TL;DR
- ドキュメントのチュートリアルに記載がない、「ML.NET Model Builder を使った転移学習での画像分類」の手順を記載します。
- ML.NET Model Builder1を利用した、コーディングなしの機械学習モデルの作成を体験できます。
(1) ML.NETとは
(1-1) コードファースト
ML.NETとは、.NET開発者向けの機械学習フレームワークです。
コードファーストということは、コーディングできることが前提です。
利点として、.NET のコードから使用できるので、自分の.NETアプリケーションに組み込むことが容易です。
すべてを.NETで完結できる、ということは、今までの言語知識を活用でき、さまざまな言語を覚える必要がないため、学習コストを抑えることができます。
(1-2) オープンソース
フリー、クロスプラットフォーム、オープンソースです。
Microsoftが提供していますが、Windowsだけで動作する、ということはありません。Mac、Linux、Windowsで動作します。
(1-3) 言語、対象フレームワーク
- C#, VB.NET などの既存の言語スキルを活用できる
(2023年6月27日追記)公式にissueが上がっているが、ML.NET Model BuilderはVB.NETには現時点で対応していない。ML.NET Model Builderを利用する場合は、C#で構築したほうが良いと思われる。
作成したC#ライブラリを呼び出すことは可能かもしれないが、未検証。
https://github.com/dotnet/machinelearning/issues/3679
https://github.com/dotnet/machinelearning-modelbuilder/issues/34
- .NET Core 2.1以降、.NET Framework 4.6.1以降(4.7.2以降推奨)で動作します
(1-4) 豊富なドキュメント、チュートリアル
様々な状況を想定したチュートリアルも豊富な**日本語!**のドキュメントが用意されているため、学習、利用が容易です。
ML.NETの使用方法だけではなく、アルゴリズムの選択と用意すべきトレーニングデータに関する解説など、機械学習の基本から実践的な解説まで網羅されています。
(1-5) AutoML、ML.NET Model Builder、ML.NET CLI
AutoML(Automated Machine Lerging)
自動で最適な学習アルゴリズムと、ハイパーパラメータを検索することで、機械学習モデルの作成を自動化することができます。
通常、ML.NETを単独で使用し、特徴エンジニアリング、学習アルゴリズム、およびハイパーパラメーターの最適な組み合わせを見つけようとすると、機械学習モデルの最適化に数週間から数か月かかる可能性があります。
AutoMLを使うことで、"民主化"、つまり機械学習の利用をより実務で活かして行くことが簡単になります。
ML.NET Model Builder
AutoMLをGUI(ウイザード形式)から使用できるVisual Studioから利用するツールです。
トレーニングデータセットに基づき、機械学習モデルとソースコードを作成できます。
ML.NET CLI
AutoMLをCLI(コマンドラインインタフェース)から使用できるツールです。クロスプラットフォーム(Windows、Mac、または Linux)です。
トレーニングデータセットに基づき、機械学習モデルとソースコードを作成できます。
(1-6) ONNXが使用できる
AI モデルのオープン ソース形式であるOpen Neural Network Exchange(ONNX)を使用できます。
つまり、PyTorch、Tensorflowなどの多くの一般的な機械学習フレームワークのいずれかでモデルをトレーニングして ONNX 形式に変換し、ML.NET で学習モデルを使用することができます。
(1-7) 他の機械学習モデル開発環境との比較
他の機械学習のサービス、開発環境と比較した場合、ML.NETはコーディングする部分が多いです(コードファースト)。
しかし、ML.NET Model Builderを使用すれば、機械学習部分のコーディング部分はだいぶ減らすことができます。
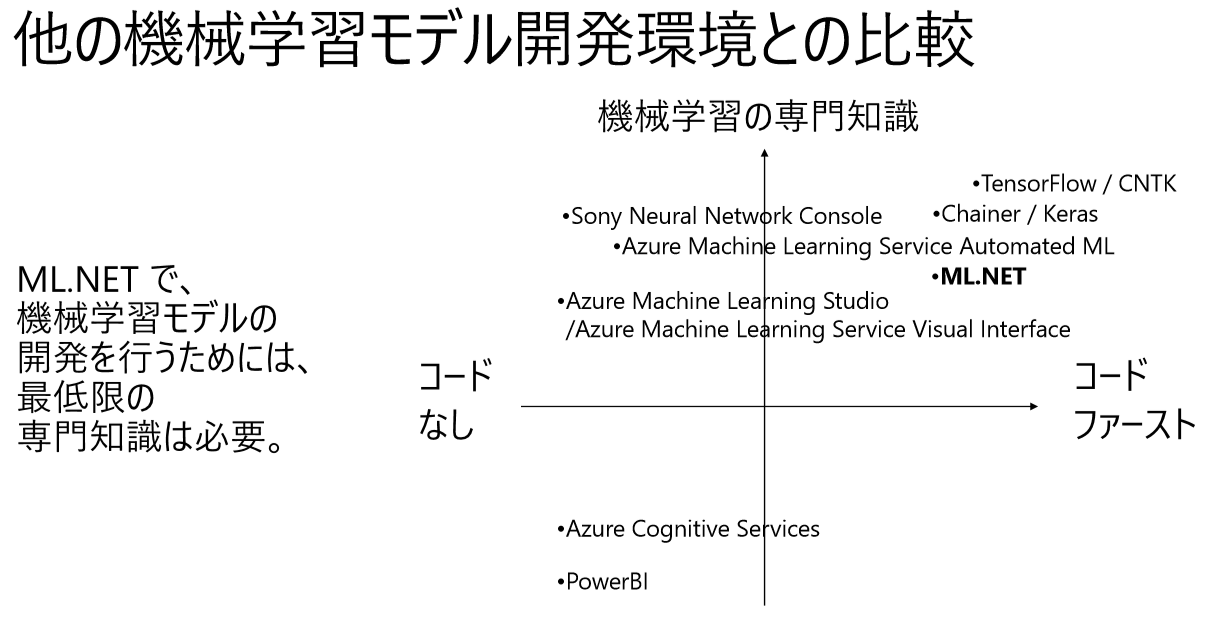
引用元:AI83 .NET 開発者のための機械学習フレームワーク ML.NET 入門(資料)
(2) ML.NET Model Builder のインストール
手順に従いインストールします。
参考:https://docs.microsoft.com/ja-jp/dotnet/machine-learning/how-to-guides/install-model-builder
Visual Studio 2019での手順を以下に示します。
-
Visual Studio 2019を起動し、拡張機能-拡張機能の管理をクリック
-
"ML.NET モデル ビルダー"で検索し、以下のダウンロードをクリック

Visual Studioを一度閉じて再起動後に、適用する必要があります。
(3) 「ML.NET Model Builder を使った転移学習での画像分類」の手順
概要
今回は、ML.NET Model Builderを利用し、AutoML を利用した転移学習で機械学習モデルを作成し、画像分類のテストを行います。また、最終的にソースコードを作成します。
転移学習とは、事前トレーニング済みモデルを利用し、一部のパラメータを変更しながら学習モデルを作成することで、トレーニングの時間を大幅に削減し、学習結果の向上を図ることができる手法です。2
環境
- Windows 10 Pro 1903
- Visual Studio 2019 16.3.9
- プロセッサ: Intel Core i7-7700 3.60 GHz
- メモリ: 16.0 GB
- 記憶域: SSD
(3-1) 画像データセットのダウンロード
サンプルとして次のデータセットをダウンロードします。
-
ひび割れあり/ひび割れなしのコンクリート構造物に関するデータセット
このデータは、SDNET2018として公開されている、ひび割れあり/ひび割れなしのコンクリート構造物 (橋床、壁、歩道) に関する注釈を含む画像データセットの抜粋(橋床のみ)です。
ML.NETのチュートリアル内で紹介されています。
フォルダ構成と内容
| フォルダ | 内容 |
|---|---|
| CD | ひび割れている |
| UD | ひび割れていない |
(3-2) 機械学習モデルとプロジェクトの作成手順
ML.NET Model Builderを利用すると、コーディングすることなく、画像分類の機械学習モデルとプロジェクトを作成できます。
(事前のデータ準備は必要です。)
-
任意の名称(例では"DeepLearning_ImageClassification_Binary"としています)の C# .NET Core コンソール アプリケーションを作成します。
-
プロジェクトに[assets]フォルダを作成し、ダウンロードしたデータを配置します。
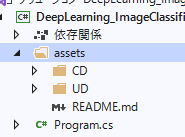
-
プロジェクトに[test]、[test] > [CD]、[test] > [UD]フォルダを作成し、[assets]フォルダの[UD]、[CD]フォルダの中から、手作業で任意の5枚程度を 移動 します。(テスト用画像とするため、移動する必要があります)
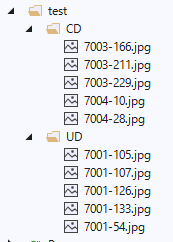
この操作で、トレーニング・検証用画像390枚、テスト用画像10枚としています。
-
プロジェクトを右クリックし、[追加] > [Machine Lerning]の順に選択します。
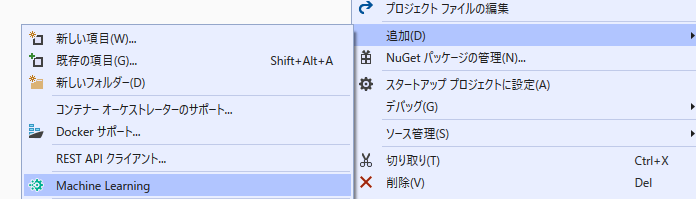
-
[1. Scienario]で、今回は画像分類を行いますので、[Image Classification]を選択します。
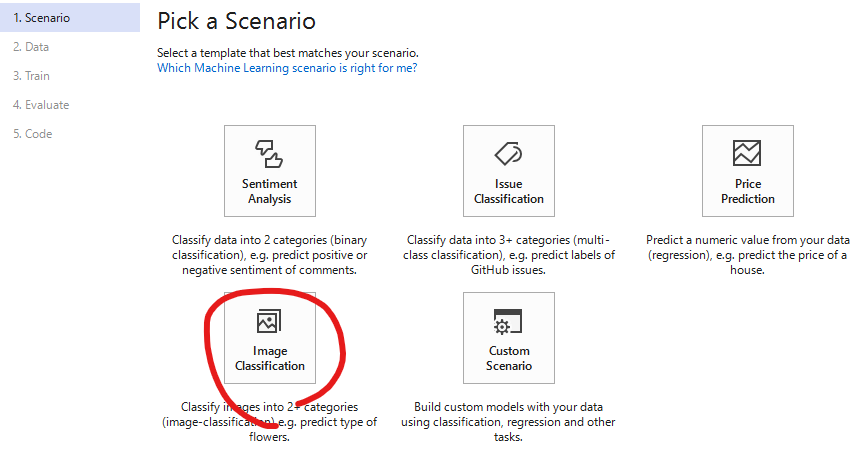
-
[2. Data]で、先ほどプロジェクトに追加した[assets]フォルダを選択します。(注意点として、パスを入力してもData Previewが表示されないため、GUIで選択する必要があります。)
選択するフォルダ内で、分類した画像ごとにフォルダ分けしておく必要があります。フォルダ名=ラベルとなります。ここでは、CD 195枚、UD 195枚の合計390枚をトレーニング画像として選択しました。
-
[Data Preview]に、選択したフォルダのプレビューが表示されます。

-
[3. Train]で、[Start training]を実行します。
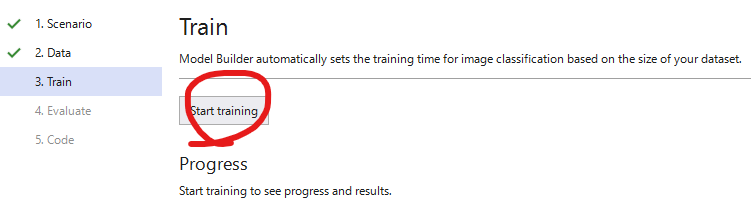
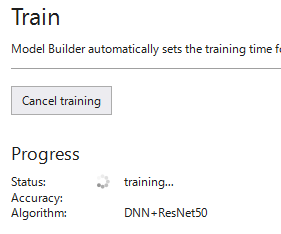
AutoML が動作し、適切なアルゴリズムが選択されます。今回は、"DNN+ResNet50"が選択されました。
-
トレーニング完了するとトレーニング結果が表示されます。
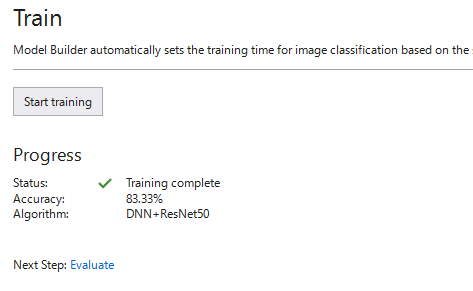
私の環境では15分程度で完了しました。
-
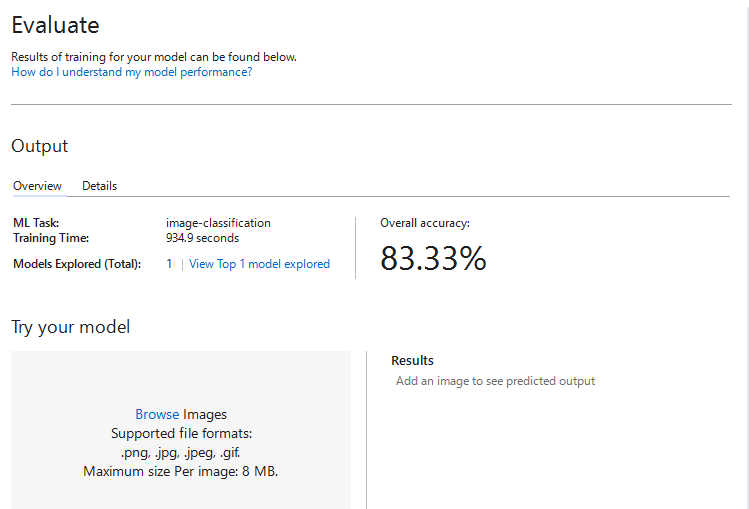
[4. Evaluate]で、トレーニング結果の確認とモデルのテストを行うことができます。
-
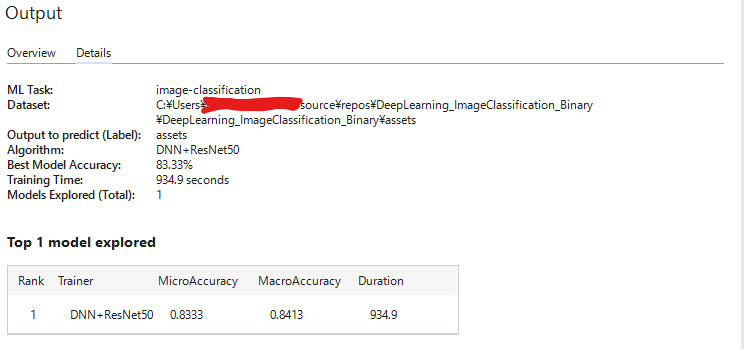
[View Top 1 model explored] をクリックすると、一番良かったモデルの詳細を確認できます。
-
[Try Your Model] > [Browse] で任意の画像でモデルをテストできます。
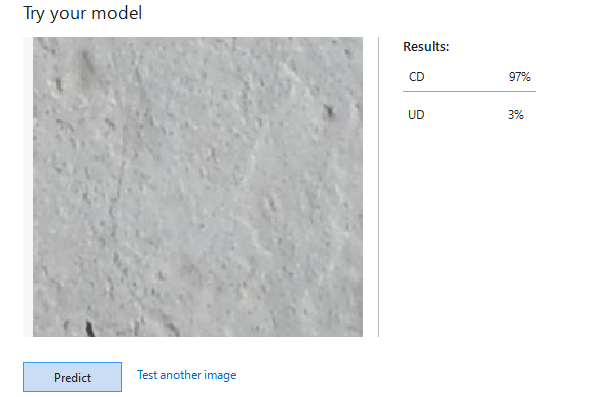
なれていない人には判断に迷う画像も、ひび割れ(CD)と認識できていることが確認できます。
-
[5. Code]で、[Add Projects]をクリックします。

-
ソリューションに、以下の変更が自動的に行われます。
- [Machine Learning]を追加したプロジェクトへの参照の追加(今回の例では、"DeepLearning_ImageClassification_Binary")
- テスト用プロジェクトの追加(~.ConsoleApp)
- 機械学習モデルのプロジェクトの追加(~.Model)
(3-3) テスト画像での検証結果まとめ
選定したテスト用画像10枚のうち、次の1枚はCD(ひび割れている)をUD(ひび割れていない)と、誤認しましたが、10枚中9枚は、正しく認識できました。
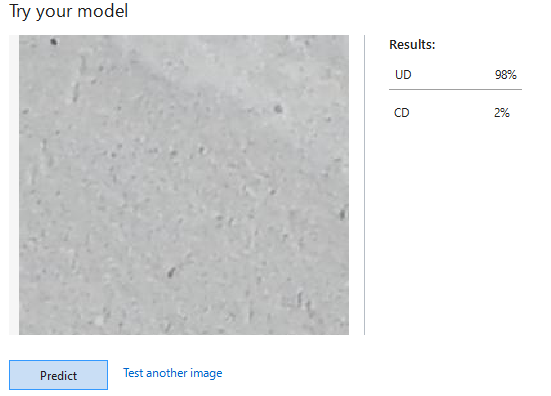
| 画像 | 想定 | 判定 | CD(ひび割れている) | UD(ひび割れていない) |
|---|---|---|---|---|
| 7003-166.jpg | CD | × | 2% | 98% |
| 7003-211.jpg | CD | ○ | 58% | 42% |
| 7003-229.jpg | CD | ○ | 97% | 3% |
| 7004-10.jpg | CD | ○ | 100% | <1% |
| 7004-28.jpg | CD | ○ | 100% | <1% |
| 7001-54.jpg | UD | ○ | 100% | <1% |
| 7001-105.jpg | UD | ○ | 96% | 4% |
| 7001-107.jpg | UD | ○ | 78% | 22% |
| 7001-126.jpg | UD | ○ | 100% | <1% |
| 7001-133.jpg | UD | ○ | 100% | <1% |
(3-4) 作成されたコード(プロジェクト)の利用
テスト用プロジェクト(~.ConsoleApp)を利用し、モデルを試す
-
以下のように、検証したいファイルのフルパスを記載したTSVファイル(UTF-8)を用意します
C:\Users\User\source\repos\DeepLearning_ImageClassification_Binary\DeepLearning_ImageClassification_Binary\test\CD\7003-211.jpg -
テスト用プロジェクト(~.ConsoleApp)の定数
DATA_FILEPATHを、前項のTSVファイルのパスに書き換えます。Program.csprivate const string DATA_FILEPATH = @"~.tsv"; -
テスト用プロジェクト(~.ConsoleApp)を実行するとコンソールに結果が表示されます。
2019-12-05 13:06:54.292859: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 Expected image (JPEG, PNG, or GIF), got empty file [[{{node DecodeJpeg}}]] Using model to make single prediction -- Comparing actual Label with predicted Label from sample data... ImageSource: Actual Label: C:\Users\User\source\repos\DeepLearning_ImageClassification_Binary\DeepLearning_ImageClassification_Binary\test\CD\7003-211.jpg Predicted Label value CD Predicted Label scores: [0,0] =============== End of process, hit any key to finish ===============
自分のプロジェクトからモデルを使ってみる
-
[Machine Learning]を追加したプロジェクトのProgram.csを書き換えます。
Program.csusing System; using DeepLearning_ImageClassification_BinaryML.Model; namespace DeepLearning_ImageClassification_Binary { class Program { static void Main(string[] args) { // Add input data var input = new ModelInput(); input.ImageSource = @"C:\Users\User\source\repos\DeepLearning_ImageClassification_Binary\DeepLearning_ImageClassification_Binary\test\CD\7003-211.jpg"; // Load model and predict output of sample data ModelOutput result = ConsumeModel.Predict(input); Console.WriteLine(result.Prediction.ToString()); } } } -
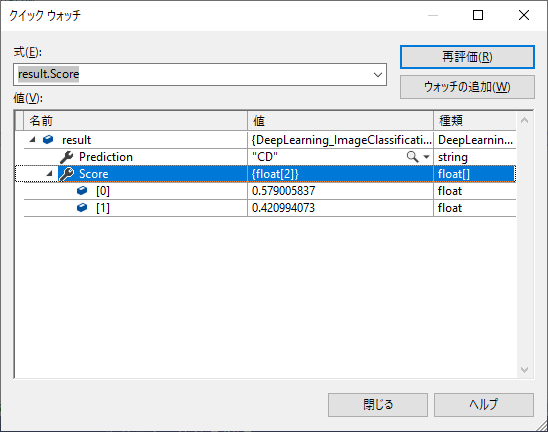
Console.WriteLine行でブレークし、result変数の内容をクイックウォッチで確認できます。予測結果と、各ラベルのスコアが確認できます。
モデルを利用したコーディングの詳細
複数画像でのコード例など、参考になるコードは以下から参照できます。
(4) 作成したモデルの改善
参考:https://github.com/dotnet/machinelearning-samples/blob/master/modelbuilder/readme.md#improve
(4-1) データの量、品質
データの量
高品質の機械学習モデルトレーニングするには、データの量またはデータの品質が十分でない場合があります。SDNET2018のフルデータセットを利用して、学習に使用する画像を増やす、という方法が考えられます。
※上記「SDNET2018のフルデータセット」のリンクは、Edgeではダウンロードできないことがありました。その場合は他のブラウザ(Chromeなど)をご利用ください。
データの品質
ただし、使用する画像が多ければよいというわけではありません。
以下のようなことを考えて、データの選別を行うことも大事です。
- 各データセット数(例の数)が不均等にならないようにすること
- 不要なデータの除外(テストデータに関係ないものが写っていたり(今回であればコンクリート面以外の地面など)した場合に除いてみる)
データ拡張(水増し、Data Augmentation)
機械学習で一般的な処理となりますが、データを前処理することで、モデルの品質が改善することも考えられます。前項とも絡みますが、やみくもに行うのではなく、本番データを意識した処理を行うことが大事です。
- ノイズを増やす(ガウシアンノイズやインパルスノイズ)
- コントラストを調整
- 明るさを調整(ガンマ変換)
- 平滑化(平均化フィルタ)
- 拡大縮小
- 反転(左右/上下)
- 回転
- シフト(水平/垂直)
- 部分マスク(CutoutやRandom Erasing)
- トリミング(Random Crop)
- 変形
- 変色
- 背景を差し替える(これはライブラリの機能ではなく別途作業)
引用元:水増しと転移学習 (Vol.7)
ML.NETにもありますが、今のところグレイスケールとリサイズ程度です。
よって、OpenCVSharpなどを使用して前処理する必要がありますね。
(4-2) トレーニングの時間
※Model BuilderのImage Classificationでは自動調整され変更できない
トレーニング(学習)の時間を増やすことで、より多くのモデルが試され、機械学習のシナリオに適したモデルを見つけることができます。
(4-3) ハイパーパラメータを変更する
※Model BuilderのImage Classificationでは自動調整され変更できない
- パラーメーターを変更すると、学習モデルの判別性能が上がることがあります。
- 各エポック後のモデル更新の規模を決定する学習率を変更すると、学習モデルの判別性能が上がることがあります。
(4-4) 別のモデルアーキテクチャを使用する
※Model BuilderのImage Classificationでは自動調整され変更できない
画像によっては、その特徴を最も効果的に学習できるモデルが異なることがあります。 学習モデルの判別に不満が残る場合、アーキテクチャの変更すると改善することがあります。