こんばんわ。みづはしです。
今回は、台詞からキャラクターの表情を推定するモデルを作ってみました。
背景
キャラクターが登場するゲームでは、その台詞に応じて、表情が変わっていく演出がよく見られます。
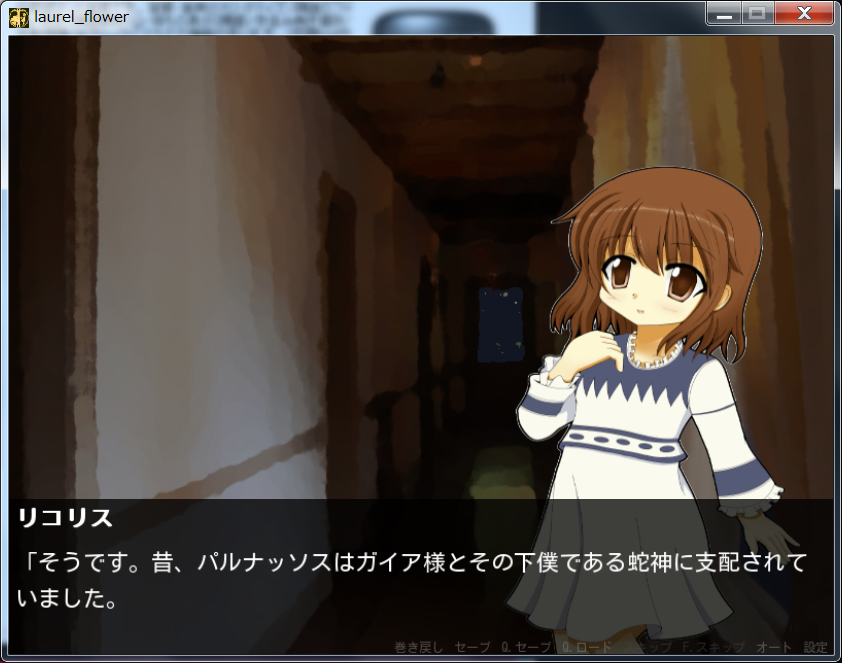
上図は、昔自分が作ったゲームの一画面です。かわいいですね(自画自賛)。画面下部に台詞があり、中央から上部にキャラクターがいる形式のゲームでは、台詞に応じて表情の画像が変更されるようプログラムを構築する必要があります。ノベルゲーム等を作った事がある方はご存知と思いますが、この作業には膨大に時間がかかります。そこで、機械学習を使って、この作業を自動化できないかを試してみました。
関連記事、研究
Twitter等のデータから、感情推定を行う研究は多く存在しています。
台詞の感情を推定するツールに、mylaskがあります。
こちらは試してみたのですが、全体の一割程度しか判定してくれませんでした。どうやら定型句をヒントに判定を行っているらしく、定型句が台詞中に存在しない場合、判定してくれないようです。見たところ、判定できたものについても精度は高くないようです(定量評価はしていません)。台詞の感情推定は複雑なタスクなので、ルールベースでは難しいのだと思います。
データ
事前学習用データ
今回は分類タスクなのでデータを用意する必要があります。しかし、台詞を表情毎にタグ付けしたデータは公開されていません。自分でタグ付けデータを用意するしかないのですが、ニューラルネット系であれば、数万タグが必要だと思います。それを一人でタグ付けするのは面倒なので少し工夫をしました。
Learning to Generate Reviews and Discovering Sentiment
この論文には、「大量にRNN言語モデルで事前学習をしていれば、少数(10程度)のラベルデータで、分類ができるようになる(F値0.8程度)」と書いてあります。
自分もこれを踏襲しました。まず、「小説家になろう」と「青空文庫」のデータから台詞文(カギ括弧で挟まれた文)だけを抽出しました。全部で450M程度になりました。これをsentencepieceで16000語程度を上限として、トークンに分割しました。
本学習用データ
以前書いた記事で使った台詞データをタグ付けに使いました。事前学習には使っていないデータです。事前学習は教師なし学習なので、使ったら絶対駄目っていうわけではないのでしょうが、実応用を考えると、使っていないデータを用いる方が良いと思います。
台詞文2000件に対してタグ付けを行い、9割を学習データ、1割をテストデータに用いました。
タグの種類と数は以下です。
| 表情 | 件数 |
|---|---|
| 普通 | 466 |
| 困る口開け | 183 |
| 微笑 | 165 |
| 眉怒り口閉じ | 165 |
| 疑問 | 125 |
| 笑顔 | 89 |
| 困る口閉じ | 86 |
| 驚き大 | 84 |
| 眉怒り口開け | 74 |
| 喘ぎ | 38 |
| ドヤ顔 | 37 |
| 考え中 | 22 |
計12分類です。
本当は以下の分類もタグ付けしたのですが、テストデータに数が得られなかったので、今回は判定から除きました。下のも足すと29分類です。
| 表情 | 件数 |
|---|---|
| 呆れ | 56 |
| 苦笑い | 39 |
| 驚き_小 | 36 |
| 苦痛 | 32 |
| 恥じらい | 19 |
| 泣き | 14 |
| 慌てる | 12 |
| それ以外 | 8 |
| 目バッテン | 7 |
| 恍惚 | 7 |
| ショック | 6 |
| 恐れ | 4 |
| ジト目 | 4 |
| キス | 3 |
| うっ | 3 |
| 寝ぼけ | 3 |
| 安堵 | 3 |
モデル
事前学習
事前学習用データの項目で述べたデータを、LSTM言語モデルで学習させました。順方向、逆方向でそれぞれ学習させ、隠れ層の次元は1200、単語ベクトルの次元は300としました。epochは5です。
本学習
上記の順逆2つの事前学習済モデルの最後の隠れ層をそれぞれ結合し、計2400次元のベクトルを、線形変換で、表情タグの種類数に落として、Softmaxをかけて、最終的に分類するモデルを学習させています。データについては本学習用データの項目で述べた通りです。epoch数は40です。
結果
結果は以下のようになりました。
| 表情 | F値 |
|---|---|
| 困る口閉じ | 0.4 |
| 笑顔 | 0.5 |
| 微笑 | 0.312 |
| 疑問 | 0.58 |
| ドヤ顔 | 0.333 |
| 眉怒り口閉じ | 0.32 |
| 困る口開け | 0.182 |
| 考え中 | 0.333 |
| 喘ぎ | 0.762 |
| 普通 | 0.566 |
| 眉怒り口開け | 0.455 |
| 驚き大 | 0.5 |
| micro_f | 0.437 |
| macro_f | 0.489 |
F値をご存知無い方のために、分類が一致した割合を併記しておきます。
一致度は43%ほどでした。
表情のタグ付けの43%程度を機械が自動でやってくれるとなれば結構良い精度ではないでしょうか?
また、現実的には、適した表情が複数あるというケースも多いと思うので、それを加味すると実性能はもっと高いと考える事もできると思います。
実用的には精度を100%にするのは無理なので、やりやすいところは自動でやっていって、後は人間が修正していく感じになると思います。
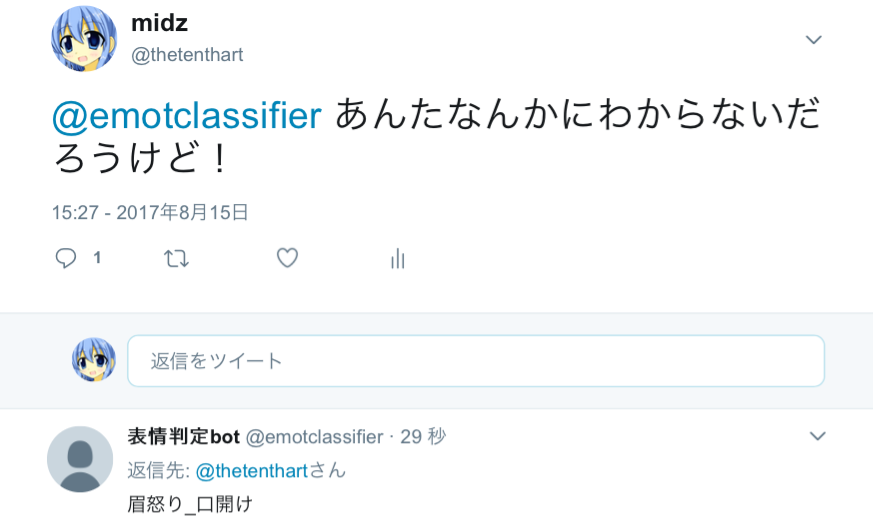
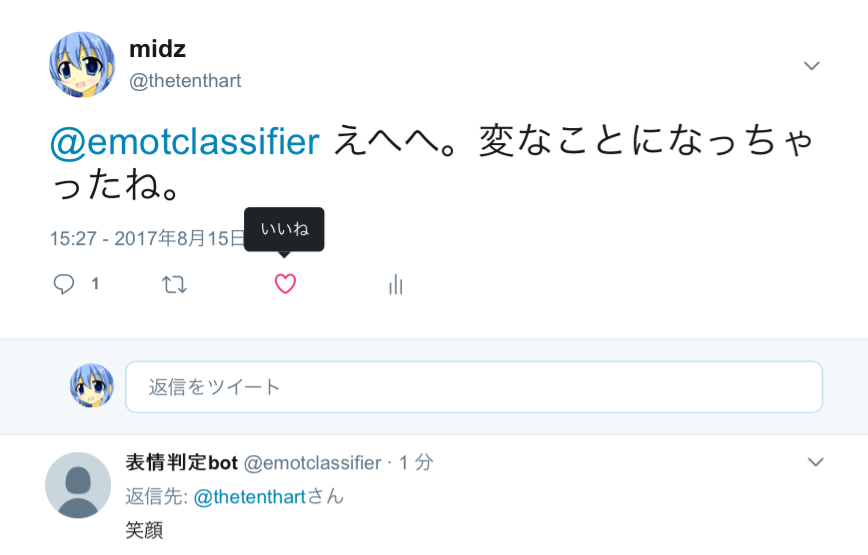
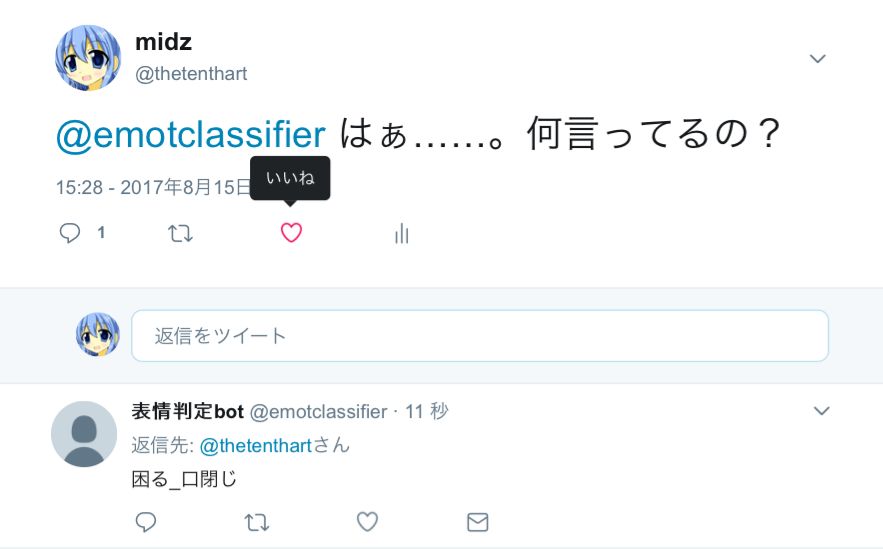
デモ用にツイッターのアカウントを作りました。
https://twitter.com/emotclassifier
リプライで台詞を送信すると、表情を判定してくれます。
試してみてください。
コードとモデルは、
https://github.com/ashwatthaman/FaceExpressionClassifier
にアップロードしてあります。
READ.mdをまだ書いていないので後ほど書く予定です。
ひとまず動かしたい方は、./src/predict.pyの最下部のtext_arrを書き換えると、好きな台詞を判定できます。実行にはsentencepieceが必要です。chainer2以降で動きます。
もし実際に使いたいという方がおられましたら、対応しますので、質問要望など気軽にお声がけください。
課題と考察
今回、学習と評価用のデータは私が作りましたが、この時に以下の2つの問題に直面しました。
1. 文脈を見ないと判断できない場合がある。
今回私は、台詞単文のみから表情を推定してタグ付けを行いました。
「そうですね」
という台詞があった場合、適当に相槌を打っているのか、同意をしているのかで表情は変わってきそうです。より性格な判定を行うには文脈を見て判定する必要があると思います。
2. キャラごとの特性を考えていない。
これは例えば、無表情キャラが「うれしい」と言いつつも顔は笑っていないような状況です。
ただ、これを考慮するのは難しいので、現実的には1.の方を優先的に取り組む事になるでしょう。
データが多ければ多いほど精度が上がるので、もし分類用のデータをくださるという方がいればご連絡ください。