APIの利用準備
手こずるだろうと思い、手を付けなかった「R言語」での取り込み。
知見不足なので、スマートにはできず。
せっかく実行したので、メモとして残しておきます。
効率のよい方法は今後見つけることとします。
以前同様「e-Stat」の APIを使います。
http://api.e-stat.go.jp/rest/3.0/app/getSimpleStatsData?cdTab=020&appId=<自分のアプリケーションID>&lang=J&statsDataId=0003410379&metaGetFlg=Y&cntGetFlg=N&explanationGetFlg=Y&annotationGetFlg=Y§ionHeaderFlg=1&replaceSpChars=0
R言語で 「readr」 パッケージを使ってインポートします。
library(readr)
api_csv <- "http://api.e-stat.go.jp/rest/3.0/app/getSimpleStatsData?cdTab=020&appId=<自分のアプリケーションID>&lang=J&statsDataId=0003410379&metaGetFlg=Y&cntGetFlg=N&explanationGetFlg=Y&annotationGetFlg=Y§ionHeaderFlg=1&replaceSpChars=0"
pop_data <- read_csv(api_csv)
tail(pop_data) #確認
# A tibble: 6 × 1
RESULT
<chr>
1 "020,人口,120,女,47000,沖縄県,1995000000,1995年,人,648703,\""
2 "020,人口,120,女,47000,沖縄県,2000000000,2000年,人,670343,\""
3 "020,人口,120,女,47000,沖縄県,2005000000,2005年,人,693092,\""
4 "020,人口,120,女,47000,沖縄県,2010000000,2010年,人,709490,\""
5 "020,人口,120,女,47000,沖縄県,2015000000,2015年,人,728947,\""
6 "020,人口,120,女,47000,沖縄県,2020000000,2020年,人,744668,\""
Warning message:
One or more parsing issues, see `problems()` for details
使わない項目を外す&列分割
そのままでは、行の最初の部分は説明に相当するので、可視化には使いません。
pop_data[25:35,] で25行目から35行目までを見ると、26行目までが説明部分だと確認。
pop_data[-1:-26,] で外します。
pop_data[25:35,]
# A tibble: 11 × 1
RESULT
<chr>
1 "NOTE,-,当該数値がないもの"
2 "VALUE"
3 "tab_code,表章項目,cat01_code,男女_時系列,area_code,地域_時系列,time_code,時間軸(調査年),u…
4 "020,人口,100,総数,00000,全国,1920000000,1920年,人,55963053,\""
5 "020,人口,100,総数,00000,全国,1925000000,1925年,人,59736822,\""
6 "020,人口,100,総数,00000,全国,1930000000,1930年,人,64450005,\""
7 "020,人口,100,総数,00000,全国,1935000000,1935年,人,69254148,\""
8 "020,人口,100,総数,00000,全国,1940000000,1940年,人,73114308,\""
9 "020,人口,100,総数,00000,全国,1945000000,1945年,人,71998104,\""
10 "020,人口,100,総数,00000,全国,1950000000,1950年,人,84114574,\""
11 "020,人口,100,総数,00000,全国,1955000000,1955年,人,90076594,\""
ただ、この時点では1列のデータフレームです。
後で分割します。
pop_data2 <- pop_data[-1:-26,]
head(pop_data2)
# A tibble: 6 × 1
RESULT
<chr>
1 "tab_code,表章項目,cat01_code,男女_時系列,area_code,地域_時系列,time_code,時間軸(調査年),un…
2 "020,人口,100,総数,00000,全国,1920000000,1920年,人,55963053,\""
3 "020,人口,100,総数,00000,全国,1925000000,1925年,人,59736822,\""
4 "020,人口,100,総数,00000,全国,1930000000,1930年,人,64450005,\""
5 "020,人口,100,総数,00000,全国,1935000000,1935年,人,69254148,\""
6 "020,人口,100,総数,00000,全国,1940000000,1940年,人,73114308,\""
1行目を列名とします。
「rown」(ベクトル)に収納しておきます。
列をカンマで分割します。
1行ずつ 「str_split」 で分割。
リスト(list)型で返されるので、「unlist」 でリスト型を外し、「rown」と 「rbind」 で結合できるようにしました。
nrow(pop_data2) #行数確認
[1] 3151
rown <- c("tab_code","表章項目","cat01_code","男女_時系列","area_code","地域_時系列","time_code","時間軸(調査年)","unit", "value", "annotation")
library(dplyr)
library(stringr)
x <- 2
for (i in 2:3151) {
row_bind <- str_split(pop_data2[x,], ",") %>% unlist()
rown <- rbind(rown, row_bind)
x <- x + 1
}
head(rown)
[,1] [,2] [,3] [,4] [,5] [,6]
rown "tab_code" "表章項目" "cat01_code" "男女_時系列" "area_code" "地域_時系列"
row_bind "020" "人口" "100" "総数" "00000" "全国"
row_bind "020" "人口" "100" "総数" "00000" "全国"
row_bind "020" "人口" "100" "総数" "00000" "全国"
row_bind "020" "人口" "100" "総数" "00000" "全国"
row_bind "020" "人口" "100" "総数" "00000" "全国"
[,7] [,8] [,9] [,10] [,11]
rown "time_code" "時間軸(調査年)" "unit" "value" "annotation"
row_bind "1920000000" "1920年" "人" "55963053" "\""
row_bind "1925000000" "1925年" "人" "59736822" "\""
row_bind "1930000000" "1930年" "人" "64450005" "\""
row_bind "1935000000" "1935年" "人" "69254148" "\""
row_bind "1940000000" "1940年" "人" "73114308" "\""
nrow(rown)
[1] 3151
データフレーム変換&列名配置
行列を 「as.data.frame」 でデータフレームに変換します。
データ型を確認し、後で人口値(value)を数値型に変換します。
その前に、列名がまだ1行目の値として収録されています。
class(rown) #型を確認
[1] "matrix" "array"
rown_df <- as.data.frame(rown)
class(rown_df)
[1] "data.frame"
str(rown_df) #データフレームの構造概要確認
'data.frame': 3151 obs. of 11 variables:
$ V1 : chr "tab_code" "020" "020" "020" ...
$ V2 : chr "表章項目" "人口" "人口" "人口" ...
$ V3 : chr "cat01_code" "100" "100" "100" ...
$ V4 : chr "男女_時系列" "総数" "総数" "総数" ...
$ V5 : chr "area_code" "00000" "00000" "00000" ...
$ V6 : chr "地域_時系列" "全国" "全国" "全国" ...
$ V7 : chr "time_code" "1920000000" "1925000000" "1930000000" ...
$ V8 : chr "時間軸(調査年)" "1920年" "1925年" "1930年" ...
$ V9 : chr "unit" "人" "人" "人" ...
$ V10: chr "value" "55963053" "59736822" "64450005" ...
$ V11: chr "annotation" "\"" "\"" "\"" ...
このため、1行目を 「colnames」 で列名としました。
colnames(rown_df) <- rown_df[1,]
> head(rown_df)
tab_code 表章項目 cat01_code 男女_時系列 area_code 地域_時系列 time_code
rown tab_code 表章項目 cat01_code 男女_時系列 area_code 地域_時系列 time_code
row_bind 020 人口 100 総数 00000 全国 1920000000
row_bind.1 020 人口 100 総数 00000 全国 1925000000
row_bind.2 020 人口 100 総数 00000 全国 1930000000
row_bind.3 020 人口 100 総数 00000 全国 1935000000
row_bind.4 020 人口 100 総数 00000 全国 1940000000
時間軸(調査年) unit value annotation
rown 時間軸(調査年) unit value annotation
row_bind 1920年 人 55963053 "
row_bind.1 1925年 人 59736822 "
row_bind.2 1930年 人 64450005 "
row_bind.3 1935年 人 69254148 "
row_bind.4 1940年 人 73114308 "
残った1行目を [-1,] と指定して削除します。
ようやく、作りたかったデータフレームの形になってきました。
rown_df2 <- rown_df[-1,]
head(rown_df2)
tab_code 表章項目 cat01_code 男女_時系列 area_code 地域_時系列 time_code
row_bind 020 人口 100 総数 00000 全国 1920000000
row_bind.1 020 人口 100 総数 00000 全国 1925000000
row_bind.2 020 人口 100 総数 00000 全国 1930000000
row_bind.3 020 人口 100 総数 00000 全国 1935000000
row_bind.4 020 人口 100 総数 00000 全国 1940000000
row_bind.5 020 人口 100 総数 00000 全国 1945000000
時間軸(調査年) unit value annotation
row_bind 1920年 人 55963053 "
row_bind.1 1925年 人 59736822 "
row_bind.2 1930年 人 64450005 "
row_bind.3 1935年 人 69254148 "
row_bind.4 1940年 人 73114308 "
row_bind.5 1945年 人 71998104 "
str(rown_df2)
'data.frame': 3150 obs. of 11 variables:
$ tab_code : chr "020" "020" "020" "020" ...
$ 表章項目 : chr "人口" "人口" "人口" "人口" ...
$ cat01_code : chr "100" "100" "100" "100" ...
$ 男女_時系列 : chr "総数" "総数" "総数" "総数" ...
$ area_code : chr "00000" "00000" "00000" "00000" ...
$ 地域_時系列 : chr "全国" "全国" "全国" "全国" ...
$ time_code : chr "1920000000" "1925000000" "1930000000" "1935000000" ...
$ 時間軸(調査年): chr "1920年" "1925年" "1930年" "1935年" ...
$ unit : chr "人" "人" "人" "人" ...
$ value : chr "55963053" "59736822" "64450005" "69254148" ...
$ annotation : chr "\"" "\"" "\"" "\"" ...
数値型変換&エラー削除
人口値(value)を 「as.numeric」 で数値型に変換をしたところ、エラー(Warning)が出ました。
rown_df2$value <- as.numeric(rown_df2$value)
Warning message:
NAs introduced by coercion
原因は数値型にできない文字列「-」が入っていたため。
「str_replace」 で「NA値」に変換しました。
rown_df2$value <- str_replace(rown_df2$value, "-", NA_character_)
rown_df2$value <- as.numeric(rown_df2$value)
str(rown_df2)
'data.frame': 3150 obs. of 11 variables:
$ tab_code : chr "020" "020" "020" "020" ...
$ 表章項目 : chr "人口" "人口" "人口" "人口" ...
$ cat01_code : chr "100" "100" "100" "100" ...
$ 男女_時系列 : chr "総数" "総数" "総数" "総数" ...
$ area_code : chr "00000" "00000" "00000" "00000" ...
$ 地域_時系列 : chr "全国" "全国" "全国" "全国" ...
$ time_code : chr "1920000000" "1925000000" "1930000000" "1935000000" ...
$ 時間軸(調査年): chr "1920年" "1925年" "1930年" "1935年" ...
$ unit : chr "人" "人" "人" "人" ...
$ value : num 55963053 59736822 64450005 69254148 73114308 ...
$ annotation : chr "\"" "\"" "\"" "\"" ...
X軸準備&グラフ作成
上記「value」はY軸値になり、X軸は年号(国勢調査は5年毎)になります。
X軸を連続値にするために、今回は数値型に変換します。
「str_replace」 で「年」を「””」に変換し、「as.numeric」 で数値型にしました。
rown_df3 <-
rown_df2 %>%
mutate(YYYY = str_replace(rown_df2$"時間軸(調査年)", "年", "")) #括弧内の処理結果を収納する列を追加
head(rown_df3)
tab_code 表章項目 cat01_code 男女_時系列 area_code 地域_時系列 time_code
row_bind 020 人口 100 総数 00000 全国 1920000000
row_bind.1 020 人口 100 総数 00000 全国 1925000000
row_bind.2 020 人口 100 総数 00000 全国 1930000000
row_bind.3 020 人口 100 総数 00000 全国 1935000000
row_bind.4 020 人口 100 総数 00000 全国 1940000000
row_bind.5 020 人口 100 総数 00000 全国 1945000000
時間軸(調査年) unit value annotation YYYY
row_bind 1920年 人 55963053 " 1920
row_bind.1 1925年 人 59736822 " 1925
row_bind.2 1930年 人 64450005 " 1930
row_bind.3 1935年 人 69254148 " 1935
row_bind.4 1940年 人 73114308 " 1940
row_bind.5 1945年 人 71998104 " 1945
rown_df3$YYYY <- as.numeric(rown_df3$YYYY)
str(rown_df3$YYYY)
num [1:3150] 1920 1925 1930 1935 1940 ...
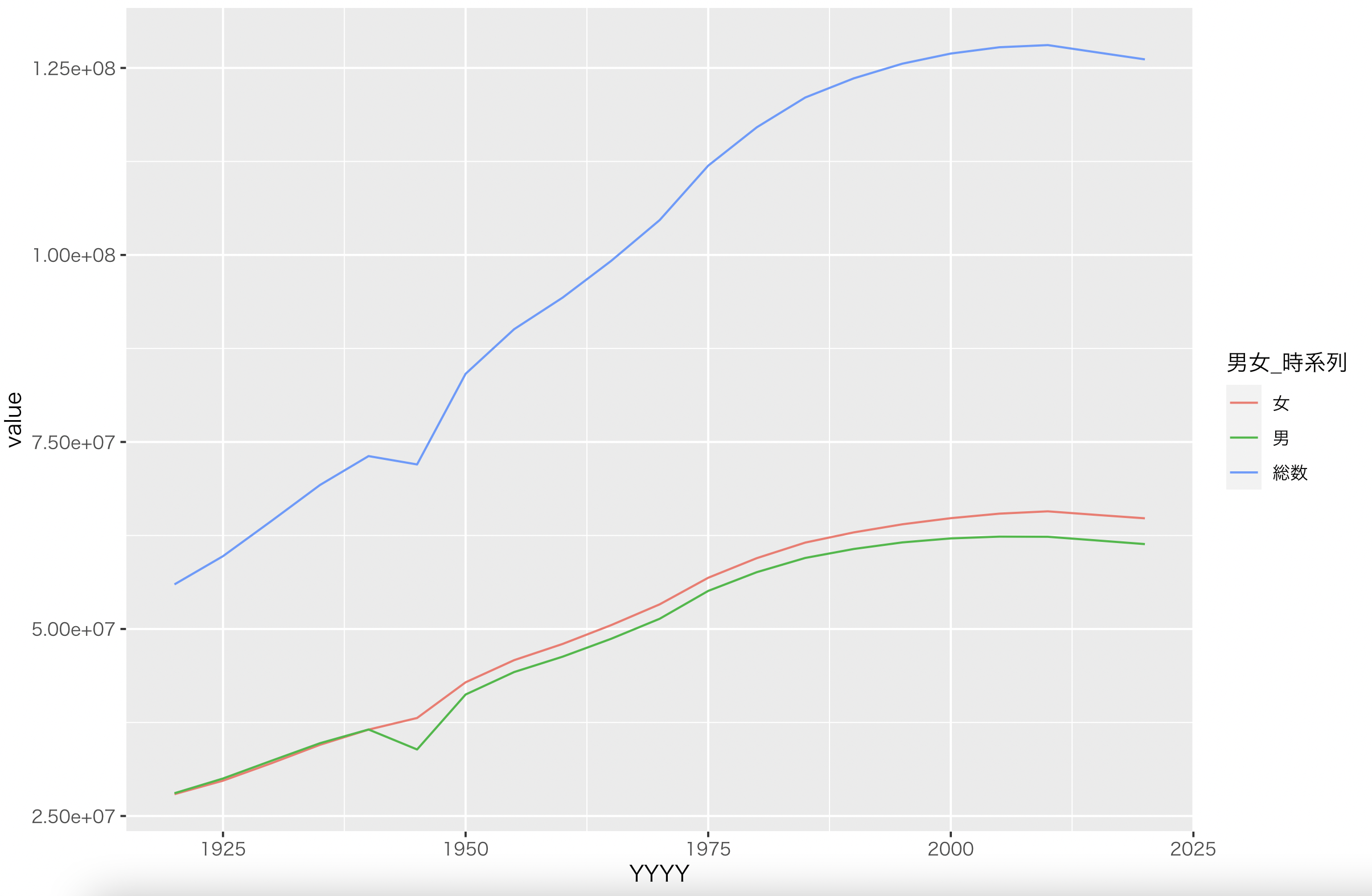
地域別にデータが配置されているので、rown_df3[rown_df3$地域_時系列 == "全国",] で日本全体の調査結果をピックアップします。
「ggplot」 & 「geom_line」 で折れ線グラフを描きます。
「colour」 で「総数」「男性値」「女性値」を凡例とする3本のグラフを並べました。
library(ggplot2)
rown_df4 <- rown_df3[rown_df3$地域_時系列 == "全国",]
ggplot(
data = rown_df4,
aes(x = YYYY, y = value, colour = 男女_時系列)) +
geom_line() +
theme_gray (base_family = "HiraKakuPro-W3") #Macの文字化けを回避するテーマ設定
了