de:code 2018に参加してきましたのでその結果をまとめています。
内容の間違い、誤字脱字等はご了承ください。正確なところは、本家のサイトを参照いただければと思います。
タイトル等
タイトル
de:code 2018 [AI02] 現場写真を有効活用せよ〜 Deep Learning と Azure ML Services で挑む竹中工務店の働き方改革
演者
- 藤本 浩介さん 日本マイクロソフト株式会社 コマーシャルソフトウェアエンジニアリング本部 テクニカルエバンジェリスト
- 髙井 勇志さん 株式会社竹中工務店 技術研究所 先端技術研究部 主任研究員 博士
日時
2018/05/23 16:20-17:10
概要、感じたこと
実際の機械学習プロジェクト現場の知見を共有するセッション。
まずは作ってみること、みせること、1週間でやること、効率化の準備は行うこと。他のセッションと共通する面もありますが、まずはやってみることと、そのための効率的な準備も行って試行することが大事ではないか、と感じました。
また、実際にどのように認識率を上げていったのか、というプロセスも非常に参考になりました。
決めたら走れ!で頑張らないと、と思います。
セッションの概要
このセッションでは、リアルなリアルな現場から得た学び(知見)を還元していきたいと思っている。アルゴリズムは説明しない代わりに実用的なテクニックや考えかたを説明していく。
アルゴリズムは別セッションを参考にしてほしい。

ビジネスサイド
- 課題の見極め
- AI/MLならではのプロマネ
テクニカルサイド
- 効率よく
- 精度向上
ビジネスサイド
5.7%
建設業界で、週に2日休めている人は5.7%だけである。
これは大きな問題。時間外労働は罰則化されることが決定されているが、そうすると建設業は建物を建てられなくなる。少なくとも今のコストと工期では。非常に社会性の強い問題となっている
例えば、実際に1人の働き方を見てみると、時間外の労働が多い、土日も働いている。
AIでなんとかならないの?→大チャンス!
こういう問題に対して、AIでなんとかならないの?と言われると嫌になるエンジニアが多いかもしれない。
しかし、実は大チャンスなんです。ニーズと技術から、実際のブレイクスルーを起こすことができるのはエンジニアだけ!

ターゲットの絞りこみ
実際に行うときは、ターゲットを絞り込むことで成功につなげることができる
- 意義があるもの
- 波及効果があるもの
- できそうなもの
写真関連業務
そこで選んだのが写真管理業務となる。
驚くかもしれないが、施工管理のすべての写真を確認しているが、このすべて目で確認している!
実際にどのくらい写真を撮ているのか?というと
年間1億枚
鉄筋コンクリートを入れたり壁を入れたりすべての工程について写真を撮っているが、この全てについて、人間が目で確認している。
データの問題
現場に実際にデータがたくさんあるといっても、いろいろな問題がある。
- 溶接といっても溶接工と溶接面の写真が同じフォルダ分けされているおじさんの写真が写っても
- 日本語やUNICODE問題
- MacなどOS違いの問題
現場はデータに関する技術要求はわからないので、エンジニアが整理・確認しないと使えるデータとはならない。
扱い問題

知財に関する問題などはついてまわるもの。相手が何を心配しているかを把握し、現場にピンポイントで説明し、納得してもらう必要がある。
Demo
デジカメがつけたタグの中にユーザーコメント、というフィールドがあるが、この中に分類とその適合度が付いてシステムから返される。データは、JPECのEXIFについてくるので、エクスプローラーで検索できる。
プロジェクトを進めるポイント
完璧を進めるよりまず見せろ
顧客は形にしたものを見せないと、何がほしいかわからない
相手に将来像を語らせろ
高井さんの言葉
テクニカルサイド
Lets Code
すべてGitHubにコードを上げているのでやってみたい人はチェックしてみよう
基本用語の確認
機械学習では、必ずTraining,Validaton,Testのセットが必要!
ログ
機械学習では大量の試行を行うことになるが、1週間でGPUのサーバーを3つ立ててやっていると困るのは、次の3つ
- ジョブの管理
- ログ管理も
- 出力ファイル管理
また、試行する中では、実質1週間で動くものを作って行くことが大事になってくる。そのために効率化を図ることが大事。
効率化のためにツールが必要
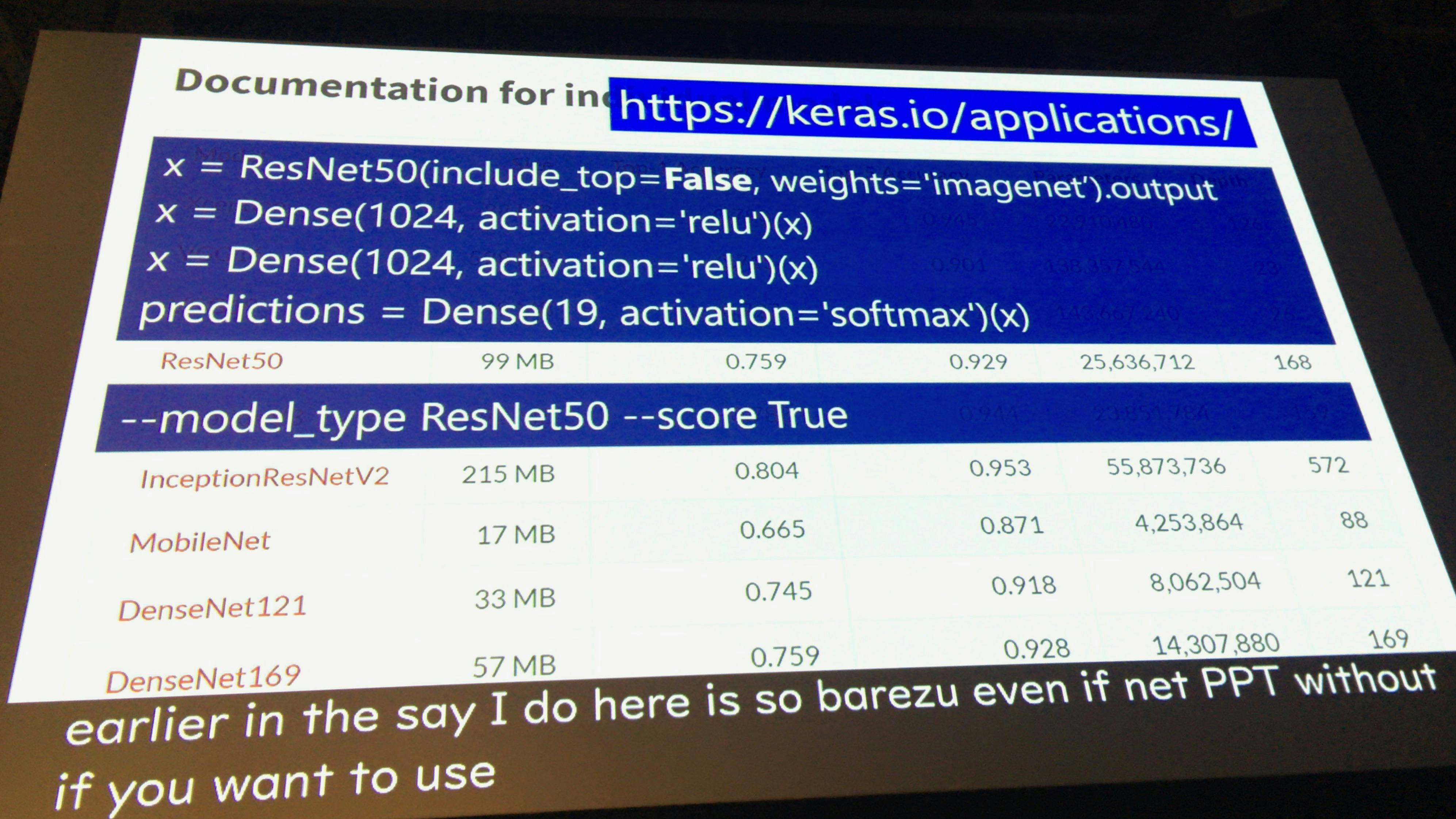
機械学習のエンジンとしては、Keras(TensorFlow)を使用している。理由は、オープンソースでサンプル豊富であること、多くの人に使用されているため、最新の論文のアルゴリズムが実装されていることが挙げられる。
機械学習を素早くやるのに便利な選択となる。
管理のために、3つPCを立てて、モデル管理サービスを行い、Azure Machine Learning WorkBenchを使用することで管理しやすくなった。
機械学習に必要な画像の数
昔は100万枚といっていた。
しかし、最近は1万枚程度でOKになっている。個人的にはもうちょっと少なくても良いのではないかと思っている。
理由は、転移学習を使うことである。
転移学習を使えばよい
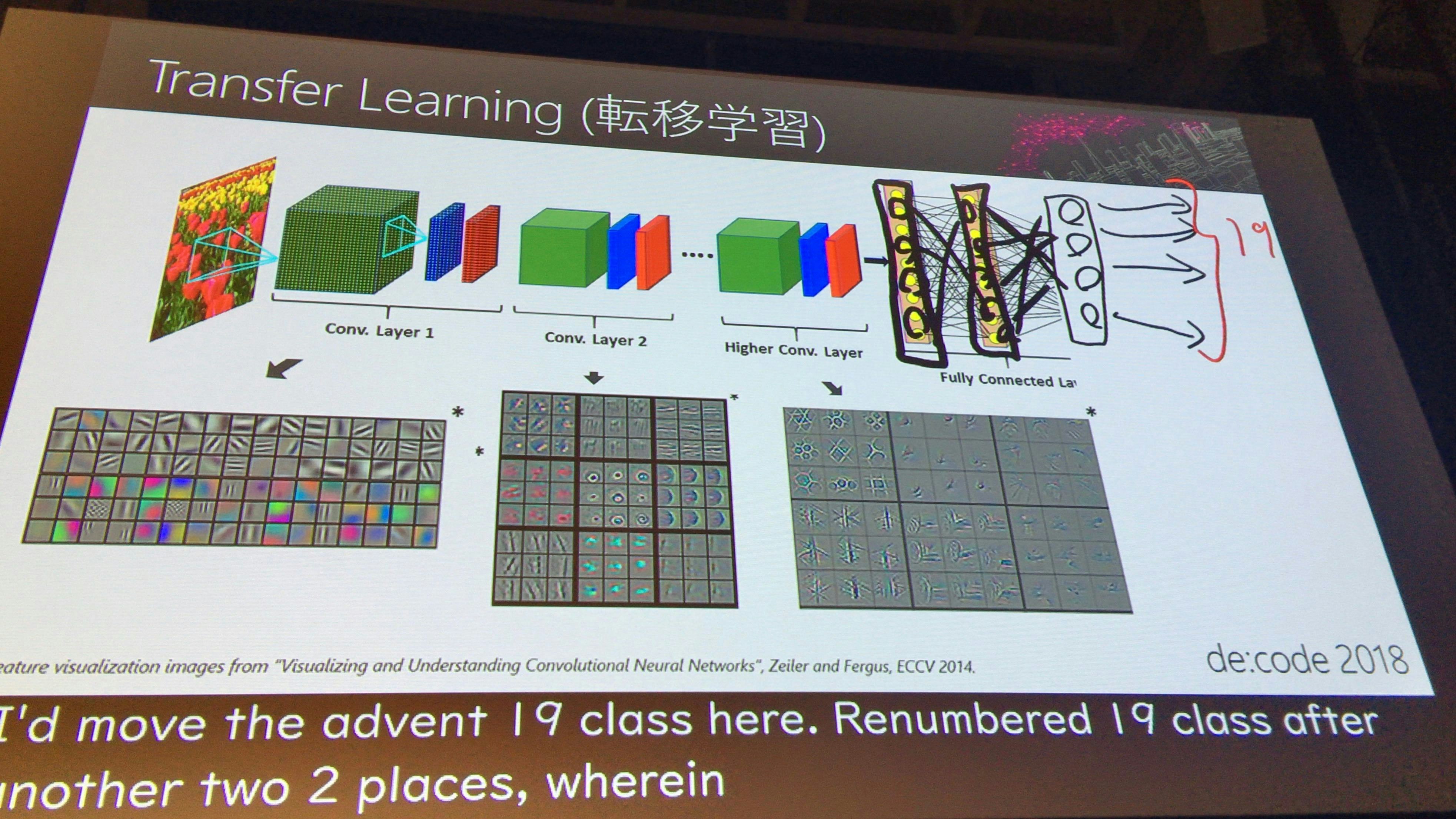
学習済みのモデルを使い、一番右の出力層だけを変えることを転移学習という。
転移学習をつかうことで、機械学習の効率を上げ、使用するデータの数を飛躍的に減らすことができる。
モデルのところは使いまわすので、ハイパーパラメータ(筆者注 機械学習の学習係数など、各関数等に与えるパラメータのことを言います)の試行を少なくても良くなる。つまり目的を達するまでの時間を少なくすることができる
どうやって認識率を上げていったか
Azure Machine Learning WorkBenchでは、結果から作成したグラフも同時に保存することができる。このグラフを参考に、分析と改善を行う。
まずはlossを減らす
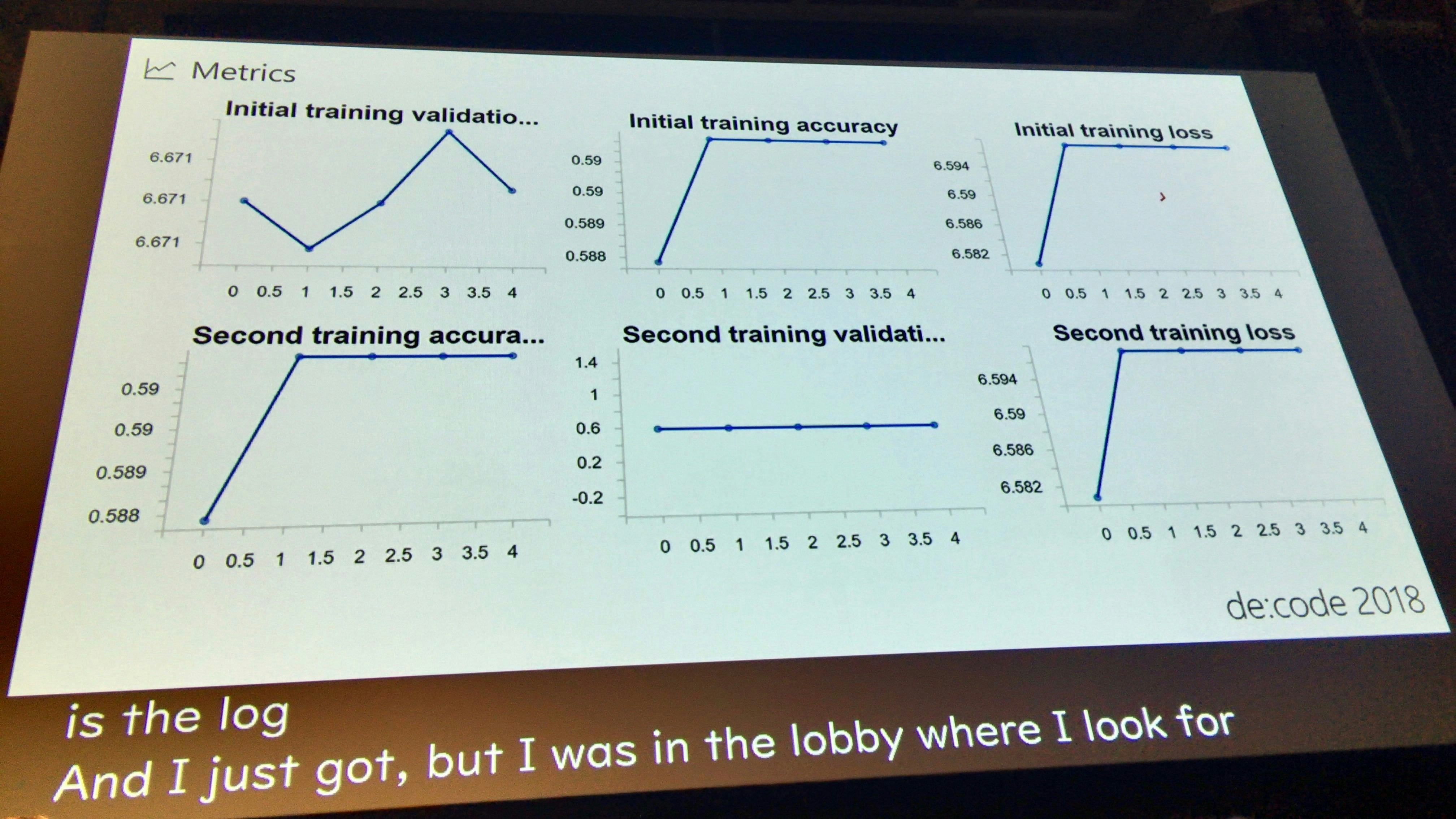
1回目(Initial)、2回目(Second)、2回のトレーニングについて、まずはlossを減らして行くことが最初の目標となる。
分析
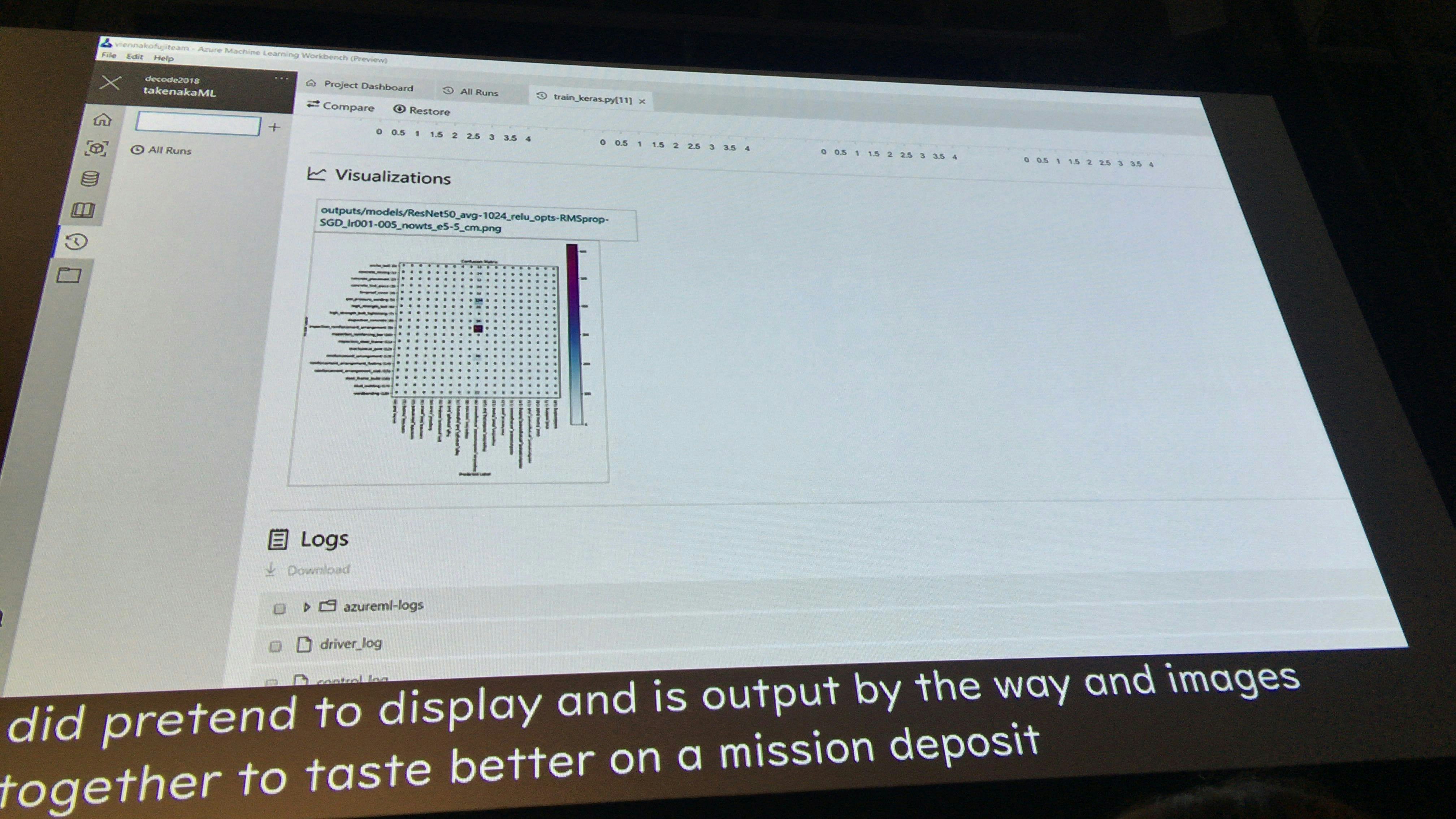
マトリックスでは、縦軸:実際の結果、横軸:理想的な結果となっている。
そのため、左上から右下への結果のラインが流れて行くのが理想であり、いかにここに近づけて行くか、ということが重要である。
ここで見てみると、やたら中心に固まっている。実際のデータを見てみると、分類9のデータが多いことが原因のようである
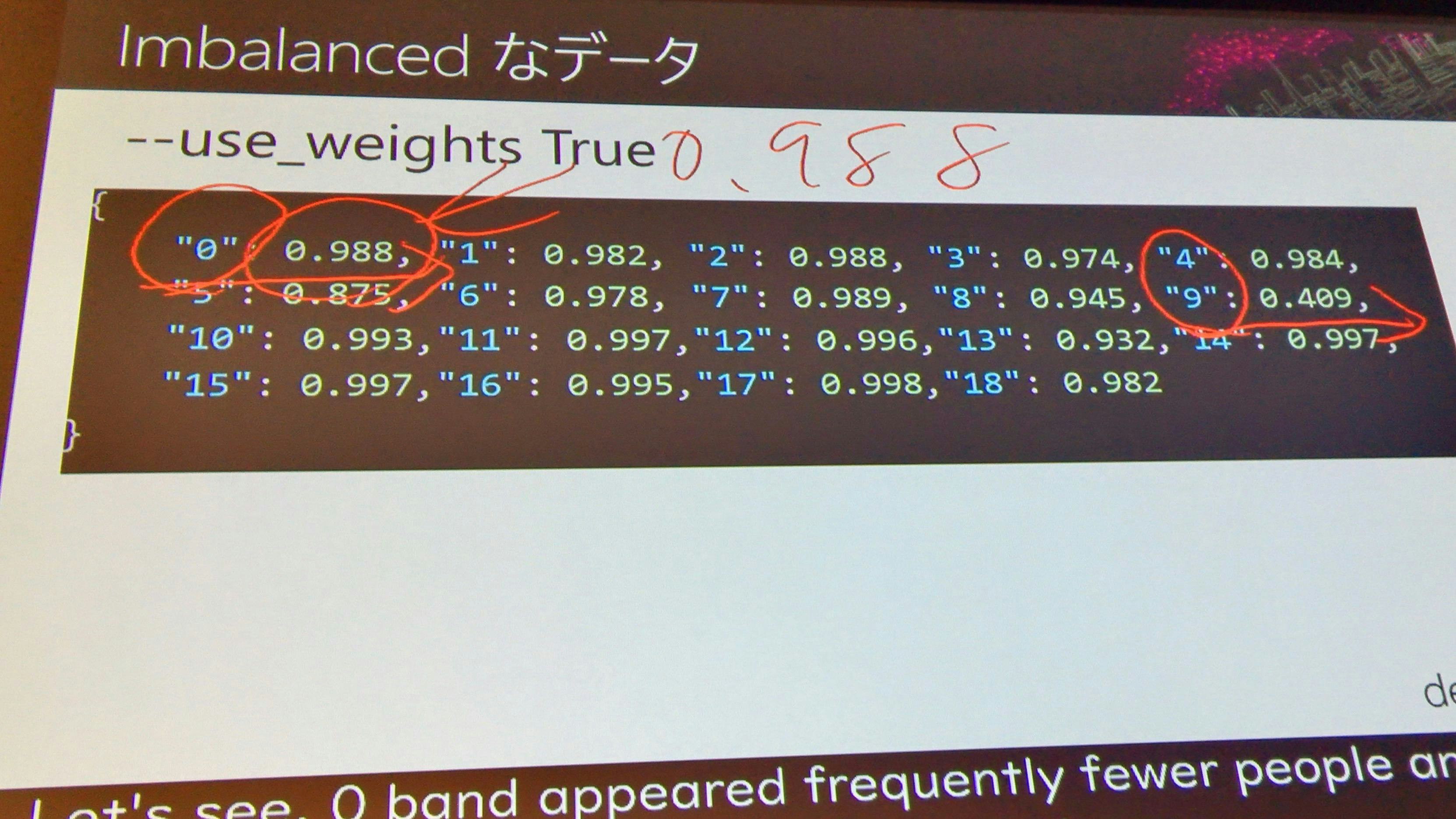
何度も出てくる分類9については影響力を減らすために、データに傾斜をかけてあげることでいい結果が得られるかもしれない
epoch数を増やす
さっきよりはましになったので、エポック数を上げてみる。1回目は5epoch 5epochだったが、20epoch 20epochにしてみた。
その結果、トレーニングは下がったが、未知なるデータに対する強さは上がった
しかし、実行時間が40分から2時間30分になったのは致命的な問題となる。どうにかして時間を減らさないと、試行数を増やすことができない。
複数GPUで分散処理
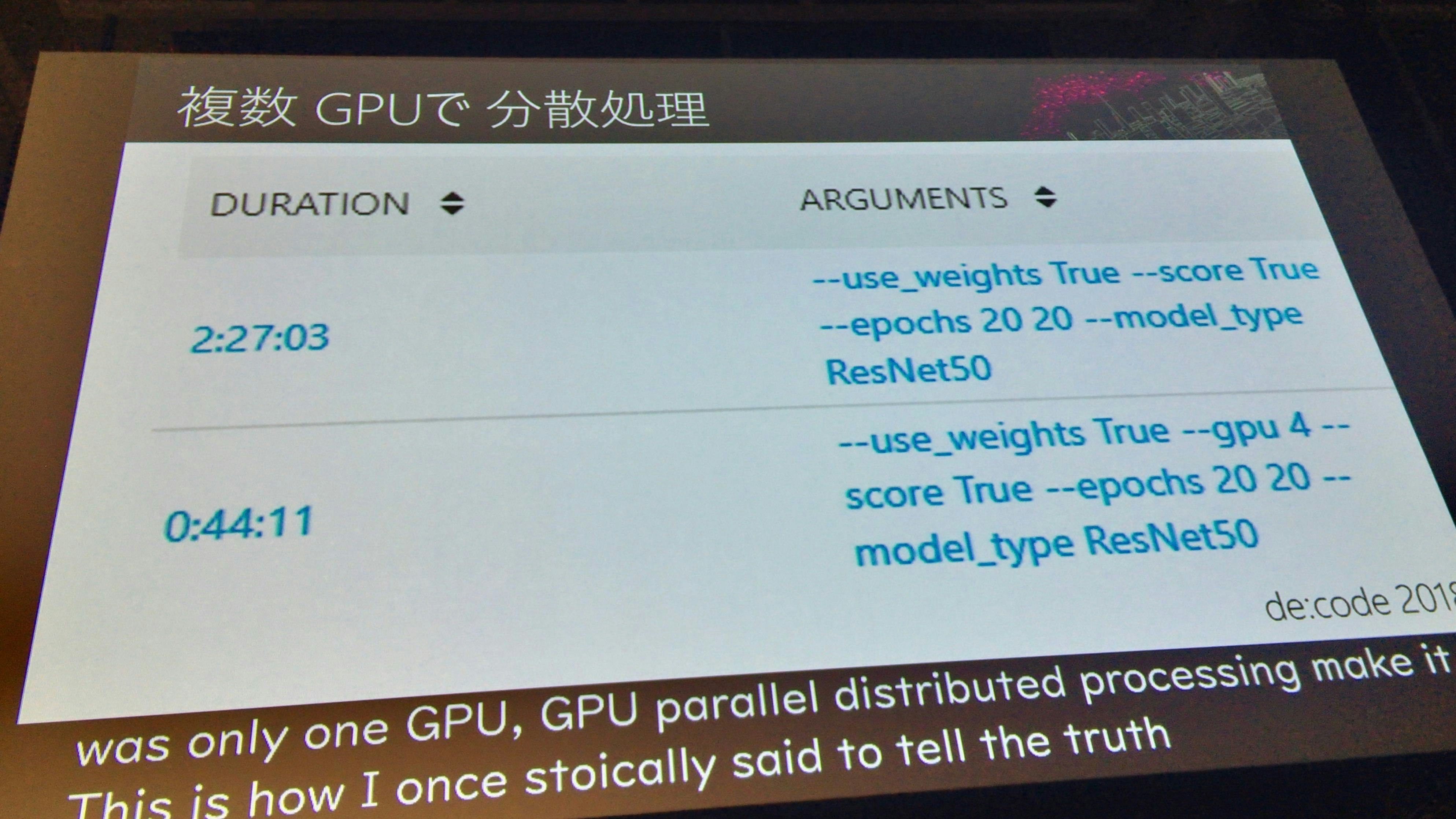
kerasは複数GPUでの処理は簡単なので、実装してみると、44分に落とせた。
GPUは正義
高性能なGPUは確かに値段が高いが、工数や工期などトータルで見るとコストはトントンではないか。やはりGPUを導入し早い方が良い
データの水増し
認識率を上げる方法として、データを移動したり、回転させた画像を生成して与える方法がある。この方法は有効なこともあるが、今回はあんまり結果が変わらなかった。
こういうのもやってみないとわからないので、1つの手としてやることは大事
上下動するだけで変わらない場合
グラフが上下動する場合には、学習率を変更する。学習率とは、Weightのパラメータを更新するか、である。
グラフが動きすぎる場合には学習率を落として行く方法が有効である。
Learning Rateの調整
かなり細かくパラメータを更新していった。accucrcyは落ちたが、validationが4%上がった。
Learning Rateについては、実際の結果を見ながら少しずつ調整していくことが大事である。
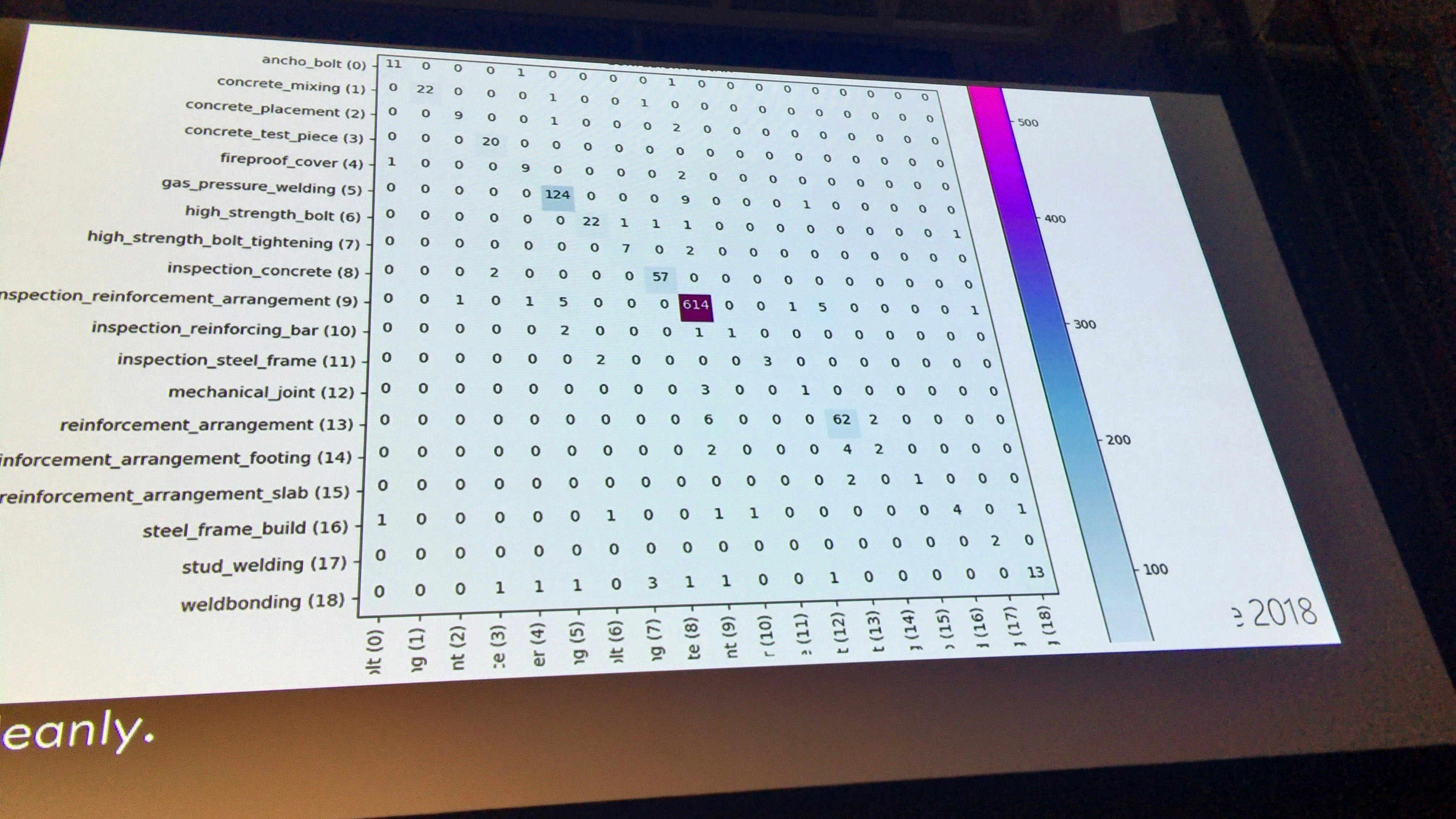
最終的に
acc 95、valacc 91まであがり、マトリクスもほぼきれいに左上から右下まで並ぶことになった。
まとめ

データが少なくても転移学習を利用し、とりあえず突っ込んでみよう。
バランスが悪いデータには調整する必要があるので、気をつけて
データを事例として発信していきたい
先端技術に挑みたい皆様へは Hackfestをやっているのでぜひお声がけしてください。

決めたら走れ!
AIで何とかできないかという相談はチャンスと捉えて、まずはやってみること!