RStudio Cloudを試す
ノンプログラミンで可視化する方が好みなので、プログラムには疎く、今になって「RStudio Cloud」を知りました。
試用がてら、ワードクラウドを作ることにししました。
経験不足もあり思い通りにはできず、何度もつまずきながら進めました。
RStudio Cloudの基本は以下を参考にしました。
アカウントを作り、RStudio Cloudを開きます。
パッケージをインストール
Twiterのツイートを解析しようと考えたので、まず「twitterR」をインストールしました。
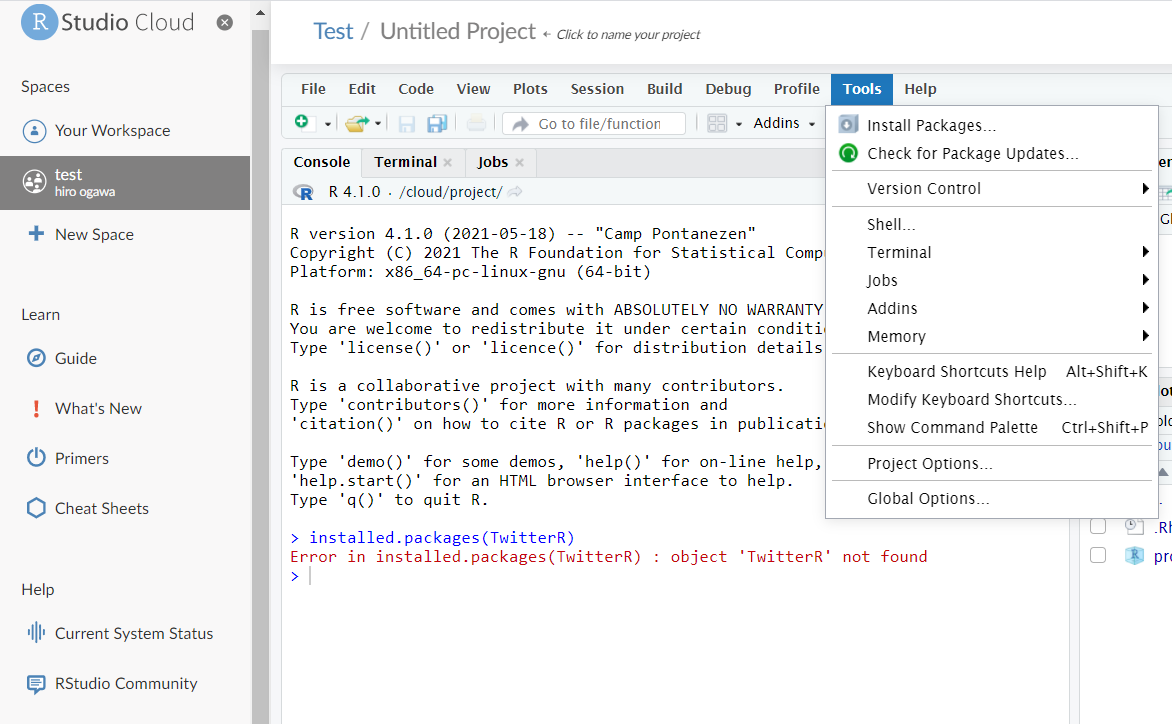
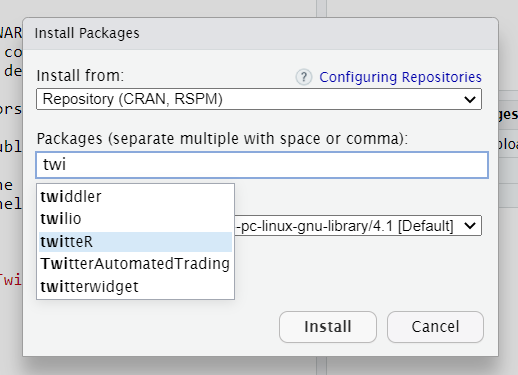
少々反応が遅いのですが、インストールできました。
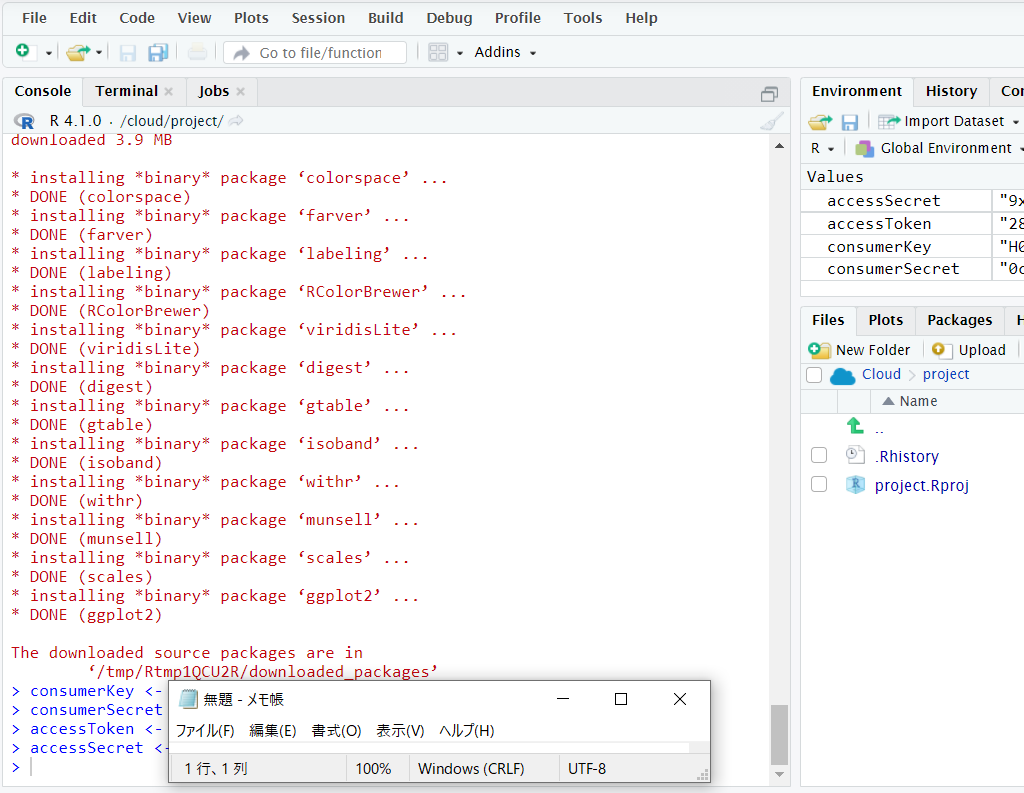
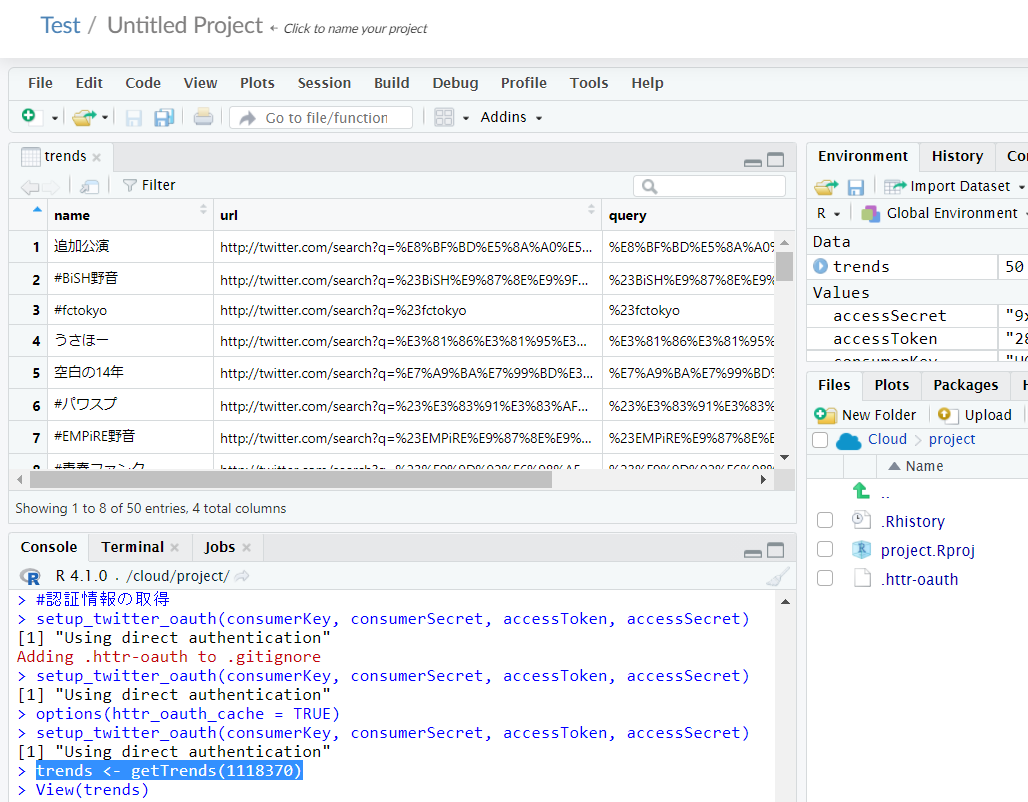
機能するかを試すためにTOKYO(1118370)のトレンドワードをピックアップしてみました。
trends <- getTrends(1118370)
このほか、以下のパッケージインストールしました。
install.packages("dplyr")
install.packages("magrittr")
install.packages("stringr")
install.packages("wordcloud2")
後述しますが、インストールできなかったのが形態素解析の「RMeCab」です。
ツイートを取得・失敗
この手順で操作を開始したのが2021/7/11(日)だったこともあり、「晴天を衝け」を含むツイートを取得しました。
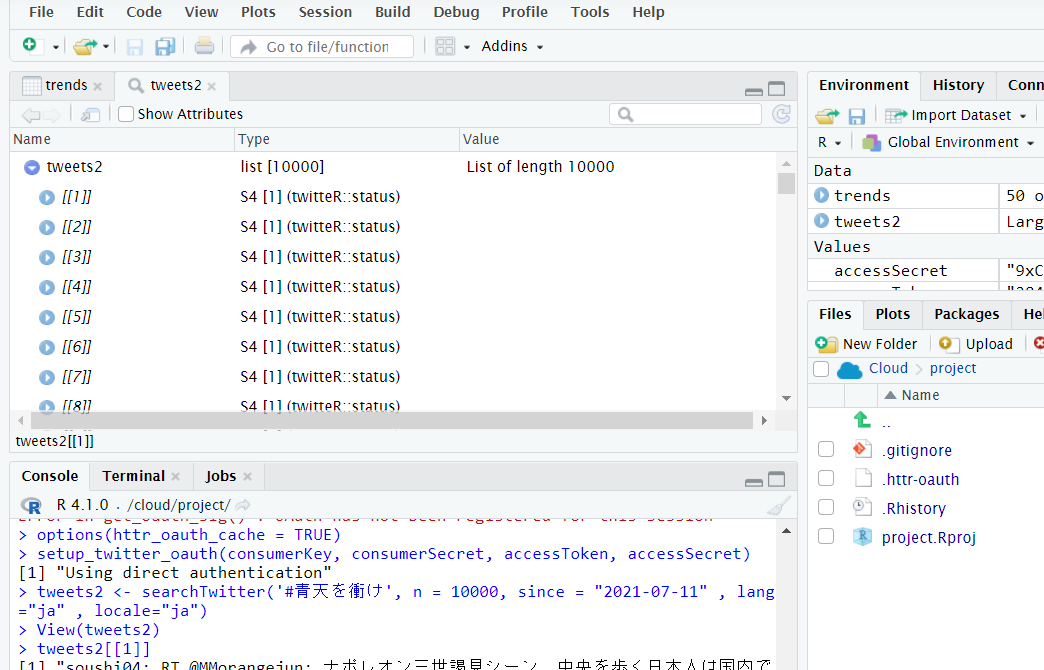
ここから、(思い出したので)「File」→「New File」→「R Script」でスクリプトエディタを使い始めました。
取得したツイートをデータフレームに変換します。
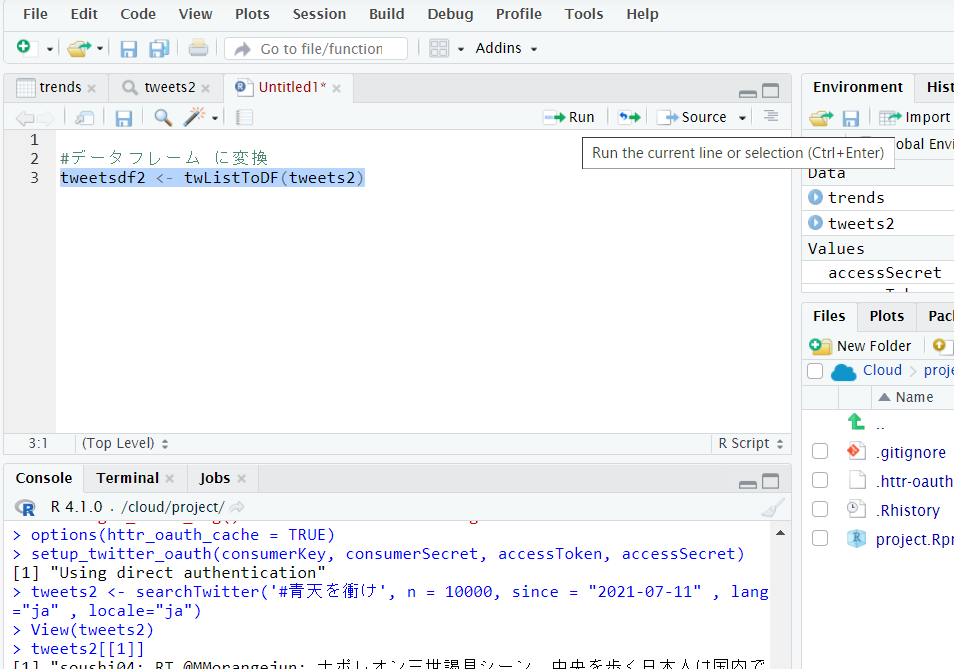
テキスト列のみを抽出し、結合します。
texts2 %<>% str_replace_all("\\p{ASCII}", "")
を使い、今回はここで記号やアルファベットを削除します。
エラーが出て先に進みません。
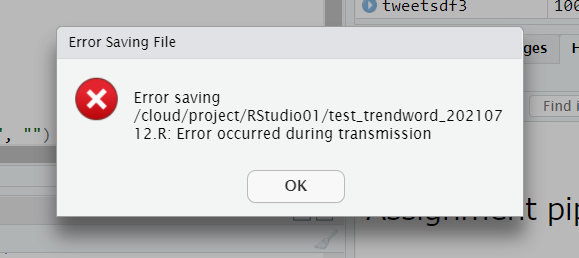
原因がわからなかったので、新しいプロジェクトを作り、再実行しました。
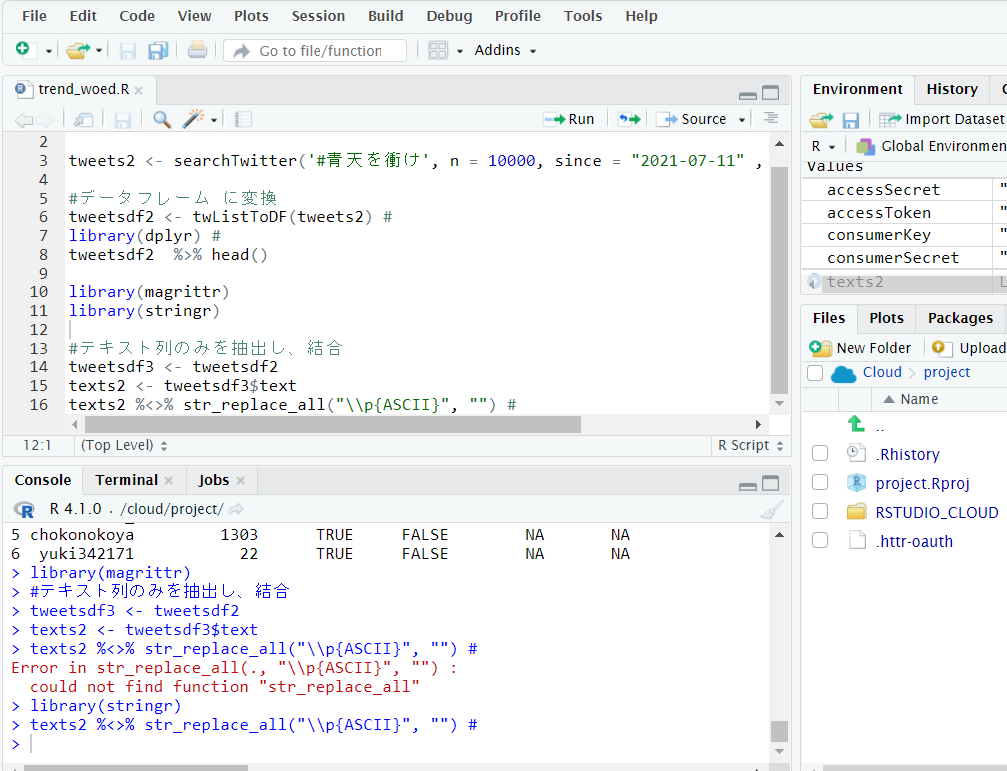
「xfile2」という一時ファイルを作り、そこに加工したツイートテキストを保存し、形態素解析を実行します。
形態素解のために、「RMeCab」というパッケージをインストールしようとしたのですが、以下のようなエラーが出ます。
install.packages ("RMeCab", repos = "http://rmecab.jp/R ", type = "source")
・・・・・・
When you run
downloaded 1.4 MB
installing * source * package ‘RMeCab’ ...
** using staged installation
** libs
g ++ -std = gnu ++ 14 -I "/opt/R/4.1.0/lib/R/include" -DNDEBUG -I / usr / local / include -fpic -g -O2 -c Ngram.cpp -o Ngram .o
In file included from Ngram.cpp: 2:
RMeCab.h: 25:10: fatal error: mecab.h: No such file or directory
etc.etc
・・・
ネットを検索して、他の方法も試したのですが、うまくいきませんでした。
海外のコミュニティに質問を投げたところ「ユーザーレベルでは無理。RStudioの管理者次第」という返答が返ってきました。
RMeCabについてはあまり詳しくないのですが、R本体と同じ環境にインストールしないといけないため、クラウド版には組み込めなかったのかもしれません。
形態素解析はデスクトップのRで回避
そこで、方針を変更しました。
RStudio Cloudで抽出したツイートをcsvで出力し、デスクトップのRで形態素解析をかけ、RStudio Cloudに取り込んでワードクラウドを作ることを試すことにしました。
また、先に進めず2日間止まっていたため、取得するツイートも変更しました。
『新宿駅から半径10kmの範囲で「ラーメン」を含むツイート』を取得することにしました。
tweets2 <- searchTwitter('ラーメン', geocode='35.689607,139.700571,10km', n = 5000, since = "2021-07-12", lang="ja")
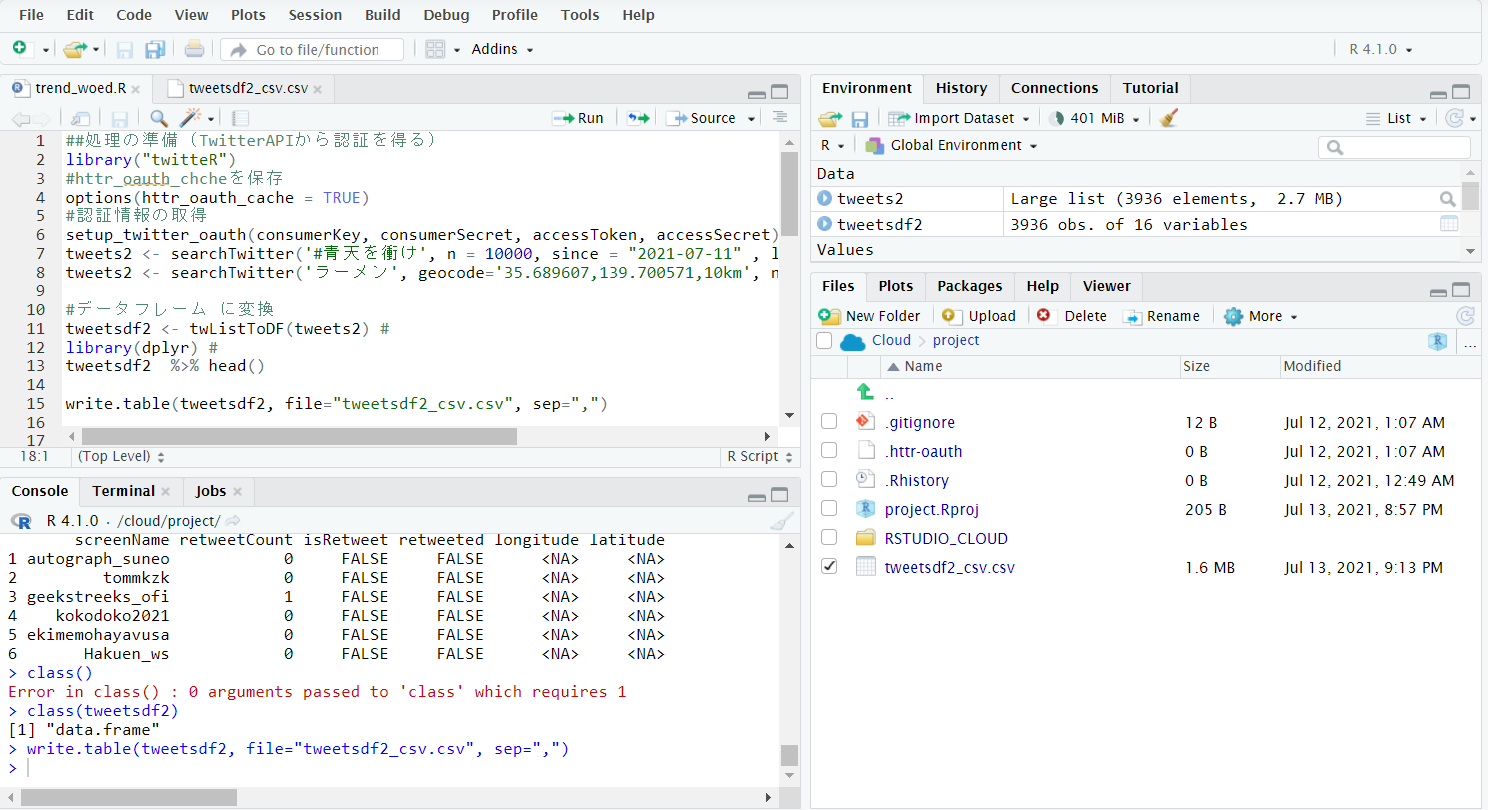
csvに出力します。
write.csv(tweetsdf2, file="tweetsdf2_csv.csv")
(画面ではwrite.tableを使っていますが、write.csvで出力したものを使っています。)
文字化けは秀丸で回避
「Export」を実行します。
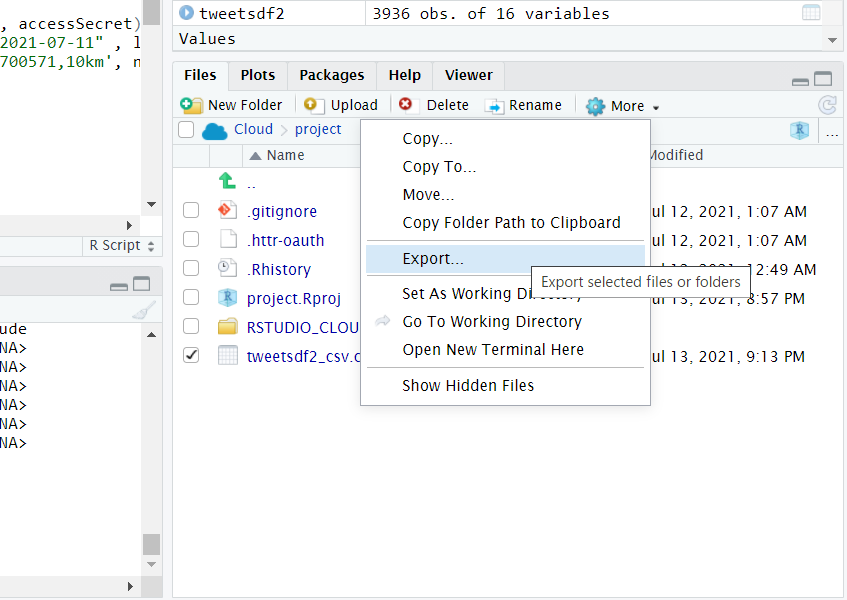
デスクトップのRから読み込みます。
ところがこれがうまくいきません。
文字コードを指定する、「readr」ライブラリを使うなど、いろいろ試しました。
tweetsdf3 <- read.csv("tweetsdf2_csv.csv", header=T, fileEncoding = "UTF-8")
tweetsdf3 <- read.csv("tweetsdf2_csv.csv", header=T, fileEncoding = "shift-jis")
tweetsdf3 <- read.csv("tweetsdf2_csv.csv", header=T, fileEncoding = "UTF-8-BOM")
tweetsdf3 <- read.csv("tweetsdf2_csv.csv", header=T, fileEncoding = "CP932")
以下のようなエラーが出ます。
警告メッセージ:
1: read.table(file = file, header = header, sep = sep, quote = quote, で:
入力コネクション 'tweetsdf2_csv.csv' に不正な入力がありました
2: read.table(file = file, header = header, sep = sep, quote = quote, で:
incomplete final line found by readTableHeader on 'tweetsdf2_csv.csv'
ネットで検索して調べたのですがうまくいかず、結局「秀丸」で「SHIFT-JIS」コードでで保存しました。
うまく変換できない文字も出ましたが、Rで取り込むことができました。
tweetsdf3 <- read.csv("tweetsdf2_csv.csv", header=T, fileEncoding = "shift-jis")
head(tweetsdf3)
favorited favoriteCount replyToSN created truncated
1 FALSE 0 <NA> 2021-07-13 12:00:59 FALSE
2 FALSE 1 <NA> 2021-07-13 12:00:22 FALSE
3 FALSE 1 <NA> 2021-07-13 11:59:34 TRUE
4 FALSE 0 mg_sparrow 2021-07-13 11:59:28 FALSE
5 FALSE 0 tk02948096 2021-07-13 11:59:23 FALSE
6 FALSE 0 <NA> 2021-07-13 11:59:05 FALSE
テキストだけを抽出するなどし、形態素解析をかけます。
library(stringr)
library(magrittr)
#テキスト列のみを抽出し、結合
texts2 <- tweetsdf3$text
texts2 %<>% str_replace_all("\\p{ASCII}", "") #今回はここで記号やアルファベットを削除
texts3 <- paste(texts2, collapse = "")
#一時ファイルを作り、xfile2という名前で保存
xfile2 <- tempfile()
write(texts3, xfile2)
library(RMeCab)
frq_Tw2 <- RMeCabFreq(xfile2)
file = C:\Users\hrogawa\AppData\Local\Temp\RtmpOaE1o8\file16d830b9944
length = 8398
frq_Tw2 %>% arrange(Freq) %>% tail(50)
Term Info1 Info2 Freq
1709 たまたま 副詞 一般 467
2196 会話 名詞 サ変接続 469
3623 シャツ 名詞 一般 469
1847 特に 副詞 一般 471
1481 変える 動詞 自立 474
4733 間 名詞 一般 475
486 なんて 助詞 副助詞 479
1595 れる 動詞 接尾 496
1136 作る 動詞 自立 499
1610 くれる 動詞 非自立 507
1555 流す 動詞 自立 520
8185 の 名詞 非自立 588
5439 人 名詞 一般 640
8060 分間 名詞 接尾 643
426 な 助詞 終助詞 647
6249 麺 名詞 一般 709
496 か 助詞 副助詞/並立助詞/終助詞 722
csvに書き出します。
fileEncodingを付与しないとRStudio Cloudで文字化けするので、警告メッセージが出ましたが、4日間にまたがるこの処理を先に進めたいので、目をつぶりました。
write.csv(frq_Tw2, file="frq_Tw2.csv", fileEncoding = "UTF-8")
警告メッセージ:
1: write.table(frq_Tw2, file = "frq_Tw2.csv", fileEncoding = "UTF-8", で:
出力の変換中に不正な char 文字列があります
2: write.table(frq_Tw2, file = "frq_Tw2.csv", fileEncoding = "UTF-8", で:
出力の変換中に不正な char 文字列があり
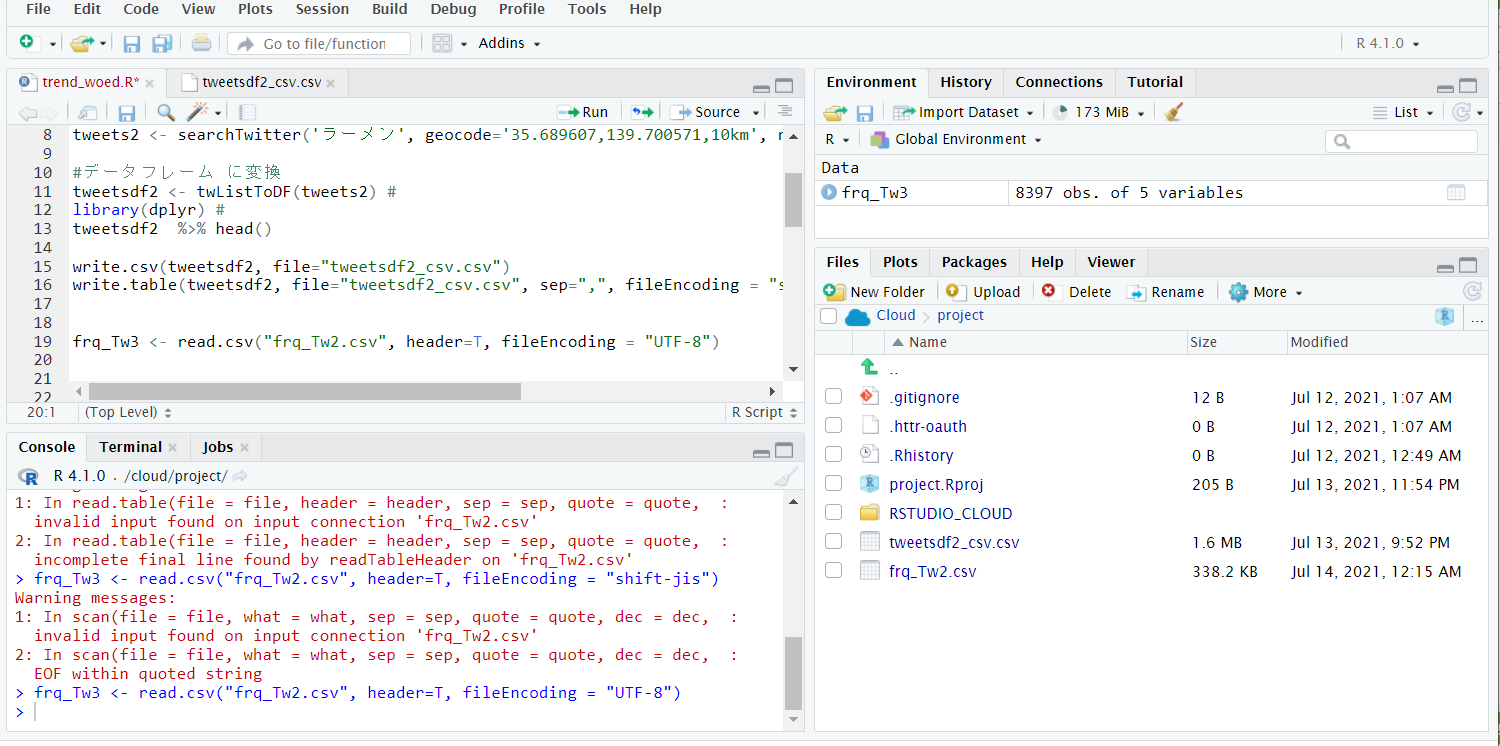
RStudio Cloudに戻りました
今度はRStudio Cloudに取り込みます。
「Upload」をします。
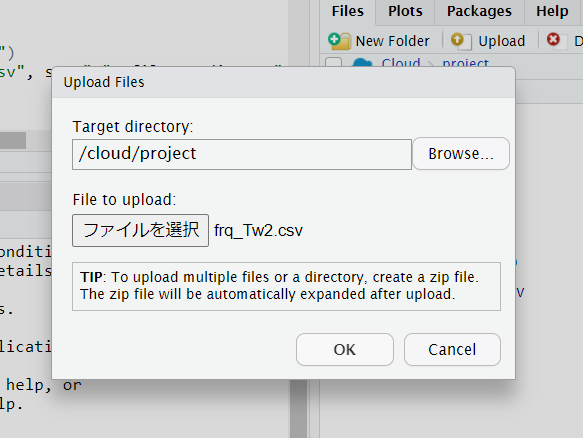
write.csvで取り込みます。
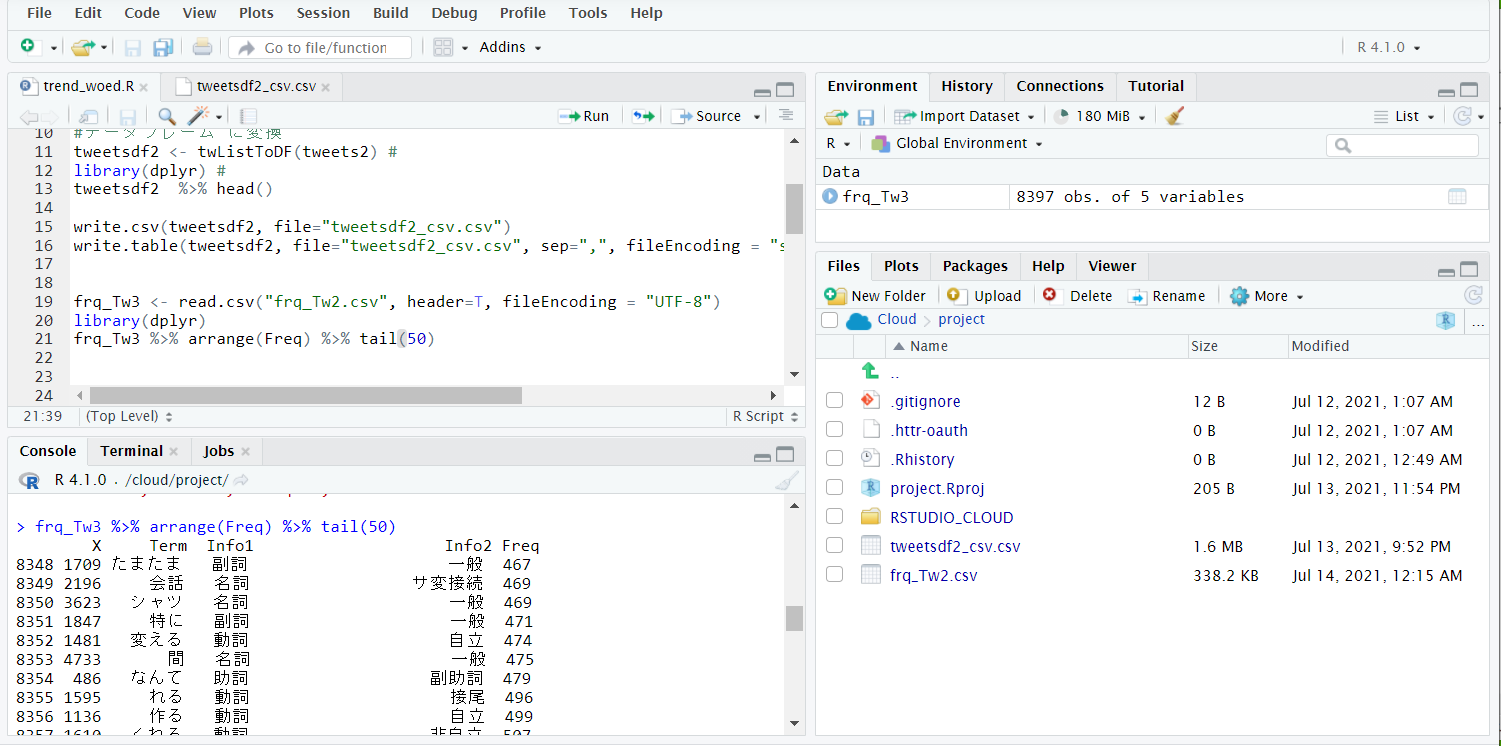
形容詞を抽出してワードクラウドを作ります。
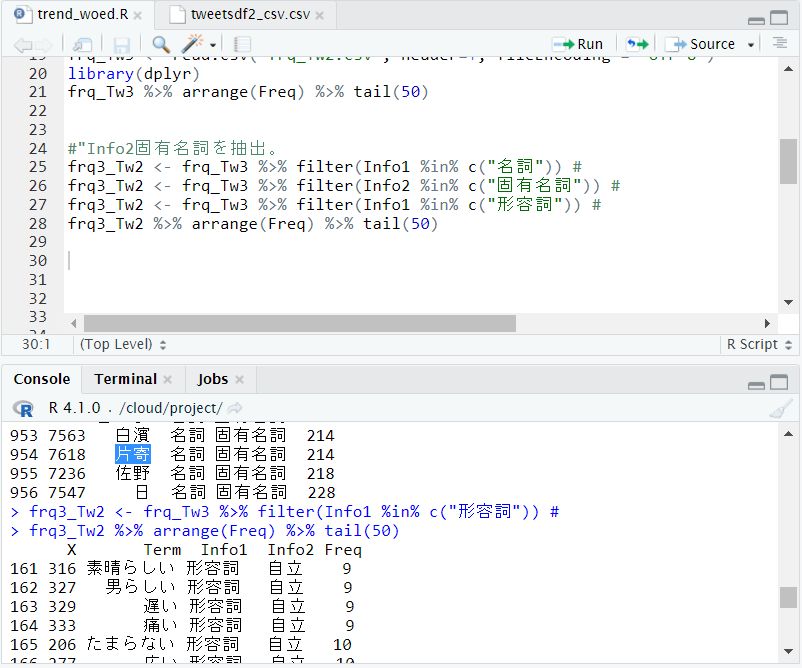
「ない」というワードが頻出して目立つので、見栄え調整のためにこの行を外します。
wordcloud2を実行しました。
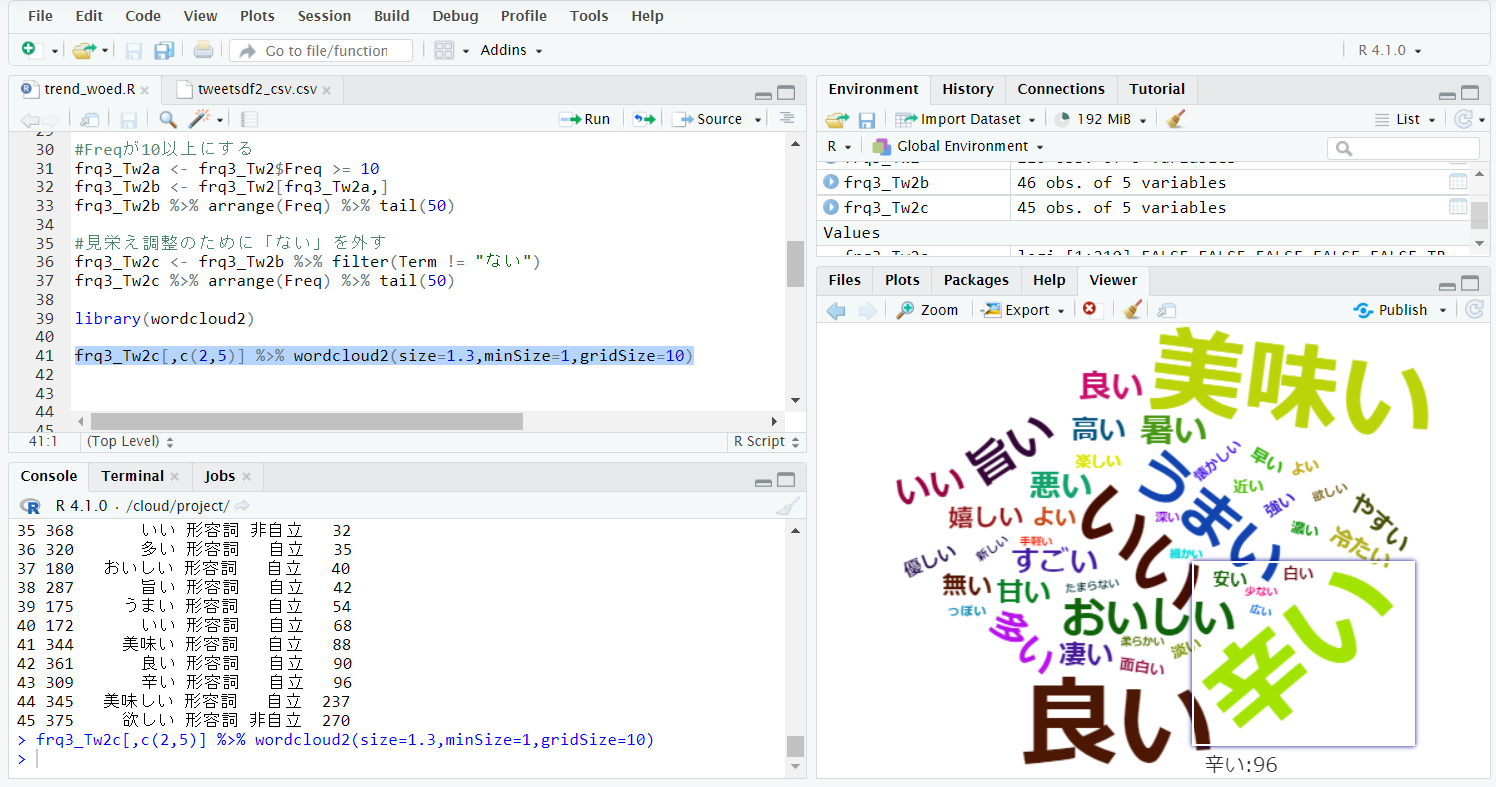
「Export」でHTMLとして出力します。
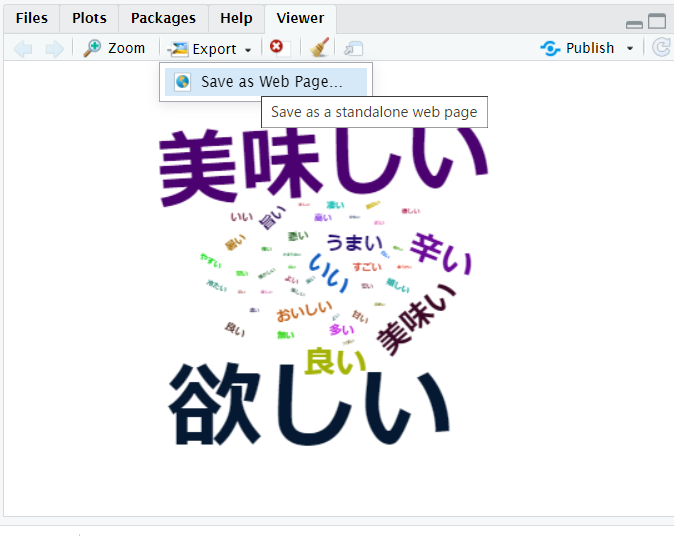
出力結果です。

了