この記事では、Web アプリケーションにおけるデータ取得(データフェッチング)やレンダリングに関する各手法について比較・整理することを目的として、特に最近注目度が高まっている **Next.js における SSG(静的サイト生成)や ISR(インクリメンタル静的再生成)、それ以外の手法(SSR、CSR 等)**を具体的なテーマとしてお話しします。
Twitter もやっているのでよかったらフォローおねがいします! ![]() @_thesugar_
@_thesugar_
記事内の解説は正確性を期すよう注意を払っておりますが、誤っている部分などがございましたらコメント欄や Twitter 等でご指摘ください ![]()
はじめに
Web アプリケーションを作るとき、レスポンスの速さをはじめとしたパフォーマンスの問題は開発者にとって大きな関心事となります。
たとえば、最近では Google が Core Web Vitals という Web のパフォーマンス計測の指標を発表し、既存のロジックに加え、この指標にも基づいて検索結果のランク付けを行うとしています。
CSR (Client Side Rendering) と SSR (Server Side Rendering)
まず、Web アプリケーションのパフォーマンスを考えるにあたっては、クライアント(ブラウザ)サイドでレンダリングを行う「クライアントサイド・レンダリング(CSR)」とサーバー側でレンダリングを行う「サーバーサイドレンダリング(SSR)」の二者の比較はよく目にするものだと思います。
JavaScript の最も素朴な使い方は、HTML ファイルの中で <script> タグの中に JavaScript のコードを記述して、ブラウザ上で JavaScript が動作させることでしょう。それを踏まえると(あるいは踏まえずとも)、JavaScript で Web アプリケーションを作成する場合、クライアント側でレンダリング(画面の描画)を行うのが基本であるというのは納得できる話だと思います。
React や Vue.js などの JavaScript ライブラリやフレームワークも基本的にはクライアントサイドでのレンダリングを行うものです。
ただ、クライアントサイドでのレンダリングを行う場合、クライアントに対して JavaScript を送信することになるため、アプリケーションが大きくなるとクライアントで処理する JavaScript の量が膨大になり、レンダリングにかかる時間、つまりユーザーにページが表示されるまでの時間が長くなってしまうという問題が発生します。特に、ユーザーが使っているデバイスの CPU の処理能力が高くない場合にこの問題は顕著になります。
そこで、ページのロジックとレンダリングを(クライアントではなく)サーバー上で実行し、サーバー上で HTML を生成し、それをクライアントに返却するという方式、すなわちサーバーサイドレンダリングを採用すれば、JavaScript を大量にクライアントに送信するという問題は回避できます。
React でサーバーサイドレンダリングを行えるフレームワークが Next.js で、ほんの少し前までは Next.js といえばもっぱらサーバーサイドレンダリングのためのフレームワークという印象だったと思います。
ただし、サーバーサイドレンダリングであっても、ユーザーからのリクエスト(アクセス)ごとにサーバー側で演算を行う以上、オーバーヘッドが発生することは避けられません。
そこで、今度は静的サイト生成(SSG; Static Site Generation)という方式が脚光を浴びることになりました。
SSG (Static Site Generation) とは
ここまで見てきたとおり、クライアント側で処理を行う CSR も、サーバー側で処理を行う SSR も、ユーザーからのリクエストに応じてその場でレンダリング処理を行うことが速度を下げてしまう主要な原因のひとつだと言えそうです。
となると、あらかじめレンダリングを行なっておいて、ユーザーからのリクエストに対して、すでに構築済みの HTML を返却するだけという形を取れば高速な応答を実現できるはずです。
これが SSG(静的サイト生成)の発想です。SSG では、Web アプリケーションをビルドするタイミングでレンダリング処理を行なってしまい、そのとき(=ビルド時)に各ページの HTML ファイルを生成します。そしてユーザーからのリクエストに対してはその HTML ファイルを返します。
なお、SSG の真の力を引き出すためには、その構築済みの HTML を都度アプリケーション・サーバーから返却するのではなく、CDN に HTML ファイルのキャッシュを配置しておき、各ユーザーに近い CDN からそのキャッシュを返す、という方法を取ることが有効です。
さて、Next.js では Ver. 9.3(2020 年 3 月リリース)から SSG が導入されました。
Next.js は Vercel 社を中心として開発されているオープンソースの React フレームワークですが、その Vercel 社は PaaS も提供しており、Next.js で作成したアプリケーションを Vercel にデプロイすることができます(Next.js 以外で作成したアプリケーションもデプロイできます)。
そして、その Vercel は Vercel Edge Network という CDN をデフォルトで備えており、アプリケーションを Vercel にデプロイすれば、世界各地に存在する Vercel のエッジネットワーク(CDN)に自分のアプリケーションのコンテンツが自動的にキャッシュされ、ユーザーに対して高速にコンテンツを提供することができるようになります。
ところで、SSG は Static Site Generation の略ですが、Static(静的)と聞いて一番理解しやすいのはたとえば個人ブログかもしれません。個人ブログでは投稿者が自分しかいないので決められたコンテンツしかありません。アプリケーションをビルドするタイミングで HTML を生成することはいかにも可能そうです。
ただ、SSG が静的な HTML ファイルを事前に作成するものだというのなら、極端な話、最初から自分で HTML ファイルを書いてそれを配信することと何が違うのかと思うかもしれません。特に個人ブログを例として考えればそう思えるでしょう。
その違いを理解するには、データ取得(データフェッチング)に注目する必要があります。
外部の DB や API、あるいは CMS(コンテンツ管理システム)からデータを取得してきて、その取得してきた情報をもとに UI としてアプリケーション上で表示するケースはよくあります。
そのような場合、(「SSG とやらと“自分で HTML をすべてあらかじめ書いておくこと”の何が違うのか」と言って)自分で HTML を書く方式を採用するのなら、外部データを必要とする部分だけはクライアントサイドで JavaScript を実行して API からデータを取得するような格好になると思います。個人のブログを例にすれば、たとえば各記事に「いいね」をつけることができたとして、そのいいね数を外部の DB 等に格納しておき、記事ごとにいいね数を取得できる API を用意しておくとします。各記事にユーザーがアクセスしたタイミングで、そのユーザーのクライアントからいいね数取得の API を叩き、結果として記事にいいね数の情報が表示される、というイメージです。
確かにこの程度であればクライアントサイドで実行しても問題なさそうです(データの量も少ないですし、記事自体はレンダリング済みであるため、いいね数の表示にたとえ少し時間がかかったとしてもユーザーにストレスは与えないでしょう)。
ですが、データ量が多い場合はどうでしょうか。たとえば、ここで仮に、ブログの記事のタイトルや本文などのすべてを外部 API から取得してくるつくりになっていたとしましょう。
そこで、(やはり「SSG とやらと“自分で HTML をすべてあらかじめ書いておくこと”の何が違うのか」と言って)各ページの基本的な HTML はあらかじめ書いておきつつも、外部データを要する部分はクライアントでデータ取得を行うとした場合、クライアント側でデータ取得を行い、その後で最終的な HTML として完成させることになりますので、結局それは主にクライアントサイドレンダリングによって成り立っているアプリということになるでしょうし、そうなれば、クライアントサイドレンダリングを考えたときに説明したパフォーマンスなどの問題が立ち現れてくることになります。
なお、サーバーサイドレンダリングを使う場合は、リクエストごとにサーバー側でデータ取得から HTML の生成までを行いますが、こちらも先ほど検討したとおり、オーバーヘッドが避けられないのでした。
その観点で改めて SSG を見ると、SSG ではアプリケーションをビルドするタイミングでデータ取得を行うのです。ユーザーからリクエストがあったタイミングでは、データは取得済みであり HTML 文書として出来上がっているのでその時点でデータ取得に時間がかかることはありません。
このようにデータ取得という観点を踏まえると、「SSG は自分で最初から HTML を書くのと同じ」ではないことがわかります。外部からデータを取得する以上、HTML に直書きでその内容を書くことはできないからです。
SSG を実現するコード - getStaticProps
Next.js で SSG を行うには、pages ディレクトリ配下の js(TypeScript の場合は tsx)ファイルの中で、以下のように getStaticProps という関数を定義してそれを export します。
以下のように getStaticProps 関数から、props というキーを持つオブジェクトを export することで、この props がページコンポーネントに渡されます。
export default function Page({ foo }) {
return <div> {foo}!!</div> // ページには Hello!! と表示される
}
export async function getStaticProps(context) {
const foo = 'Hello'
return {
// props キーに対応する { foo } オブジェクトが
// (冗長に書けば { foo : foo } すなわち foo というキー名に対して foo 変数の中身('Hello')を値として持つオブジェクトが)
// ページコンポーネント(Page)に渡される
props: { foo },
}
}
getStaticProps 関数内のコードはビルド時に実行され、そのタイミング(=ビルド時)で props がページコンポーネントに渡されます。
したがって、上記のコードで const foo = 'Hello' としている部分で、(const foo = 'Hello' とするのではなく)データ取得を行うコードを書けば、外部からデータを取得してページコンポーネント(ひいては HTML)を生成するという一連の流れがビルド時に行われます。
SSG を実現するコード - getStaticPaths
上記のコードは、pages ディレクトリ配下の js(TypeScript の場合は tsx)ファイルの中に記述すると説明しました。pages ディレクトリ配下の js (tsx) ファイルは Next.js では直接的にページのルーティングを表します(つまり、pages/hoge.js というファイルがあれば、example.com/hoge という URL にアクセスすればそのページが表示されるということです(上記のコードを pages/hoge.js ファイルに書けば、example.com/hoge にアクセスすれば「Hello!!」が表示されます))。
また、Next.js では pages/[id].js などのように角括弧を使うことで簡単に動的なルーティングを記述できます(ドキュメント)。
この動的ルーティングと組み合わせることで、外部データを要するページが複数存在する Web アプリケーションでもページ生成が簡単になります。
たとえば、投稿の ID をキーにして本文などのデータを外部から取得してくるかたちのブログアプリを考えてみます。ID をもとにしてデータ取得を行う部分のコードはどの記事でも同じはずです。動的ルーティングがあるおかげで、ブログ記事の数のぶんだけ pages/○○(各記事のパス).js というファイルを作ってすべてのファイルの中でデータ取得のコードを書く、というようなことはしなくて済みます。
動的ルーティングと組み合わせるには、ここまで扱ってきたのと同様のページファイル(pages ディレクトリ配下のファイル)から getStaticPaths という関数を export します。
getStaticPaths 関数は、ビルド時に静的にレンダリングするパスの一覧を決めておく関数です。
getStaticPaths 関数からは、paths というキーおよび fallback というキーを持ったオブジェクトを return します。
以下のコードは、個人のブログを想定した例です。
export async function getStaticPaths() {
return {
paths: [
{ params: { id: 'my-first-post' } },
{ params: { id: 'my-second-post' } },
{ params: { id: 'my-third-post' } },
],
fallback: false
}
}
paths キーには、『「params というキーに対して { id : (ページの ID) } というオブジェクトを値として持つオブジェクト」からなる配列』を値として対応させます。上記のコードを pages/posts/[id].js というファイルに書いたとすると、posts/my-first-post、posts/my-second-post、posts/my-third-post というページがビルド時に静的に生成されます。
ここで指定した各 id は getStaticProps 関数から参照できます。getStaticProps 関数について説明した部分で、(そのときは言及しませんでしたが、)getStaticProps(context) というふうに、引数の部分に context と書いていました。この context 変数に params が渡されており、context.params から { id : ... } を参照できます(もちろん、getStaticProps(context) の部分は getStaticProps({ params }) と書いても問題ありません) 。このように、getStaticPaths 関数内で指定したパスが getStaticProps 関数に渡され、そのパス(今回の例の場合は id)をもとに getStaticProps 関数内でデータを取得するコードを書くことで動的ルーティングと SSG を組み合わせることができます。
イメージしやすいよう、個人ブログの例で getStaticProps、getStaticPaths の 2 つを含むコードの例を書いてみます。
// pages/posts/[id].js
export default function Page({ postId, post }) {
return (
<>
<h1>ブログ</h1>
<h2>ID: {postId} の記事</h2>
<h3>{post}</h3>
</>
)
}
// 実際は、ブログの本文データは外部 API から取得してくるようなつくりになるはずだが、
// ここでは挙動の解説のために、記事 ID をもとにブログ本文を取得する、API を模したような関数を定義している
function fetchContent(articleId) {
switch (articleId) {
case 'my-first-post':
return '初投稿です!これからよろしくお願いします。'
case 'my-second-post':
return 'SSG を勉強中!'
case 'my-third-post':
return 'Next.js は楽しい!'
}
}
export async function getStaticProps(context) {
const postId = context.params.id // context.params で、paths で指定した params を参照できる
const post = fetchContent(postId) // 実際はここで await fetch(`https://.../posts/${postId}`) などとして外部 API からデータを取得するイメージ
return {
props: { postId, post },
}
}
export async function getStaticPaths() {
return {
paths: [
{ params: { id: 'my-first-post' } },
{ params: { id: 'my-second-post' } },
{ params: { id: 'my-third-post' } },
],
fallback: false
}
}
実際には、ブログの ID からその ID に対応する記事のデータ(本文など)を取得する場合、API を叩いてデータ取得を行うと思いますが、ここでは簡単のため、API を模したような関数として fetchContent という関数を定義しています(そのため、当然ですが「getStaticPaths 関数を使うときには fetchContent のような関数を定義する必要がある」なんてことは決してありません)。
さて、上記のコード例のようにすると、https://example.com/posts/記事 ID にアクセスすると、それに対応する本文が表示されます。
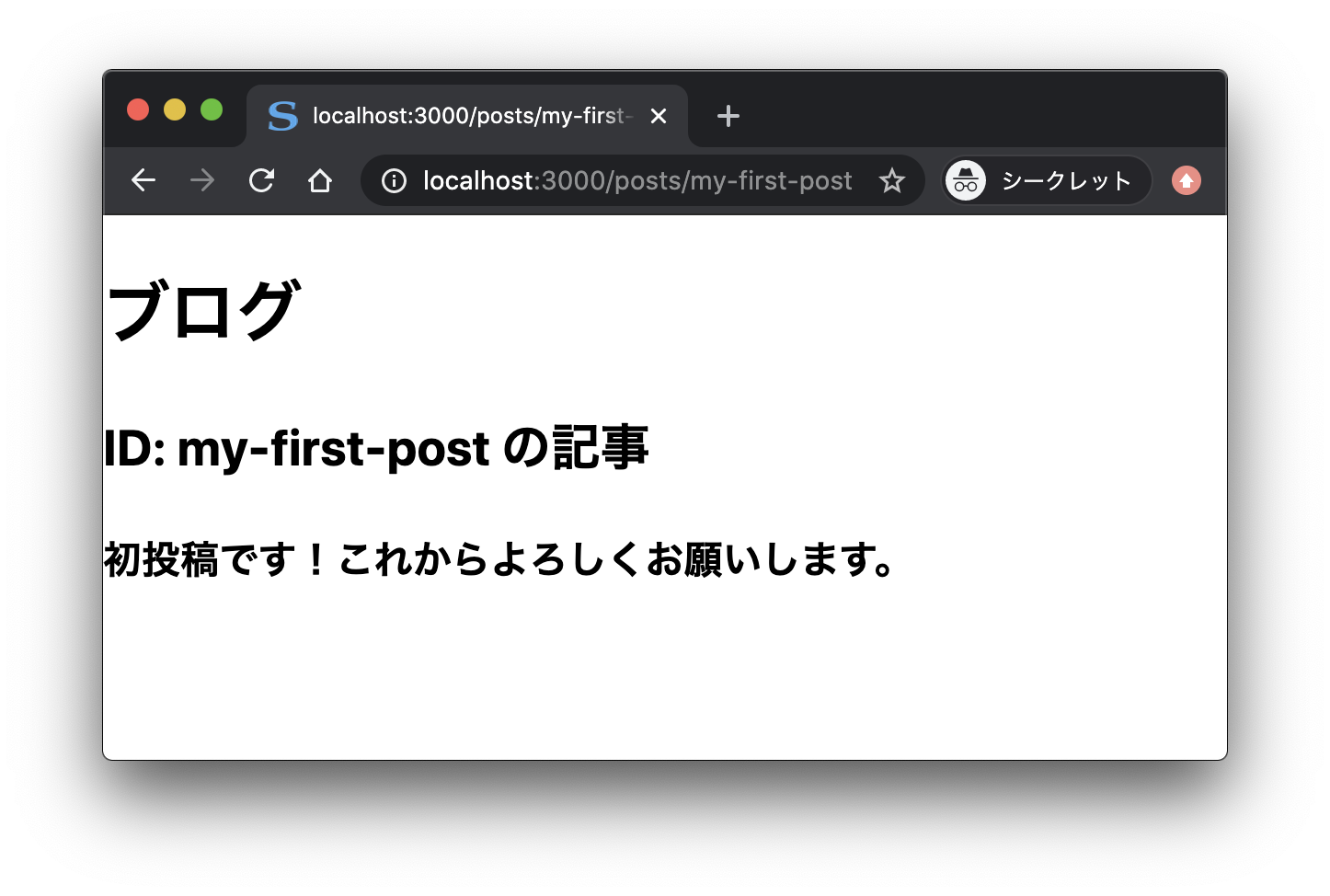
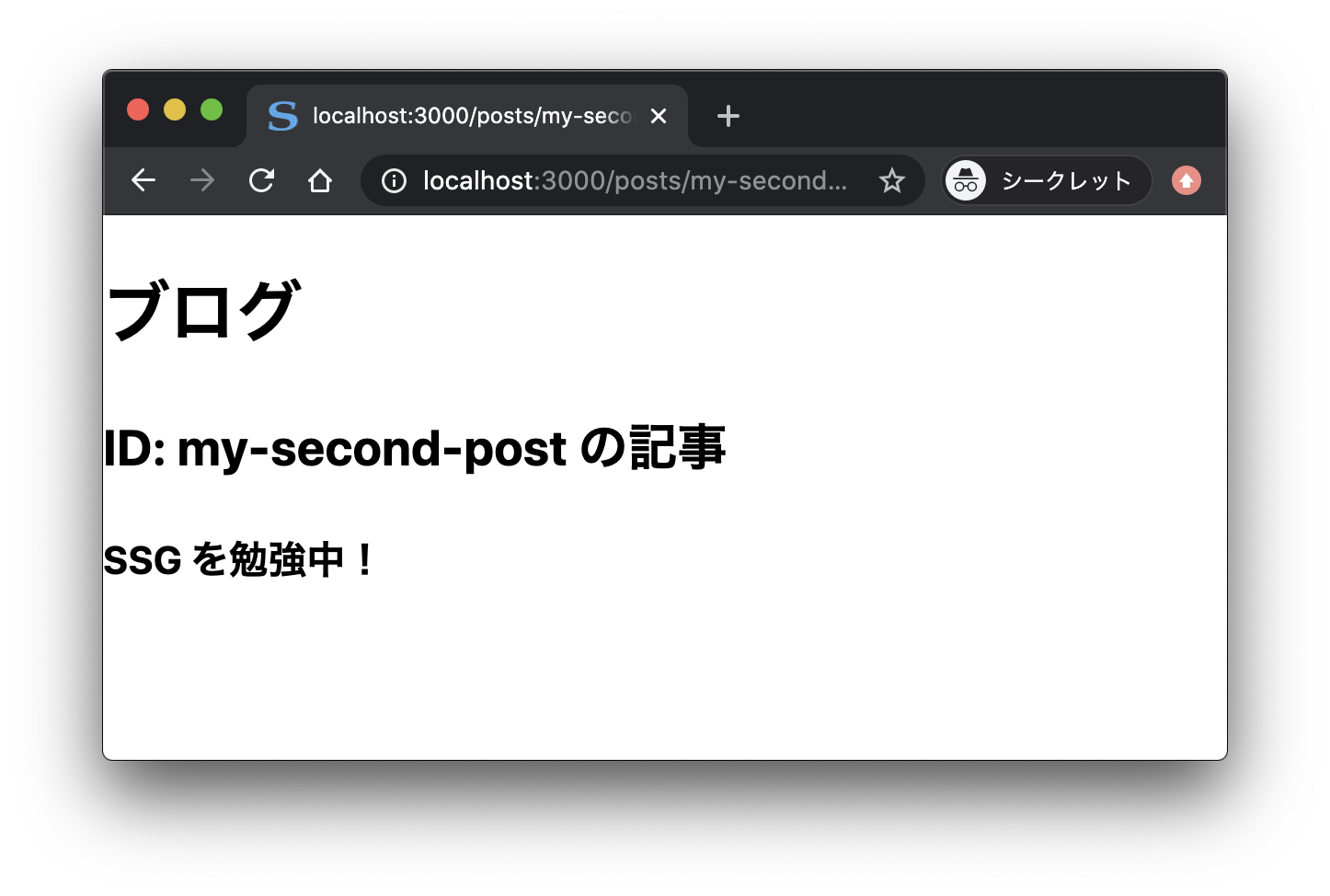
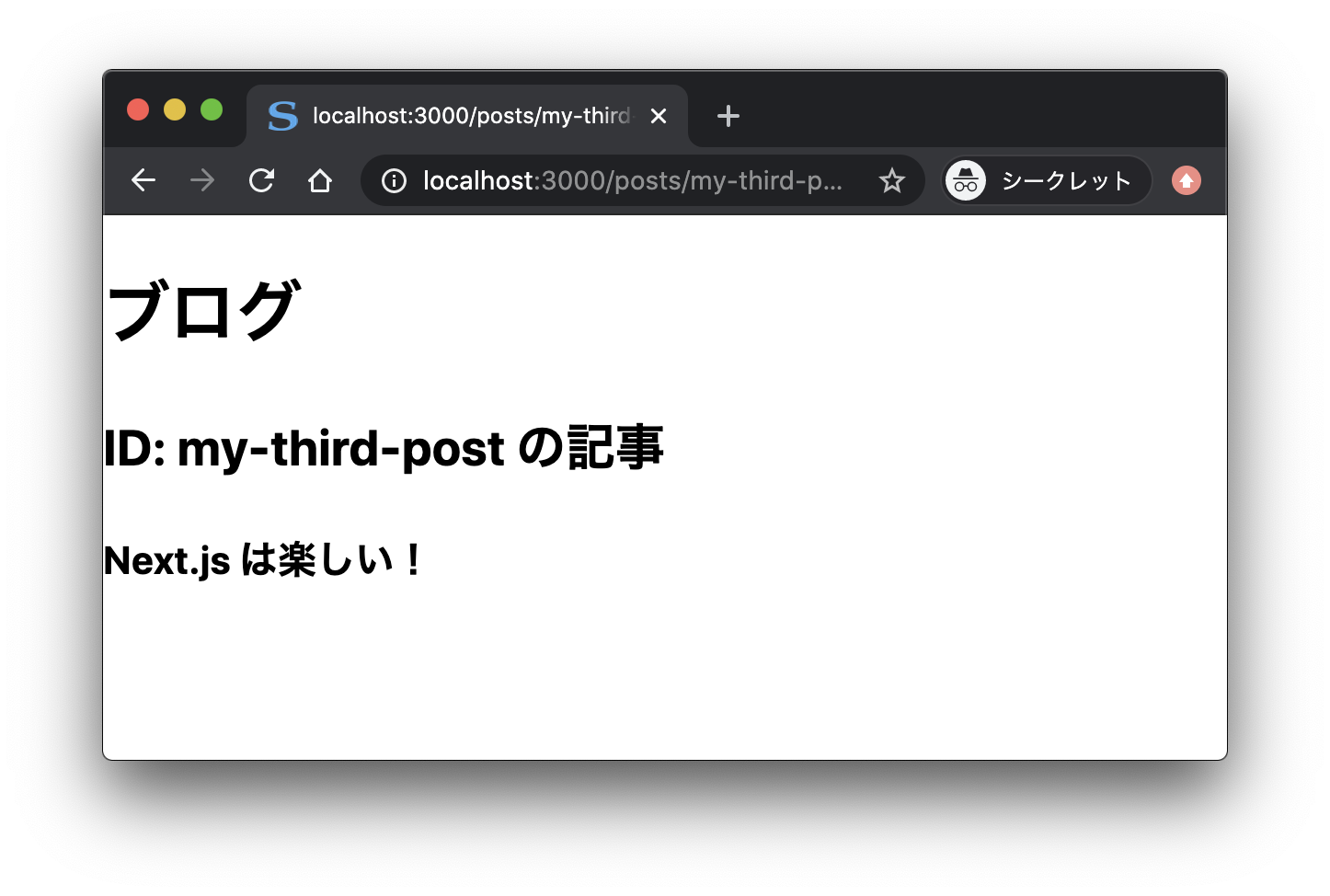
なお、paths で指定していない ID からなる URL にアクセスすると(たとえば .../posts/my-fourth-post など)、404 エラーが返ってきます。ここの挙動には、getStaticPaths 関数から return したオブジェクトの fallback キーが関係しています。すなわち、fallback キーを false にすると、指定したパス以外に対してリクエスト(アクセス)があったときは 404 エラーを返します(fallback キーを true にするとどうなるのかということは後述します)。
ここまで説明したことを図にして表すと以下のようになります。

ところで、SSG のこの「ビルド時に外部からデータを取得して、ユーザーのリクエストに対しては生成した HTML を配信する」という挙動には問題もあるのではないかと思うかもしれません。
たとえば、個人のブログ程度ならともかく、他のユーザーもブログ記事を投稿できるようなブログプラットフォームのようなものを作りたいとき、あるいは、Amazon のように文字通り無数に商品(つまり商品ページ)が存在する EC サイトを作る場合、それらのページ(ブログプラットフォームに投稿されたあらゆる記事や、EC サイトで扱うすべての商品)のパスをあらかじめすべて指定して、そのすべてのページについてビルド時にデータ取得から HTML の生成まで行なっていたのでは時間がいくらあっても足りなそうです。また、ブログプラットフォームの投稿も EC サイトの商品も、ビルドしたタイミング以降も追加されていくはずです。追加されるたびにビルドし直す方法もありますが、自分以外のユーザーが好きなタイミングで記事や商品を追加していくようなケースだと、それらのページをアプリケーションのビルド時にレンダリングするのは不可能という話になってしまいます。
また、自分が書いたブログ記事の本文を外部に格納しておいてそのデータを引っ張ってくるという程度であればやはり問題なさそうですが、その記事についたいいね数や、ユーザーからのコメント(いいね数やコメントは外部の DB に保存してあり、API 経由で取得するとします)を表示したくなった場合はどうでしょうか。
これらは、時間の経過に応じて内容が変化することが予想される(いいね数は増加していくでしょうし、コメントも追加されていくはずです)ため、ビルド時に取得したデータをずっと表示し続けるわけにはいきません(わかりやすい例では、新しいブログ記事を投稿するタイミングではその記事へのいいねもコメントもゼロであるので、そのときに取得したデータを表示し続けるのであれば、少なくとも次にビルドするタイミングまでは誰がいいねをつけてもコメントを投稿しても、0 いいね 0 コメントという表示になってしまいます)。
もちろん、先ほど述べたように、いいね数や読者からのコメントはコンテンツの核ではありませんし、処理の負担を考えても、ビルド時にデータ取得するのではなくクライアント側でのデータ取得を行っても問題ないとは思います。しかし、ここで問題にしているのは、もっと一般的な話として、ビルドとビルドの間に内容が変化しうるデータを取得したい場合は SSG は使えないのかどうかです。
実は、こういった問題にも SSG の範疇内でしっかりと対応策が用意されています。
フォールバック
まず最初に、(たとえばブログプラットフォームや EC サイトのように)アプリケーション全体が大きくて、ビルド時にすべてのページについてデータ取得を行なって HTML を生成するということが現実的ではない場合の対処法を見ていきます。
ここで、先ほど getStaticPaths 関数の説明で少しだけ触れた fallback キーを使います。
fallback: true
getStaticPaths 関数から return するオブジェクトの fallback キーに対応する値を true に設定します(先ほどは false に設定していました)。
// pages/posts/[id].js
export default function Page({ postId, post }) {
return (
<>
<h1>ブログ</h1>
<h2>ID: {postId} の記事</h2>
<h3>{post}</h3>
</>
)
}
// 実際は、ブログの本文データは外部 API から取得してくるようなつくりになるはずだが、
// ここでは挙動の解説のために、記事 ID をもとにブログ本文を取得する、API を模したような関数を定義している
function fetchContent(articleId) {
switch (articleId) {
case 'my-first-post':
return '初投稿です!これからよろしくお願いします。'
case 'my-second-post':
return 'SSG を勉強中!'
case 'my-third-post':
return 'Next.js は楽しい!'
+ case 'my-fourth-post':
+ return '勉強することが多くて大変だ〜'
+
+ case 'my-fifth-post':
+ return 'これからも頑張ります!'
+
+ default:
+ return 'no content'
}
}
export async function getStaticProps(context) {
const postId = context.params.id // context.params で、paths で指定した params を参照できる
const post = fetchContent(postId) // 実際はここで外部 API からデータを取得するようなつくりになる
return {
props: { postId, post },
}
}
export async function getStaticPaths() {
return {
paths: [
{ params: { id: 'my-first-post' } },
{ params: { id: 'my-second-post' } },
{ params: { id: 'my-third-post' } },
],
- fallback: false
+ fallback: true // ここを true に設定した
}
}
API を模したような関数である fetchContent は、my-fourth-post や my-fifth-post などを引数に取っても、本文データを返すように変更しました。外部 DB に記事が追加されて、API が返しうる記事データも増えたというイメージです。
一方、getStaticPaths 関数の paths には my-fourh-post や my-fifth-post は追加されていません。ブログの記事を外部のデータソース(CMS など)に追加したからといって、記事を追加するたびにアプリのコード(paths)を書き換えるわけでもないでしょうから、現実的にもありえないパターンではないでしょう。
上記の差分のとおりにコードを変更すると、/posts/my-first-post、/posts/my-second-post、/posts/my-third-post 以外のパスにアクセスしたときは、404 エラーを返すのではなく、いったん、データ取得を要する部分以外がレンダリングされた静的なページにフォールバック (fallback) されるようになります。
ここでいったん、フォールバック (fallback) という言葉について確認しておきます。
Google で「フォールバック」と検索すると、IT用語辞典 e-Words が出てきますが、そこでは「フォールバックとは、通常使用する方式や系統が正常に機能しなくなったときに、機能や性能を制限したり別の方式や系統に切り替えるなどして、限定的ながら使用可能な状態を維持すること。また、そのような切り替え手順・動作のこと。」と説明されています。
この説明に当てはめれば、「通常使用する方式や系統(=事前に paths で指定されたパス)が正常に機能しなくなった(=その指定されたパス以外に対してリクエストがあった)ときに、機能や性能を制限したり別の方式や系統に切り替える(=上記の「データ取得を要する部分以外がレンダリングされた静的なページ」とやらを表示することで対応)などして、限定的ながら使用可能な状態を維持すること」と解釈することで雰囲気は掴めます。
ちなみに、その他、特に Web や React の文脈では、React の error boundary という概念において fallback という言葉が登場します。React における error boundary とは、「自身の子コンポーネントツリーで発生した JavaScript エラーをキャッチし、エラーを記録し、クラッシュしたコンポーネントツリーの代わりにフォールバック用の UI を表示」するもので、ここでも、fallback という言葉は代替的な表示・対応策、という意味合いで使われています。
これらを頭に入れると、fallback という単語の意味がなんとなく汲み取れると思います。
話を戻すと、paths で指定されたパス以外へのリクエストがあった場合、fallback キーが false であればフォールバックは行わず、単に 404 エラーで返しますが、fallback が true であれば、(エラーで返すのではなく)先ほども述べた「データ取得を要する部分以外がレンダリングされた静的なページ(=まだ必要な外部データは取得されていない)」にフォールバックするのです。
このフォールバックの挙動について詳しく説明します。あらかじめ paths で指定していたパス('my-first-post' など)に関してはビルド時にデータ取得とレンダリングが行われるのでした。ビルド時にデータ取得とレンダリングを行うパスは paths で指定したものだけなので、それ以外のパスについては、当然ながらビルド時にデータ取得もレンダリングも行われません。そのかわり、ユーザーからのリクエストがあった場合の動作が異なります。ユーザーから初めてそのパス(=paths で指定されていないパス)にリクエストがあった場合、まず、クライアント(ブラウザ)に対して、取得を要するデータが欠けた状態の HTML がサーブされます(※)。この不完全な状態の HTML をいったんクライアントに対して送信することをフォールバックといいます。そして、その不完全な HTML を受け取ったクライアント側でデータ取得が行われます。つまり、ブラウザで JavaScript が実行され、必要なデータが取得され、HTML が構築されます。同時に、バックグラウンド(サーバー)側でも同様に JavaScript が実行され、必要なデータの取得とレンダリング(HTML の生成)が行われます。そして、そのパスは、それ以降のユーザーからのリクエストに対しては、サーバー側で生成した HTML(のキャッシュ)を返すようになり、事前に paths で指定していたパスにリクエストがあったときと同じふるまいを取ることになるのです。
(※)いまは pages/[id].js などのような動的ルーティングを考えているのでした。あらかじめ paths で指定していたパス以外はビルド時にデータ取得もレンダリングも行われないと書きましたが、それは、外部データを要する部分のレンダリングが行われないという意味で、それ以外の(id というパラメータに依存しない)基本的なページの構造などはレンダリングされており(これはプリレンダリングと呼ばれます)、それがフォールバックページになります。
たとえば、今まで扱ってきたブログの例で考えてみると、/posts/my-fourth-post というパスは paths で指定されていません。ですから、ユーザーから /posts/my-fourth-post というパスにリクエストがあったとき、fallback キーが false であれば 404 エラーとなってしまいます。ここで fallback が true であれば、初めてそのパスに対してユーザーからのリクエスト(アクセス)があったとき、クライアント(ブラウザ)に対してはまず、本文など必要な情報が欠けた状態の HTML が送られます。my-fourth-post に対応するブログ記事を読みたいのに、「本文:(空白)」となってしまっているようなイメージです。ただし、すぐさまブラウザで JavaScript が実行され、my-fourth-post というパスに対応する本文などのデータが取得され、HTML が構築されます。同時に、サーバー側でも my-fourth-post というパスに対応するデータの取得とレンダリングがなされます。そして、それ以降ユーザーから my-fourth-post というパスにリクエストがあった場合は、いまサーバー側で生成した HTML(のキャッシュ)が返されるのです。つまり、2 回目以降の挙動は、事前に paths で指定されていた my-first-post などにリクエストがあったときと同じようになります。
以上は、個人のブログが例なのでいまひとつありがたみがわからなかったかもしれませんが、先述のとおりたとえば多くのユーザーが気ままに記事を投稿するブログプラットフォームや、無数の商品ページを用意する必要がある EC サイトなどだと、あらかじめ paths ですべてのパスを指定しておくことなど到底不可能ですし、ビルドしたタイミング以降に新たに記事や商品が追加されることも当然あるということを考えると、この機能はもはや無くてはならないほど有用なものと言えるでしょう。
fallback: 'blocking'
ここまでは fallback: true としたときの挙動を追いました。
便利な機能ではありますが、やや不便な点もあります。事前に paths で指定されていないパスに対してリクエストがあった場合、初回のリクエストでは、取得を要するデータが埋め込まれていない状態の、不完全な HTML がクライアントに対してサーブされてしまうということです。たしかに、すぐにクライアント側の JavaScript でデータ取得が行われますし、2 回目以降はデータ取得が行われた状態の HTML(のキャッシュ)がサーブされるので、何か致命的な問題になるというわけではありませんが、それでもやはりちょっと気になるポイントであることは間違いないでしょう。
この問題に対処するためには、fallback キーを 'blocking' という値(文字列)にします。
export async function getStaticPaths() {
return {
paths: [
{ params: { id: 'my-first-post' } },
{ params: { id: 'my-second-post' } },
{ params: { id: 'my-third-post' } },
],
fallback: 'blocking'
}
}
fallback: 'blocking' モードは、本記事執筆時点で最新の Next.js 10(10/27 リリース)にて追加された機能です。
fallback キーの値を 'blocking' にすると、読んで字のごとく、フォールバック動作をブロックします。ここで、先ほどまでの内容を振り返ると、フォールバックとは、paths で指定されていないパスに対してはじめてリクエストがあったときに、必要なデータの取得に先んじて、データ取得が行われていない状態の不完全な状態の HTML をクライアントに返すことを指すのでした。fallback を 'blocking' とすると、この動作をブロックするので、不完全な状態の HTML をクライアントに返すことをしなくなります。ではどうなるかというと、あるパス(事前に paths で指定されていないパス)に対してユーザーから初めてリクエストがあったタイミングで、サーバーサイドでデータ取得およびレンダリングが行われ、レンダリングまで完了した段階でクライアントに対して HTML がサーブされます。つまり、初回はサーバーサイドレンダリングが行われます(fallback: true の場合は、初回は不完全な HTML がサーブされ、クライアント側でデータ取得とレンダリングが行われる(クライアントサイドレンダリング)のでした)。つまり、ユーザーに不完全な状態の HTML が表示されることはなく、初回のアクセスでもレンダリングが完了した状態のページが表示されるようになります。そして、サーバーサイドでレンダリングされた HTML(のキャッシュ)が 2 回目以降のリクエストに対しては使いまわされます。ここの挙動は fallback: true の場合と同様です。
いま説明した部分の挙動は、上記のコード例を使っても確認できます。fallback を true にしたときと 'blocking' にしたときで /posts/my-fourth-post や /posts/my-fifth-post にアクセスすると、その違いが確認できるはずです。また、開発者ツールから JavaScript を無効にしてみると、fallback: true のときはデータ取得がいつまでも行わず、データ取得を要する部分が空白のままなので、クライアントサイドレンダリングが行われていることがわかります(ブラウザ(クライアント)でレンダリングを行うはずだからこそ、ブラウザの JavaScript を無効化したことでデータ取得が行われなくなったということです)。一方、fallback: 'blocking' の場合は、JavaScript を無効化してもデータが表示されることがわかります。これはサーバーサイドでレンダリングされた HTML を受け取った(=クライアントで JavaScript を実行するのではない)からです。
ちなみに、いま説明した部分は以下の Twitter のスレッドでも説明していますので、もしかしたらご参考になるかもしれません(以下のツイートのスレッドを最初から見るにはこちら)。
ほとんどご認識のとおりだと思います!
— thesugar / Ryohei Sato (@_thesugar_) October 29, 2020
fallback: trueと’blocking’の一番の違いは、私のQiita記事のデモのアニメのとおり、事前に指定していないパスに対してリクエストがあった場合に「まずはデータ取得が必要な部分以外を返してからデータ取得が行われる(true)」か、(続)
なお、開発時(localhost で動かしているとき)は Next.js の仕様として(というよりは、アプリケーションをビルドしているわけではないので)「2 回目以降のリクエストに対して静的な HTML(のキャッシュ)がサーブされる」という動作を確認することはできませんのでご注意ください。
時間の経過に応じて変化するデータへの対応
さて、fallback: true もしくは fallback: 'blocking' とすることで、アプリのビルド時にすべてのページについてデータ取得およびレンダリングを行わなくてもよいということがわかりました。
続いて、時間の経過に応じて変化するデータへの対応を考えてみます。今まで見てきたかぎりだと、SSG ではビルド時(あるいは、fallback: true もしくは fallback: 'blocking' を用いた場合は初回リクエスト時)にページをレンダリングしたあと、その HTML(のキャッシュ)を使いまわすので、一度データを取得してしまったあと、データ元でデータの内容が変更された場合、再度アプリをビルドし直さなければ、その変更を反映できなそうに思われます(ブログ記事のいいね数やコメントに限らず、ブログの本文内容が変更されることだってあるでしょうし、基本的に外部から取得してくるデータはつねに変更される可能性があるでしょう)。
言い換えれば、SSG は「静的サイト生成」というからには動的 (dynamic) なデータを扱うことはできないのではないか? という懸念です。
この問題にも対応策が用意されています。
インクリメンタル静的再生成 (Incremental Static Regeneration; ISR)
「インクリメンタル静的再生成 (Incremental Static Regeneration; ISR)」という手法によって上述の問題に対処できます。
インクリメンタル静的再生成は、今まで説明した SSG の挙動に加えて、一定時間ごとにバックグラウンドでデータの再取得およびページの再レンダリングを行い、HTML を再生成 (regenerate) する手法です。この機能は Next.js 9.5 から導入(β 導入は 9.4 から)されました。
まずはコードを見てみます。getStaticProps 関数に変更を加えます。
export async function getStaticProps(context) {
const postId = context.params.id
const post = fetchContent(postId)
return {
props: { postId, post },
revalidate: 60, // ここを追加
}
}
getStaticProps 関数から return するオブジェクトの中で、revalidate というキーに対して秒数を指定します。ここでは 60 ですから 60 秒という時間を指定しています。
先ほど、インクリメンタル静的再生成を「一定時間ごとにバックグラウンドでデータの再取得およびページの再レンダリングを行」う手法だと書きましたが、revalidate プロパティで指定される秒数がまさにその「一定時間」に相当するものです。
この revalidate をたとえば 60 秒に指定したとすると、getStaticProps を使って SSG が行われる各ページについて、少なくとも 60 秒間はこれまでの説明と同様に静的な HTML(のキャッシュ)をサーブします。しかし、60 秒経過した後に初めてユーザーからリクエストがあったタイミングで、そのリクエストに対してはすでに構築済みの HTML(のキャッシュ)を返しつつ、バックグラウンドでデータの再取得および再レンダリングを行いページを再生成し、次のリクエストに対しては再生成したページのキャッシュを返します。この動作を繰り返していくことになります。
いま説明した部分をイメージ図として表すと以下のようになります。図中の経過秒数等はあくまでも 1 つの例として考えてください。
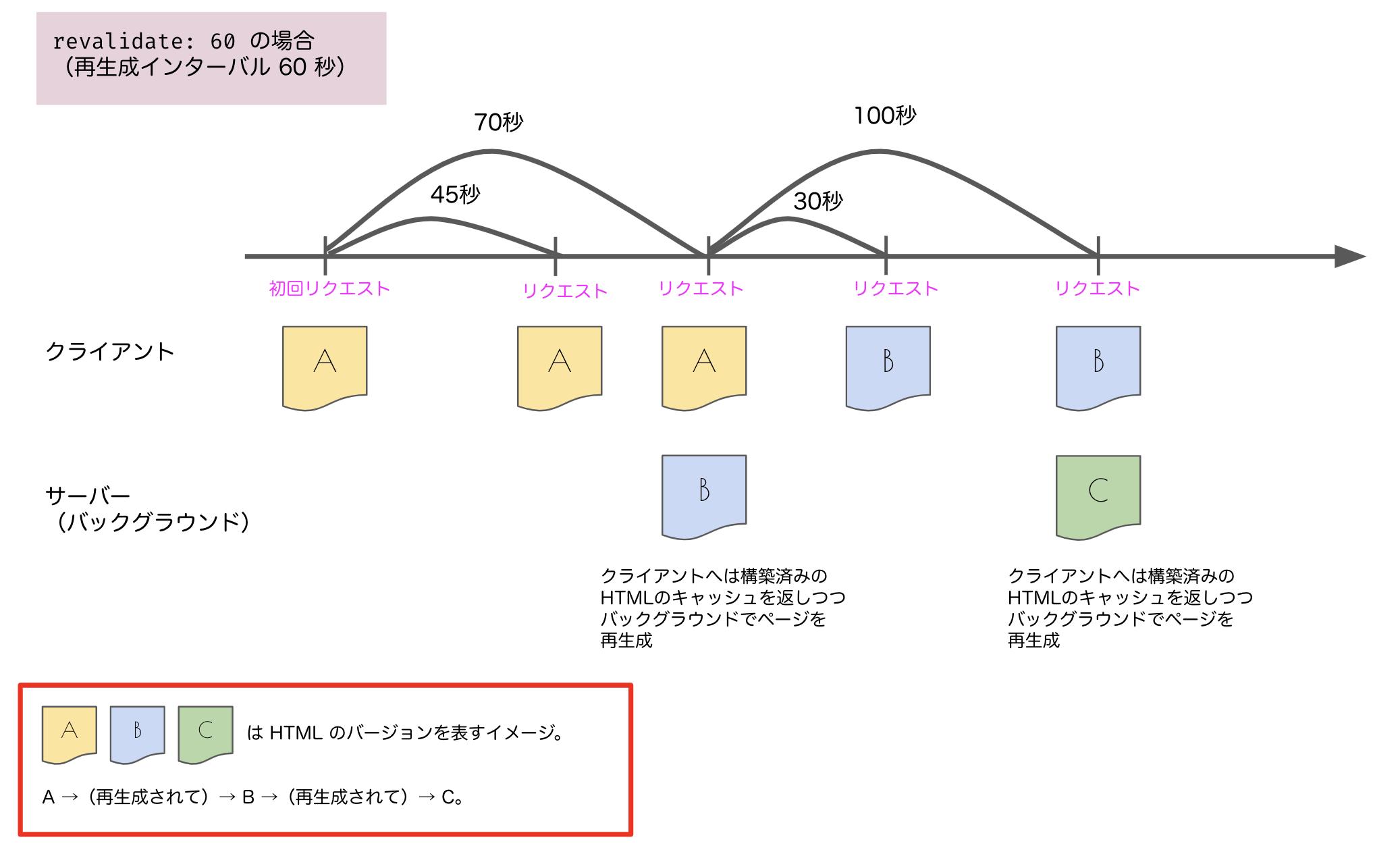
これにより、時間の経過に応じて内容が変化するデータであっても、アプリ全体を再ビルドすることなくその変化を反映させることができます。
今は秒数を 60 秒として説明しましたが、データの性質に応じてこの秒数を長くしたり、あるいは短くしたりすることができます。
なお、先ほども説明したとおりではありますが、revalidate で指定した時間の経過後にリクエストが行われ、ページを再生成している間は、再生成する前の(つまり、生成済みの)HTML のキャッシュを返すので、ページを再生成するタイミングで応答が遅くなるというようなことはありません。また、再生成に際してデータの再取得に失敗するなどしてページの再生成ができなかった場合は、それまでサーブしていたキャッシュがその後もサーブされます。
これらの挙動は、stale-while-revalidate という、Web ブラウザにおけるキャッシュ戦略にインスパイアされた機能です(日本語では こちらのブログ記事 がわかりやすいと思います)。
Note
Vercel 所属の開発者の @chibicode さんの以下のツイートによると、「インクリメンタル静的再生成」と言った場合はrevalidateを使ってページを再度生成する機能を指し、「再」をつけず「インクリメンタル静的生成」と言った場合には、fallbackによりリクエストに応じてページを逐次的に生成する機能も含意するようです。
また、Incremental Static Regeneration の日本語訳についても以下のツイートを参考に、本記事では「インクリメンタル静的再生成」と訳しています。詳しくはこちらをご覧ください!https://t.co/P0vYEAzKYR
— Shu Uesugi (@chibicode) May 11, 2020
日本語訳ですが、
Incremental Static Generation→インクリメンタル静的生成
Incremental Static Regeneration→インクリメンタル静的再生成
にしようかなと考えてます。
インクリメンタル→「段階的」「逐次」だと漢字が多すぎるかなと… pic.twitter.com/bRkgXh3qk5
CSR(クライアントサイドレンダリング)再考
SSG のメリットや、SSG に伴う問題への対処方法をひととおり見てきたこのタイミングで、改めてクライアントサイドレンダリングについて考えてみます。
冒頭で、クライアントサイドレンダリングはクライアント側で JavaScript を実行するため、アプリのサイズが大きくなるとパフォーマンスが劣化するというような話をしました。
しかしながら、部分的にクライアントサイドレンダリングを取り入れることで直ちにパフォーマンスが悪化するわけではありませんし、むしろメリットのほうが大きい場合もあります。
SSG との比較は後ほど検討するとして、ここでクライアントサイドレンダリングにおいて便利なライブラリを紹介します。
SWR
SWR とは、Vercel が中心となって開発されている、クライアントサイドにおけるデータフェッチング(データ取得)のための React フックライブラリです。SWR というライブラリ名は、先ほども登場した stale-while-revalidate の頭文字をとったものになっており、命名から察されるとおり、取得したデータをクライアント側でキャッシュすることができます。
以下は、公式ドキュメントからそのまま流用したものですが、SWR の簡単な使用例です。
import useSWR from 'swr'
const fetcher = (...args) => fetch(...args).then(res => res.json())
function Profile () {
const { data, error } = useSWR('/api/user/123', fetcher)
if (error) return <div>failed to load</div>
if (!data) return <div>loading...</div>
// render data
return <div>hello {data.name}!</div>
}
上記のコードで核となるのは useSWR という React フックです。
useSWR は第一引数に key という文字列を、第二引数に fetcher という Promise を取ります(ほかにもオプションで様々な引数を取ることができますが、詳細はuseSWR に関する公式ドキュメントをご覧ください。
第一引数の key は、データフェッチングを行う際のキーになります。第二引数の fetcher は、データフェッチングを行う関数を返す Promise です。コード例では、fetch 関数のラッパーになっています。第一引数の key が第二引数に渡されます。コード例では、/api/user/123 という文字列が fetcher ひいては fetch 関数に渡され、外部の API からデータを取得できます。
SWR は、ページに再フォーカスしたタイミングや、タブ切替えで再びページを表示したタイミングで自動的にデータを再取得してくれる機能や、一定時間(インターバル)ごとにデータを再取得してくれる機能をはじめ、きめ細かい有用な機能がたくさん備わっています。詳細は SWR のドキュメントをご確認ください。
SSG とその他手法の比較
クライアントサイドでのデータ取得とそのライブラリ SWR について確認したところで、SSG に話を戻します。SSG は、静的な HTML のキャッシュを返すためパフォーマンスに優れ、また、fallback: true あるいは fallback: 'blocking' とすることでページ数の膨大なアプリであっても対応でき、さらに revalidate プロパティを使って実現するインクリメンタル静的再生成により、動的なふるまいを取らせることもできる(時間経過に応じて内容が変化するデータにも対応できる)のでした。
こうなるとすべてインクリメンタル静的再生成でよいのではないかという気がしてきますが、必ずしもそうとは言い切れないようです。
インクリメンタル静的再生成では、revalidate で指定した時間が経過した後の初めてのリクエストがトリガーとなって再生成が行われるので、そのリクエスト自体に対しては古い状態のページが返されます。それを許容するかどうかはアプリケーションの要件次第でしょうが、一般的な使い分けは以下のツイートのように考えることができます。
遅れました、仰る通りです!
— Shu Uesugi (@chibicode) August 28, 2020
UXにおいて、
1️⃣結果整合性(Eventual Consistency)のみが求められる場合
→(incremental)静的生成で対応可能
2️⃣強整合性(Strong Consistency)が求められる場合
1. getServerSidePropsを使うor
2. swr等でクライエント側で確実に更新する
ユーザーによる編集は2️⃣ですね。
このツイートのやりとりでは「Twitter のプロフィールページ」のような、ユーザーによって頻繁に編集が行われるページが想定されています。編集が完了したにもかかわらず、(編集後初めてのリクエストに対してであっても)編集前のデータが表示されてしまうことは厳に回避したい、という要求があるのであればインクリメンタル静的再生成は適していない、と結論づけられています。
上記のツイートの内容そのままではありますが、改めてまとめると以下のようになります。
- 結果整合性(最新ではないデータが表示されることを許容する)でじゅうぶんである場合はインクリメンタル静的再生成で対応すればよい
- 強整合性(つねに最新のデータが表示されてほしい)を求める場合は、都度のサーバーサイドレンダリングあるいは SWR 等を用いたクライアントサイドでのデータ取得を行う
SSG vs それ以外の手法という観点では他にも議論があります。詳しくは 参考に挙げたページやツイートをご覧ください。
また、SSG あるいはインクリメンタル静的再生成を行わない場合にサーバーサイドレンダリングを行うかクライアントサイドレンダリングを行うかは、これもまたアプリケーションの要件等を踏まえてその時々の判断になるかと思います。
ただし、たとえばユーザーのダッシュボードページのような、SEO が関係なく、データが頻繁に更新され、また、事前に静的にページをレンダリング(プリレンダリング)しておく必要もないページであればクライアントサイドでデータを取得してしまうのがよさそうです。これは Next.js の公式ドキュメントでもそのように書かれています。
以上で見たように、アプリの要件や求める挙動の違いによって都度各手法を比較検討する必要がありますが、そうは言っても SSG あるいはインクリメンタル静的再生成は Web 開発にあたってかなり有力な手法・選択肢であると言えるでしょう。
参考
最後に、参考となるページや記事、ツイートを紹介します。
-
Next.js - Data Fetching
- Next.js 公式のデータフェッチングに関するドキュメントです。コード例も記載されています。私も参加している Next.js 日本語翻訳プロジェクトによる翻訳版ドキュメントはこちら。
-
Rendering on the Web - Web上のレンダリング
- Google による説明記事です。サーバーサイドレンダリング、静的レンダリング (SSG)、クライアントサイドレンダリングに関して、基本的な定義から説明されています。
-
Static Tweet Next.js Demo
- Vercel による SSG のデモです。
https://static-tweet.now.sh/1321470235703083009などと、ツイートの ID を指定してアクセスすることで任意のツイートがページコンテンツとして表示されます。当然、あらかじめ各ツイート ID に対応する URL がpathsで指定されているわけもなく、fallbackを利用して未知のパスに対するページがリクエストに応じて生成されます。初回のリクエストと 2 回目以降のリクエストの挙動の違いなどが確認できると思います。
- Vercel による SSG のデモです。
-
Static Reactions Demo
- こちらも Vercel によるインクリメンタル静的再生成のデモです。デモページの説明文のとおりですが、この GitHub の issueへの反応(絵文字の数)を取得しています。インクリメンタル静的再生成を使えば、動的に変化するデータにも対応できることがわかると思います。
-
SWR
- SWR の公式ドキュメントです。使い方やオプション、使用例など丁寧に記述されています。
-
Incremental Static Regeneration で実現する次世代のサーバーアーキテクチャ
- インクリメンタル静的再生成の使用方法、メリットについてデモを交えながら説明されています。
-
【React】useSWRはAPIからデータ取得をする快適なReact Hooksだと伝えたい
- SWR に関する記事です。SWR に関して日本語の説明記事は少ないなか、使用方法やメリット等、わかりやすく解説されています。
-
SSRはおまいらには早すぎた 〜Next.jsのgetServerSidePropsの登場が何を意味するか〜
- サーバーサイドレンダリングとクライアントサイドレンダリングの比較記事です。特に、サーバーサイドレンダリングが使いづらいシチュエーションについて詳しく説明されています。
-
Next.js 4年目の知見:SSRはもう古い、VercelにAPIサーバを置くな
- SSG と SSR を比較して、SSG(インクリメンタル静的再生成を含む)のメリットや、それに限らず Next.js を使用するにあたっての知見が詳しく解説されています。
-
- 一方、こちらのツイートでは SSR にも依然として需要が大いにあるということが具体的な例を交えて説明されています。今日Twitterで何度も流れてきてる話題の件、何回も話すの嫌なので、会社のSlackに書いた SSR/SSG/SPA に並びに静的サイトについての見解のスクショを貼っておきます。 pic.twitter.com/6D1hPP7yYa
— potato4d / Takuma HANATANI (@potato4d) November 6, 2020