
概要
SalesforceもPower BIも職人芸なところがあり、Pythonでデータ分析・予測を行う人からは手を出しにくい(あまり余計な技を覚えたくない)かと思いますが、蓋を開けてみるとPythonコードで全て料理できたので、記録しておきます。
事前に
Power BI Desktopを使うのでWindowsです。
pyenv-winでversion管理していたらPower BI謎エラー沼にはまったので、MS StoreでPython 3.8を入れました。3.9だとcdataが入りません。
Power BI大人事情により、numpyもversion指定です。
> pip install seaborn sqlalchemy numpy==1.19.3
SalesforceデータをDataframeで抜いてくる
SFDCプロジェクトでは、古来よりDataloaderを使ってcsvを落としたり、$sfdxしてきたかもしれませんが、もう不要です。数行のコードでDataframeが作れます。
import cdata.salesforce as mod
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine("salesforce:///?User=a@b.com;Password=xxx;SecurityToken=yyy;")
df = pd.read_sql("SELECT Column1, Column2 FROM Object1;", engine)
cdataの入れ方
☟こちらからwhlを落としてpipします。
https://www.cdata.com/jp/drivers/salesforce/python/
> pip install ~/Downloads/CData.Python.Salesforce/win/Python38/cdata_salesforce_connector-20.0.7654-cp38-cp38-macosx_10_9_x86_64.whl
SecurityToken 取り方☟(お借りします)
Salesforceコネクタをあえて使わないでデータ取得する
真っ当にコネクタを使うところを☟
☟あえてスクリプトで取り込みます。
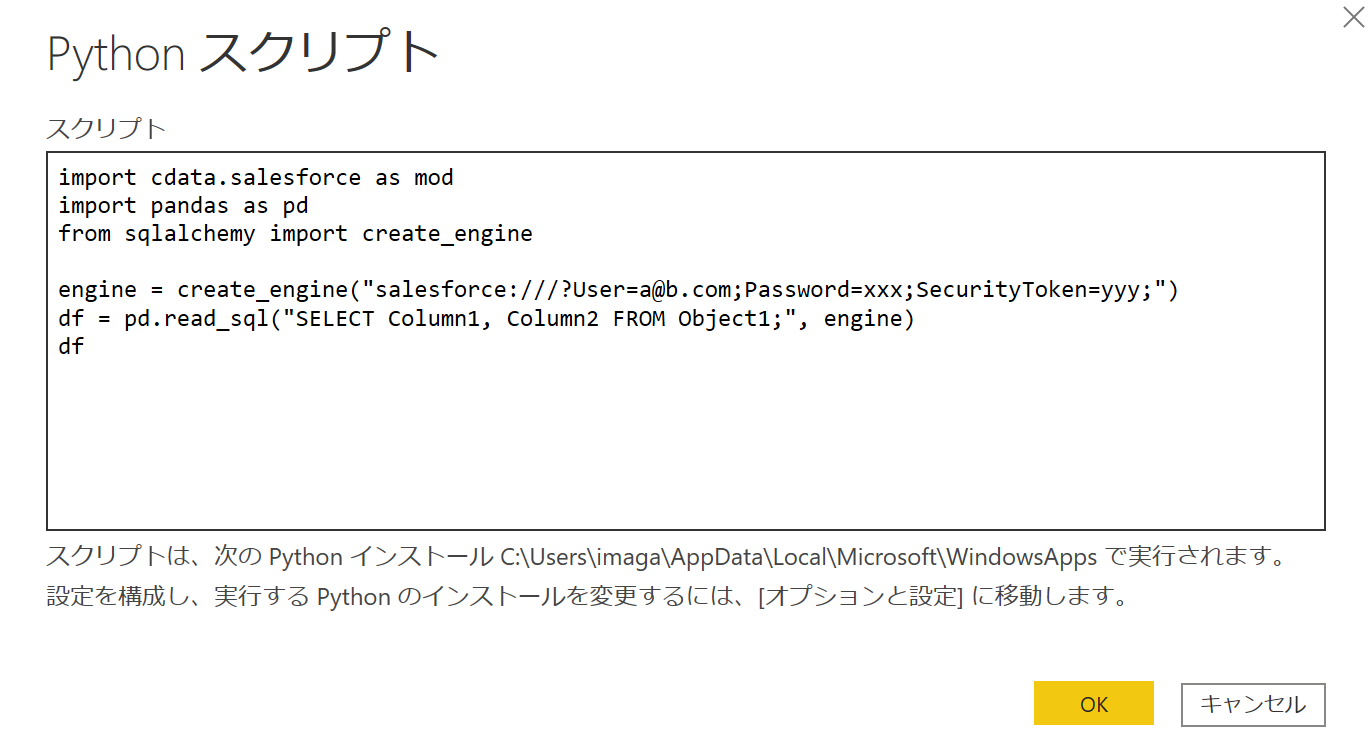
☟先ほどのスクリプトを入れて、最後にdfを加えます。(公式docはprint(df)ですが、間違えたら通りました)
何かメリットがあるのかという話ですが、強いて挙げるなら
- 必要なカラムだけとれる
- 事前に加工できる
- 設定変更をしないとコネクタが勝手にDatetimeを'月'カラム(String)等にしてしまうのを防げる
- 事前に手元で分析したPythonファイルをそのままコピペできる
ことでしょうか。
Python Visualを使う
☟VisualizationsからPyを選びます。
☟使うカラムをチェックします。
☟スクリプトエディタに☟☟のコードが現れるので加筆していきます。
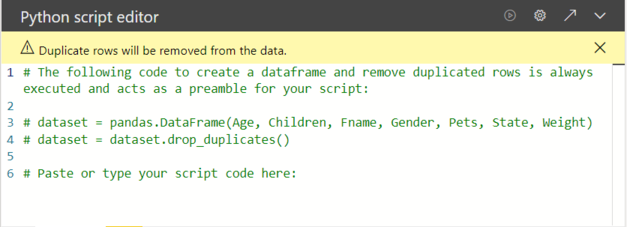
はじめからdatasetが用意されていて、最後にpyplot.show()をするとグラフが表示される仕様です。
エディタで開くボタンを押すとわかるのですが☟のコードが隠れています。
# Prolog - Auto Generated #
import os, uuid, matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot
import pandas
os.chdir(u'C:/Users/user/PythonEditorWrapper_e52c53d3-3ad9-4b06-9404-d671e336fb61')
dataset = pandas.read_csv('input_df_bc91c5f1-75c9-47a1-be02-0e0ad04c0b60.csv')
matplotlib.pyplot.figure(figsize=(5.55555555555556,4.16666666666667), dpi=72)
matplotlib.pyplot.show = lambda args=None,kw=None: matplotlib.pyplot.savefig(str(uuid.uuid1()))
# Original Script. Please update your script content here and once completed copy below section back to the original editing window #
# データフレームを作成して重複行を削除する次のコードは、常に実行され、スクリプトのプリアンブルとして機能します。
# dataset = pandas.DataFrame(Column1, Column2)
# dataset = dataset.drop_duplicates()
# スクリプトのコードをここに貼り付けるか入力します。
## ほげほげほげほげ
# Epilog - Auto Generated #
os.chdir(u'C:/Users/user/PythonEditorWrapper_e52c53d3-3ad9-4b06-9404-d671e336fb61')
ダミーdfを作ってグラフを表示
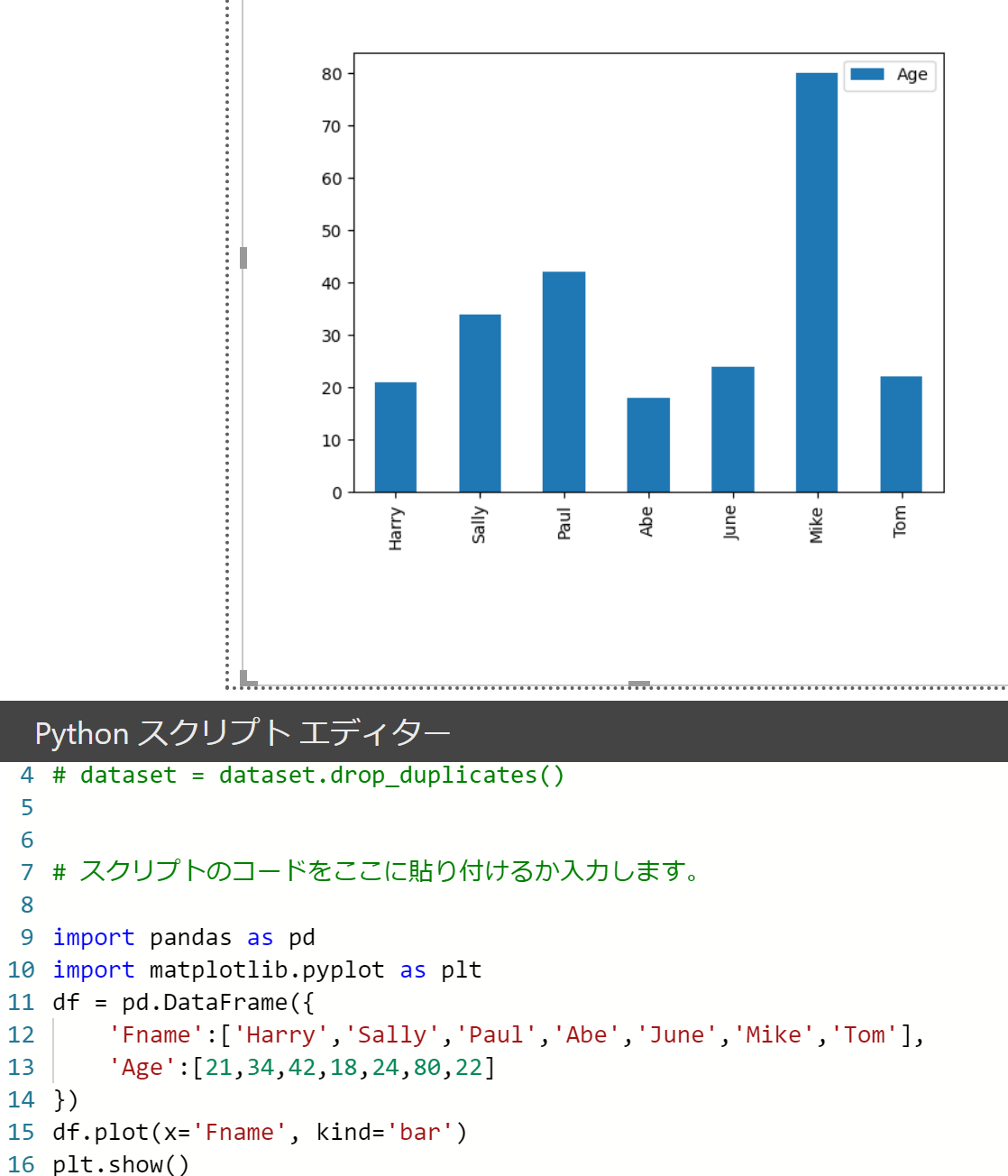
pdとpltは書きやすさのためにimportしています。
df = dataset等、前処理文を用意しておけば、手元のPythonコードをそのまま使えて大変便利です。
TIPS
日本語化(豆腐対策)
import matplotlib.font_manager as fm
from matplotlib import rcParams
fm.findSystemFonts()
rcParams['font.family'] = 'sans-serif'
rcParams['font.sans-serif'] = ['Hiragino Maru Gothic Pro', 'Yu Gothic', 'Meirio', 'Takao', 'IPAexGothic', 'IPAPGothic', 'Noto Sans CJK JP']
見た目
数値やラベルのサイズをPower BI用に調整しなければならないようで、ここでどうしても職人芸が必要とされてしまいますが、pyplot力の高い人にはハードルが低いと思います。
機械学習
scikit-learnやxgboostが使えるようなので、予測結果も併せて出力できそうですね。(まだ試し中)
https://docs.microsoft.com/en-us/power-bi/connect-data/service-python-packages-support