de:code 2018に参加してきましたのでその結果をまとめています。
内容の間違い、誤字脱字等はご了承ください。正確なところは、本家のサイトを参照いただければと思います。
タイトル等
タイトル
de:code 2018 [AI14] Azure Machine Learning services で実現する Deep Learning によるテキスト分類
演者
得上 竜一さん 株式会社PLAN-B
日時
2018/05/23 11:00-11:50
概要、感じたこと
機械学習と言えば、画像判定ということがどうしても多くなっていますが、実際の業務でまずは導入しやすいのは、文字に対する機械学習ではないか、と思っていましたが、その考えを後押ししてくれるセッションでした。
また、実際に精度を高めるプロセスを行うためには、精度を測るということより、精度を測れる状態にするということが大事である、という考え方は胸落ちするものがありました。
実際にデータの精度を高めて行くプロセスも含めて、今日からでも実践できるので、どんどん試してみようと思います。
また、Azure Machine Learning StudioをMirosoft Azureを使用しないで、Tensorflowを使用する目的でも使えること。最終的に動作させるときに、Dockerコンテナではなく、Javaを使用して動かす、という考え方も参考になりました。
はじめに

このセッションを受けた人は、次の言葉を覚えて帰ってほしい!
Deep Learningって、画像だけじゃないんですよ。テキストデータならうちにもあるし、なんなら、私やり方も知ってますよ。
今回の例
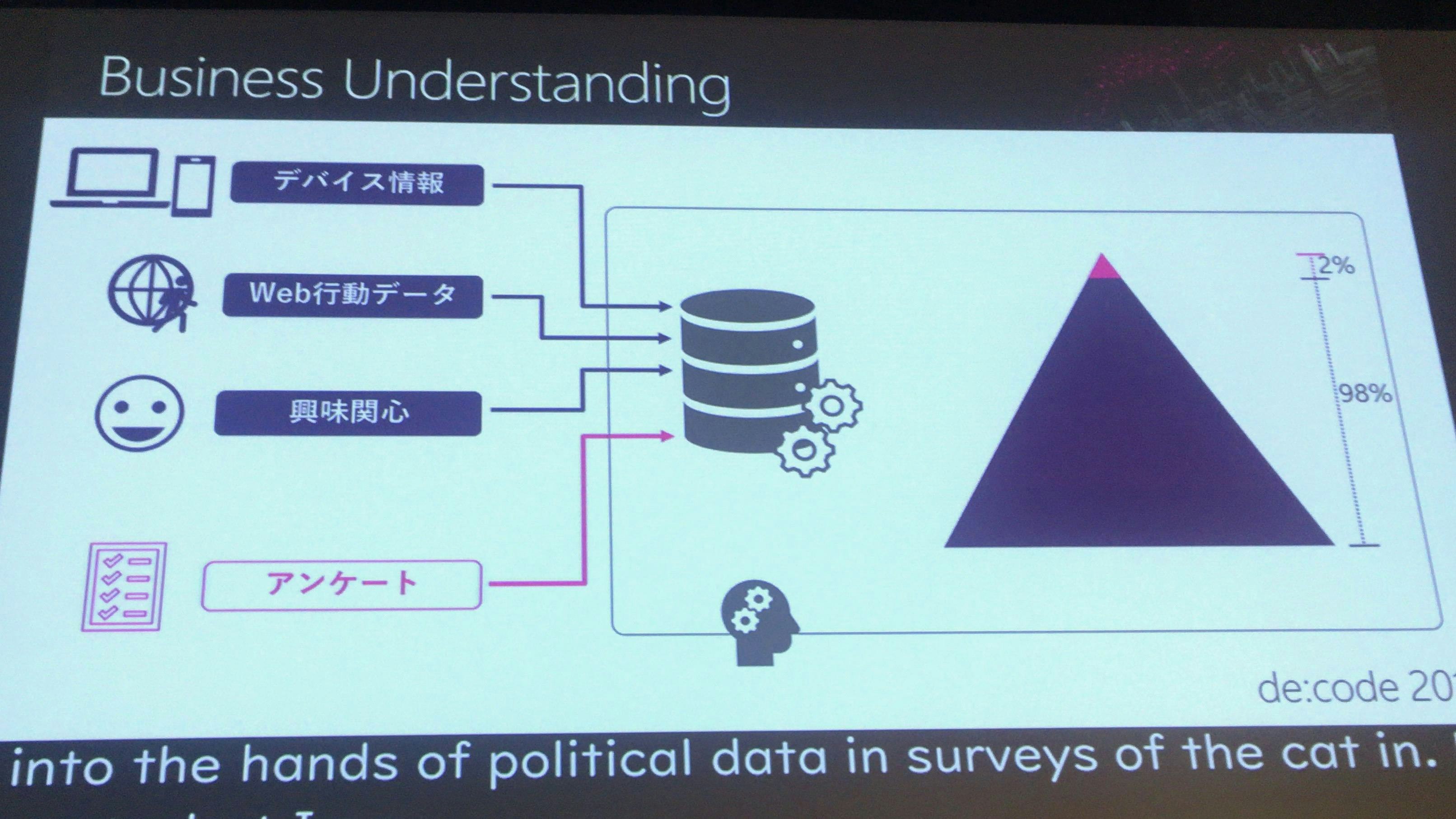
DMP=広告配信ビジネスについて、自動的に収集できるWeb行動情報だけではなく、アンケートも利用して広告配信ビジネスを行いたい。
もともと別件で機械学習を行っていたが、こういう案件が上がってきた。
推定されたデータと確実なデータ
98%のWeb行動情報など大抵はインターネット上から得られたデータとなるがこれは推定されたデータとなる(クッキー、ブラウザの個別情報)。
2%については、アンケートから得られたデータと繋がったデータとなっているので、これを確実なデータとしている。
Webの行動データとアンケートがつながった確実なデータが全体の2%しかない。そのため残り98%について、年齢と性別をどの様に推定するか、ということを行いたい。
今回の作成方法
Azure Machine Learning WorkBenchを利用し、IDをベースにして、どの年齢なら、どのアクセスをしているかというデータを作成していく。
Azure Machine Learning WorkBench
チームでデータサイエンスをどのように進めていけばよいかということを示したTDSP(Team Data Science Process)プロジェクトがWorkBench上で作成できるので、これを参考にすれば良い。

Azume Machine Learning StudioとAzure Machine Learning Servicesはイコールではない。
Azume Machine Learning WorkBenchは、ローカルで実行することもできるし、クラウド上でも動かすこともできる。Tensorflowの実行を行うこともできる。クラウド上の操作ツールとして使いやすいツール
データを見ながら、データの取り込み、加工処理(抽出も)を行うことができる。途中でヒストグラム、データソースのジョインを表示することもできる。
Modelingで行うこと
Modelingには、TensorFlowを利用する(Azure MLではない)。普通にサポートされている。

Modelingでは以下の手順を行なっていく。
- データをNewral Networkに入れやすい形に変換
- まずはSimpleなNewral Netowrkを作ってみる
- 精度を測る
- 層の追加やパラメータの調整
- (必要があれば)データの追加
- 3.4.5の繰り返し
まずは、精度を測るということより、精度を測れる状態にするということが大事である。つまり、実際にモデリングの精度を高めていくには、前述の3.4.5の繰り返しを行うための環境づくりが大事である。
Demo
- ノートブックを使っていく
- インストールには30分かかるが、30分後にはクラウド関係なく使用できる状態になる。Pythonのノートブックなどが使える
- CNTK、CNDKをバックエンドにすることもできる
- データを読み込む際には、Generate Data Access Codeで作成したコードを張り付けると、コードの作成を簡略化して、読み込むことができる
- 実際の判定方法としては、1文字ずつのコードにして数値化している。今回は100文字だけ読み込んでいる後はぶった切っている。
Deep LearningとはInputとOutputの間に層を挟んで楽しむ雅な遊び
Depp Learningは、InputとOutputとの間に層を挟んで変化を楽しむ雅な遊びであり、すごく楽しい作業である。
シンプルな、ネットワークから、複雑なネットワークにしていくのが、非常に楽しい。
実際の解析の手順
概要
今回使う方法としては、Character Level CNN(畳み込みが特徴的なニューラルネットワーク)。
ここで問題となるのが、テキストは1次元なのに2次元にできるのか?というところ。そこで、N-gramという方法を利用し、テキストを3文字ずつに分けて、3文字の数値にすることで画像と同じ扱いをできるようにする。
シンプルなNewral Network
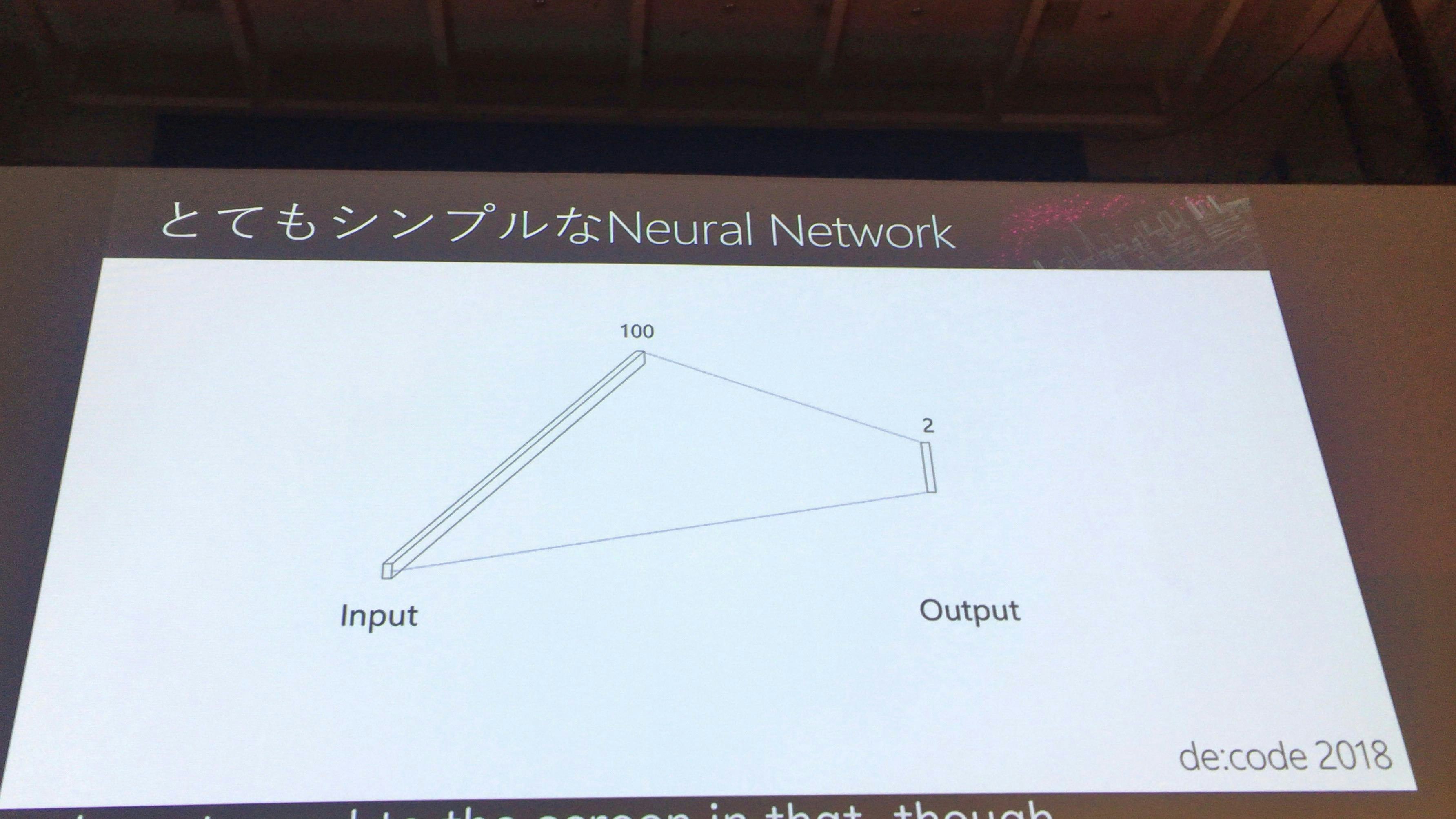
まずは、間の層がないシンプルなネットワーク。この時点では当然判定の精度もコイントスと変わらない!
3Gramで文字を分割

ピンクの文字の部分が、3Gramで分割するために追加したところ。この部分で、文字を3文字ずつに分割している。
ネットワーク図
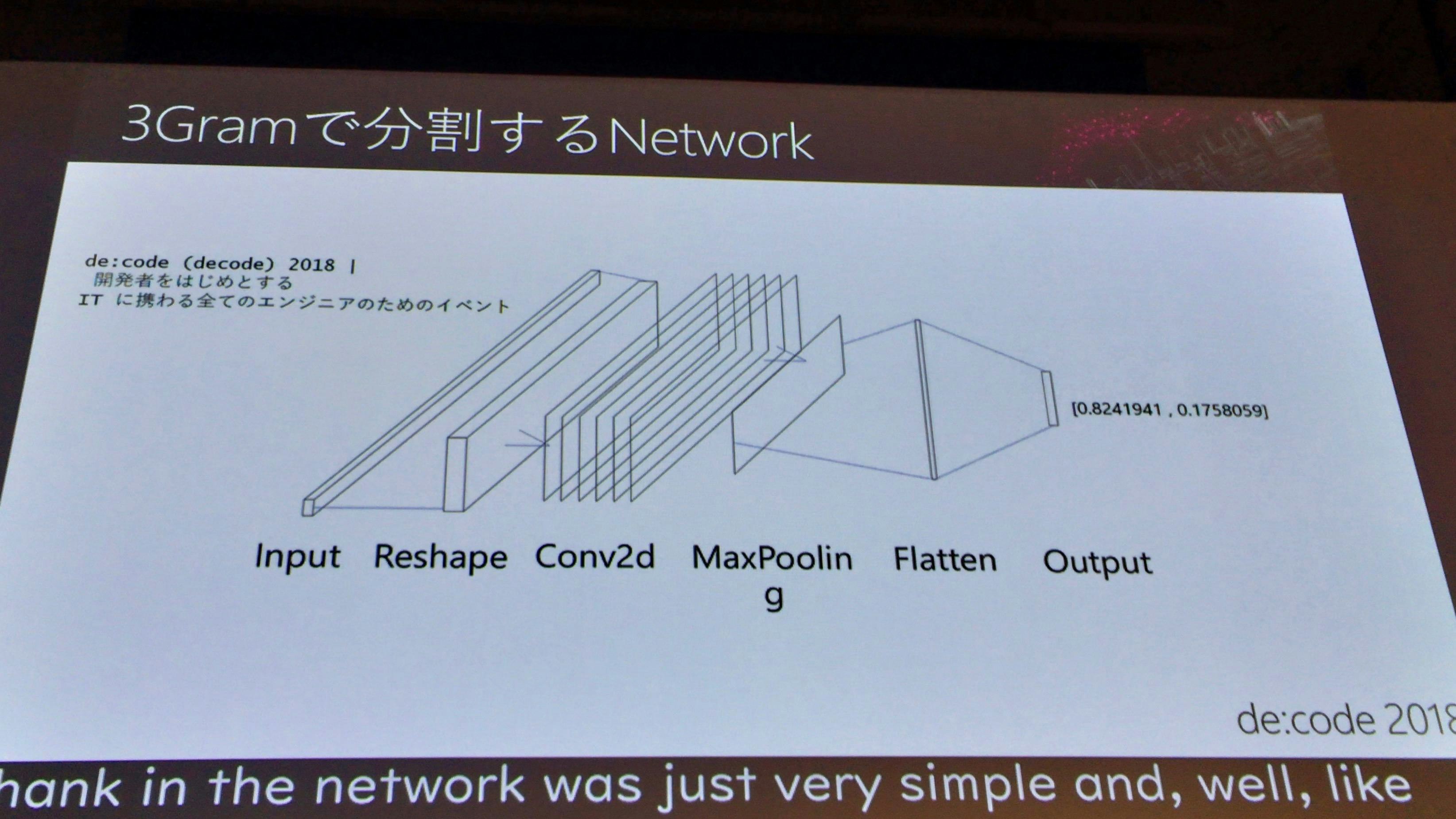
InputとOutputの間に、文字の2次元化などの層を挟んでいる
結果
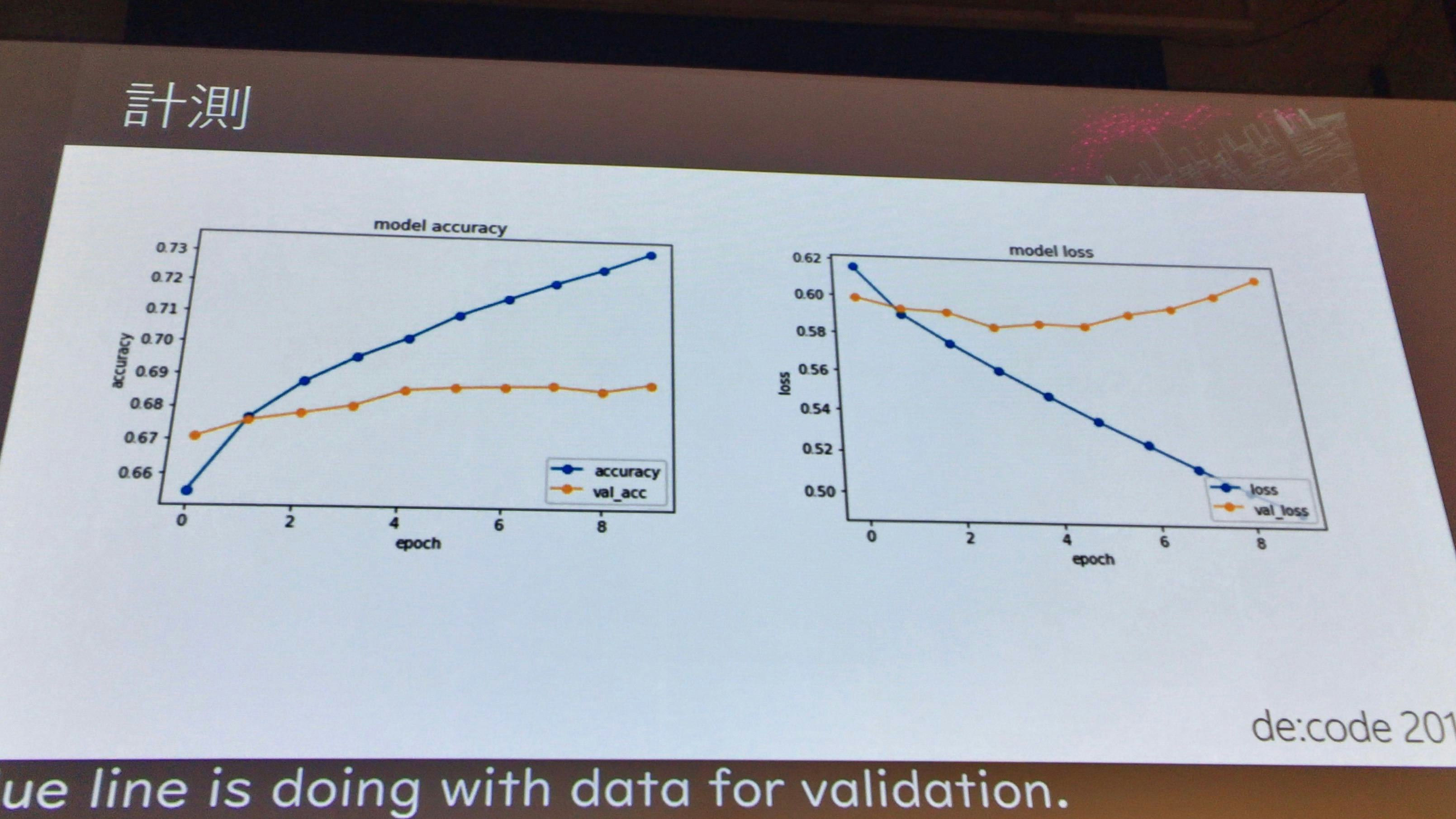
コイントスよりは良いが、まだよくはない。
-
accurcy(判定の精度)
精度は上がってきているが、まだ不十分。
-
loss(損失)
検証データでは問題なく損失が下がってきているが、テストデータでは、途中でグラフが上昇に転じている。これは過学習が発生している。つまり学習したデータについてのみOKな学習モデルとなっている
では、過学習となっているものについてどうすればいいか?の対策として、まずはDropoutを入れる。
Dropout

ピンクの部分で追加されたデータを入れると、一部のデータを捨てる(次の処理に渡さない)ということを行う。
せっかく入れたデータを捨てることになるが、ランダムに捨てることで過学習となったモデルが汎用化される層となる。
ネットワーク図

Dropoutを入れることで若干良くなったが、これでも足りないので、Batch Normalizationを行う。
Batch Normalization

Batch Normalizationは画期的な層であり、学習進行や過学習対策として効果的である。
(筆者補足)Batch Normalizatinは、2015年に提案された画期的な手法で、次の特徴があります。これらの効果により、ディープラーニングの学習にかかる時間や、パラメータ調整の難しさを軽減することができます。
- 学習を早く進行させることができる(学習係数をおきくすることができる)
- 初期値にそれほど依存しない(初期値に対して神経質でなくても良くなる)
- 過学習を抑制する(Dropoutなどの必要性を減らす)
ネットワーク図

結果
lossのテスト結果が右肩上がりはダメだが、右肩下がり、または並行になればいったんOKである。
Inputの近くにDropoutを追加
ネットワーク図

Input近くに1個、Outputの前に1個、真ん中に1個という形が大体の場合において理想的である。
結果
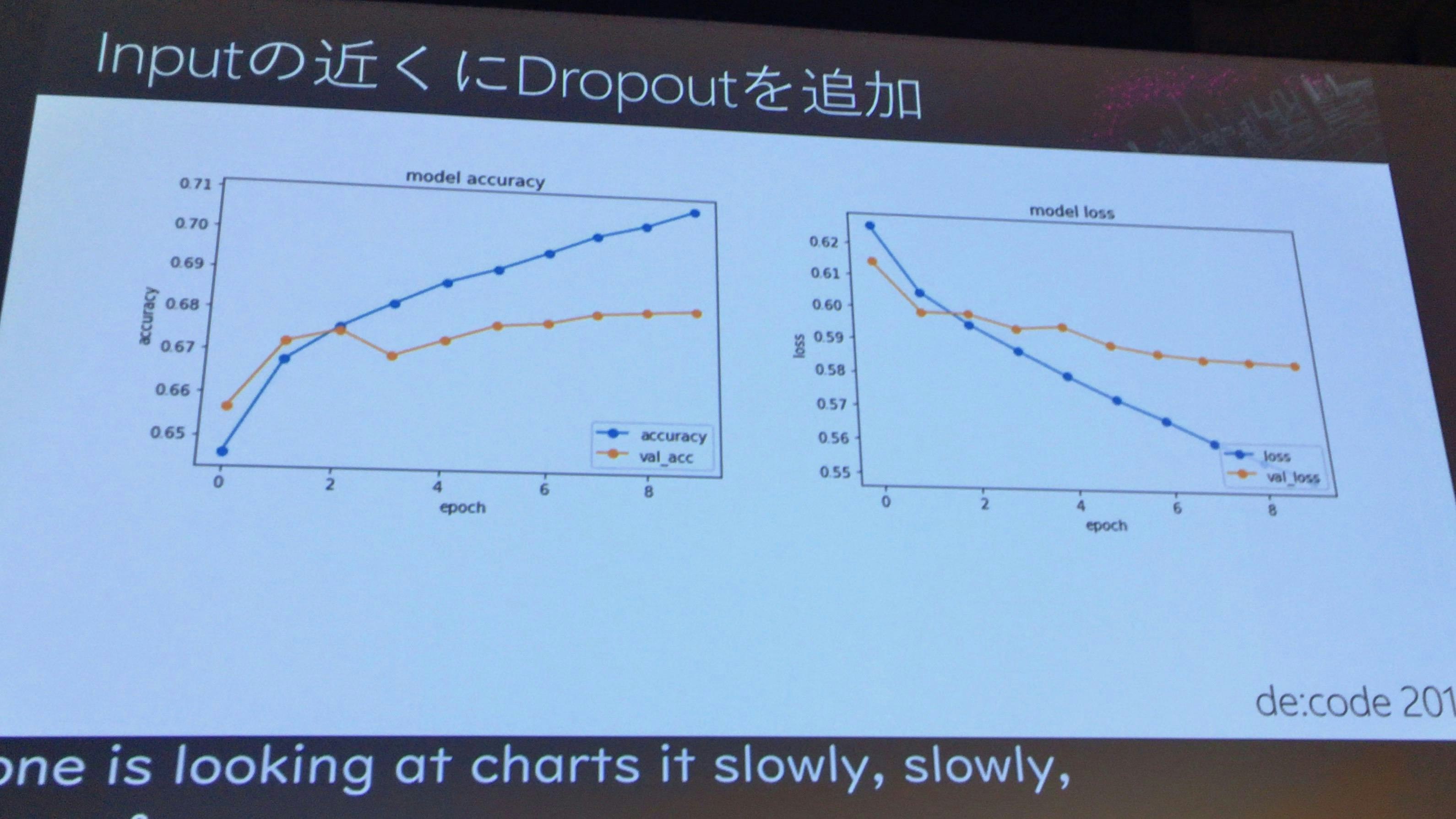
lossのほうが下がっていく傾向になると、使えるモデルとなる。データ量を増やすのはそれから行った方が良い。
つまり、ある程度妥当なモデルになるまでは、むやみに回数を増やさずに、少ない回数で試行し、いいモデルになってから回数(epoch_count)を増やすということをやったほうが効率的である。
補足
-
epoch_count
最初にやるときは、10,20,50を試すと良い。
-
early_stoppingを使えば、学習精度が悪い時には止まってくれる
-
Workbenchを使えば、ローカルでNotebookが使える
3Gram + 2Gram
使用するデータとして、3文字ずつ切り出したデータに加えて、2文字ずつ切り出したデータも元データとして利用し、結果を確認してみる。
ネットワーク図

結果
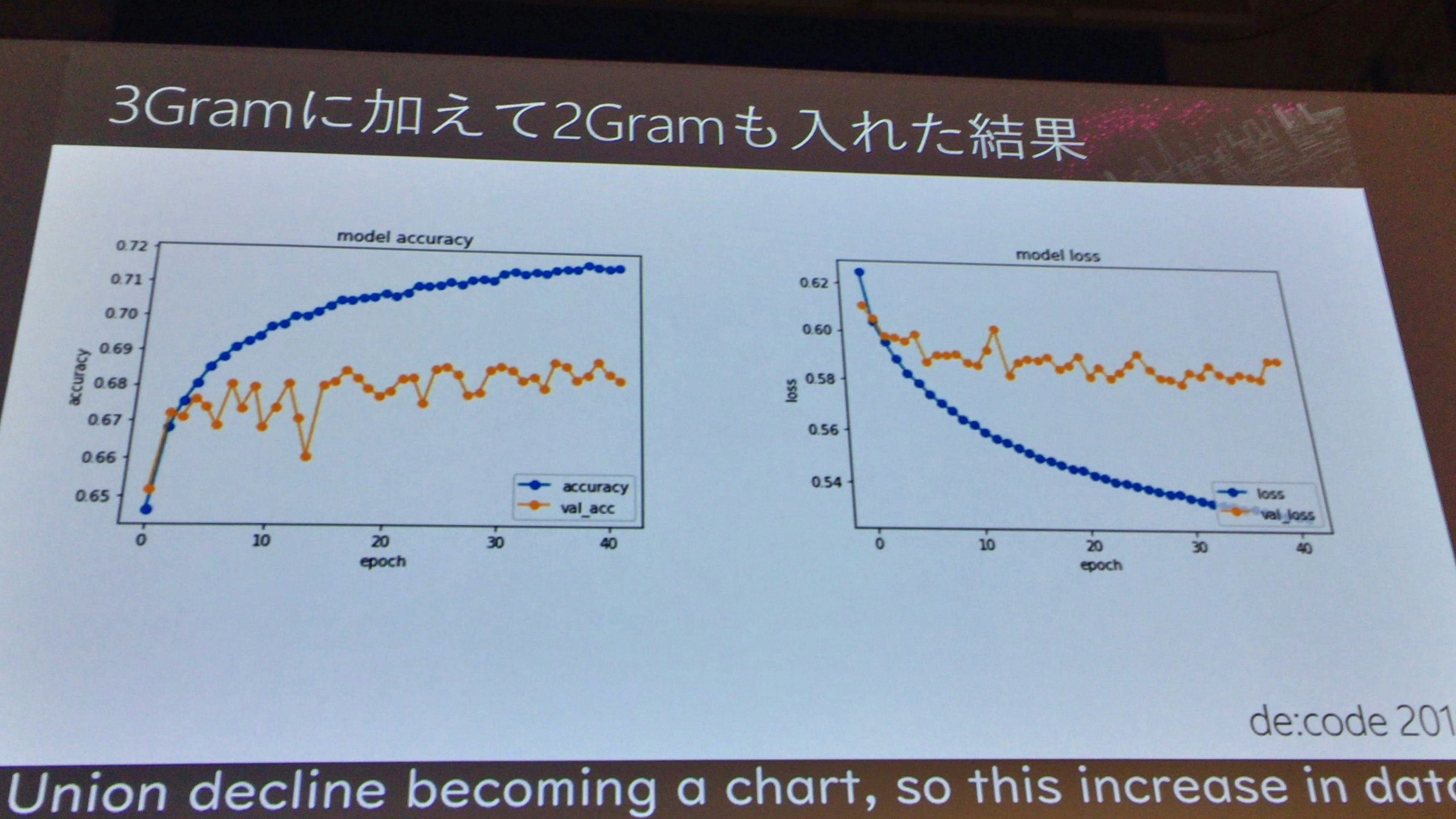
結果が上下動する結果なので、あまり良い状態ではない結果となった。
これが最適とは全く言えない
前項までの結果では、これが最適とは全く言えない、というようなことを繰り返していくのがチューニングである。
様々なパラメータを繰り返し、一番Accuracyがたかい設定を探っていく。
方法としては、回数、人数をかけるということになる。いろいろな手法(後述)が出ているが、これ、というような方法はまだ出ていない。
機械学習においては、AIだけではなく、周辺の技術や、数学的な考え方についても学んだ方が、考え方が広がる。
手法の紹介
GridSearch
とにかく全部のパラメータについて総当たりを行い、良いパラメータを探る方法
複数の組み合わせ
1個だけの精度ではなくて、別の精度算出方法を使用して、良い方法を比較する。いわゆるマギシステム。
マルコフチェーン
調和平均。2択の問題であれば揺らぎながらも妥当な結果となる。
Deployment(実際の実行)
Docker コンテナによるポータビリティ

学習モデルについて、Dockerコンテナによるポータビリティが行える。
しかし、演者としては推奨していない、とのことだった。理由としては、簡単なモデルでも2GBになってしまうので、別の方法があるならば、少々重すぎる方法ではないか、とのこと。
Java Run Anywhere

TensorflowはJavaでも使えるので、Paasに乗せてしまえばよい。
実際にやっている環境の話だが、4GB 2VCPUでOK。テキストであれば、GPUまで載せなくても、CPUでも十分である。Javaは最適化されるので1時間で200はさばけている。
考え方として、とにかくDockerコンテナという方法に走らず、TensorflowのBindingできるやり方(Java、JavaScript)を検討した方が良い。
最後に
協力
一人でやることもできるが、検証はアウトソースにでもやるでもよいが、モデリングはいろんな人で協力しよう。
宿題
帰ってから、早速やってみること。
Azure Machine Learning WorkBenchをインストールし、日報でもなんでもいいので、まずはテキストを探してやってみる。もし何もなければ、青空文庫、Wikipediaなどはいいデータである。
たとえば、日報からネガティブな報告なのか、ポジティブな報告などを2択で判定してみるのも良いし、問い合わせについて、これはクレームなのか、そうではないのかを判定してみるのも良い。
判定に使用する機器としては、タブレットでできるレベルである。文字は画像に比べて軽いので、まずはやってみること!
参考情報

お願い
帰ったら、次の言葉を組織の人に言いましょう。
