ツイートを取得します
ワード「結婚」を含むツイートを取得しました。
2021年5月19日以降、取得ツイート数は最大10,000としました。
前回同様の手順で取り込みました。
#TwitterAPI認証情報設定
consumerKey <- "************"
consumerSecret <- "*****************"
accessToken <- "*****************"
accessSecret <- "*********************"
##TwitterAPIにログイン
library("twitteR")
options(httr_oauth_cache = TRUE)
setup_twitter_oauth(consumerKey, consumerSecret, accessToken, accessSecret)
#「結婚」を含む日本語ツイートを10000件取得。2021年5月19日から
tweets2 <- searchTwitter('結婚', n = 10000, since = "2021-05-19" , lang="ja" , locale="ja")
#データフレームに変換
tweetsdf2 <- twListToDF(tweets2)
#型を確認
class(tweets2)
[1] "data.frame"
#csvに出力する場合
write.csv(tweetsdf2,file="tweets2.txt")
#取得できたか確認
library(dplyr)
tweetsdf2 %>% head()
リツイートを使う
まず、リツイートされたもの(TRUE)、そうでないもの(FALSE)のを確認し。リツイートのみ取り出します。
#リツイートされたもの(TRUE)、そうでないもの(FALSE)の数を確認
table(tweetsdf2$isRetweet)
FALSE TRUE
4128 5872
#今回リツイートのみ使ってみる
tweetsdf3 <- tweetsdf2 %>% filter(isRetweet %in% c("TRUE"))
head(tweetsdf3) #確認
nrow(tweetsdf3) #行数確認
#データフレームのテキスト列だけ抽出
texts <- tweetsdf3$text
head(texts) #確認
#後々使うのでテキスト処理のためのライブラリを呼び出す
library(stringr)
library(magrittr)
形態素解析をかける
「RMeCab」を使い形態素解析をかけるために、テキストを結合します。
一時ファイルを作り、そのファイルに対し、形態素解析を実行します。
#複数の(リスト型)テキストを結合。テキストとテキストの間にはブランクを入れる
texts3 <- paste(texts, collapse = "")
#一時ファイルを作り、xfileという名前で保存
xfile <- tempfile()
write(texts3, xfile)
##形態素解析のライブラリー
library(RMeCab)
#形態素解析。頻度を集計
frq_Tw2 <- RMeCabFreq(xfile)
#上位50を確認
frq_Tw2 %>% arrange(Freq) %>% tail(50)
10250 星野 名詞 固有名詞 3202
10251 を 助詞 格助詞 3301
10252 。 記号 句点 3603
10253 # 名詞 サ変接続 3656
10254 は 助詞 係助詞 4032
10255 て 助詞 接続助詞 4282
10256 だ 助動詞 * 4850
10257 する 動詞 自立 5867
10258 、 記号 読点 5938
10259 : 名詞 サ変接続 6009
10260 が 助詞 格助詞 6133
10261 @ 名詞 サ変接続 6240
10262 た 助動詞 * 6486
10263 の 助詞 連体化 7148
10264 結婚 名詞 サ変接続 7169
品詞を指定しノイズっぽいものを外す
今回は「名詞」をピックアップすることにしました。
frq3_Tw2 <- frq_Tw2 %>% filter(Info1 %in% c("名詞"))
frq3_Tw2 %>% arrange(Freq) %>% tail(50) #確認
8271 ガッキー 名詞 一般 2161
8272 co 名詞 一般 2409
8273 / 名詞 サ変接続 2411
8274 :// 名詞 サ変接続 2417
8275 t 名詞 一般 2436
8276 結衣 名詞 固有名詞 2442
8277 新垣 名詞 固有名詞 2540
8278 RT 名詞 一般 2599
8279 . 名詞 サ変接続 2602
8280 _ 名詞 サ変接続 2786
8281 源 名詞 固有名詞 2942
8282 星野 名詞 固有名詞 3202
8283 # 名詞 サ変接続 3656
8284 : 名詞 サ変接続 6009
8285 @ 名詞 サ変接続 6240
8286 結婚 名詞 サ変接続 7169
「単語」として扱いにくいものは外します。
#termがアルファベットを削除。noun列が作られ「<NA>」が表示。mutateは列を追加したり修正する
frq4_Tw2 <- frq3_Tw2 %>% mutate(noun=str_match((Term), '[^a-zA-Z]+')) #◼️
frq4_Tw2 %>% arrange(Freq) %>% tail(50)
#削除。na.omitでNA含む行を削除。
frq5_Tw2 <- na.omit(frq4_Tw2) #◼️
frq5_Tw2 %>% arrange(Freq) %>% tail(50)
5206 ガッキー 名詞 一般 2161 ガッキー
5207 / 名詞 サ変接続 2411 /
5208 :// 名詞 サ変接続 2417 ://
5209 結衣 名詞 固有名詞 2442 結衣
5210 新垣 名詞 固有名詞 2540 新垣
5211 . 名詞 サ変接続 2602 .
5212 _ 名詞 サ変接続 2786 _
5213 源 名詞 固有名詞 2942 源
5214 星野 名詞 固有名詞 3202 星野
5215 # 名詞 サ変接続 3656 #
5216 : 名詞 サ変接続 6009 :
5217 @ 名詞 サ変接続 6240 @
5218 結婚 名詞 サ変接続 7169 結婚
#termが記号を識別。noun列が作られ「<NA>」が表示。「\\W」は記号
frq6_Tw2 <- frq5_Tw2 %>% mutate(noun=str_match((Term), '[^\\W]+'))
frq6_Tw2 %>% arrange(Freq) %>% tail(50)
#削除。na.omitでNA含む行を削除。
frq7_Tw2 <- na.omit(frq6_Tw2)
frq7_Tw2 %>% arrange(Freq) %>% tail(50)
4961 発表 名詞 サ変接続 973 発表
4962 逃げ 名詞 一般 992 逃げ
4963 恥 名詞 一般 1164 恥
4964 ん 名詞 非自立 1294 ん
4965 さん 名詞 接尾 2046 さん
4966 ガッキー 名詞 一般 2161 ガッキー
4967 結衣 名詞 固有名詞 2442 結衣
4968 新垣 名詞 固有名詞 2540 新垣
4969 _ 名詞 サ変接続 2786 _
4970 源 名詞 固有名詞 2942 源
4971 星野 名詞 固有名詞 3202 星野
4972 結婚 名詞 サ変接続 7169 結婚
さらに見やすくするために1文字のワードを外すことにしました。
ただ、2文字の単単語とみなされませんでしたが、「恥」と「源」というワードは抜き出し、後で結合することにしました。
#「恥」を後で結合できるように取り出しておく
frq7_Tw2_2 <- frq7_Tw2 %>% filter(Term %in% c("恥","源"))
frq7_Tw2_2
Term Info1 Info2 Freq noun
1 恥 名詞 一般 1164 恥
2 源 名詞 一般 83 源
3 源 名詞 固有名詞 2942 源
4 源 名詞 接尾 254 源
#Termが1文字の行を削除。まず、1文字ワードの行番号を抽出
index <- grep('..', frq7_Tw2[,1])
tail(index)
[1] 4942 4944 4950 4951 4969 4970
frq7_Tw2[index,] %>% arrange(Freq) %>% tail(50) #確認
4170 今日 名詞 副詞可能 494 今日
4171 こと 名詞 非自立 802 こと
4172 発表 名詞 サ変接続 973 発表
4173 逃げ 名詞 一般 992 逃げ
4174 さん 名詞 接尾 2046 さん
4175 ガッキー 名詞 一般 2161 ガッキー
4176 結衣 名詞 固有名詞 2442 結衣
4177 新垣 名詞 固有名詞 2540 新垣
4178 星野 名詞 固有名詞 3202 星野
4179 結婚 名詞 サ変接続 7169 結婚
#上記データフレームを下記に収納
frq8_Tw2 <- frq7_Tw2[index,]
frq8_Tw2 %>% arrange(Freq) %>% tail(50)
先ほど抜き出した「源」「恥」のデータフレームを結合します。
frq9_Tw2 <- rbind(frq8_Tw2, frq7_Tw2_2)
frq9_Tw2 %>% arrange(Freq) %>% tail(50)
ワードクラウドを描画
#wordcloud2で描画準備
library(wordcloud2)
frq11_Tw2 <- frq9_Tw2 #下記の作業でミスをした場合元のデータフレームに戻せるようにする
#Freqが100以上にする。まず確認
frq11_Tw2[frq11_Tw2$Freq >= 100,] %>% arrange(Freq) %>% head() #確認
1 集中 名詞 サ変接続 100 集中
2 交通 名詞 一般 100 交通
3 保険 名詞 一般 100 保険
4 事故 名詞 一般 101 事故
5 しな 名詞 接尾 101 しな
6 なか 名詞 非自立 101 なか
frq12_Tw2 <- frq11_Tw2$Freq >= 100
tail(frq12_Tw2) #確認
[1] FALSE FALSE TRUE FALSE TRUE TRUE
frq13_Tw2 <- frq11_Tw2[frq12_Tw2,]
frq13_Tw2 %>% arrange(Freq) %>% head()
Term Info1 Info2 Freq noun
1 集中 名詞 サ変接続 100 集中
2 交通 名詞 一般 100 交通
3 保険 名詞 一般 100 保険
・・・
#wordcloud2で描画。frq13_Tw2の1列目(Term)と4列目(Freq)を使う
frq13_Tw2[,c(1,4)] %>% wordcloud2(size=2,minSize=1) #size
frq13_Tw2[,c(1,4)] %>% wordcloud2(size=2.3,minSize=1) #sizeを大きくし方がバランスよいのでこちら使用
wordcloud2で描画した結果です。

ネットワークグラフ(図)作成
ネットワークグラフも作成してみます。
ワードクラウドを作る過程で用意したデータフレーム 「tweetsdf3」を使います。
Nグラム(今回N=2)用データを用意します。
head(tweetsdf3) #内容確認
#バイグラムデータの作成。column = 1はツイートテキストの列
#type = 1はターム(単語)のNグラム。N = 2なので2グラム。nDF = TRUEでおそらくタームごとの列作成
tw_res <- docDF(tweetsdf3, column = 1, type = 1, N = 2, nDF = TRUE)
head(tw_res) #N1-N2が取得した書くツイートに含まれるかをRow1以降に収納
N1 N2 POS1 POS2 Row1 Row2 Row3 Row4 Row5 Row6 Row7
1 ! これ 名詞-名詞 サ変接続-代名詞 0 0 0 0 0 0 0
2 ! ニュース 名詞-名詞 サ変接続-一般 0 0 0 0 0 0 0
3 ! モーニング 名詞-名詞 サ変接続-一般 0 0 0 0 0 0 0
4 ! ユイ 名詞-名詞 サ変接続-固有名詞 0 0 0 0 0 0 0
5 ! 東野 名詞-名詞 サ変接続-固有名詞 0 0 0 0 0 0 0
6 ! \U0001f389\U0001f44f 名詞-記号 サ変接続-一般 0 0 0 0 0 0 0
ネットワークグラフ描画用に整形します。
#N1-N2の出現歌回数を集計
tw_res2 <- cbind(tw_res[, 1:2], rowSums(tw_res[, 5:ncol(tw_res)]))
head(tw_res2)
N1 N2 rowSums(tw_res[, 5:ncol(tw_res)])
1 ! これ 6
2 ! ニュース 1
3 ! モーニング 3
4 ! ユイ 2
5 ! 東野 1
6 ! \U0001f389\U0001f44f 1
#出現数の降順で並び替え
tw_res3 <- tw_res2[order(tw_res2[,3], decreasing = TRUE),]
head(tw_res3)
N1 N2 rowSums(tw_res[, 5:ncol(tw_res)])
5103 RT @ 5820
30910 結婚 する 3032
28578 星野 源 2843
3001 :// t 2417
7743 t . 2410
527 . co 2408
class(tw_res3) #型の確認
[1] "data.frame"
#3列目の列名を「Freq」に変更
colnames(tw_res3)[3] <- "Freq"
head(tw_res3)
N1 N2 Freq
5103 RT @ 5820
30910 結婚 する 3032
28578 星野 源 2843
3001 :// t 2417
7743 t . 2410
527 . co 2408
文章と関係なさそうなタームを外します。
#N1がアルファベットを削除。noun列が作られ「<NA>」が表示。mutateは列を追加したり修正する
tw_res4 <- tw_res3 %>% mutate(noun=str_match((N1), '[^a-zA-Z]+')) #◼️
tw_res4 %>% head(10) #確認
N1 N2 Freq noun
1 RT @ 5820 <NA>
2 結婚 する 3032 結婚
3 星野 源 2843 星野
4 :// t 2417 ://
5 t . 2410 <NA>
6 . co 2408 .
7 新垣 結衣 2382 新垣
8 co / 2340 <NA>
9 する た 2281 する
10 が 結婚 2135 が
#削除。na.omitでNA含む行を削除。
tw_res5 <- na.omit(tw_res4) #◼️
tw_res5 %>% head(10) #確認
N1 N2 Freq noun
2 結婚 する 3032 結婚
3 星野 源 2843 星野
4 :// t 2417 ://
6 . co 2408 .
7 新垣 結衣 2382 新垣
9 する た 2281 する
10 が 結婚 2135 が
12 の 結婚 1197 の
13 ! ! 1001 !
14 する て 989 する
#N同様にN2がアルファベットを削除。noun列が作られ「<NA>」が表示。mutateは列を追加したり修正する
tw_res6 <- tw_res5 %>% mutate(noun=str_match((N2), '[^a-zA-Z]+')) #◼️
tw_res6 %>% head(10) #確認
#削除。na.omitでNA含む行を削除。
tw_res7 <- na.omit(tw_res6) #◼️
tw_res7 %>% head(10) #確認
N1 N2 Freq noun
1 結婚 する 3032 する
2 星野 源 2843 源
5 新垣 結衣 2382 結衣
6 する た 2281 た
7 が 結婚 2135 結婚
8 の 結婚 1197 結婚
9 ! ! 1001 !
10 する て 989 て
11 逃げ 恥 981 恥
12 た 、 961 、
ネットーワークグラフをプロットします。
#グラフのプロット
#出現数を100以上に設定
Plot_Tw <- subset(tw_res7, tw_res7[, 3] > 300)
tail(Plot_Tw)
N1 N2 Freq noun
82 歳 。 324 。
83 結衣 、 324 、
84 て くる 323 くる
85 た の 319 の
86 と 星野 316 星野
87 : 結婚 310 結婚
#MACでの文字化け防止
par(family = "HiraKakuProN-W3")
#グラフのプロット
#データフレーム をネットワークグラフ形式に変換
library(igraph)
Plot_Tw1 <- graph_from_data_frame(Plot_Tw)
#ネットワークグラフをプロット
plot(Plot_Tw1,vertex.color="white",vertex.size=4,
vertex.label.cex=1.5,
vertex.label.dist=1.1,
edge.width=E(Plot_Tw1)$weight,
vertex.label.cex=0.8,
vertex.label.family="HiraKakuProN-W3")
プロットした結果です。
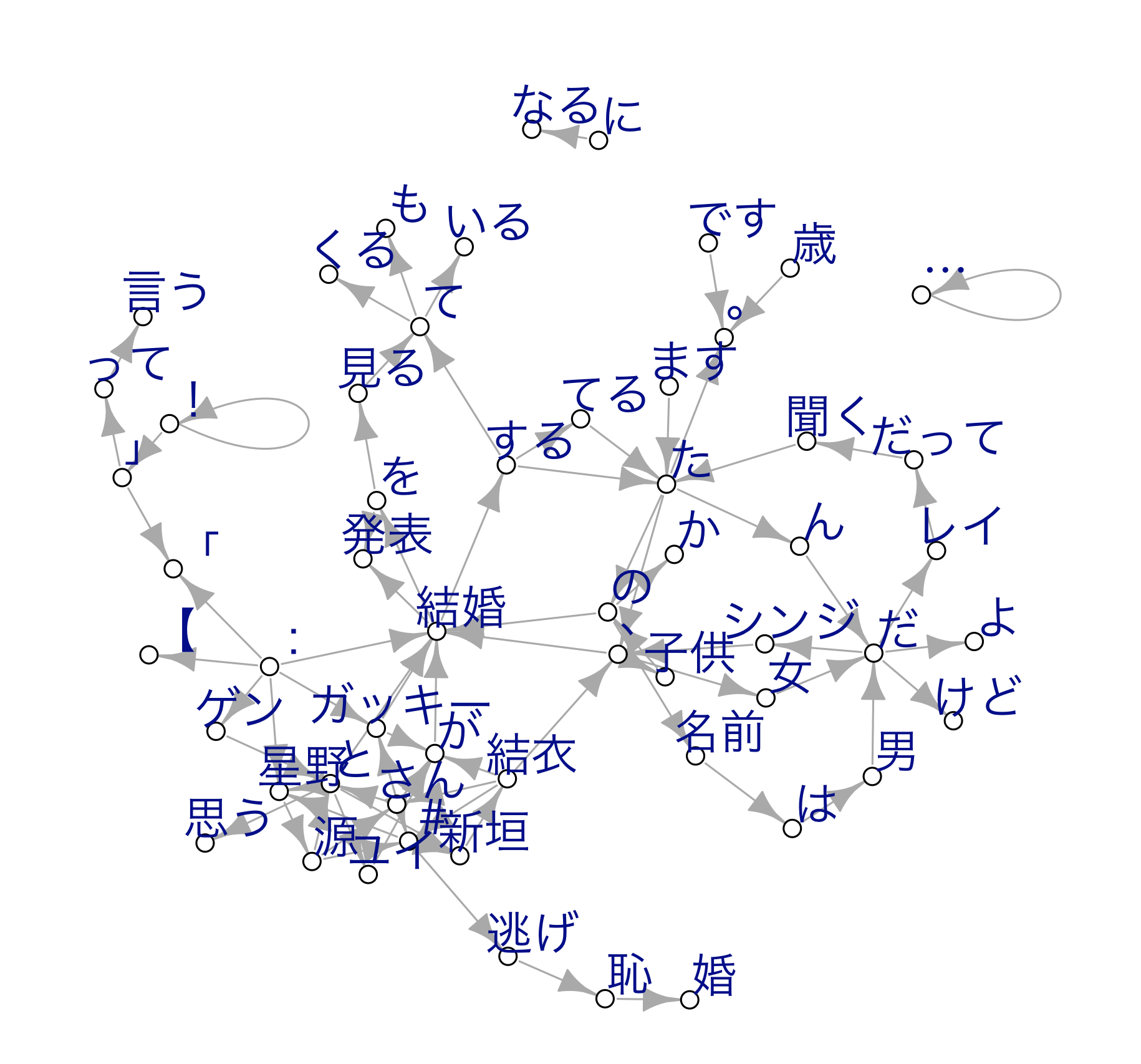
「シンジ」とは?
ワードクラウドでは目立ちませんでしたが、ネットワークグラフ で見ると「シンジ」という単語が気になりました。
Twitterで検索したところ、
「ゲン」と「ユイ」の子供だから
というツイートが飛び交っていました。
納得です。
参考させて頂いたサイト
了