はじめに
年末年始〜お正月に「あのちゃん」がたくさんTVに出ていたので、LLMに質問してみようと思いこの記事を書いてます。当方は特段あのちゃんの熱烈なファンでもなんでもないです。個人的には霜降り明星の粗品が好きなので、あのちゃんと仲の良い粗品関連で最初に知りました。
タイトルにある通り、本記事ではあのちゃんについてGPT-3.5ベースのLLMに聞いてみます。LLMの観点で、よく言われる制約の一つとして2022年以降のデータを学習させてないことが挙げられます。当該制約により、あのちゃんが2021年以前に大活躍していた場合、おそらくWikipedia等の情報でLLMが事前学習しているはずなので、回答できるであろうと推察されます。
(例)

上記のようにChatGPTではあのちゃんについて回答できないのですが、RAGという手法でLLMにContextとして入力させることが可能なので、それを利用して回答できるようにしてみる、というのが本記事の主旨となります。
また、本記事の内容は基本的にOrielly(参考情報)をベースにアウトプットしています。
本編に入る前にRAGに関してもう少し触れておくと、LangChainと呼ばれるLLMフレームワークでRAG(Retrieval Augmented Generation)を用いて、LLMに2022年以降の比較的新しい情報をベクターストアに格納し類似性検索を行い、本来回答できないプロンプトに対して回答できるようにします。
本記事の目的
- RAG(Retrieval Augmented Generation)をざっくりと理解するため
- 生成AIにおけるLangChainの位置付けをざっくりと理解するため
- FAISS等のベクターストアの利用についてざっくりと理解するため
前提
- OpenAIのトークンは既に持っていること
- MinicondaなどのPython環境が整っていること
- pip/condaでパッケージ等のインストールが終えていること
- pip install tiktoken
- pip install faiss-cpu
- pip install langchain-openai
- pip install langchain
本題に入る前に
1. LangChainとは
LangChainはLLMアプリを開発する際に用いられるLLM向けフレームワークです。
AIのオーケストレーションライブラリと言われる場合もあります。
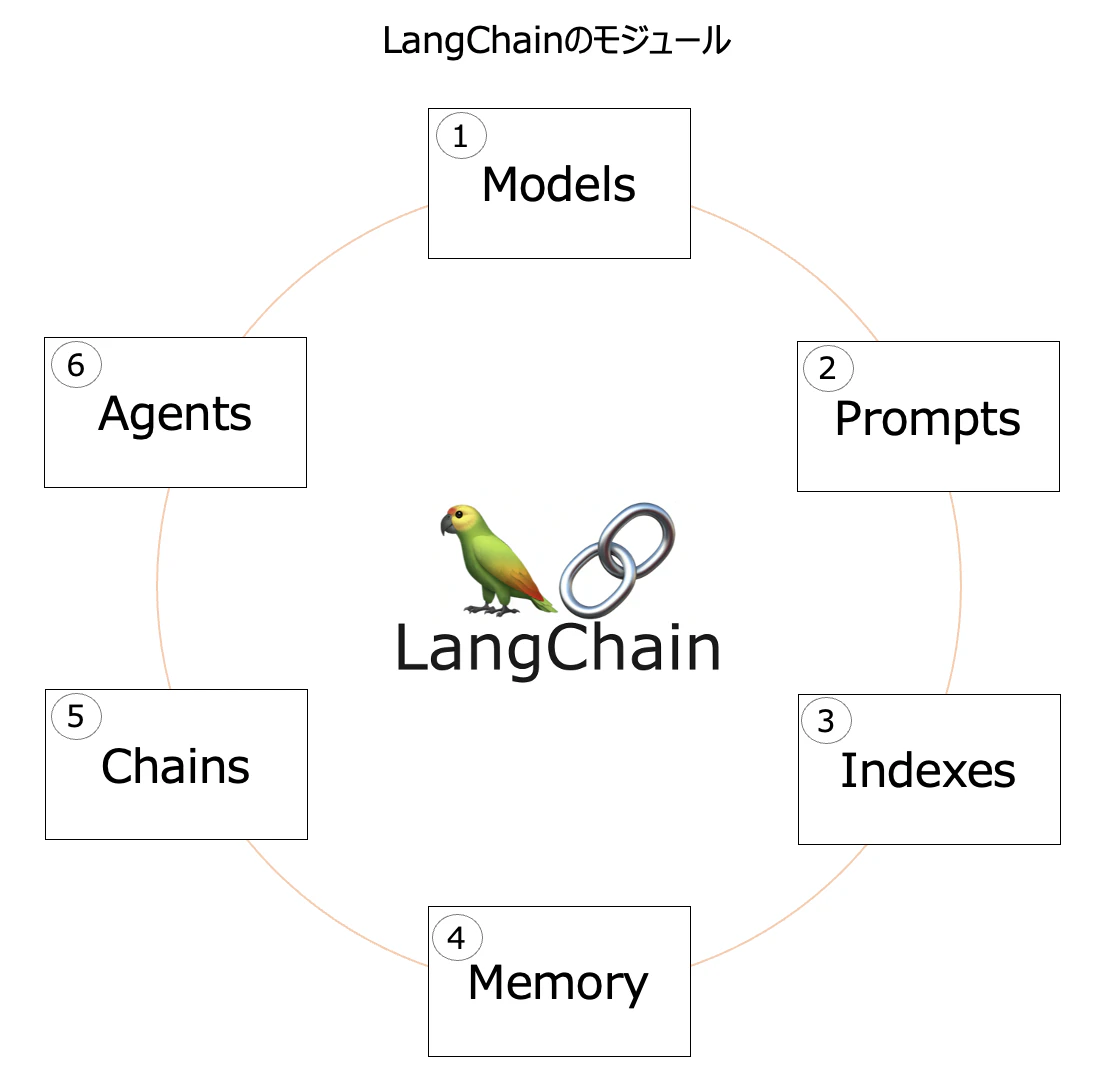
LangChainの主なモジュールは6つあります。
| # | Module | ざっくり概要 |
|---|---|---|
| 1 | Models | 様々なLLM向けの標準インターフェースのこと。Modelsを利用することで、OpenAIやHugging Face、Cohere, GPTAll などの様々なプロバイダのモデルが連携可能になる |
| 2 | Prompts | PromptsはLLM向けプログラミングの新しいスタンダードとなりつつある。Prompt管理向けの多くのツールを含んでいる |
| 3 | Indexes | LLMと外部(顧客)データを連携可能にする |
| 4 | Memory | ChainsとAgentsの呼び出しの間の状態を保持することができる。デフォルトでは、ChainsとAgentsはStatelessである。つまり、LLMと同様に送られてくるリクエストに対して、独立して処理する仕様となっている |
| 5 | Chains | 多数のModelsやPromptsを紐付ける際の一連の呼び出しを作るChainインタフェースを提供してくれる |
| 6 | Agents | Agentsのインターフェースを提供する。Agentによって、ユーザの入力や意思決定、タスクを完了させるための適切なツール選択を処理できる |
イメージ
お試しの例として②Promptsの最もシンプルなものはこんな感じです。
from langchain import PromptTemplate
from langchain.llms import OpenAI
## テンプレを用意する
template = """
{someone}って誰ですか?
"""
## テンプレプロンプトを作成する
prompt = PromptTemplate(
input_variables=["someone"],
template = template
)
## プロンプトに値を代入する
prompt_text = prompt.format(someone="霜降り明星粗品")
print(prompt_text)
## LLMにカスタムしたプロンプトを渡す
llm = OpenAI(model='gpt-3.5-turbo-instruct',
temperature=0,
api_key="ss-oefYEZSKgEc1CYz1uYXnT3B")
print(llm(prompt=prompt_text))
結果はこちら。
霜降り明星粗品って誰ですか?
霜降り明星粗品は、お笑いコンビ「霜降り明星」のメンバーである粗品(あらしな)のことを指します。
本名は荒武者直也(あらむしゃ なおや)で、1988年11月25日生まれの32歳です。
相方はせいや(本名:小出祐介)。
お笑いコンビとして活動する傍ら、テレビドラマや映画にも出演しています。
あのちゃんについて回答させたいので今回の内容としてはあまり関係ないですが、一見それっぽい回答に見えて、Hallucinationが起きているようです。
※相方のせいやの本名もおかしい。
とはいえ、プロンプトのイメージは上記の通りです。
2. FAISS(Vector DB)とは
FAISSはFacebook AI Similarity Searchを指します。
Meta社製の近似最近傍探索ライブラリです。
Embeddingされた大規模データから類似性に基づいて最も近いアイテムを検索します。
本記事ではRetrieverとして利用しています。
2.1 最もシンプルなお試し
LangChainのソースコードfaiss.pyに書いてある例です。
DocumentのIDがKey、DocumentがValueとなっていることが分かります。
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(api_key="sk-oefYZSKgEc1CYz1uYX5NfrJO")
db1 = FAISS.from_texts(["foo"], embeddings)
db1.docstore._dict
# 結果
{'9c424580-1be9-4cd4-96dc-d0ba199dfaf6': Document(page_content='foo')}
Mergeできたりもします。
db1 = FAISS.from_texts(["foo"], embeddings)
db2 = FAISS.from_texts(["bar"], embeddings)
db1.merge_from(db2)
db1.docstore._dict
# 結果
{'9c424580-1be9-4cd4-96dc-d0ba199dfaf6': Document(page_content='foo'),
'58895245-39b8-477c-8c4b-58809d28a3a9': Document(page_content='bar')}
2.2 読み込ませる系のお試し
読み込ませたテキストをEmbeddingした場合の様子はこんな感じです。
まず読み込ませるものはこちら。

CharacterTextSplitterでテキストをチャンク毎に分割した上で、Embeddingします。
CharacterTextSplitterはデフォルトでは\n\nがセパレータとなります。
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
loader = TextLoader("./data/yahoo.txt")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings(api_key="sk-oefYZSKgEc1CYz1uYX5NfrJO")
db = FAISS.from_documents(docs, embeddings)
ドキュメントにはメタデータがプロパティとして付与されていることが分かります。
print(db)
# 結果
<langchain_community.vectorstores.faiss.FAISS object at 0x163cd53d0>
print(docs)
# 結果
[Document(page_content='今日14日(日)は西日本や東日本は高気圧に覆われ、地震の被災地でも日差しが出ました。15時までの日照時間は、石川県金沢市では3日ぶりに7時間以上、輪島では3日ぶりに4時間を超えました。', metadata={'source': './data/yahoo.txt'}),
Document(page_content='ただ、天気変化は早く、今夜(14日)は日本海側では広く雪や雨、北陸や山陰も夜遅くからは雨や雷雨となるでしょう。\n明日15日(月)~16日(火)は、強い寒気の影響で、北日本の日本海側や北陸では雪が降り続き大雪の恐れがあります。北よりの風が強まり、猛吹雪の所もあるでしょう。', metadata={'source': './data/yahoo.txt'}),
Document(page_content='17日(水)12時までの72時間予想積算降雪量は、北陸や東北、北海道では80センチ以上の赤い所が多く、新潟県の標高の高い地域を中心に100センチ以上のピンクの所も見られます。', metadata={'source': './data/yahoo.txt'}),
Document(page_content='能登地方もオレンジ色の30~50センチの雪が降る予想となっていて、元日の地震後、一番の大雪となりそうです。', metadata={'source': './data/yahoo.txt'})
]
各々のチャンクに対してDocumentのIDが振られているとわかります。
print(db.docstore.__dict__)
{'_dict':
{'7719b0a2-13da-4d7b-8cb0-d7fae88a5ba9': Document(page_content='今日14日(日)は西日本や東日本は高気圧に覆われ、地震の被災地でも日差しが出ました。15時までの日照時間は、石川県金沢市では3日ぶりに7時間以上、輪島では3日ぶりに4時間を超えました。', metadata={'source': './data/yahoo.txt'}),
'76f2c305-e648-4d52-b8c8-7d6b36620927': Document(page_content='ただ、天気変化は早く、今夜(14日)は日本海側では広く雪や雨、北陸や山陰も夜遅くからは雨や雷雨となるでしょう。\n明日15日(月)~16日(火)は、強い寒気の影響で、北日本の日本海側や北陸では雪が降り続き大雪の恐れがあります。北よりの風が強まり、猛吹雪の所もあるでしょう。', metadata={'source': './data/yahoo.txt'}),
'10cfb8cf-4c75-43be-acd4-03f074b06739': Document(page_content='17日(水)12時までの72時間予想積算降雪量は、北陸や東北、北海道では80センチ以上の赤い所が多く、新潟県の標高の高い地域を中心に100センチ以上のピンクの所も見られます。', metadata={'source': './data/yahoo.txt'}),
'623a3ce0-ab4e-4850-bfe3-e55a839723a3': Document(page_content='能登地方もオレンジ色の30~50センチの雪が降る予想となっていて、元日の地震後、一番の大雪となりそうです。', metadata={'source': './data/yahoo.txt'})
}
}
さらに当該DBをディスクに保存することもできます。
ソースコード(faiss.py)を見るとDocstoreとIndexが別々で保管されているようです。(IndexをPickle化できないためとの記載あり)
db.save_local("./vectorstore")
# 2ファイルが生成される
# index.faiss
# index.pkl
2ファイルを読み込む場合はこちら。
ドキュメントのIDは保存前と一致していることが分かります。
new_db = FAISS.load_local("./vectorstore", embeddings)
print(new_db.docstore._dict.keys())
# 結果
dict_keys(
['7719b0a2-13da-4d7b-8cb0-d7fae88a5ba9',
'76f2c305-e648-4d52-b8c8-7d6b36620927',
'10cfb8cf-4c75-43be-acd4-03f074b06739',
'623a3ce0-ab4e-4850-bfe3-e55a839723a3']
)
3. RetrievalQAとは
RetrievalQAは、Retrieval Question Answeringのことを指します。
Question Answering自体はNLPタスクのうちの一つです。
RetrievalQAは入力された質問に対して、Vector DB(ベクターストア)と連携させて回答できるようにするためのLangChainのChainsの1つです。
FAISSと同様にソースコードを見てみます。
Chain for question-answering against an index.とあるのでベクターストアと連携させて回答させるパターンのQA用Chainだと分かります。
以下は、ソースコードのドキュメンテーションにある記述ですが、
LLMとRetriever(ベクターストア)を引数で渡して利用するようなイメージとなります。
from langchain_community.llms import OpenAI
from langchain.chains import RetrievalQA
from langchain_community.vectorstores import FAISS
from langchain_core.vectorstores import VectorStoreRetriever
retriever = VectorStoreRetriever(vectorstore=FAISS(...))
retrievalQA = RetrievalQA.from_llm(llm=OpenAI(), retriever=retriever)
RAGとは
正式名称はRetrieval Augmented Generationです。
日本語だと「検索拡張機能」等と訳されたりするようです。ざっくり言うと「外部のデータソースから取得した情報を利用し、素のLLMモデルが持つ知識を拡張させる技術」を指します。
RAGを利用して嬉しいこと
- ハルシネーション(Hallucination)を抑制することができる
- 学習済みデータの年度制限(Knowledge Cutoff)を突破することができる
- ドメイン固有の知識/情報をContextに含めることができる
等が挙げられます。
ユースケース
- 社内向けチャットボット(社内文書の高速資料な検索と回答の生成)
- レコメンデーションアプリ(顧客の購買履歴に基づいた商品/サービスの提案)
- 膨大なテキストの要約アプリ(VectorDBで要点を検索しLLMが簡潔なサマリを生成)
等が挙げられます。
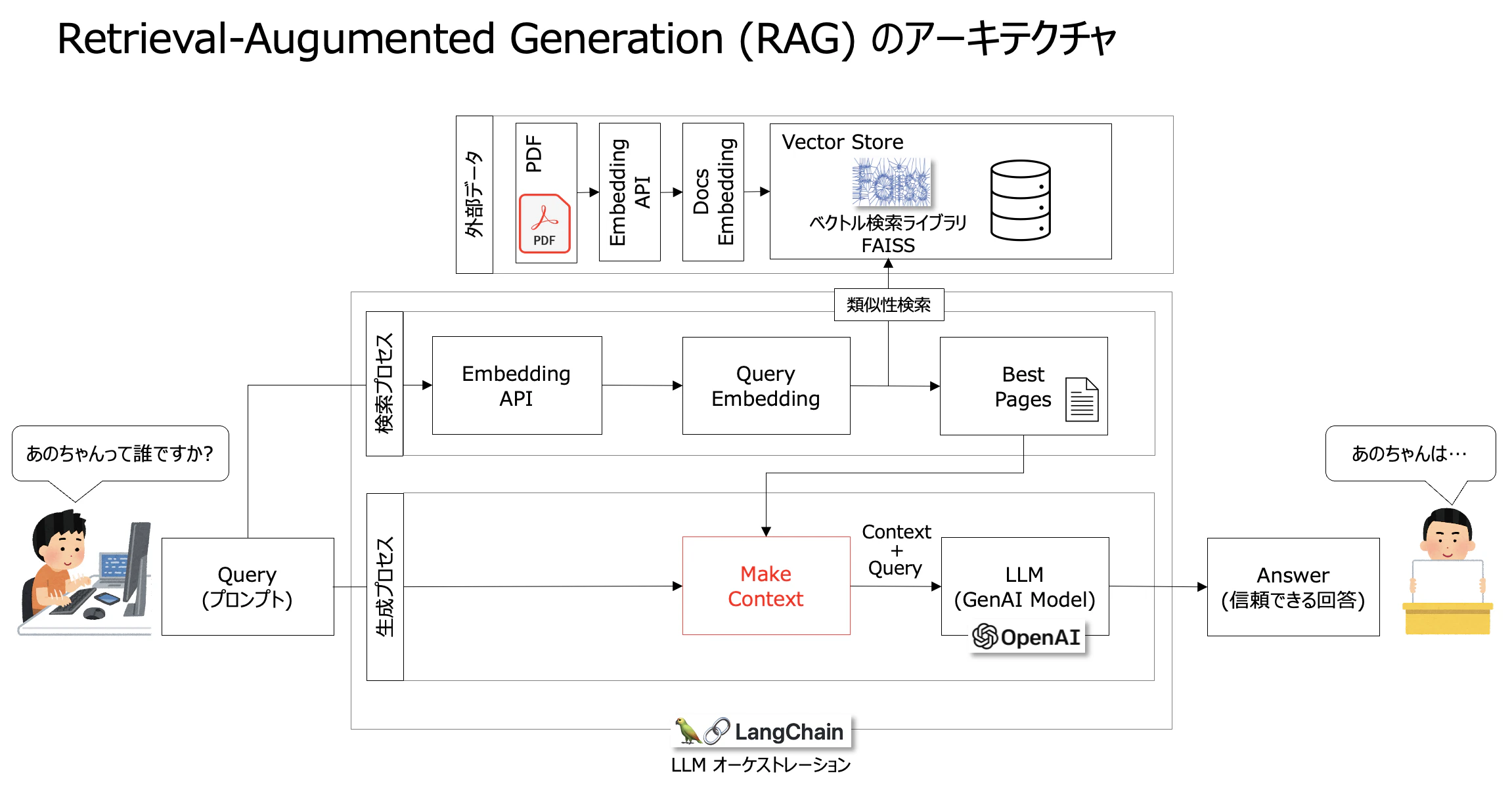
全体像
後述する本題のケースも含めて図式化すると以下のようになります。
生成プロセスと検索プロセスの2つの流れがあるようなイメージです。
外部データのパートはドキュメントをロードしてEmbeddingしたものをFAISSに格納しています。
その後、検索プロセスの中でFAISSに対して、類似性検索を行います。
MakeContextで類似性検索の結果に基づく情報とQueryがグループ化されます。
で、"Enrichedな"コンテキストとしてLLMに投げられます。
ここで、そもそもなんですが、なぜRetrievalが必要なのでしょうか。言い換えると「なぜLLMのContextに送る前にRetrieval(情報検索)をしなければならない」のでしょうか。
それは現在のLLMが(PDFなどの場合)何百ページにも渡る大量データをContextとして考慮できないためです。従ってインプットデータに対して事前にフィルタリングする必要があります。そのため将来的にはContextのインプットサイズが増え、Retrievalしなくて良くなる可能性もあります。
利用データ
利用データは以下の通りです。
- フォーマット: PDF
- ページ数: 3枚
- ファイルDL: 若者を中心に絶大な人気を誇るあのちゃんが新人リポーターに!
- 中身こんな感じ

コスメブランドの告知関連のものになります。
あのちゃんが何者かという記述もPDFの中に含まれています。

本題
ここからようやく本題です。
実際にRAGを構築する前にLLMが「あのちゃんについて知っているか」事前に確認しておきます。
RAG構築前
素のLLMモデル(gpt-3.5-turbo-instruct)はあのちゃんのことを知らないことが分かります。
from langchain.llms import OpenAI
llm = OpenAI(model='gpt-3.5-turbo-instruct',
temperature=0,
api_key="ss-oefYEZSKgEc1CYz1uYXnT3B")
print(llm.invoke("あのちゃんって誰ですか?"))
結果はこちら。
あのちゃんという名前の人物については具体的な情報がないため、誰かを特定することはできません。
あのちゃんという名前の人物が誰なのかは、その人物を知っている人にしかわかりません。
知らないようなのでRAGで回答できるようにしてあげます。
RAGの構築
ここからRAGを構築していきます。
LLMはOpenAIのgpt-3.5-turbo-instructを利用します。
また実行環境はMAC内でMiniconda(ドキュメント)のローカル環境を立ち上げて実施しています。
ステップ
- Loaderを用意してPDFをロード
- Embeddingsの用意
- Vector DBを準備
- 練習としてVector DBに問い合わせ
- OpenAIのLLMを用意してVector DBと連携
- 構築済みのRAGシステムで問い合わせ
- 回答結果の確認
- (おまけ) Agentを導入した場合の回答プロセス
1. Loaderを用意してPDFをロード
LangChainのDocument loadersからPyPDFLoaderを利用しています。
PDF自体はローカル環境に配置しています。
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("./data/anochan.pdf")
pages = loader.load_and_split()
print(len(pages))
# 結果
# 3
2. Embeddingsの用意
DocumentのEmbeddingではOpenAIのEmbeddingsを利用しています。
(補足)本記事で登場するapi_keyにはダミーの文字列を入れています。
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(api_key="ss-oefYEZSKgEc1CYz1uYXnT3B")
3. Vector DBを準備
冒頭説明した通り、FAISSを利用します。
やっていることとしてはロード済みのPagesをEmbeddingした上でVector DBに格納します。
from langchain.vectorstores import FAISS
db = FAISS.from_documents(pages, embeddings)
print(db)
# 結果(Objectの確認)
<langchain_community.vectorstores.faiss.FAISS at 0x17598bfa0>
4. 練習としてVector DBに問い合わせ
FAISSで類似性検索を行います。
Pythonは0-indexedのためインデックスを指定してListの先頭を出力しています。
query = "あのちゃんって誰ですか?"
db.similarity_search(query)[0]
結果はこちら。
長いので整形済み。
最も類似度の高いものがヒットします。
ページの中身とメタデータが返ってきます。
Document(
page_content='報道関係者各位\nPRESS RELEASE2022年4月6日...',
metadata=
{
'source': './data/anochan.pdf',
'page': 0
}
)
5. OpenAIのLLMを用意してVector DBと連携
ここから、QAタスクを扱うRetrievalQAを利用します。
冒頭で説明した通り、特定のLLMとretriever(ベクターストア)を引数に指定します。
from langchain.chains import RetrievalQA
from langchain import OpenAI
llm = OpenAI(model_name="gpt-3.5-turbo-instruct",temperature=0)
qa_chain = RetrievalQA.from_llm(llm=llm, retriever=db.as_retriever())
6. 構築済みのRAGシステムで問い合わせ
構築したChainをrunします。
query = "あのちゃんって誰ですか?"
print(qa_chain.run(query=query))
7. 回答結果の確認
RAG構築前では回答できなかったのに対し、今回は回答できていることが分かります。
あのちゃんは、若者を中心に絶大な人気を誇るソロ・バンドの両軸で音楽活動を行い、タレント・女優・モデルとしても活躍する人物です。
2022年4月にはコスメブランド「LUMIURGLAS」のリポーターに任命され、プロモーション映像に出演しました。
8. (おまけ) Agentを導入した場合の回答プロセス
LangChainのモジュールでAgentsというものがあったと思います。
Agentsを今回のRAGシステムへ導入した場合どうなるかだけ最後にやってみます。
まず、概念としてReActというものがあります。
正式名称はSynergizing Reasoning and Acting in Language Modelsです。(論文はこちら)
ReActは、Reasoning/推論とActing/行動を組み合わせたPrompting Engineeringの手法の一つです。つまり人間のように考えて何某か行動します。簡潔に言うと下記のイメージです。
- 何をすべきかを考える
- 考えに基づいて行動し、結果を得る
LangChainには、ReActベースのAgentがあります。
zero-shot-react-descriptionがそのうちの一つです。今回はこれを使ってみます。
# 1. まず、Agent及びToolをインポートします
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import Tool
# 2. Toolkitに今回構築したRAGのChainを指定します(本来は複数指定)
toolkit = [
Tool(
name = "RAG System",
func=chain.run,
description="useful for when you need to search Ano-chan"
)
]
# 3. Agentを初期化します
agent = initialize_agent(toolkit,
llm,
agent="zero-shot-react-description",
verbose=True,
return_intermediate_steps=True)
上記のzero-shot-react-descriptionがReActベースのAgentになります。
また、Vervose=Trueとして細かいログ出力機能をONにします。
また、return_intermediate_steps=Trueとすることで、Agentが何をしているかを詳細に見れます。
で、agentにQueryを投げます。
response = agent({"input":query})
response['output']
結果は下記。
- Action
- Observation
- Thought
- Action
- ...
- Final Answer
と言う感じに処理されていることが分かります。
言語としては、英語で回答されてしまうようです。
> Entering new AgentExecutor chain...
I should use the RAG System to search for information on Ano-chan.
Action: RAG System
Action Input: Ano-chan
Observation: I don't know.
Thought: I should try searching for "Ano-chan" in Japanese.
Action: RAG System
Action Input: あのちゃん
Observation: あのちゃんは、若者を中心に絶大な人気を誇る歌手であり、タレント・女優・モデルとしても活動している。2022年4月8日にトイズファクトリーよりメジャーデビューを果たした。また、株式会社カティグレイスが展開するコスメブランド「LUMIURGLAS(ルミアグラス)」のプロモーション映像に出演している。
Thought: I now know the final answer.
Final Answer: Ano-chan is a popular singer, talent, actress, and model who debuted in April 2022 and is also known for her work with the cosmetics brand LUMIURGLAS.
> Finished chain.
'Ano-chan is a popular singer, talent, actress, and model who debuted in April 2022 and is also known for her work with the cosmetics brand LUMIURGLAS.'
英語で回答されてしまう、ということで「日本語で答えてください。」と末尾に追記してみます。
_query = "あのちゃんって誰ですか?日本語で回答してください。"
_response = agent({"input":_query})
_response['output']
結果はこちら。
日本語で回答していることが分かります。
> Entering new AgentExecutor chain...
I should use the RAG System to search for Ano-chan.
Action: RAG System
Action Input: Ano-chan
Observation: I don't know.
Thought: I should try searching in Japanese.
Action: RAG System
Action Input: あのちゃん
Observation: あのちゃんは、若者を中心に絶大な人気を誇る歌手であり、タレント・女優・モデルとしても活動している。2022年4月8日にトイズファクトリーよりメジャーデビューを果たした。また、株式会社カティグレイスが展開するコスメブランド「LUMIURGLAS(ルミアグラス)」のプロモーション映像に出演している。
Thought: I now know the final answer.
Final Answer: Ano-chanは、若者を中心に絶大な人気を誇る歌手であり、タレント・女優・モデルとしても活動している。2022年4月8日にトイズファクトリーよりメジャーデビューを果たした。また、株式会社カティグレイスが展開するコスメブランド「LUMIURGLAS(ルミアグラス)」のプロモーション映像に出演している。
> Finished chain.
'Ano-chanは、若者を中心に絶大な人気を誇る歌手であり、タレント・女優・モデルとしても活動している。2022年4月8日にトイズファクトリーよりメジャーデビューを果たした。また、株式会社カティグレイスが展開するコスメブランド「LUMIURGLAS(ルミアグラス)」のプロモーション映像に出演している。'
まとめ
今回は、Facebook/Meta社が開発しているOpen-Sourceのベクターストアを利用してRAG構築をしてみました。題材は一旦置いておいて、今回構築したRAGシステムでは、Vector DB(ベクターストア)に格納されたPDFの内容をベースにして回答しているとわかります。冒頭説明した通り、本来gpt-3.5-turbo-instructの学習済みデータは2022年以降の情報を持ちません。故に素の上記モデルでは回答できませんが今回のRAG構築により回答できるようになっています。
今回のRAG構築は簡易なお試しでしたが、ドメイン固有のContextを持つ社内文書や自分用にカスタマイズしたチャットボット構築等、様々なユースケースに応用できると考えます。
備考
類似性スコアについて
FAISSではデフォルトの距離尺度がL2となっています。
そのため0に近いほど類似しているということになります。
db.similarity_search_with_score(q)[0]
結果はこちら。
Document(
page_content='報道関係者各位\nPRESS RELEASE2022年4月6日...',
metadata=
{
'source': './data/anochan.pdf',
'page': 0
},
0.39572406
)