Elastic Cloud on Kubernetes(ECK)がGAになった(なる予定)のでいろいろさわってみた
本記事はElasticsearchアドベントカレンダー(2019年)の24日目の記事です。
23日が空いてましたが、22日目は@hssh2_binさんによる「LogstashとFilebeatでIISログをあれこれしてみた話」でした。
このエントリは何か?(免責事項)
本記事はElastic Cloud on K8s(ECK)がバージョン1.0としてめでたくGAした?ことを記念するためにアドベントカレンダーにエントリしたものです。
2019/05/21に最初のリリースが行われ、0.8、0.9と順調に開発が進められ、1.0-betaのリリースが2019/10/14だったことから、まぁ遅くても2か月後、年内には1.0がGAするよね、と期待して意気込んでアドベントカレンダーにエントリしたのですが、、
2019/12/23時点では1.0 GAのアナウンスはされていません(涙)
このままだとアドベントカレンダーも取り下げか、、と思ったのですが、昨日Githubを見に行ったところ、
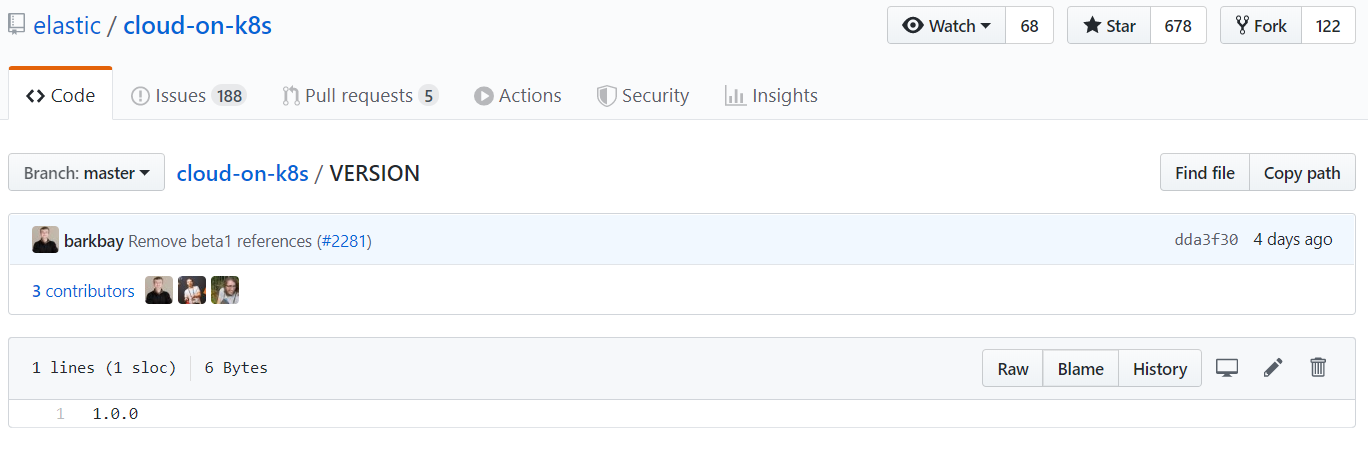
なんと、4日前(12/18)にVERSIONファイルだけひっそりと1.0-betaから1.0に更新されてました(歓喜)
ただし、まだREADMEも1.0-betaのままですしアナウンスもされてないので、もろもろ調整などをしているのだとは思いますが、時間の問題かと勝手に思っています。
ということで、気持ち的にはGAしたつもりで書きすすめていきますのでおつきあいください。
(注意)本エントリはECK 1.0-betaの内容をもとにしています。1.0 GA時点で一部内容が異なる可能性がある点ご了承ください。
はじめに
Elasticsearchは全文検索以外にもインフラのログ、アクセスログによる分析などここ数年で非常にユースケースが幅広くなってきました。
それにともない、Elasticsearchの環境を構築するにもバリエーションが増えてきました。OS上にパッケージインストールする以外にも、Dockerコンテナで起動したり、SaaSとしてのElasticCloudも運用負荷のオフロードという観点で非常に便利です。
今年に入り、kubernetes(以下、k8s)環境上でElasticsearchやKibanaをOperator経由で管理できるElastic Cloud on K8s(ECK)が新しい選択肢として登場しました。Operatorとはk8s上でのインフラ運用を抽象的なリソースとして扱い、自動化するための仕組みです。これにより、k8s環境上でElasticsearchやKibanaを簡単にインストールしたり、ノードスケールアウトやバックアップといった運用作業もすべて自動化が可能になります。
ECKを使うことで、Elasticsearch/Kibanaの環境を少し触ってみたいような場合にも、一からインストールをしなくてもすぐにセットアップができますし、利用者・テナントごとに必要に応じてアドホックにElasticsearch環境を作ったり消したりするという使い方もできます。従来、社内をまたいで共通基盤的にElasticsearchクラスタを管理していたような組織でも、ECKによりサービス開発チームごとに個別のクラスタを立てるという形が今後主流になるかもしれません。
少し前置きが長くなりましたが、ここではECKの簡単な使い方について紹介します。
前提
お手元にk8s環境がある前提とします。パブリッククラウドではいくつかマネージドなk8sサービスがありますので手軽に試す場合は利用を検討してみてください。
今回はAzureが提供するAKS(Azure Kubernetes Service)を使って動作確認をしています。
手元にk8s環境を準備するのが難しい、あるいは、もっと簡単に試してみたいという方も多いかと思いますので、本稿の最後にブラウザベースでECKが試せる方法もご紹介していますので、よろしければ見てみてください。
各種リソース(リポジトリ、ドキュメント)
ECKはgithub上でコードが公開されています。
https://github.com/elastic/cloud-on-k8s
ドキュメントもelasticsearchと同じくサイトにホスティングされています。(ちなみに、ドキュメントとしては1.0バージョンもすでに公開されています。)
https://www.elastic.co/guide/en/cloud-on-k8s/1.0-beta/k8s-overview.html
なお、AKSを利用するための端末環境ですが、AzureですとAzure Portalからすぐ使えるCloud Shellが便利です。初期状態でkubectlコマンド、azコマンドがインストール済になっています。利用方法は以下のドキュメントを参考にしてください。
https://docs.microsoft.com/ja-jp/azure/aks/kubernetes-walkthrough
利用環境
| product | version |
|---|---|
| AKS | 1.15.5 |
| kubectl | 1.16.0 |
| ECK | 1.0-beta |
| Elasticsearch | 7.5.1 |
| Kibana | 7.5.1 |
導入手順
手順の概要は以下の通りです。
1. AKSのセットアップ
2. k8s環境へのECK Operatorのインストール
3. Operator経由でElasticsearchリソースをデプロイ
4. Operator経由でElasticsearchクラスタとKibanaをデプロイ
5. アクセス確認
1. AKSのセットアップ
AKSクラスタをセットアップする手順の例を以下にまとめますので、参考にしてみてください。
リソースグループ名やクラスタ名、サブネットのCIDRなど、必要に応じて変更してください。
また、リージョンは東日本を指定していますが、AKSはリージョンごとに利用できるk8sのバージョンが異なる場合がありますので、ご注意ください。(az aks get-versions --location japaneastなどとすると確認できます)
## ログイン
$ az login
## リソースグループの作成
$ az group create --name akstest01rg --location japaneast
## 仮想ネットワークとサブネットの作成
$ az network vnet create \
--name aksVNet \
--resource-group akstest01rg \
--address-prefixes 10.0.0.0/8 \
--subnet-name aksSubNet \
--subnet-prefixes 10.1.0.0/16 \
--location japaneast
## AKS を所属させるサブネットリソースID の取得
$ VNET_SUBNET_ID=$(az network vnet subnet list \
--resource-group akstest01rg \
--vnet-name aksVNet \
--query [].id --output tsv)
## AKSクラスタの作成
$ az aks create --resource-group akstest01rg \
--name aks01 \
--network-plugin azure \
--vnet-subnet-id ${VNET_SUBNET_ID} \
--docker-bridge-address 172.17.0.1/16 \
--dns-service-ip 10.0.0.10 \
--service-cidr 10.0.0.0/16 \
--node-count 3 \
--kubernetes-version 1.15.5 \
--generate-ssh-keys
## クレデンシャル情報の登録
$ az aks get-credentials --resource-group akstest01rg --name aks01
Merged "aks01" as current context in /home/USER/.kube/config
## ノード確認
$ kubectl get node
NAME STATUS ROLES AGE VERSION
aks-nodepool1-18086731-0 Ready agent 3d17h v1.15.5
aks-nodepool1-18086731-1 Ready agent 3d17h v1.15.5
aks-nodepool1-18086731-2 Ready agent 3d17h v1.15.5
2. k8s環境へのECK Operatorのインストール
k8s環境にECK Operatorを次の手順でインストールします。基本的にkubectl applyコマンド1つでインストールが完了します。便利ですね。
$ kubectl apply -f https://download.elastic.co/downloads/eck/1.0.0-beta1/all-in-one.yaml
customresourcedefinition.apiextensions.k8s.io/apmservers.apm.k8s.elastic.co created
customresourcedefinition.apiextensions.k8s.io/elasticsearches.elasticsearch.k8s.elastic.co created
customresourcedefinition.apiextensions.k8s.io/kibanas.kibana.k8s.elastic.co created
clusterrole.rbac.authorization.k8s.io/elastic-operator created
clusterrolebinding.rbac.authorization.k8s.io/elastic-operator created
namespace/elastic-system created
statefulset.apps/elastic-operator created
serviceaccount/elastic-operator created
$
CRD(カスタムリソース定義)、Operatorが動くためのnamespace、サービスアカウントとRBAC定義が作られ、続けてOperator用Pod(Statefulset)も起動します。
以下のコマンドでOperatorが起動していることを確認しておきます。
$ kubectl get all -n elastic-system
NAME READY STATUS RESTARTS AGE
pod/elastic-operator-0 1/1 Running 0 2m25s
NAME READY AGE
statefulset.apps/elastic-operator 1/1 2m26s
この時点で、環境がどのような状態になっているかを以下の図で示します。これはElastic社の方が先月Barcelona k8s meetupで発表された資料をお借りしています。
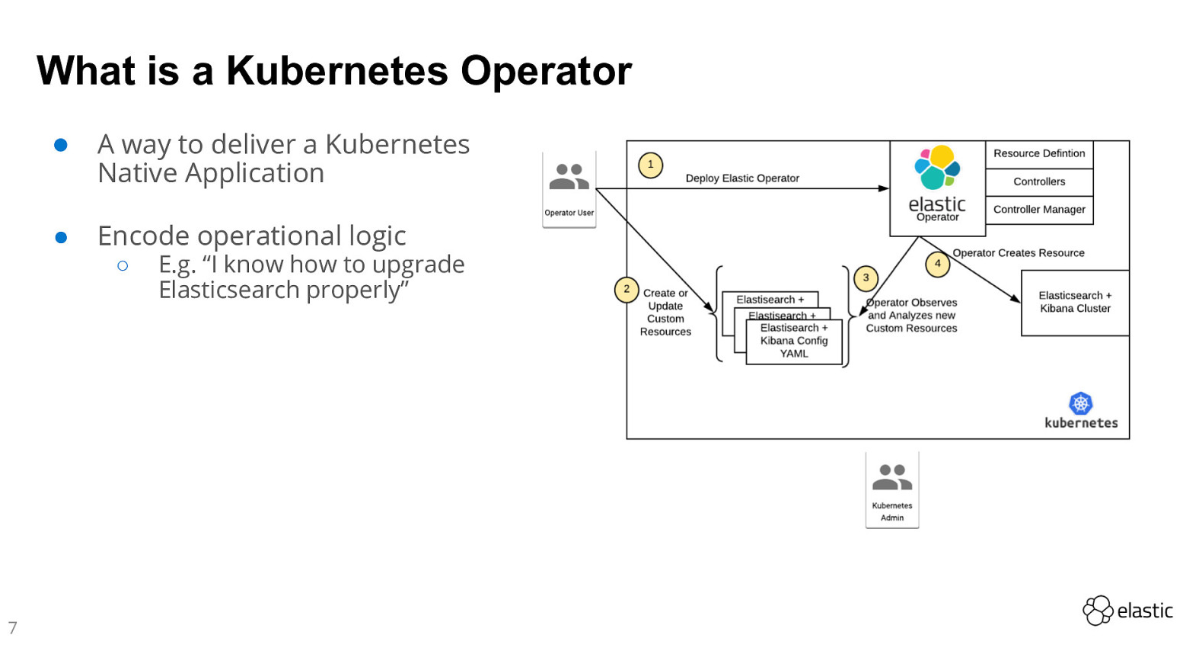
Operatorをインストールした現時点では図の①が完了した状態になります。カスタムリソース定義(CRD)とそれを制御するPodが稼働しています。この後、利用者が個別にリソースリクエストをyamlで投げると(②)、コントローラが動作して(③)、よしなにリソース(ElasticsearchクラスタやKibana)をデプロイ(④)してくれます。
以降では、この②③④の動きをみていきましょう。
3. Operator経由でElasticsearchリソースをデプロイ
Operatorが稼働していれば、いつでもElasticsearch、Kibanaのリソースがデプロイ可能です。さっそく、試しに1環境デプロイしてみます。
リソースデプロイには、リソースを定義したyaml(カスタムリソース定義)を作ります。以下が一例です。
apiVersion: elasticsearch.k8s.elastic.co/v1beta1
kind: Elasticsearch
metadata:
name: quickstart
spec:
version: 7.5.1
nodeSets:
- name: default
count: 1
config:
node.master: true
node.data: true
node.ingest: true
node.store.allow_mmap: false
ここでは、Master兼Data兼Ingestノードを1台構成しようとしています。バージョンは7.5.1ですね。
「kind: Elasticsearch」と書いてある箇所に注目してください。通常のk8sではこのようなリソース種別はないのですが、Opeartorをインストールする際に、CRD(カスタムリソース定義)としてこれらのカスタムリソースを追加したため、利用者が「kind: Elasticsearch」という抽象化されたリソースをリクエストして使うことができます。
従来利用者はElasticsearchのインストール手順に従ってセットアップを行っていましたが、k8s環境+ECKではこれらがすべてyamlファイルでセットアップできることになります。
それではこのリソース定義ファイルを使って実際にデプロイを行います。
$ kubectl apply -f quickstart.yaml
elasticsearch.elasticsearch.k8s.elastic.co/quickstart created
$
実際にどのようなリソースが作られたのかを確認してみます。
$ kubectl get all
NAME READY STATUS RESTARTS AGE
pod/quickstart-es-default-0 1/1 Running 0 11m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 3d19h
service/quickstart-es-default ClusterIP None <none> <none> 11m
service/quickstart-es-http ClusterIP 10.0.110.167 <none> 9200/TCP 11m
NAME READY AGE
statefulset.apps/quickstart-es-default 1/1 11m
Elasticsearchノード用のStatefulSetが定義され、それに従ってPodが1つ起動しています。また、9200ポートにアクセスするためのserviceリソースも作成されています。
なお、このリソースは何も考えずにdefaultネームスペースにデプロイしたために、service/kubernetesなどのリソースと同居してしまっています。この後のサンプルでは新たにネームスペースを作成して、その上にデプロイしたいと思います。
「kind: Elasticsearch」として作成したリソースは次のコマンドでステータス確認をすることもできます。1ノードクラスタが状態greenで稼働していることがわかります。
$ kubectl get elasticsearch
NAME HEALTH NODES VERSION PHASE AGE
quickstart green 1 7.5.1 Ready 8m59s
$
リソースを削除したい場合には、kubectl deleteコマンドを使います。リソース名として「kind名/インスタンス名」を指定して次のように実行します。
$ kubectl delete elasticsearch/quickstart
elasticsearch.elasticsearch.k8s.elastic.co "quickstart" deleted
$
4. Operator経由でElasticsearchクラスタとKibanaリソースをデプロイ
次にもう少し実践的な内容を試してみるために、以下の要件を考えます。
- Elasticsearchリソースを展開するための専用ネームスペースを作る
- ElasticsearchクラスタをMaster/Data分離構成で作る
- 可用性を考えてMasterを3ノード構成、Dataを2ノード構成にする
- 上記Elasticsearchに接続するKibanaをデプロイする
- AKS外部からアクセスできるよう外部ロードバランサからのアクセス経路を設定する
順を追って作業していきます。
- Elasticsearchリソースを展開するための専用ネームスペースを作る
$ kubectl create namespace myeckns
namespace/myeckns created
$
- ElasticsearchクラスタをMaster/Data分離構成で作る
- 可用性を考えてMasterを3ノード構成にする
- AKS外部からアクセスできるよう外部ロードバランサからのアクセス経路を設定する
これは以下のようにyamlファイル内ですべて定義ができます。
apiVersion: elasticsearch.k8s.elastic.co/v1beta1
kind: Elasticsearch
metadata:
name: myeck
namespace: myeckns
spec:
version: 7.5.1
nodeSets:
- name: master
count: 3
config:
node.master: true
node.data: false
node.ingest: false
node.store.allow_mmap: false
- name: data
count: 2
config:
node.master: false
node.data: true
node.ingest: true
node.store.allow_mmap: false
http:
service:
metadata: {}
spec:
type: LoadBalancer
少し細かい説明になりますが、"spec.nodeSets"でロール別のノードグループが定義できて、さらに"spec.nodeSets.config"以下にどのロールを持たせるかをtrue/falseで指定できます。ここでは、masterのみtrueのノードを3ノード、data/ingestがtrueのノードを2ノードずつ構成しています。
一番下にはこのクラスタに関連づけるserviceリソースのカスタム定義をしており、AKSで"type: LoadBalancer"を指定することで外部のAzure LoadBalancerを紐づけることができるようになっています。
なお、「version: 7.5.1」とある箇所がElasticsearchのバージョンを指定できる属性ですが、2019/12/22現在で7.6.0のdockerイメージは取得できない(リリースされてない)ため、7.5.1を使っています。
$ sudo docker image pull docker.elastic.co/elasticsearch/elasticsearch:7.6.0
Error response from daemon: manifest for docker.elastic.co/elasticsearch/elasticsearch:7.6.0 not found
$
以下のコマンドでこのリソースを作成してみます。
$ kubectl apply -f myes.yaml
elasticsearch.elasticsearch.k8s.elastic.co/myeck created
$
リソースの確認をする際は、"-n"オプションを付けて明示的にネームスペースを指定する必要がある点に注意してください。
$ kubectl get all -n myeckns
NAME READY STATUS RESTARTS AGE
pod/myeck-es-data-0 1/1 Running 0 7m37s
pod/myeck-es-data-1 1/1 Running 0 7m36s
pod/myeck-es-master-0 1/1 Running 0 7m37s
pod/myeck-es-master-1 1/1 Running 0 7m37s
pod/myeck-es-master-2 1/1 Running 0 7m37s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/myeck-es-data ClusterIP None <none> <none> 7m37s
service/myeck-es-http LoadBalancer 10.0.125.221 138.91.14.xx 9200:31475/TCP 7m38s
service/myeck-es-master ClusterIP None <none> <none> 7m37s
NAME READY AGE
statefulset.apps/myeck-es-data 2/2 7m37s
statefulset.apps/myeck-es-master 3/3 7m37s
$
外部ロードバランサーからアクセスできるようにもなったため、試しにElasticsearchクラスタの9200ポートにアクセスしてみましょう。
ECKではデフォルトでsecurityが有効化されているため、elasticユーザのパスワードを取得する必要があります。パスワードはk8sのsecretリソースにbase64エンコードされていますので、以下のコマンドで取得します。
$ kubectl get secret -n myeckns
NAME TYPE DATA AGE
default-token-2qx47 kubernetes.io/service-account-token 3 27m
myeck-es-data-es-config Opaque 1 10m
myeck-es-elastic-user Opaque 1 10m ★ここに格納されている★
myeck-es-http-ca-internal Opaque 2 10m
myeck-es-http-certs-internal Opaque 3 10m
myeck-es-http-certs-public Opaque 2 10m
myeck-es-internal-users Opaque 3 10m
myeck-es-master-es-config Opaque 1 10m
myeck-es-transport-ca-internal Opaque 2 10m
myeck-es-transport-certificates Opaque 13 10m
myeck-es-transport-certs-public Opaque 1 10m
myeck-es-xpack-file-realm Opaque 3 10m
$
$ PASSWORD=$(kubectl get secret myeck-es-elastic-user -n myeckns -o=jsonpath='{.data.elastic}' | base64 --decode)
$ echo $PASSWORD
44gkrmqh75lnzx8p7ppsgcbg
$
elasticユーザのパスワードが変数PASSWORDに格納されましたので、以下のコマンドでcurlアクセスを行います。
$ curl -u "elastic:$PASSWORD" -k https://138.91.14.xx:9200
{
"name" : "myeck-es-data-1",
"cluster_name" : "myeck",
"cluster_uuid" : "o9GKgJVDTTOOIJO8v_bbGQ",
"version" : {
"number" : "7.5.1",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "3ae9ac9a93c95bd0cdc054951cf95d88e1e18d96",
"build_date" : "2019-12-16T22:57:37.835892Z",
"build_snapshot" : false,
"lucene_version" : "8.3.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
$ curl -u "elastic:$PASSWORD" -k https://138.91.14.xx:9200/_cat/nodes
10.1.0.88 6 91 5 0.14 1.03 0.83 lm - myeck-es-master-2
10.1.0.96 9 91 5 0.14 1.03 0.83 dil - myeck-es-data-0
10.1.0.30 11 97 6 0.16 0.25 0.31 lm * myeck-es-master-1
10.1.0.41 7 96 9 0.24 0.47 0.54 dil - myeck-es-data-1
10.1.0.37 11 96 9 0.24 0.47 0.54 lm - myeck-es-master-0
$
- 上記Elasticsearchに接続するKibanaをデプロイする
Kibanaのデプロイも試してみます。yamlは同じように以下カスタムリソース(「kind: Kibana」)として定義します。一つポイントになるのは"spec.elasticsearchRef.name"がmyeckとなっている点で、これは上記のElasticsearchリソースのnameと一致させる必要があります。これでkibanaの接続先Elasticsearchが紐づけされるためです。
apiVersion: kibana.k8s.elastic.co/v1beta1
kind: Kibana
metadata:
name: myeck
namespace: myeckns
spec:
version: 7.5.1
count: 1
elasticsearchRef:
name: myeck
http:
service:
metadata: {}
spec:
type: LoadBalancer
しばらく待った後、リソース確認をしてみます。Elasticsearchクラスタと合わせるとかなり多くのリソースがデプロイできました。
$ kubectl get all -n myeckns
NAME READY STATUS RESTARTS AGE
pod/myeck-es-data-0 1/1 Running 0 24m
pod/myeck-es-data-1 1/1 Running 0 24m
pod/myeck-es-master-0 1/1 Running 0 24m
pod/myeck-es-master-1 1/1 Running 0 24m
pod/myeck-es-master-2 1/1 Running 0 24m
pod/myeck-kb-5c846f465c-9jbk9 1/1 Running 0 6m49s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/myeck-es-data ClusterIP None <none> <none> 24m
service/myeck-es-http LoadBalancer 10.0.125.221 138.91.14.xx 9200:31475/TCP 24m
service/myeck-es-master ClusterIP None <none> <none> 24m
service/myeck-kb-http LoadBalancer 10.0.170.36 13.78.26.xxx 5601:32406/TCP 6m50s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/myeck-kb 1/1 1 1 6m49s
NAME DESIRED CURRENT READY AGE
replicaset.apps/myeck-kb-5c846f465c 1 1 1 6m49s
NAME READY AGE
statefulset.apps/myeck-es-data 2/2 24m
statefulset.apps/myeck-es-master 3/3 24m
5. アクセス確認
さっそくKibanaにアクセスしてみます。アクセス先IPアドレスは、上記の"service/myeck-kb-http"リソースのEXTERNAL-IPにある"13.78.26.xxx"で、ポートは5601です。セキュリティが有効化されているため、httpsでアクセスする点に注意してください。

elasticユーザのパスワードは上記のPASSWORD変数に格納されていますので、以下のコマンドを使ってコピペしましょう。
$ echo $PASSWORD
44gkrmqh75lnzx8p7ppsgcbg
$
無事にKibanaにアクセスできました。
念のため、Monitoringでノード一覧も確認しておきます。
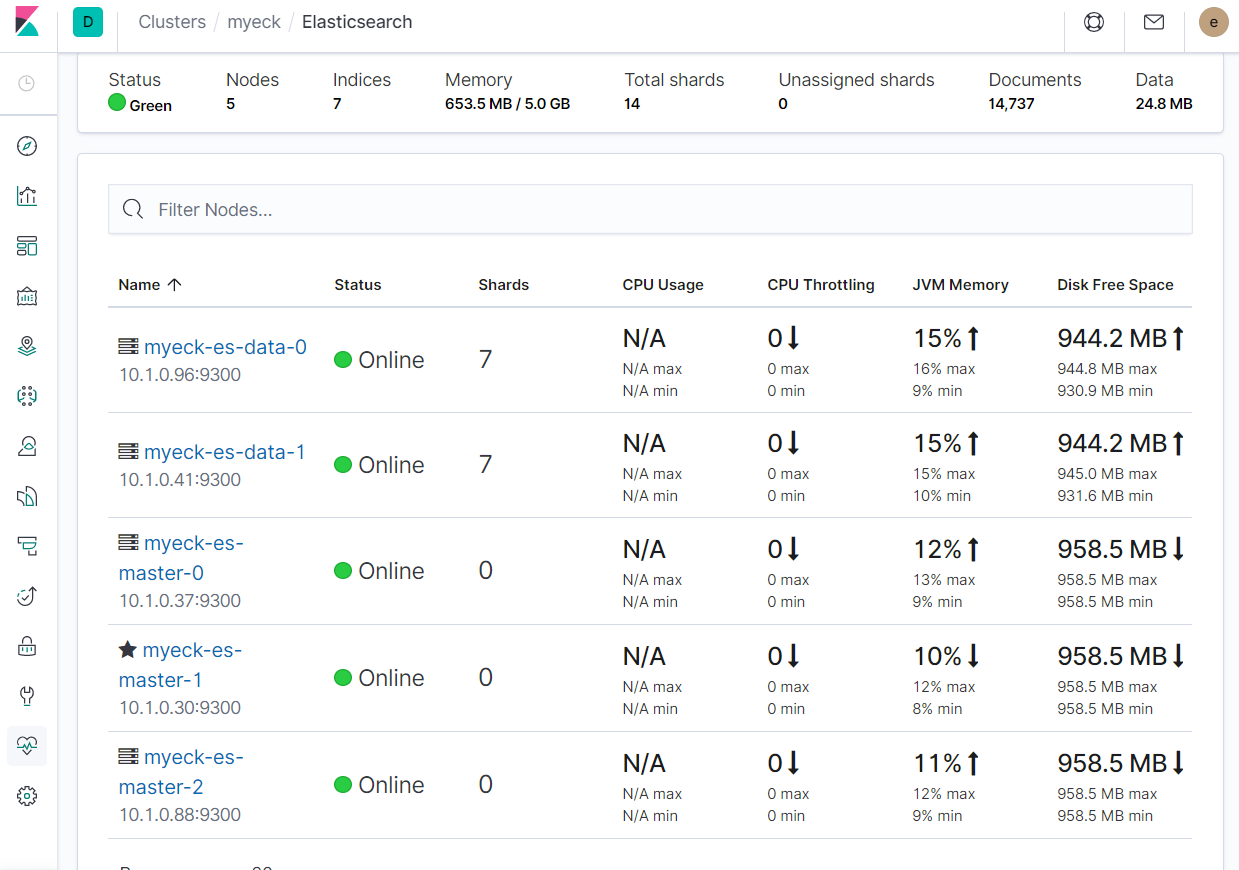
きちんと想定通りのMasterx3、Datax2になっています。シャード数が7+7になっているのは、サンプルデータをimportした後だからです。(ECK固有のshardがあるということではありません)
ECKの中身とできることについてもう少し
ここまではごく基本的なECKの使い方ですが、もう少しだけ具体的な構成や利用法について説明します。
1. StatefulSetの採用
ECKは初期リリースされた0.8バージョンでは、StatefulSetは使わずに、Operatorが直接Podを管理するアーキテクチャとなっていました。k8sでステートフルなワークロードを扱う際にStatefulSetリソースを利用すると、複数Pod利用時の起動・停止の順序やPVCのマッピングなどの考慮をk8s側が巻き取ってくれるため、他の多くのOperatorではStatefulSetを採用していました。
しかし、ECKでは各ノードがさまざまなロールやスペックを持つ構成がありえるため、StatefulSetのような一意なPodグループでひとくくりに管理する仕組みに当てはめにくく、また、upgradeやノード拡張などの細かなコントロール・配慮が必要なケースでStatefulSetが扱いにくいことから、まずはStatefulSet採用を見送りました。このあたりの経緯はver0.8のころのgithub上のdesign discussionとしてまとまっていて非常に興味深いので参考までにURLをあげておきます。
- StatefulSet of Custom controller
1.0-betaからはクラスタ内でも同一タイプごとにnodeSetsというグループでまとめて、それぞれStatefulSetとして扱うことにしました。このため、MasterはMaster、DataはDataそれぞれのStatefulSetがPodを管理するというアーキテクチャになっています。
$ kubectl get statefulset -n myeckns
NAME READY AGE
myeck-es-data 2/2 72m
myeck-es-master 3/3 72m
$
ここでそれぞれのStatefulSetはyaml定義内のnodeSetsの各グループに対応しています。
実はStatefulSetを採用したことで、ノードのupgradeなどコンテナイメージを差し替える際の所要時間が大幅に短縮できるようになりました。
理由は、StatefulSetにはノード固有のPVC(Persistent Volume Claim)を割り当てる(bind)することができ、永続データは基本的にPV上に格納されることから、コンテナが再起動したり、upgradeなどで新規イメージに更新された際にも、PVCデータは再利用ができるためです。
実際にStatefulSetに属する各々のPodがPVCを持っている様子を確認してみましょう。
$ kubectl get pvc -n myeckns
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
elasticsearch-data-myeck-es-data-0 Bound pvc-ddd1efc1-7a2b-4d7d-8c83-cf9d1205c7cb 1Gi RWO default 78m
elasticsearch-data-myeck-es-data-1 Bound pvc-461de1a1-6ce4-4241-8e94-33bfee7df8ab 1Gi RWO default 78m
elasticsearch-data-myeck-es-master-0 Bound pvc-df8174fd-52a1-4deb-9ebc-d9615abc1603 1Gi RWO default 78m
elasticsearch-data-myeck-es-master-1 Bound pvc-ccf71a3c-9428-4e1d-ab16-fe2498ade35b 1Gi RWO default 78m
elasticsearch-data-myeck-es-master-2 Bound pvc-97a9ba87-855b-4157-a074-42a7679ed9fa 1Gi RWO default 78m
$
このように、各Podごとに自分専用のPVCを持っており(サイズはデフォルトで1GB)、コンテナの再起動、差し替えに関わらず再利用されます。
StatefulSetの採用前は、コンテナの差し替え時にデータ領域を引き継げずに、都度他ノードからのデータ同期が必要でしたが、この問題が改善できています。
2. ノード構成のカスタマイズ
導入方法の説明時に、yamlファイルにノード数やノード種別(ロール)を指定することで複数ノード構成がとれることを紹介しましたが、ここではもう少し一般的なノード構成のカスタマイズ方法を紹介します。
- "elasticsearch.yaml"に記載していた設定パラメータ
- 実は"spec.nodeSets.config"以下にそのまま従来使っていたelasticsearch.yamlファイルの設定を書くことができます。以下は一例です。
spec:
nodeSets:
- name: mlenabled-nodes
count: 3
config:
node.master: true
node.data: true
node.ingest: true
node.ml: true
xpack.ml.enabled: true
cluster.remote.connect: false
- JVMヒープサイズ
- ヒープサイズの設定もconfig以下に書きたいところですが、これは環境変数ですので、コンテナ設定のenv属性で指定する必要があります(指定がない場合のデフォルト値は1Gです)
- さらに、この設定をする場合、resources句を用いて、PodにおけるCPU、メモリリソースの制限を明記することをおすすめします
spec:
nodeSets:
- name: node-with-jvmheapsetting
count: 1
podTemplate:
spec:
containers:
- name: elasticsearch
env:
- name: ES_JAVA_OPTS
value: "-Xms4g -Xmx4g"
resources:
requests:
memory: 8Gi
cpu: 0.5
limits:
memory: 8Gi
cpu: 2
- ボリュームサイズの指定
- デフォルトでは"default"ストレージクラスから1GiのPVCを割り当てようとします
- これを変更したい場合、同じようにspec以下に指定します
- metadata.nameの値は"elasticsearch-data"で固定です(注意:名前をこれ以外に変更してはいけません)
- 自前のk8s環境で要件に合わせたストレージクラスを用意している場合はstorageClassNameに明示的に指定して使い分けることが可能です
spec:
nodeSets:
- name: data-with-big-and-fast-volume
count: 3
volumeClaimTemplates:
- metadata:
name: elasticsearch-data ★★注意:この値はelasticsearch-dataから変更不可★★
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
storageClassName: superfast-ssd
- スケールアウト・スケールイン
- ノード拡張したい場合、元のyamlの定義"spec.nodeSets.count"を編集して"kubectl apply"します
- ノード縮退についても同じです
- (注意)StatefulSetを使っていることから、以下のコマンドでノード拡張したくなりますが、StatefulSetのコントロールはすべてOperatorが掌握しているため、このコマンドは無視されますので、上記の方法でノード拡張をしてください(※厳密に言うと、replicasが一瞬3になりますが、すぐにOperatorがあるべき設定値(=desired state)である2に戻してしまいます)
$ kubectl scale statefulsets myeck-es-data --replicas=3 -n myeckns
statefulset.apps/myeck-es-data scaled
$ kubectl get statefulset -n myeckns
NAME READY AGE
myeck-es-data 2/2 105m ★★レプリカ数を3にしたが無視されている★★
myeck-es-master 3/3 105m
$
-
Elasticsearch/Kibanaのバージョンアップ
- ノード拡張と同様で、yaml定義ファイルのspec.versionの値を編集して"kubectl apply"します
- 基本的な動作としては、既存コンテナは破棄されて、新規コンテナが起動します(ただし、PVC/PVは引き継げるためコンテナ起動時間だけ待てばOKです)
- バージョンダウンはできない仕様となっています
-
ノードスケジューリング制御
- Masterノードなどクラスタ可用性を担うロールのノードはk8sクラスタの同一ノードで起動しないように制御したい場合があります
- ECKではデフォルトで「できるだけ」同じロールのノードは別ホストでスケジューリングされるようになっています
- デフォルトスケジューリングポリシーを変更して、たとえば「必ず」別ホストでスケジュールさせることも可能です
spec:
nodeSets:
- name: antiaffinity-nodes
count: 3
podTemplate:
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution: ★★同一ホストでの起動を禁止★★
- podAffinityTerm:
labelSelector:
matchLabels:
elasticsearch.k8s.elastic.co/cluster-name: myeck
topologyKey: kubernetes.io/hostname
上記の例ではk8sホスト名を基準として、このnodeSets(同一ロールのノードグループ)は同一ホスト上では起動させないようにスケジュールしています(podAntiAffinityで"requiredDuringSchedulingIgnoredDuringExcecution"を指定)
Pod数は3としていますので、もしk8sホストが2ノードしかなければ、3番目のPodがPending状態のまま起動ができなくなります。
デフォルトでは"prefferedDuringSchedulingIgnoredDuringExcecution"のポリシーとなっており、この場合、他ノードでどうしても起動できなければ同一ホストでも起動を許可する動きとなります。
- プラグインインストール
- kuromojiなど追加でプラグインをインストールするには、コンテナ起動時にinitContainerでplugin-installコマンドを実行するという手順をふみます
apiVersion: elasticsearch.k8s.elastic.co/v1beta1
kind: Elasticsearch
metadata:
name: myeck
namespace: myeckns
spec:
version: 7.5.1
nodeSets:
- name: default
count: 3
config:
node.master: true
node.data: true
node.ingest: true
node.store.allow_mmap: false
podTemplate:
spec:
initContainers:
- name: install-plugins
command:
- sh
- -c
- |
bin/elasticsearch-plugin install --batch analysis-kuromoji ★★ここでインストール★★
http:
service:
metadata: {}
spec:
type: LoadBalancer
きちんとインストールできたかを確認するには以下のコマンドを実行します。指定したkuromojiプラグインが正しくインストールされています。
$ curl -u "elastic:$PASSWORD" -k https://<LBのIP>:9200/_cat/plugins
myeck-es-default-0 analysis-kuromoji 7.5.1
myeck-es-default-1 analysis-kuromoji 7.5.1
myeck-es-default-2 analysis-kuromoji 7.5.1
$
以上、ここまでECKの導入方法、カスタマイズ方法など説明してきました。おおよその内容は公式ドキュメントにも詳細に説明がありますので、上記を読んでざっくり理解してから参考にしていただくと、キャッチアップが短期間でできるかと思います。
One more thing...
ここまで手元のk8s環境でECKを使う手順をご紹介してきましたが、k8s環境なんてすぐに準備できないよ、という方も多くいらっしゃるとは思います。
そこで、いままでご説明してきた内容がほぼブラウザ上で体験できるkatakodaのシナリオを見つけることができましたので、こちらをぜひお試しください。
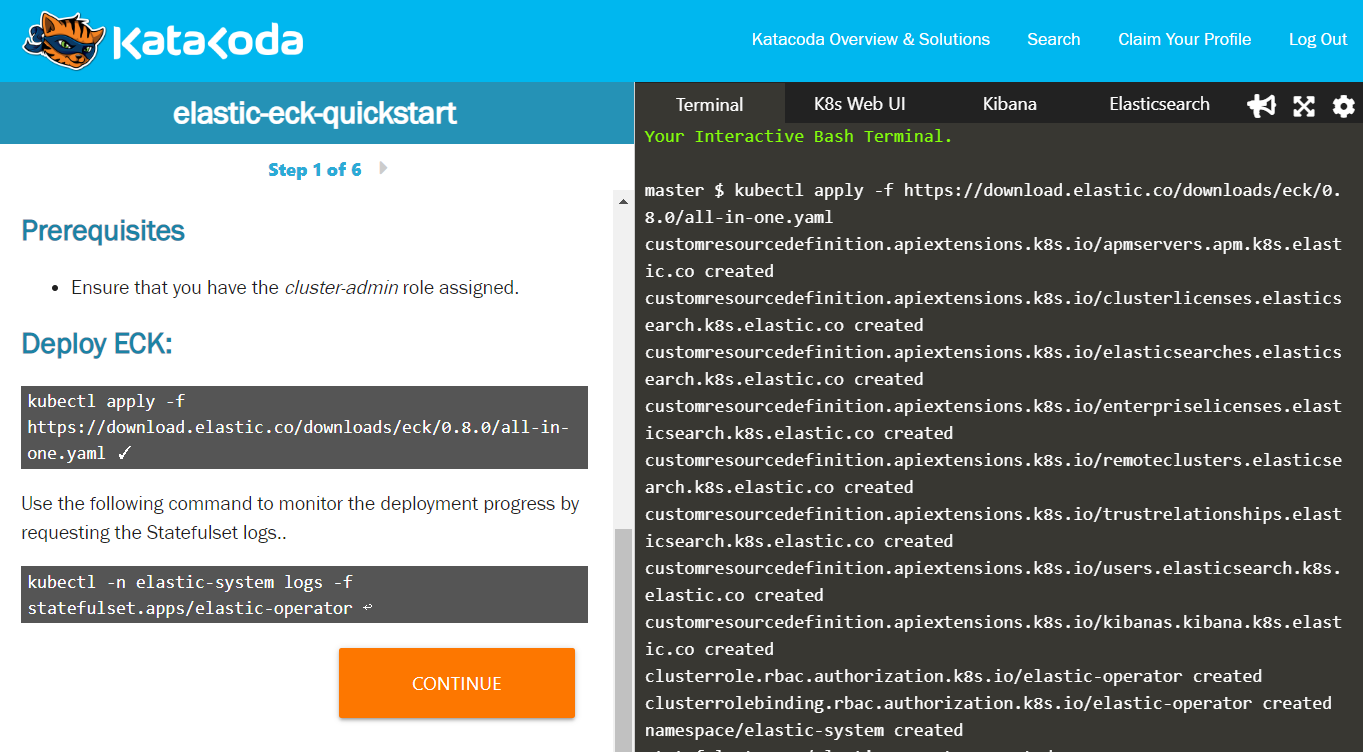
- katakoda: elastic-eck-quickstart
ブラウザだけでECKのチュートリアルが10分程度で一通り体験できます。すばらしい。
左側ペインには(英語ですが)説明文と実行するコマンドが表示されています。右側ペインはコンソールになっていて、コマンドは直接入力しなくても、左側ペインのコマンドウインドウをクリックすると自動でタイプ&実行されます。
少し内容が古めなのでECKも0.8、Elasticsearchも7.1か7.2だったと思いますが、手を動かして理解する目的であれば十分な内容だと思いました。
まとめ
ここではECK(Elastic Cloud on K8s)がGAになったつもりで、導入方法からいくつかの使い方をご紹介しました。今後はElasticsearchを必要なときにすぐ立ち上げるといったCloud-likeな使い方が増えてくるだろうと考えていますが、ECKがその一助になれればと思っています。
2019年のElasticStackアドベントカレンダー(その1)の最後は@amanekeyさんです!!