1. 概要
こんばんは。
今回はタイトルの通り、キャラクターの台詞をCVAE(Conditional Variational Auto-encoder)で生成してみました。
同手法で、キャラクターの口調変換も試みたりもしています。
※170624: githubのコードに不具合があったので修正しました。
2. 関連記事(既存研究)
台詞をRNN系で生成する記事は多く見られます。
【エヴァンゲリオン】アスカっぽいセリフをDeepLearningで自動生成してみる
こうした記事には以下の課題がありました。
- 当該キャラクターの学習データが少ない(せいぜい1000文。しかも、他のキャラの台詞を学習データに混ぜると上手くいかない)
- 既に当該キャラクターが喋った台詞のみを学習データに用いるため、その台詞に出てこない単語をキャラクターが発する事はない
これらの課題をCVAEで解決しようと思います。CVAEではカテゴリー毎(この場合はキャラクター)の特徴を学習する事ができるので、異なるキャラクターの台詞を学習データに加えても、各キャラクターの台詞生成の精度を向上させる事ができます。
3. モデル
前回書いた記事「VAEでキャラクターの設定を作る。」を踏襲して、同じくLSTMVAEをモデルに用いています。
LSTMとVAE、Encoder-Decoderモデルについてはここでは深く触れませんので、ご存知無い方は以下の記事をご参照ください。
VAEはDeepNeuralNetを生成モデルに転じたモデルですが、どういったデータを生成するかを制御する事ができないという問題がありました。これを解決したのがCVAEです。
CVAEでは、VAEにカテゴリーベクトル(カテゴリーを表現するベクトル、これもパラメータです)を結合したモデルです。
VAEの適用事例として、MNIST(数字の文字認識)の画像生成が論文で紹介されています。

通常のVAEではランダムに数字が生成されてしまいますが、CVAEでは0から9までの数字を指定して生成する事が出来ます。
同様の手法を使う事で、キャラクターを指定して、台詞を生成する事ができないかを検証しました。
CVAEのモデルの構成は、基本的に以前書いた記事のLSTMVAEと同じです。
これのencoderとdecoderの隠れ層の初期値にカテゴリーベクトルを加算するだけです。
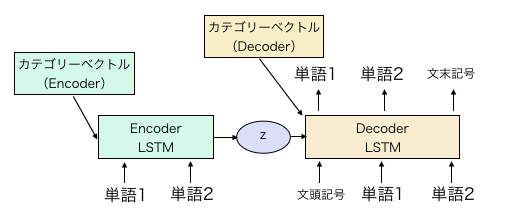
簡単に図示すると、上図のようなモデルです。
上図のカテゴリーベクトルは、キャラクター毎に変更して学習させるパラメータです。
学習時にはEncoderとDecoder両方に入れますが、生成時には、中間表現zの分布とDecoderのカテゴリーベクトルの組み合わせで、臨んだキャラクターの台詞を生成できます。
encoderはBidirectionalLSTMで各隠れ層の次元は300としました。
中間層zの次元は600。
decoderの隠れ層の次元は600にしました。
単語ベクトルはencoderとdecoder共通で300です。
形態素解析はsentencepieceで行い、単語数は約16000です。
後、以下は自信がなかったところですが、カテゴリーベクトルは、LSTMのhとcの隠れ層両方用に作っています。encoderがBidirectionalなので、2×3で計6種類ものカテゴリーベクトルがあります。
次元は隠れ層の次元と同じです(encoderなら300、decoderなら600)
コードは例によって、
https://github.com/ashwatthaman/LSTMVAE
に置いてあります。
src/each_case/sampleCVAESerif.py
にConditionalVAEの実行用コードが書いてあります。
ただ、今回は著作権的な観点からデータが公開できないので、
置いてあるのはダミーデータのみとなります。
4. データ
こちらは以下をはじめとするサイトからクロールしました。
- 愛するべきもの -アニメのセリフ紹介-
-
Anime Transcripts@アニメで英語
合計で218キャラクター、約12万文を学習させています。
上記12万文には、100文以上台詞があるキャラクターの台詞のみを使用しています。
5. 結果
5.1. キャラクター毎の文生成
結果です。
一番上手く言った(気がする)のが綾波レイの台詞だったのでこちらを載せます。
嘘よ。私は私しかいないのよ。
あ、あの、私は初号機を護ればいいのね
私は、私は私を求めていたのみたい。
碇君はとても失敗。
生きていて
分からないわ。私は初号機を出撃させる。
綾波レイと呼ばれている顔をしているのよ。
...いえ。そうして...あなただけのものの
嫌な感じで来るのよ?
いいえ。本当に動けばない。
何を言うのよ。ただ、贔屓もなし。私のしたことが分からないの。
ありがとう、ありがとう。私は、その日の扉の中に
あなたは、綾波レイと呼ばれているものにやり遂げてるの。
黙って、誰かを倒したらダメよ。
はい。この物体が一つに感謝して、そのつもりです。
そうお世話するのも、時の流れ、恐いんでしょう?
こんな状況だからね。みんな心配してたの。
おめでとう!
なぜ、あなたは生きてる?
だから、私は、あなたのお父さんから逃げ出した
いいえ、私は私よ。私は私の命が、生きていたのよ!
イヤ、逃げちゃだめよ!
主観ですけど、ただRNNを使うだけよりもそれらしい文章が生成されているように思えます。
「嘘よ。私は私しかいないのよ。」
「だから、私は、あなたのお父さんから逃げ出した」
らへんとか、綾波に言って欲しいけど、言われてない台詞って感じで良いですね。
次はミサトです。
回収は、もう出撃していいわね?
ご、ごめんなさい
とにかく、ネルフの予備電源にカット!
でも、幸せな居になりたいこと。
本部からの報告から、少し早朝早く終わらせるわよ
シンジ君の命令に従え。
ご、ごめんなさい、お手持ちよ。じゃ、早く行かないと
開けるわよ、日本。
そんな無茶な願います
...アスカ、予備要塞ね
相変わらずジョークの通じない奴。
あなたのお母さんの傷についているのか?
委員会は、予備電源を切断。あと初号機を回
加持君、爆撃るわよ?
バカ...
あんた、心当たりがあるの?
恐い!寂しみ聞きながら、どんな顔したの?
あんたみたいな顔をしてるよ。あんた、父親なんて
使徒?
あの、アスカ、レイ?零号機は?
大っ嫌い!
...エヴァのパイロットは応急信号が...わ
で、で、だめよ、だめよ、こんなの着てないし...
そう。
なんですって!?
させるのダラサスチが当たった事...
ぐっ!
変わる?
第一、第二、第二資格、何の救出。
アスカ
嫌いよ、そんなの決まってるわよ!
分かってるわよ!せっかく作ってきてくれたんだし、ママのお弁当を貸してね
ママ?
加持さんとお風呂に入るとこ持って来てくれたな?
うっさい!
...大丈夫なの、ほんとにもう、大っ嫌い!
嫌い...
ちょっとここで待ってなさいよ!
ママッ、ばっか
オッケイ、シェッジョイエテヨーイ!
バカ!あんたなんかバカにすんのよ!
あれ?
ひっ、行くわよ、行くわよ。
そうやって、たった今で大人だもん。
嫌ぁ!バカぁ!
...あのバカ...
ちょっとここで待っててんのよ。どいてね!加持さん!
ファースト、ファーストフェイズに入るから
嫌い嫌いだって、せっかく作ってきてくれたんだし、もう一つじゃないわ
取り替えた、弐号機をバックアップ、あなた自身が。
人の話は言ってやったのはやめてね
何よこれ?
エヴァンゲリオン弐号機、弐号機に乗るのよ!
変わった子ね。
はぁぁ...
分かってる。
...加持さんがうるさいのよ...
あんたも電話しないでよ!
シンクロ率は、2週間ぐらいの4番目。
何よ、嘘がばれた、それ
イヤ、ファーストよ。
これでとりあえずは持っていって!
あんたこそ、まだ起きないのにずっと乗ってたの
ちょっとここで待ってなさいよ!
あんたバカぁ?ファーストチルドのファーストよ!
何よ、口元はいちいち口から、仲良く!
オッケイ、シェッジョイエテヨーイ!
突然のポプテピピック。
他キャラの台詞は
https://github.com/ashwatthaman/LSTMVAE/tree/master/src/each_case/serif/test28_Public.txt
にあります。
ガンダム、コードギアス、ハルヒ、らきすた、日常、イカ娘などがあります。
キャラによって結構生成精度が異なるように見えます。
5.2. 口調の変換
次に口調の変換を試みます。
何をやるかというと、先程、CVAEではencoderとdecoderの両方にカテゴリーベクトルを加算すると述べました。このカテゴリーベクトルは普通はencoderとdecoderで同じものを入れますが、違うベクトルを入れる事で、encoderのキャラクターの台詞を別のキャラクター風に変換できないか? というのを試してみました。
友利奈緒の台詞
「皆さんも見て下さい」
をイカ娘に変換してみます。
すると……、
「みんな、やるでゲソ!」
という文章が出力されました。
惜しい……。
やるじゃなくて見るだったら完璧だったんですが。
次にアスカの台詞
「ハロ〜ォ、ミサト! 元気してた?」
をシンジ風に変換します。
「ミサトさんの言う通りだ。綾波の連絡してみようよ」
となりました。
うーん、微妙です。
他にもう一つ、
シャアの台詞
「ギュネイが敵の核ミサイル群を阻止してくれた。あれが強化人間の仕事だ」
をクェスに変換します。
「ギュネイが敵の核ミサイルを阻止してくれたって話、許してあげるわ」
こうなりました。
これは、割りと変換できている気がします。
ただ、こういう風に比較的?上手くいった例は10個に1個もないです。
全然意味の違う言葉に変換してしまう例がほとんどでした。
流石にAutoEncoderで口調変換をするにはもうちょっと工夫が要りそうです。
6. 考察とか感想
6.1. 台詞生成
最初に、既存の手法について2つの課題を上げました。
-
学習データが足りなくて上手く学習できない事。
-
1キャラの台詞だけで学習させると、キャラクターがそれまでに発していない単語は発さない事。
の2点です。 -
については定量的な評価はしていませんが、他のキャラクターの台詞を学習データに入れる事で文章の質が向上する事が確認されたと思います。既存の方法に比べて、文法的に破綻した文章の割合が少ないです。しかも、元の台詞にあるものをそのまま発しているわけではありません。
-
について。上の例で言うと、レイが「扉」と言ったり、ミサトが「要塞」と言ったりしています。これらの単語は、元の台詞文には登場していない単語なので、新たな単語を発する事には成功しているといえます。ただ、その割合が予想以上に低くはなっています。
6.2. 口調変換
カテゴリーベクトルをencoderとdecoderで変更する事で、口調や文体を変換できる可能性を示しました。(まだまだ実用レベルではありませんが)
word2vecで単語の加減算、GANでは、画像の加減算(メガネを外したりつけたりする)の結果が知られていますが、文章の加減算によって意味や、文体の変更を行う研究はまだ出ていないように思われます。
文体の変更自体は、勿論encoder-decoderモデルなどを使えばできるでしょうが、対応する文章を大量に収集しないといけない観点からすると、現実的ではありません。
CVAEを使った変換の精度は、学習データを増やせばある程度いけるのかも知れませんが、どこまでいけるのかは今のところ未知数です。もうちょっと研究の余地ありです。
7. 今後の課題
- 本当に、口調や文体変換ができるか検証するならば、もうちょっと各カテゴリーで文が多いデータを用いた方が良さそうです。
- 12万文あっても文法的におかしい文を生成する事があります。これはもっと学習データを増やせば解決できると思います。
- 今回MeCabじゃなくて、Sentencepieceを形態素分割に使用しているので、条件を合わせるならMeCabを使って比較するべきでした。ただ、形態素分割の仕方でここまで変わるとも思えないので、やっぱりCVAEが効いているんだと思います。
- 学習データで喋っていない単語をキャラクターに発させるのは難しい気がしました。うーん、何か事前分布的なものが要るんですかねぇ。
8. 参考サイト(お世話になりました)
記事
- 【エヴァンゲリオン】アスカっぽいセリフをDeepLearningで自動生成してみる
- VAEでキャラクターの設定を作る。
- LSTMネットワークの概要
- Auto-Encoding Variational Bayes [arXiv:1312.6114]
- ChainerとRNNと機械翻訳
論文
学習データ