概要
前々回 (1/3): https://qiita.com/tfull_tf/items/6015bee4af7d48176736
前回 (2/3): https://qiita.com/tfull_tf/items/968bdb8f24f80d57617e
コード全体: https://github.com/tfull/character_recognition
かな認識モデルが、システムの動作確認ができる水準になったため、 GUI で画像を生成し、それをモデルに読み込ませて文字を出力するものを作ります。
Tkinter でかな入力用パレットを作成する
Tkinter を使うので、インストールをしておきます。
# Mac + Homebrew の場合
$ brew install tcl-tk
# Ubuntu Linux の場合
$ sudo apt install python-tk
canvas を作り、その中に左クリックで白い線を、右クリックで黒い線(黒い背景なので実質消しゴム)を引きます。ボタンは2つ用意し、書いた文字を認識させるものと、書いたものを消す(黒で塗りつぶす)操作をさせます。
import tkinter
# from PIL import Image, ImageDraw
class Board:
def __init__(self):
self.image_size = 256
self.window = tkinter.Tk()
self.window.title("かな入力")
self.frame = tkinter.Frame(self.window, width = self.image_size + 2, height = self.image_size + 40)
self.frame.pack()
self.canvas = tkinter.Canvas(self.frame, bg = "black", width = self.image_size, height = self.image_size)
self.canvas.place(x = 0, y = 0)
self.canvas.bind("<ButtonPress-1>", self.click_left)
self.canvas.bind("<B1-Motion>", self.drag_left)
self.canvas.bind("<ButtonPress-3>", self.click_right)
self.canvas.bind("<B3-Motion>", self.drag_right)
self.button_detect = tkinter.Button(self.frame, bg = "blue", fg = "white", text = "認識", width = 100, height = 40, command = self.press_detect)
self.button_detect.place(x = 0, y = self.image_size)
self.button_delete = tkinter.Button(self.frame, bg = "green", fg = "white", text = "削除", width = 100, height = 40, command = self.press_delete)
self.button_delete.place(x = self.image_size // 2, y = self.image_size)
# self.image = Image.new("L", (self.image_size, self.image_size))
# self.draw = ImageDraw.Draw(self.image)
def press_detect(self):
output = recognize(np.array(self.image).reshape(1, 1, self.image_size, self.image_size)) # recognize は機械学習を使って認識させる関数
sys.stdout.write(output)
sys.stdout.flush()
def press_delete(self):
# self.canvas.delete("all")
# self.draw.rectangle((0, 0, self.image_size, self.image_size), fill = 0)
def click_left(self, event):
ex = event.x
ey = event.y
self.canvas.create_oval(
ex, ey, ex, ey,
outline = "white",
width = 8
)
# self.draw.ellipse((ex - 4, ey - 4, ex + 4, ey + 4), fill = 255)
self.x = ex
self.y = ey
def drag_left(self, event):
ex = event.x
ey = event.y
self.canvas.create_line(
self.x, self.y, ex, ey,
fill = "white",
width = 8
)
# self.draw.line((self.x, self.y, ex, ey), fill = 255, width = 8)
self.x = ex
self.y = ey
def click_right(self, event):
ex = event.x
ey = event.y
self.canvas.create_oval(
ex, ey, ex, ey,
outline = "black",
width = 8
)
# self.draw.ellipse((ex - 4, ey - 4, ex + 4, ey + 4), fill = 0)
self.x = event.x
self.y = event.y
def drag_right(self, event):
ex = event.x
ey = event.y
self.canvas.create_line(
self.x, self.y, ex, ey,
fill = "black",
width = 8
)
# self.draw.line((self.x, self.y, ex, ey), fill = 0, width = 8)
self.x = event.x
self.y = event.y
これで、文字を書く、消すという操作が実現できます。
pillow を用いて内部で追従させる
幾らか調べたところ、 Tkinter の Canvas は、線を引いたりすることができるので文字がかけますが、書いたものを読み込んで数値化することができないようです。
解決策を模索していると、 Pillow を内部で持っておいて、 Canvas に描画するときに同じものを Pillow の Image に描画すれば良い、という議論を見つけました。(そんなことは思いつかなかったので、すごく賢い策だなと思いました。)上のコードでコメントアウトされている部分がそれに対応します。 Pillow の Image は numpy.array ですぐに numpy の配列にできるため、機械学習モデルに与えることが容易です。
かな認識システムの完成
手書き文字を入力する GUI と、かなの画像を分類する機械学習モデルが完成しました。これを組み合わせたものが次です。
YouTube: https://www.youtube.com/watch?v=a0MBfVVp7mA
動作確認の所感と考察
精度が高い、とは言えないものの、まあまあ正しく認識してくれました。汚い文字は認識してくれませんが、「あいうえお」と丁寧に入力すると、きちんと対応する文字を出力してくれました。
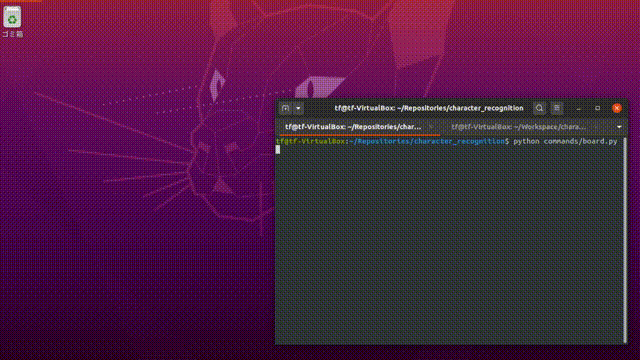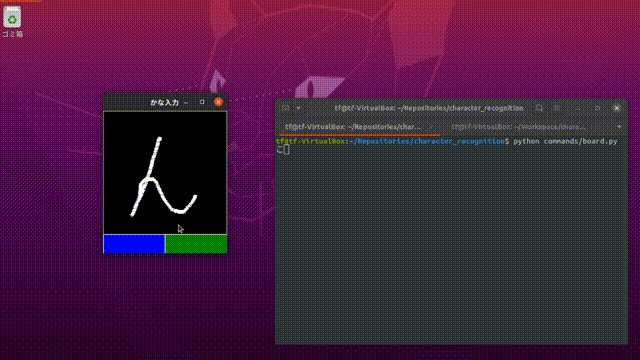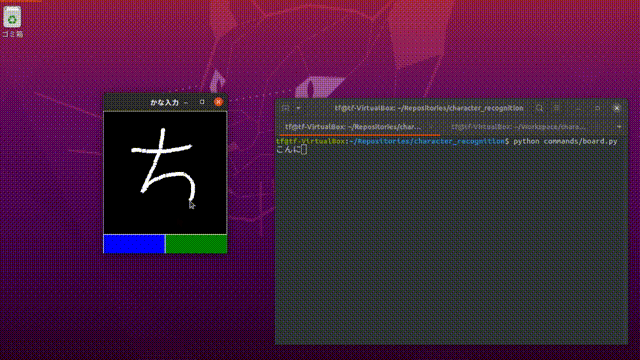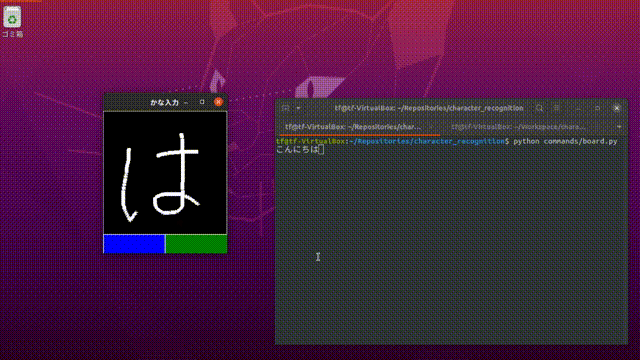
「こんにちは」で試したところ、「ち」が「ら」や「ろ」に認識される場合が頻発しました。気になったので「ち」の画像データを確認すると、自分で書いた「ち」と画像のそれの形が少し乖離があることがわかりました。フォントは3種類だけで学習させたので、やはり形の変わった入力には対応しきれないみたいです。入力したデータに近い形で文字を書くと正しく認識してくれました。
認識時間は、機械学習モデルに GPU を使わずとも一瞬で結果を出力してくれます。
漢字も認識できればそれが理想ですが、分類先が169から数千単位になります。かなだけでも十分と言える正確性ではないため、性能が一気に落ちそうな気がします。
少し手間がかかりますが、分類の確率が高い上位n件を出力するようにすれば、インターフェースとしての利便性が上がると思います。
あとは、単語としての確からしさを学習しておいて、文字の形+単語としての尤度で認識させれば、意味のある単語や文章を入力するときの精度は上がるかもしれません。(例えば、「こんにち」を入力したとき、次は「は」が来そうというのを加味させる。)