作ったもの
YouTubeLiveの生放送から盛り上がった箇所を自動抽出するCLI
PyPlに公開してます。
$ pip install pylive_jp
$ pylive
動画URL=>https://www.youtube.com/watch?v=
ハイライト抽出数(何箇所抽出するか?)=>3
処理中:
2020/1/6 追記
現在PyPlには公開していません、外部パッケージ依存のエラーが頻発して保守が大変なので一部機能を見直してwebサービスとしてリリースしました。是非利用してみてください。
※動画DL処理を消去したので動画DLはできません
リンク→https://www.highlight-ranking.com/
Qiitaの記事としてもまとめました。気になる方はご覧ください
YouTubeLiveの生放送から盛り上がった箇所を自動抽出するwebサービス作りました。是非使ってみてください。https://t.co/fYxddc2jOV
— tf (@tf0101_tw) January 6, 2020
開発期間
半月くらい
開発人数
一人
なぜ作ったのか
生放送は再生時間が長く全て見るのに時間がかかる、そこで盛り上がった箇所だけ自動で抽出できたら便利だと思ったので作成
また、事前に使えそうなパッケージなどを探していたらいい感じのが見つかったのも開発に踏み切った要因の一つ
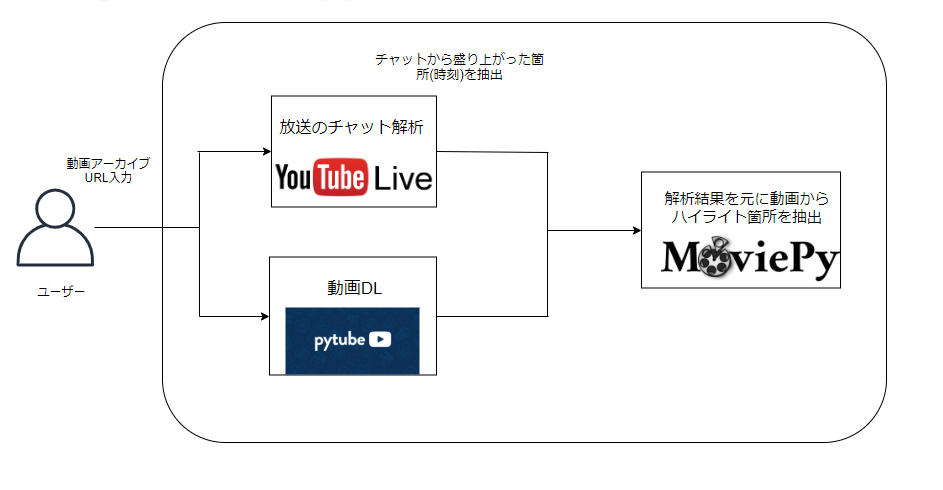
処理内容
大きく分けて、動画DL、チャットの解析、動画切り出し、という3つの処理を行っている。また、動画のDLとチャットの解析は互いに独立した処理なので並列処理で実装した。
以下に概要図を示す。
チャット解析
YouTube Liveのチャットを解析することで盛り上がり箇所を抽出している。
※チャットデータの取得方法の解説ですが、仕様変更の度に更新が必要となるのでこちらで有料記事としてまとめることにしました。
以降、最新版はこちらの記事で公開していきます。
チャットデータの取得
YouTube Liveの生放送からのチャットデータの取得方法はこちらのサイトが詳しく解説しているので参考にさせていただきました。詳しい解説などはこちらのサイトをご覧下さいhttp://watagassy.hatenablog.com/entry/2018/10/06/002628
やっていることはBeautiful SoupでのHTMLの解析、1チャットにはあらゆるデータが含まれているのでこの中からチャット文と投稿時間を取得する
# チャット文
# ※チャット文の場所が変更されたのを確認 2019/6/27
samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["message"]["simpleText"]
↓
samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["message"]["runs"][0]["text"]
# チャット投稿時間(ミリ秒)
samp["replayChatItemAction"]["videoOffsetTimeMsec"]
1チャットから取得できるデータ一覧
samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["message"]["runs"][0]["text"]
samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["authorName"]["simpleText"]
samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["authorPhoto"]["thumbnails"][0]["url"]
samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["authorPhoto"]["thumbnails"][0]["width"]
samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["authorPhoto"]["thumbnails"][0]["height"]
samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["authorPhoto"]["thumbnails"][1]["url"]
samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["authorPhoto"]["thumbnails"][1]["width"]
samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["authorPhoto"]["thumbnails"][1]["height"]
samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["contextMenuEndpoint"]["clickTrackingParams"]
samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["contextMenuEndpoint"]["commandMetadata"]["webCommandMetadata"]["ignoreNavigation"]
samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["contextMenuEndpoint"]["liveChatItemContextMenuEndpoint"]["params"]
samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["id"]
samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["timestampUsec"]
samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["authorExternalChannelId"]
samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["contextMenuAccessibility"]["accessibilityData"]["label"]
samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["timestampText"]["simpleText"]
samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["clientId"]
samp["replayChatItemAction"]["videoOffsetTimeMsec"]
チャット取得コード(長いので一部省略)
from bs4 import BeautifulSoup
import requests
import datetime
import lxml
def analysis(target_url):
session = requests.Session()
#ユーザーエージェント情報(ブラウザとかの情報)
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36 '}
# まず動画ページにrequestsを実行しhtmlソースを手に入れてlive_chat_replayの先頭のurlを入手
html = requests.get(target_url)
soup = BeautifulSoup(html.text, "html.parser") #html解析
for iframe in soup.find_all("iframe"):
if("live_chat_replay" in iframe["src"]):
next_url= iframe["src"]
(・・・略)
while(1):
try:
html = session.get(next_url, headers=headers)
soup = BeautifulSoup(html.text,"lxml")#パーサーは処理を高速化するためにlxmlを選択
# 次に飛ぶurlのデータがある部分をfind_allで探してsplitで整形
for scrp in soup.find_all("script"):
if "window[\"ytInitialData\"]" in scrp.text:
# window["ytInitialData"] = {チャットデータ一覧} を分割
dict_str = scrp.text.split(" = ",1)[1]
# javascript表記なので更に整形. falseとtrueの表記を直す
dict_str = dict_str.replace("false","False")
dict_str = dict_str.replace("true","True")
# 辞書形式と認識すると簡単にデータを取得できるが, 末尾に邪魔なのがあるので消しておく(「空白2つ + \n + ;」を消す)
dict_str = dict_str.rstrip(" \n;")
# 辞書形式に変換
dics = eval(dict_str)
# "https://www.youtube.com/live_chat_replay?continuation=" + continue_url が次のlive_chat_replayのurl
continue_url = dics["continuationContents"]["liveChatContinuation"]["continuations"][0]["liveChatReplayContinuationData"]["continuation"]
next_url = "https://www.youtube.com/live_chat_replay?continuation=" + continue_url
# dics["continuationContents"]["liveChatContinuation"]["actions"]がコメントデータのリスト。先頭はノイズデータなので[1:]で保存
#コメント情報を取得
for samp in dics["continuationContents"]["liveChatContinuation"]["actions"][1:]:
#print("コメント探索")
comment_data.append(str(samp)+"\n")
"""
コメントデータの場所が変更されたのを確認 2019/6/27
samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["message"]["simpleText"]
↓
samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["message"]["runs"][0]["text"]
"""
#コメント取得
try:
coment=str(samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["message"]["runs"][0]["text"])
#print(coment)
except:
#print("取得できないコメントです")
continue
#コメント時間の取得
time_msec=int(samp["replayChatItemAction"]["videoOffsetTimeMsec"])#コメントした時間のミリ秒を取得
time_msec=int(time_msec/1000)#ミリ秒→秒に変換
#print(str(time_msec)+"秒")
(・・・略)
盛り上がりの定義
チャットの取得方法がわかったので次は、生放送における「盛り上がり」の定義とはなにか?について考えた。
ここで最初に思いついたのが秒間チャット数だ、秒間チャット数が多ければそこは盛り上がったシーンだと考えたが必ずしもそうではなかった。というのも、配信者が視聴者に対して質問を投げかける場面や、配信者の疑問に視聴者が応答する場面などではチャット数が増加するからだ。単純な秒間チャット数だけでは「盛り上がり」を上手く抽出できない
そこで、特定のワードに着目することで「盛り上がり」を定義することにした。というのも、ネット上では面白いという感情を表現するワードとして**「草」や「w」**のような文字が使われているからだ、上記のワードが語尾に含まれる場合や、これらのワードのみで構成されるチャットを秒間でカウントして数値が大きい個所を盛り上がり箇所として抽出することにした。
実際に「草」や「w」の含まれる1秒間のチャット数をカウントしてグラフ化した画像を以下に示す。
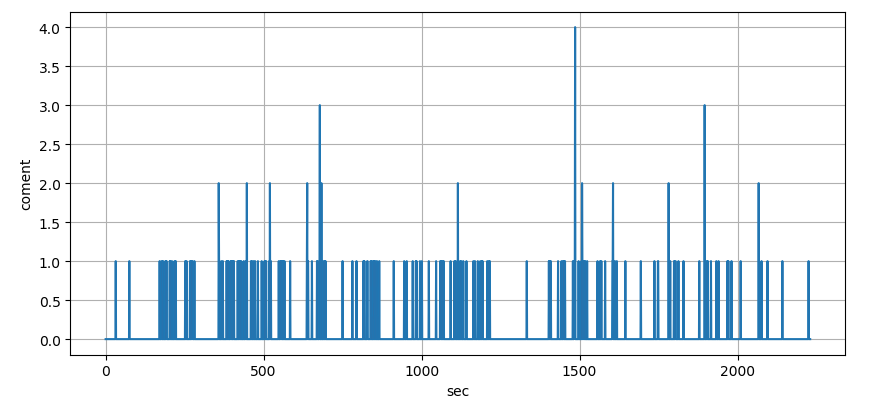
ここで、本当に1秒間の頻度で判断していいのかと疑問に感じた。というのも、チャットは連続性があり配信者の1アクションに対して数秒に渡ってチャットが流れるからだ。ある程度の時間的な幅が必要だと考え、10秒単位でカウントすることにした。
10秒単位でカウントしてグラフ化した画像を以下に示す。
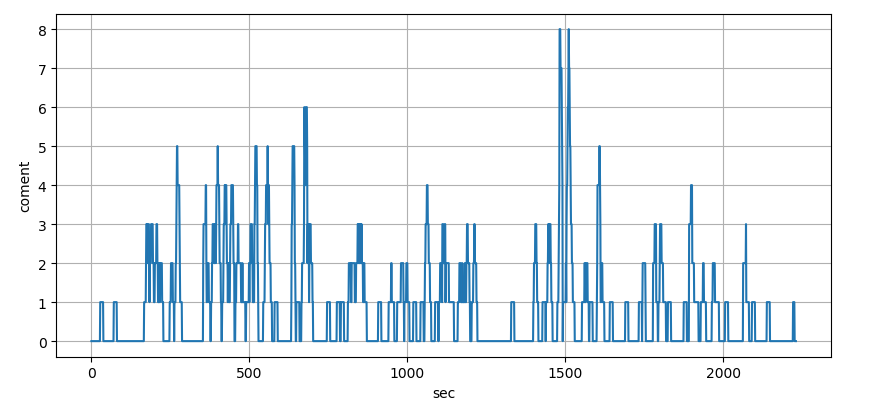
1秒単位では現れなかった部分が確認できる。
ではなぜ10秒単位なのか?正直言うとここは適当に設定した。ここの時間幅はもう少し考察する必要があるかもしれない
後はコメント数の多い順に盛り上がった箇所の時間リストを生成
動画のダウンロード
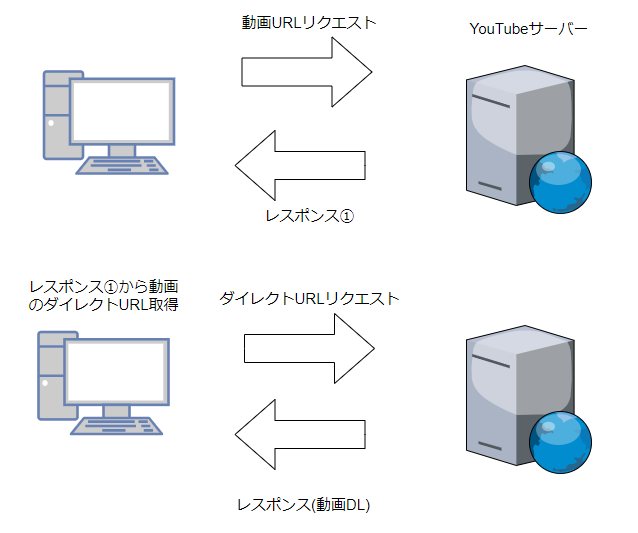
YouTubeから動画をDLするのにはpytubeというパッケージを使用した。https://python-pytube.readthedocs.io/en/latest/
動画URLからDLできる便利なパッケージ
仕組みは、動画URLリクエスト(動画視聴用のURL)のレスポンスから動画のダイレクトURL(実際に動画ファイルがある場所)を取得してYouTubeサーバーにリクエストすることで動画をDLしているらしい
pytubeについてもっと詳しく知りたい人はここ→ https://github.com/nficano/pytube
動画切り出し
時間を指定して動画を切り出すのにはMoviePyというパッケージを使用した。https://zulko.github.io/moviepy/
開始時刻と終了時刻を指定すれば指定動画ファイルから動画を切り出してくれる。
今回開発したCLIでは切り出し位置は盛り上がり時間のリストの各要素に対して、盛り上がった時間が中央になるように各要素±1分の合計2分間を切り出している。(切り出し時間はCLIで指定できるようにした方がいいかもしれない)
抽出時間範囲をこのように設定したのには二つの理由がある。
一つ目はラグ対策だ、盛り上がり箇所10秒間のみを切り抜いただけでは映像とチャットにラグがあった場合に盛り上がり箇所を上手く切り抜けない
二つ目は前後の流れの把握のためだ、なぜ盛り上がっているのか把握するためには前後の流れも動画に含める必要がある、というのも、盛り上がり箇所10秒間を切り抜いただけでは話の流れを理解することが難しいからだ
以上の理由から、抽出する時間範囲にある程度の余裕を持たせる必要があると考えた。
しかし、前後の流れの時間幅は千差万別であり、これだけの時間を設定すれば抽出できるという明確な閾値がない、というかそんな閾値出すの無理なんじゃないか?
「動画は2分くらいが丁度いいというデータがある」という理由をこじつけて2分にした(正直この辺の時間設定は適当、とりあえず何か理由のある値が欲しかった)
参考URL:https://blog.hubspot.com/marketing/how-long-should-videos-be-on-instagram-twitter-facebook-youtube
並列処理
動画DLとチャット解析は独立した処理なので並列処理を行うことにした。しかし、pythonにはGIL(Global Interpreter Lock)という仕組みがあり、1プロセスに1つのインタプリタしか割り当てられないので1プロセスでは並列処理ができないことが判明した。(もっと正確には、GILを取得している1スレッドはPythonのコードの実行を行えるが他スレッドは動かせないとのこと)、どうやら複数プロセスを扱う必要があるらしい
そこで、複数のプロセスを扱うためのモジュールであるmultiprocessingを用いた。
multiprocessingドキュメント
以下コード(長いので一部省略)
from multiprocessing import Process, Queue, Pool
# 動画DL
def videodl(q,video_objct):
v_path=video_objct.dounlord_video() #動画のダウンロード処理
q.put(v_path)
return
# コメント解析
def analysis(q2,target_url):
c_count=coment_analysis.analysis(target_url)
q2.put(c_count)
return
(・・・略)
def main():
(・・・略)
#プロセス間のデータ受け渡しがキューかパイプでしかできない
q=Queue() #DLパス記録用のキュー
q2=Queue() #秒間コメント数記録用のキュー
#並行処理
pros=Process(target=videodl, args=(q,video_objct)) #動画DL
pros2=Process(target=analysis, args=(q2,target_url)) #コメント解析
pros.start()
pros2.start()
(・・・略)
#joinするまえにデータを受け取らないとerrorになる
video_path=q.get()
pros.join()
comment_count=q2.get()
pros2.join()
複数プロセスを扱うのでデータの受け渡しはキューで行った。データ受け渡しの際に、joinでプロセスがブロックされるのでその前にデータを受け取る必要がある
苦労した点・感想
外部パッケージのpytubeがYouTubeの仕様変更の影響を受ける為、pytubeを起因としたエラーが発生する時がある。
しかしこれはもう仕方がない事だと思う、今後はpytubeのOSS開発に貢献できるように勉強していこうと思っている。
今回は発想したシステムの機能を細分化した結果、機能に当てはまる技術が見つかったので比較的スムーズに開発できた。
やはり外部パッケージのpytubeとMoviePyの存在が大きかったと思う、自分のタスクとしてはチャットの解析と並列処理の部分で、動画DLと動画の切り出しに関しては外部パッケージに依存している。
スムーズに開発できるのはいいが外部パッケージに依存することでデメリットもある。可用性が低かったり保守が難しいという点だ、外部パッケージを起因としたエラーは修正に時間がかかる場合があり、また、修正後の最新verのリリースを待たなければならない
今後何かやる際はこういった部分も考慮して開発できたらと感じた。