背景
アプリケーションに機能を追加して動かしてみたけど、SQLが遅くてこれじゃだめだ・・・といってる人を最近よく見かける気がします。で、詳しそうな人に相談したら「インデックス使えてないんじゃないの!?」と突っ込まれ、言われるがままにインデックスを作ったり、SQLの条件を見直したり、で、なんとなく速くなってよかったみたいな。
なんとなく解決して終わりじゃなくて、どんな仕組みで速くなってるのか、簡単なイメージだけでも理解しておくと次の開発で役に立つし、そこから詳しく調べていっていろんな技術に繋がるからいいよねっていう話です。
説明したい事
なんでインデックス作るとSELECTが速くなるのか、出来るだけ簡単なイメージで説明します。
- 普通にCREATE INDEXするとツリーインデックスが出来るので、これを利用した検索の概要を説明します。
- Oracle以外のRDBでも基本は同じだと思います。
- 正確さより分かり易さ重点で、基本の部分を説明します。本当はRDB毎にいろんな工夫があるので、詳しくは各RDBのマニュアルを読むと良いです。
- ハッシュインデックスやOracleの逆キーインデックスなど、他のインデックスもありますが、ここでは説明しません。
- アルゴリズムやデータ構造の詳しい話も始めると長くなるので、また今度にします。
前提
商品テーブルから、商品コードを条件に、商品名をSELECTするSQLを例にしたいと思います。
よくありそうなテーブルとSQL。
-- 商品コードを条件に商品を検索する例
select 商品名 from 商品 where 商品コード='15'
このテーブル、最初の頃は数十万品目を取り扱っていましたが、最近は増えてきたみたいです。
その数は42億を超えます![]()
-- 商品コードと商品名を全部取り出す
select rownum,商品コード,商品名 from 商品
| rownum | 商品コード | 商品名 |
|---|---|---|
| 1 | 85639552 | 運動場 |
| 2 | 291678494 | 冷凍保存 |
| 3 | 6314957 | 消灯ラッパ |
| 4 | 190509022 | 焼け野原 |
| 5 | 104882262 | 窓枠 |
| 6 | 243016188 | ダンプカー |
| 〜 | 〜 | 〜 |
| 4294967296 | 98164086 | 地下鉄 |
商品は頻繁にメンテナンスされていて、商品コードはばらばらに並んでいます。
商品コードは乱数メーカーをお借りしました。
商品名にはランダム単語ガチャをお借りしました。
インデックスを使わないでSELECTする大変さ
下のような課題とその回答があったとして、商品テーブルにインデックスがないとどれくらい時間がかかるか、考えてみます。
課題
お客さんから、商品コード「167975642」の注文がありました。
どんな商品なのか分かりません。SQLで商品名を調べてください。
-- 回答
select 商品名 from 商品 where 商品コード='167975642'
DBから1つの商品を取り出して、商品コードが「167975642」なのかどうかを調べるのに、0.000001秒かかると仮定してみます。
データはバラバラに並んでいるので、商品コード「167975642」がどこにあるか分かりません。1行目から順番に一つ一つ探していくしかないです。商品数は前提で書いた通り、42億を超えます。
| 行番号 | 商品コード | 商品名 |
|---|---|---|
| 1 | 85639552 | 運動場 |
| 2 | 291678494 | 冷凍保存 |
| 3 | 6314957 | 消灯ラッパ |
| 4 | 190509022 | 焼け野原 |
| 5 | 104882262 | 窓枠 |
| 6 | 243016188 | ダンプカー |
| 〜 | 〜 | 〜 |
| 338346887 | 167975642 | こたつ |
| 〜 | 〜 | 〜 |
| 4294967296 | 98164086 | 地下鉄 |
行番号「1」の商品から順に商品コード「167975642」かどうかを調べていくと、338346887番目でヒットしました。おめでとうございます。
探すのにかかった時間は
0.000001 * 338346887 = 338.346887 (秒)
338.346887 / 60 = 5.63911478333 (分)
だいたい5分半くらいでした!
今回は運良く、全商品の1割程度を探すだけで見つかりましたが、運が悪いと1時間くらいかかりそうです。
商品が数十万件のときは1秒以内で探せていましたが、取り扱う商品が増えるにつれて、探すのに時間がかかるようになってきました。商品を1つ探す度に何十分も待たされていては仕事が進まないです。
どうすればいい?
商品コードがバラバラに並んでいて、目的の商品コードがどのへんにあるか分からないのがいけないです。仮に商品コードが順番に並んでいたら、いまより早く探せそうです。これを実現するためにインデックスを使います。
RDBにインデックスを作ると、テーブルのデータとは別に、木構造のデータを持ちます。
インデックスをイメージしやすくするために、商品のデータから少し離れます。
1〜15まで15件のデータで木構造を作ってみました。
2分探索木というデータ構造ですが、それ自体の説明は省きます。
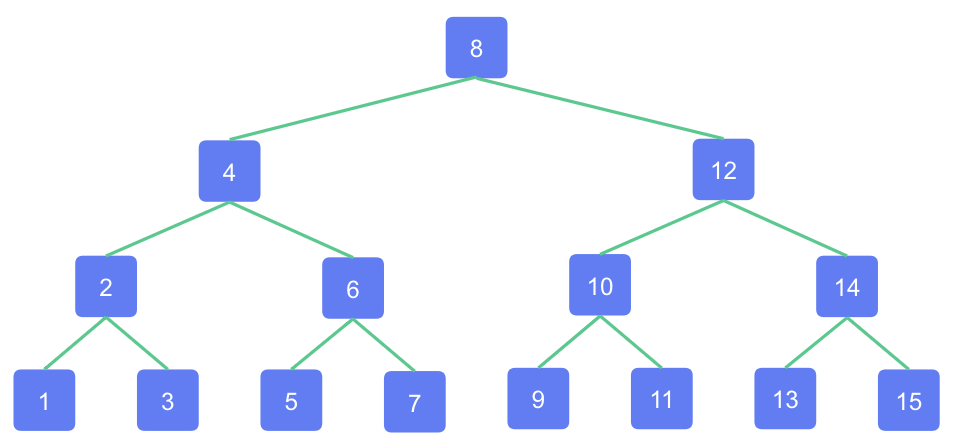
とにかく、中心の数である8を先頭に、小さいものを左の枝に、大きいものを右の枝にくっつけました。
この形だと、探したいデータが中心より大きいか、小さいかで選択肢が半分ずつになります。
例えば15を探す場合、バラバラのデータだと最大15回の探索が必要ですが、この木構造から探す場合は[8]→[12]→[14]→[15]と4回の探索で見つかります。木構造の階層が4つあるので、一番上の根から探索をスタートして、4回で一番下の葉までたどり着く感じですね。
どのくらい速くなるの?
データ件数が増えてくると効果が大きくなります。
データが31件だと木構造の階層が1つ増えて5回の探索、1,024件だと10回、65,536件だと16回の探索で目的のデータが探せます。
商品のデータの話に戻ります。
前提で書いた商品数が42億(≒2^32)の場合、インデックスが無いと商品コード「167975642」を探すのに3億回を超える探索を行い、5分半かかりました。これがインデックスがあると、最大でも32回の探索で済むので、0.000032秒で探し出せるようになります。
まとめると、データがn件の場合、インデックスがないと探索の計算量はO(n)になりますが、インデックスがあると
O(log_2 n)
で済みます。
あと、ツリーインデックスは範囲検索が得意です。商品コードが近いものは木構造でも近くにあります。
美味い話だけ?落とし穴があるんじゃないの?
商品テーブルの更新でインデックスの木構造を見直す必要があるので、更新に時間がかかるようになります。
特に範囲検索した結果を更新するなど、更新が特定の枝に集中する場合はコストが大きそうです。
最後に
これを読んで、なんとなく使っていたインデックスでデータの検索がどう変化するのか、イメージを持ってもらえると嬉しいです。