Aplogogies
本稿は2017/4/14開催の「インフラ野郎Night おかわり」向けに準備していたものなのだが、某国に拉致されたため、無念のキャンセルになってしまったorz 書きかけの部分も多いのだが、フィードバック・突っ込み等いただければ...ということで公開する。
イントロ
本記事は、少し前に書いたこれ(「Azureのインフラを支える技術(概要編)」)の続きである。当該記事で整理した以下の項目のうちの、2.の深堀り調査として2016年10月に台北で開催されたIEEE MICRO49 での発表 "A Cloud-Scale Acceleration Architecture" 1 を紹介する。
- データセンタ
- ハードウェア・アクセラレータ
- コンピュート
- ストレージ
- ネットワーク
- 分散処理基盤
なお、現在のアーキテクチャは第二世代である。第一世代の論文は末尾のリンク集に追加しておいたのであわせて参考にしてほしい。
もう一点、最初にこれがどんな論文か、おことわりのような話を書いておくと、人によっては、FPGAで具体的にどんな回路を組んだのか?というような話を期待すると思う。しかし、この論文ではDCあるいはクラウド基盤の高速化のために、どういう取り組みを行ったのか?が主題なので、FPGAそのものの話は回路ブロックレベルまでであることに留意してほしい。
論文の構成
論文自体は以下のような構成になっている。
- Introduction
- Hardware Architecture
- Local Acceleration
- Network Acceleration
- Remote Acceleration
- Lightweight Transport Layer
- Elastic Router
- LTL Communication Evaluation
- Remote Acceleration Evaluation
- Oversubscription Evaluation
- Hardware-as-a-Service
- Related Work
- Conclusion
1章が全体のアーキテクチャの説明、2章がFPGAボードの構造の説明。実際FPGAを使って何をしているのか?については、3章から5章までで順次説明される。なお、アーキテクチャ/構造の説明については、1.節と2.節以外に5.節にもちらばっているので、以下、論文の構成とは話の流れを変え、先に大小の構造の話を、次にどう使っているのかの話をまとめる。
なお、利用用途ごとにそれぞれ評価結果も載っているのだが、結果は相対評価で normalize されてしまっており、絶対値がわからないのがちょっと残念だった。
アーキテクチャ
そもそもの目的(FPGAの用途)
まず、ここで言うFPGAは、AWSのFPGAインスタンスのようにクラウド利用者に開放されるようなものではなく、あくまでクラウドのインフラ処理やBingのインデックス作成、機械学習処理のような、Azureのサービス自体の高速化のためにあることに注意のこと。
アーキテクチャの特徴
まず、Microsoft Research のページから、論文の Fig.1 を引用する。特に左側を見てほしい。
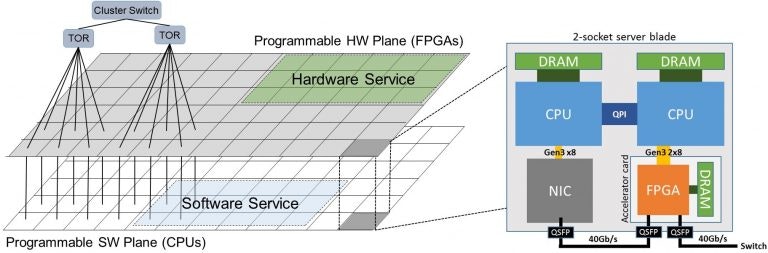
下の白いメッシュが一般的なソフト処理を行うCPUのプレーン(Programmable SW Plane(CPUs))で、上のグレーのメッシュがFPGAのプレーン(Programmable HW Plane(FPGAs))である。そして、右側の図の "2-socket server blade" の箱が一台のサーバ(blade)の構造を示していて、この箱の中の右下のFPGAカード(Acceralator Card)が、FPGAのプレーンのセルの1つ1つに対応する。FPGAカードを除く部分がCPUのプレーンのセルに対応する。見くらべると、ToR SWとFPGAカード間、およびサーバとFPGAカード間がそれぞれ40GbEのリンクで接続されていて、左右の図で対応しているのがわかると思う。
さて、どうしてこんなアーキテクチャになっているのか?
これには前の世代のハードウェア・アクセラレータからの教訓があるようだ。前世代では、FPGAどうしがサーバとは独立した6x8 torusトポロジのネットワークで接続されていた。しかし、これには以下のような課題があった。
- 独立したNWにコストがかかる
- torus は故障ハンドリングが複雑
- torus はdirect neibour以外レイテンシが高くなる
- スケールが難しい
これらの課題に対する回答として、FPGAをCPU(NIC)とNWの間に配置し、NWを共有するというアイデアで解決したのである。実際、
- スイッチのポート数はサーバの分だけで済む
- Leaf-Spine構造にすれば普通のNWノウハウで対応できる
- 同一のToR経由で(2-hop で)direct に到達できる台数も自然に増える
- サーバ(CPUs)とアクセラレータ(FPGAs)を(blade単位で)物理的にセットでデプロイすればスケールも容易
なお、CPUの台数とFPGAの台数の比率は固定になるので、さまざまなワークロードに対してこの配置で最適かどうかは自明ではない。これを解決するため、CPUのPlaneとFPGAのPlaneを論理的に分離して管理し、必要に応じて自由に再構成して割り当てて使えるようになっている。
そういうわけで、Configurable Cloud Architectureという名前がついているようだ。
やや脱線するが、これを見て、ある意味計算クラスタとストレージクラスタが重なっている、MapReduce の発想に近いものを感じるかもしれない。しかし、MapReduce の場合は、データは計算資源のそばにおいておこう…という発想だったのに対して、これはアクセラレータのデプロイの都合から来ているので、似て異なるものであると言える。
Hardware-as-a-Service
Hardware-as-a-Serviceとは、前述のFPGAのPlaneのリソースをpool管理して「自由に再構成して割り当ててて使うことを実現する部分である。論文では、この説明は 5. Remote Acceleration で出てくるのだが、全体アーキテクチャに深く関連するのでここで説明する。
より抽象度の高いレイヤから、SM、RM、FMというコンポーネントが存在する。
- SM : (higher-level) Service Manager
- 論文では詳細は触れられていないが、FPGAやCPUを何にどう使うのか?をつかさどっていると思われる。
- RM : Resource Manager
- Yarn に類似の処理を行う、centralized なリソースマネージャ
- 上記のSMに対して、簡易なAPIを提供する
- FM : FPGA Manager
- 各サーバに配置され、FPGAのconfiguration管理や状態監視を行う
5.節では Decoupled Programmable Hardware Plane という表現も出てくる。前述の通り、CPU(というかサーバ)とFPGA(カード)は1:1対応でDC内にデプロイはされるが、分離されているので、利用するときにも1:1だとは限らないということである。
FPGAボードの構造
FPGAボードの構造は、2. Hardware Architecture にも解説があるが、詳細は特に 5. Remote Acceleration も熟読する必要がある。
以下、キーワードベースでポイントをピックアップする。
Bump-in-wire Architecture
構造上、一番重要なのが Bump-in-Wire Architectureである。
- Altera Stratix V D5 (ALM量が 172.6Kというのはカタログより少ないようだが...)
- FPGAは、NICの外側、つまりToR SW側に配置される。
- 場合によっては 40GbEのトラフィックをNW-ホスト間でスルーする
- 言い換えれば、ホストの通信とFPGA独自の通信が同じ40GbEのメディアを共有する。
- この論文の時点では 40GbE だが、50GbEのSmartNIC Gen2 というものが既に存在する。
* しかし、40GbEのPHYってFPGAで普通に処理できちゃうのね...
Shell Architecture
Shell とは、FPGAに組み込まれたロジックのうち、(Acceleratorの)アプリケーションロジック(role)とは別の、(コンポーネント化された)共通機能群のことを指す。shell IP という書き方もあるので、ものによっては外部から買ってきていることだおうか。このshell に分類されるコンポーネントとしては以下のようなものがある。
- 40G MAC PHY (TOR)
- 40G MAC PHY (NIC)
- Network Bridge/Bypass
- DDR3 Memory Controller
- Elastic Router
- LTL Protocol Engine
- LTL Packet Switch
- PCIe DMA Engine
- そのほか
以上全部をあわせて、FPGA全体のALMリソースの44%を消費している。一方、アプリケーションロジック部分が32%なので、余りは24%ということだ。
LTL - Lightweight Transport Layer
shellのひとつ。
FPGA間の通信に使われる、コネクション指向の軽量通信プロトコルの実装部。前述のブロックでは、Engine と Switch をまとめたもの。LTL プロトコルはUDP/IP上に定義され、フロー制御は credit ベースのようだが、loss less の(class を使える)スイッチを前提にしているようだ。(が、いまいち判然としない)
FPGA-ToR-FPGAの RTTが 1us 程度。
なお、繰り返すが、LTLはFPGA-FPGAの間で使われるものであって、ホストにLTLスタックが実装されているわけではない。
Elastic Router
shellのひとつ。
これはFPGA内のshell/role間通信に使われるものであって、FPGA間ではないのに注意してほしい。
PCIe DMA Engine
shellのひとつ。
ホスト側のメモリにアクセスするのに使用される。
Memory Controller
shellのひとつ。
FPGAカード上に載っている4GBのメモリアクセスするのに使用される。
ただ、論文の Fig.4 ではカード上の PCIe DMA Engine に接続されているのだが、本当にこれでよいのだろうか?
Role
Acceleratorのロジック。これは上述の shell ではない。
たとえば、Bing の処理のオフロードとか。(TBD)
議論
-
Role 部分を書き換えることによって、後述の3つの用途で使いわけている。
- bump-in-the-wire アーキテクチャをとっているために、ロジックの更新をミスった場合にどうするか?問題になる。
実際のところは...(TBD)
- bump-in-the-wire アーキテクチャをとっているために、ロジックの更新をミスった場合にどうするか?問題になる。
-
Over-subscription テスト
3つの用途と効果
Local Acceleration
GPGPU的な、オフロード処理のこと。
この用途では、サーバとFPGAカードの間には 1:1 対応関係が成り立つ。
Network Acceleration
サーバが発生する
この用途でも、サーバとFPGAカードの間には 1:1 対応関係が成り立つ。
Remote Acceleration
まとめ
- たのしそう...(とおいめ
以上。(えっ...
リンク集
- 論文 : A Cloud-Scale Acceleration Architecture
- 論文 : A Reconfigurable Fabric for Accelerating Large-Scale Datacenter Services - (前世代のハードウェア・アクセラレータ)
- SmartNIC: FPGA Innovation in OCS Servers for Microsoft Azure (LL20D - Server) - OCP U.S. Summit 2016, March 9-10, San Jose, CA
余談
その1
そういえば、年末の Azure Night のときに、FPGAの書き換えはどのくらいの頻度で行っているのか?と聞いてみたところ、「そんなに頻度が高いわけではない」とのことだった。それなら適当に枯れたところでASIC化してもいいのでは?と思うのだが、どのくらい効果があるのだろうか...
その2
InfiniBand由来でSDPプロトコルというものがあって、socket APIによる通信をRDMAで高速化できることをご存知の人もいるかもしれない。
実は、SDPプロトコルは、元々Windows Socket Directの内部プロトコルをベースに、InfiniBand TAの Software Working Groupで策定されたものである。
当時のMicrosoftの担当者は今どこにいるのだろう?と思って調べてみたら、AWS勤務とのこと。AWSの内部はベールに包まれているが、推して知るべしといったところである。
-
Adrian Caulfield, Eric Chung, Andrew Putnam, Hari Angepat, Jeremy Fowers, Michael Haselman, Stephen Heil, Matt Humphrey, Puneet Kaur, Joo-Young Kim, Daniel Lo, Todd Massengill, Kalin Ovtcharov, Michael Papamichael, Lisa Woods, Sitaram Lanka, Derek Chiou, Doug Burger, "A Cloud-Scale Acceleration Architecture", in Proceedings of the 49th Annual IEEE/ACM International Symposium on Microarchitecture(MICRO49), IEEE, 2016. ↩