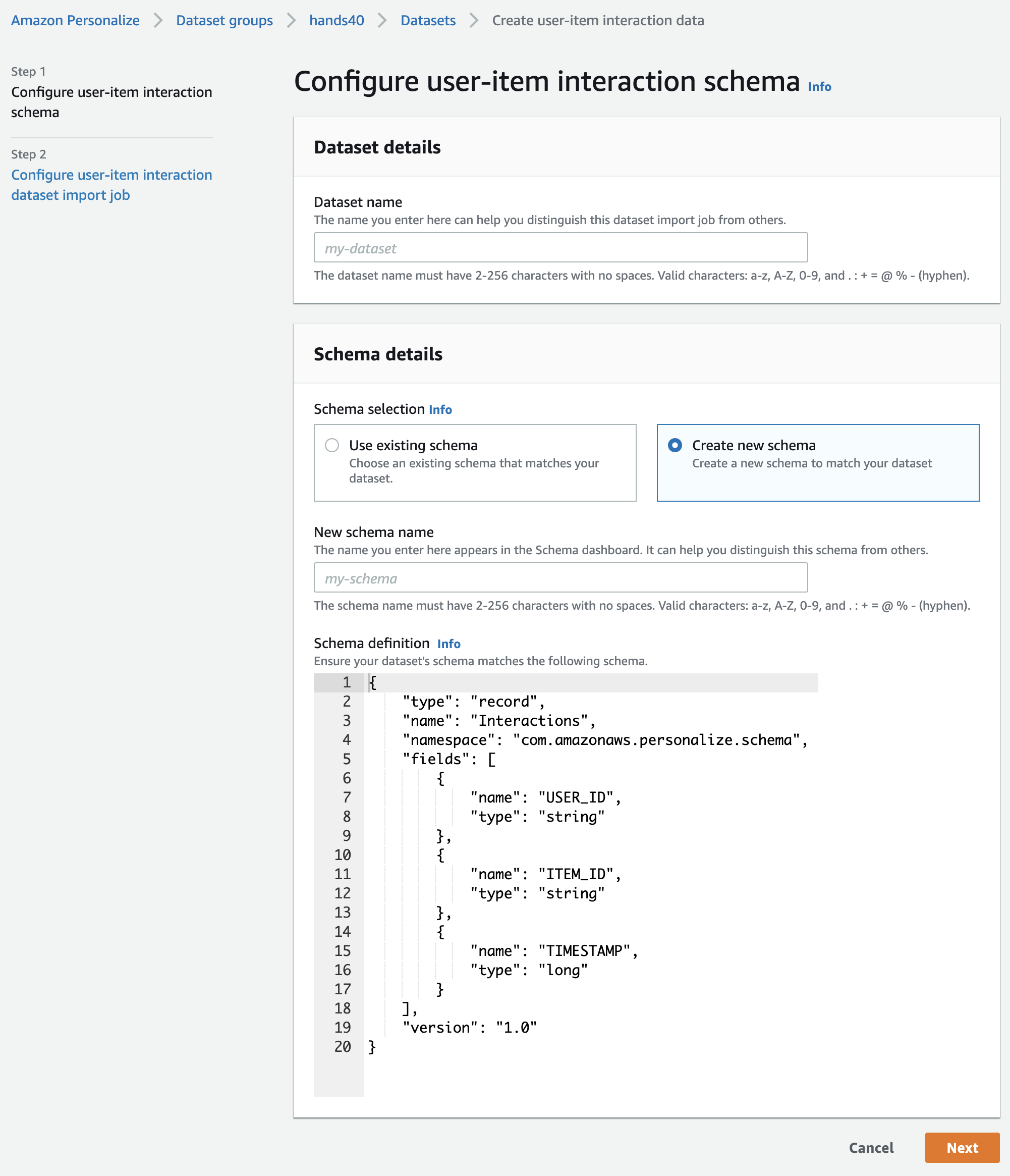
csvファイルのヘッダ名と同じようにSchema definitionを編集します。
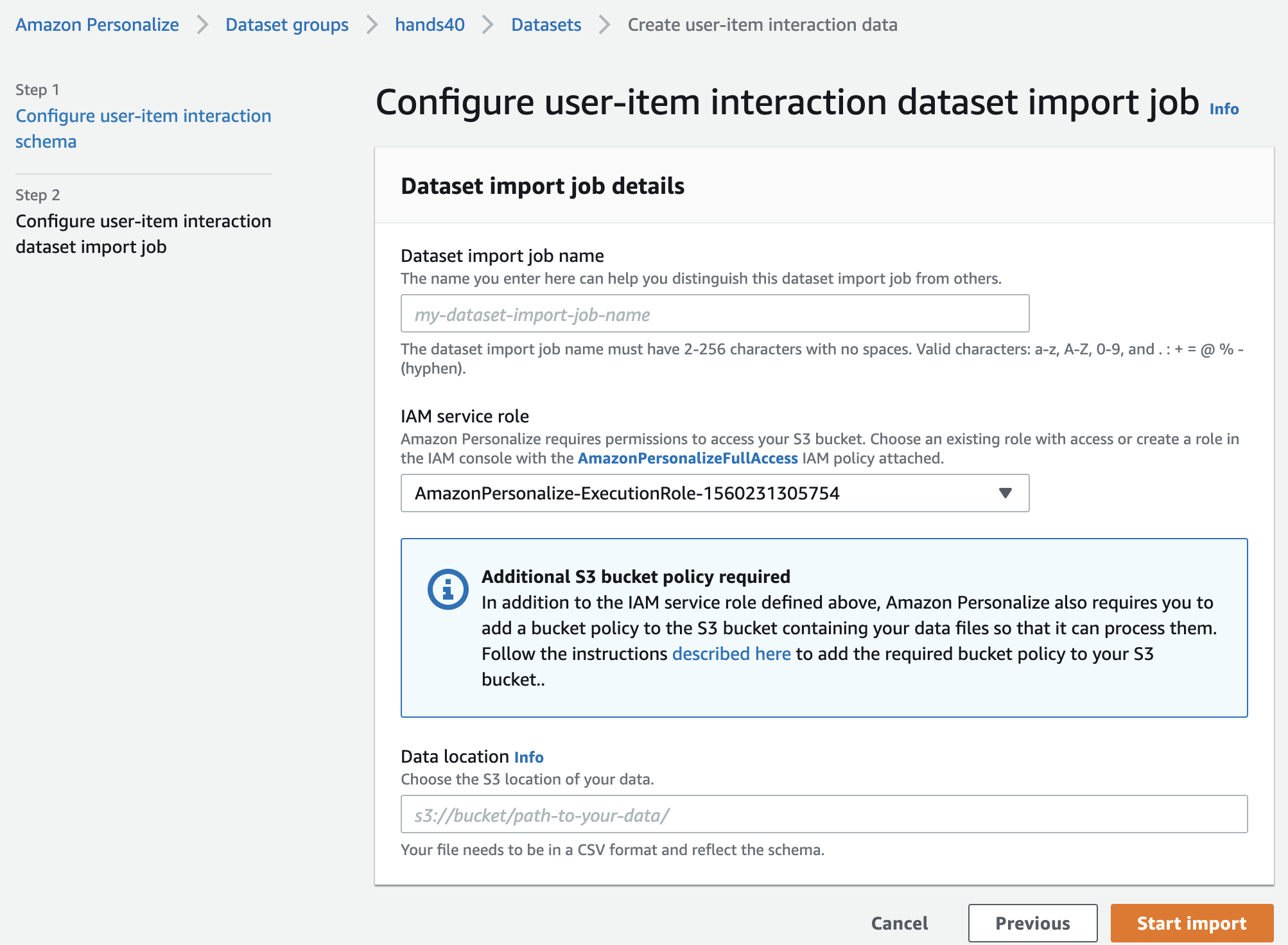
IAM service roleは今回は既存の物を使用しましたが、ここでも作成できます。
Data locationにS3のパスを書いてインポート開始です。
ダッシュボードをみるとCreate in progressになっています。
この調子でUser dataとItem dataも作成していきます。
User dataを作成
Item dataを作成
3. solutionsを作成する
データのインポートが全て終了したらsolutionsを作成します。
Automatic(AutoML)にチェックを入れるとインポートしたデータから適したモデルを作成します。
割と時間かかりました(1時間以上はかかった気がします)。
モデルをトレーニングするためのレシピの一覧
今回はaws-hrnnとaws-hrnn-metadataを使用していきます。
4. campaignを作成する
campaignの名前、solutionを設定、スループットの下限を設定して作成(30分くらい)。
(重要!)スループットの下限はなるべく少なくした方がいいです。DynamoDBのキャパシティーと同じ感じです。私はこの値をテキトーに200にして、エンドポイントを叩きまくってしまった結果高額な請求がきてしまいました。

5. レコメンドしてみる
campaignの作成が完了するとレコメンドのテストがコンソール画面上から行えるので適当なユーザーIDでテストしてみます。
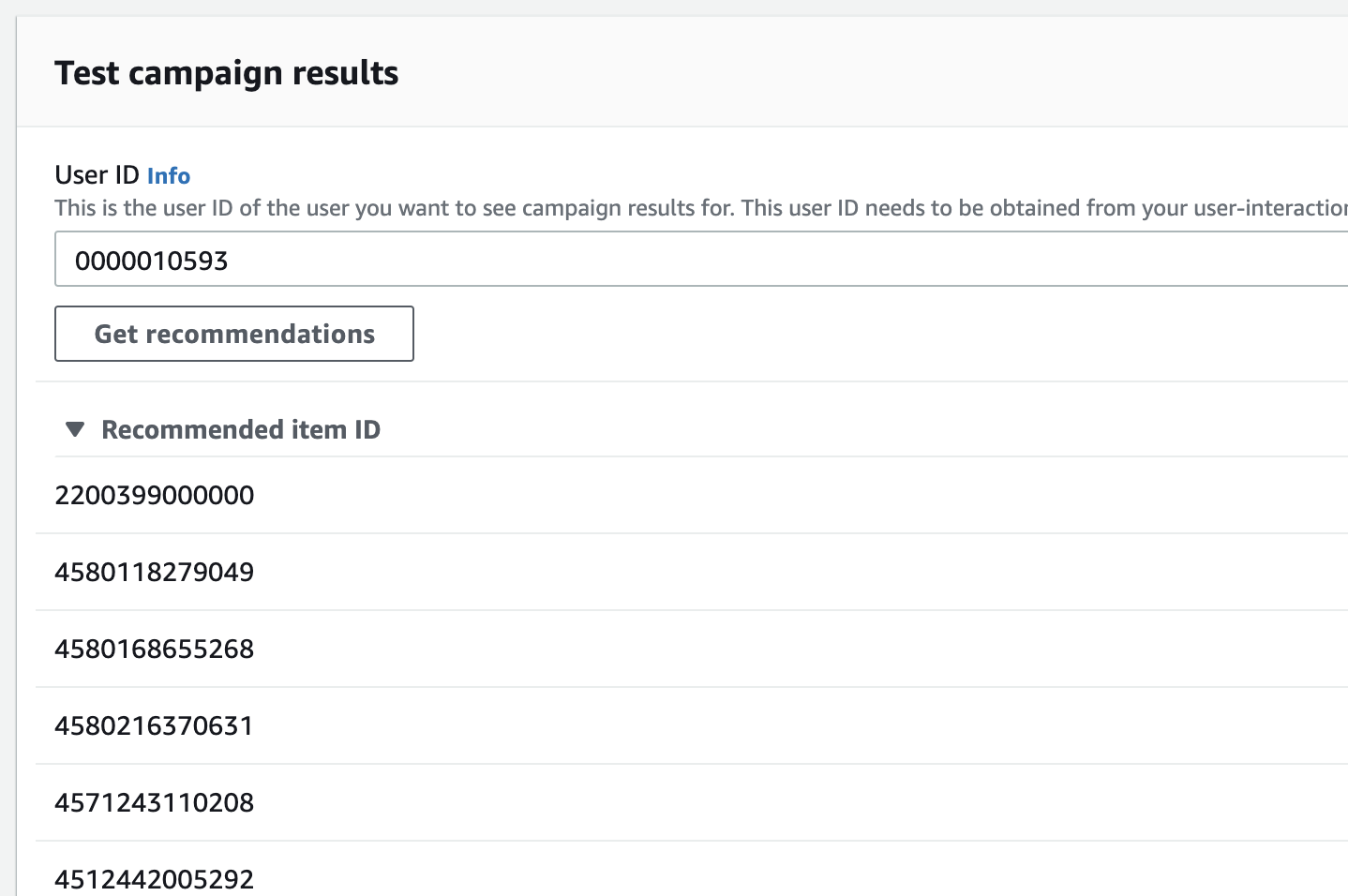
商品IDが複数推薦されます。画面では表示しきれてないですが25件推薦されました。
6. boto3から実行する
とりあえずローカルの環境から取得できるか、試してみました。
import boto3
if __name__ == "__main__":
personalizert = boto3.client('personalize-runtime', region_name='ap-northeast-1')
response = personalizert.get_recommendations(
campaignArn="<Campaign ARN>",
userId='<User ID>',)
for item in response['itemList']:
print (item['itemId'])
注意点
ローカルのaws-cliにpersonalize-runtimeがない場合があるのでサービスを追加する必要があります。
各サービスのjsonをダウンロードしてaws-cliにセットするだけなのですぐできました。
7. APIを作成する
SeverlessFrameWorkを使用してAPIを作成しました。
コードなど
service: personalize-test
provider:
name: aws
runtime: python3.7
stage: stg
region: ap-northeast-1
profile: test
functions:
recommend:
handler: src/handler.get_recommend
events:
- http: GET /{user_id}
import json
import boto3
def get_recommend(event, context):
user_id = event['pathParameters']['user_id']
personalizert = boto3.client('personalize-runtime', region_name='ap-northeast-1')
response=personalizert.get_recommendations(
campaignArn="<Campaign ARN>",
userId=str(user_id),)
item_list = []
for item in response['itemList']:
item_list.append(item['itemId'])
body = {
'item_list': item_list
}
response = {
'statusCode': 200,
'isBase64Encoded': False,
'headers': {'Content-Type': 'application/json'},
'body': json.dumps(body)
}
return response
問題発生
sls deployでデプロイをしたらAPIのエンドポイントが表示されるのでcurlで試してみたところInternal Server Errorが返って来ました。
CloudWatchのログを見た所以下のログが出ました。
[ERROR] UnknownServiceError: Unknown service: 'personalize-runtime'. .....
内容としてはboto3でpersonalize-runtimeというサービスはないとのこと。githubのissueにもあがっていました。
解決策としてはamazon-linux上で最新のboto3をインストールし、zipで固めてLamdbaのLayerとしてboto3を使用するとのことでした。
AmazonPersonalizeはつい最近一般公開されたばかりでLambdaのboto3の対応が間に合っていないんですかね。
以前の記事(pandasをLambdaのLayerとして追加する)で似たようなことを行なったので同様にzipファイルを作成しました。
作成したzipファイルはgithubにあげましたので使用される人がいれば使ってみてください。
いざ再び
$ curl https://XXXXXXX.execute-api.ap-northeast-1.amazonaws.com/stg/242 | jq
{
"item_list": [
"2200399000000",
"4580118279049",
"4580168655268",
"4580216370631",
"4571243110208",
"4512442005292",
"2400040256128",
"4954540129232",
"2430002732278",
"4512442005490",
"4982757911630",
"4997640091030",
"4997640092105",
"4512442005179",
"4976631605029",
"2400040918354",
"2401020995907",
"4536361026251",
"2430002792463",
"4573222000029",
"2430000383120",
"4580127310146",
"4571243110130",
"4539427300012",
"2430000362002"
]
}
返ってきたー!これで既存のアプリケーションへの利用もできそうです。
終わりに
今回でAmazon Personalizeの課金体系を身をもって感じたのでみなさんも気をつけてください。 それでもAmazon Personalizeは簡単にレコメーンデーションを作成するとても素晴らしいAIサービスなのでご利用は計画的に。
今回はEvent trackersは使用しませんでしたが、Event trackersを使用すればリアルタイムにレコメンデーションをすることができるので知見がたまり次第紹介しようと思っています。