はじめに
前回は、下記のエントリーにて、Jupyter NotebookからDb2の表にデータを書き出す方法を試してみました。
Watson StudioのJupyter NotebookからDb2の表にデータ出力をする
今回は、IBM Cloudが提供するSQL QueryというサービスをJupyter Notebookで利用してみます。SQL Queryとは、ICOS(IBM Cloud Object Storage)上のファイルを簡単にSQLで検索することのできるサービスです。筆者のようにRDBやSQLに馴染みの深い方には、気軽にICOS上のファイルデータを加工して参照できる大変使い勝手の良いサービスだと思います。
当文書で示すシナリオ
当文書では以下のBlogで紹介している手順を実際にIBM Cloudに用意したWatson Studio, Object Storage, SQL Queryの環境で実施し、動作を確認します。いずれも無償のLiteプランです。
Analyzing Data with IBM Cloud SQL Query
このシナリオでは、ロサンジェルス警察管轄内で発生した交通事故のデータをSQL Queryを使って加工、集計し、MapboxのPixieDustを使って、発生件数を地図上に可視化しています。
SQL Queryとは
冒頭で示した通り、SQL QueryとはICOS(IBM Cloud Object Storage)上のファイルを簡単にSQLで検索することのできるサービスです。
ICOS上にファイルがあれば、データベースのインスタンスやETLの仕組みを構築することなく、そのファイルを直接、簡単にSQLで参照、加工することができます。
SQL Queryは内部ではApache Spark SQLを利用しています。SQL Queryのサービスを立ち上げるだけで特別な構成も必要なく気軽にICOS上のファイルにアクセスするApache Spark SQLの処理を実行できるようになります。

当サービスのマニュアルページは以下です。
SQL Query概要
IBM Cloud SQL Query Overview
SQL Queryをクイックに理解するためには以下の文書を参照されるとよいでしょう。
ICOS上のファイルを簡単にSQL検索できる「SQL Query」を使ってみた
Jupyter Note BookからSQL Queryを使ってICOS上のデータにアクセスする例
それでは実際にSQL Queryの利用例をみてみることにしましょう。
0. 環境
当文書の内容を実施するためには以下の3つのサービスが必要です。
- Watson Studio
- Object Storage
- SQL Query
いずれも無料のLiteプランで結構です。IBM Cloudのダッシュボードから追加してください。
1. 準備
まずはCSVファイルの準備です。
IBM Cloud Object Storageのコンソールから、バケットを1つ作ります。

名前は、「mybkt01」としました。
続いてSQL Queryによって参照されるcsvファイルを1つアップロードしました。csvファイルは以下より取得しています。
Los Angeles Traffic Collision Data from 2010 to Present.

2.ICOSへのアクセス
先ほどICOSにアップロードしたファイルにアクセスするため、IBM Cloud API Key, Cloud Resource Name(CRN), さらにアクセスするファイルの情報( cos://<エンドポイント>/<バケット名>/<ファイル名> のフォーマットになります)を取得します。
IBM Cloud API Key
IBM Cloudにて用意したサービスにアクセスするためにIBM Cloud API Keyの準備が必要です。
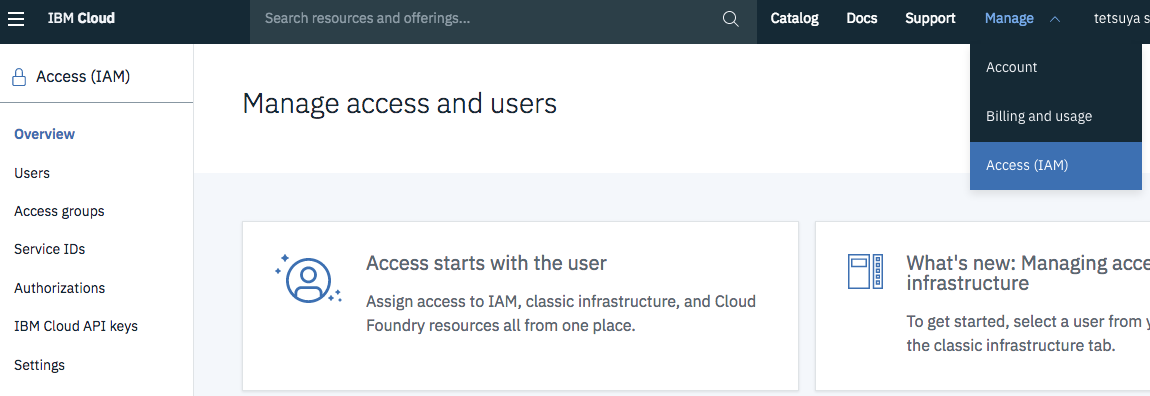
利用しているIBM Cloudのダッシュボードから「Manage」→「Access(IAM)」を選択します。
左に「Access(IAM)」のリストが現れますので、「IBM Cloud API keys」を選択して、IBM Cloud API Keyを発行します。

Cloud Resource Name
続いて、SQL QueryにアクセスするためのCloud Resource Nameを取得します。
起動したSQL QueryのManageページを開き、Overviewのセクションを開くと、CRNと示されている箇所があると思います。これを後ほど利用します。

ファイル情報
SQL Queryでアクセスするファイルはcos://<エンドポイント>/<バケット名>/<ファイル名>というフォーマットになります。エンドポイントとパケット名を調べても良いですが、Object Storageのコンソールから手軽に調べることができます。対象のバケットを開き、対象フィアルの右側の「...」記号をクリックすると「SQL URL」を選択できます。上記のフォーマットでファイルアクセスのためのURLが表示されますので、そのままコピーして保管します。

SQL Queryを利用するPythonコードを書く
それではPythonのコードをみてゆきましょう。
前提となるSWを導入します。
!pip install --upgrade ibmcloudsql
!conda install -c conda-forge pyarrow
!pip install --upgrade pixiedust
ibmcloudsqlというのは、SQL Queryを実行するためのPythonクライアントです。
以下のページに詳細説明があります。
https://github.com/IBM-Cloud/sql-query-clients/blob/master/Python/README.md
pixiedustは、後ほど取得データを地図上に描画するのに使います。
導入に成功したらibmcouldsqlとpixiedustをインポートします。
import ibmcloudsql
import pixiedust

次に、先ほど入手したIBM Cloud API Keyをセットします。
ここではgetpassを使ってインタラクティブに先ほど入手したIBM Cloud API Keyを入力されています。
import getpass
cloud_api_key = getpass.getpass('Enter your IBM Cloud API Key')

さらに、先ほど入手したCloud Resource Nameをセットし、SQL Queryの実行結果を保管するObject Storageの場所を指定します。SQL Queryのサービスを立ち上げると自動的に結果保管先のバケットが作成されるので、そこを使うことにします。SQL Queryのコンソールに表示されます。
sql_crn = 'crn:v1:bluemix:XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX'
sql_cos_endpoint = 'cos:XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX'

これでSQL Queryに対してSQLを実行する準備ができました。まずはSQLQueryにてSQL実行のためのオブジェクトを作ります。Cloud API Key、Cloud Resource Name, SQL結果の格納先を指定します。
続いて、runQueryにて実際のSQLを実行しています。runQueryには実際のSQLストリングを渡します。format(data_source)にて実際にアクセス対象となるファイルを指定しています。SQLのストリングの中で検索条件(20歳から35歳の方が17時から20時に遭遇した事故)を取得しています。
sqlClient = ibmcloudsql.SQLQuery(cloud_api_key,sql_crn,sql_cos_endpoint)
data_source = "cos:XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
query = """
select
`Time Occurred` as time,
`Area Name` as area,
`Victim Age` as age,
`Victim Sex` as sex,
`Location` as location
from {}
where
`Time Occurred` >= 1700 and
`Time Occurred` <= 2000 and
`Victim Age` >= 20 and
`Victim Age` <= 35
""".format(data_source)
traffic_collisions = sqlClient.run_sql(query)

traffic_collisions.head()
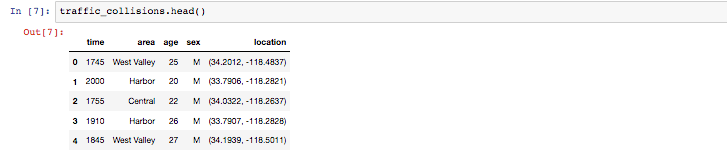
正しく結果を取得することができました。
次にもう少し複雑なSQLにも挑戦します。共通テーブル式(with句を使ったSQLの構文)でわかりにくいですが、下記では後ほど地図に描画がしやすいように1列に入ってしまっているLocation列のデータを緯度データと経度データに変換しています。
sqlClient = ibmcloudsql.SQLQuery(cloud_api_key,sql_crn,sql_cos_endpoint)
data_source = "cos:XXXXXXXXXXXXXx/Traffic_Collision_Data_from_2010_to_Present.csv"
query = """
with location as (
select
id,
cast(split(coordinates,',')[0] as float) as latitude,
cast(split(coordinates,',')[1] as float) as longitude
from (select
`Dr Number` as id,
regexp_replace(Location, '[()]','') as coordinates
from {0}
)
)
select
d.`Dr Number` as id,
d.`Date Occurred` as date,
d.`Time Occurred` as time,
d.`Area Name` as area,
d.`Victim Age` as age,
d.`Victim Sex` as sex,
l.latitude,
l.longitude
from {0} as d
join
location as l
on l.id = d.`Dr Number`
where
d.`Time Occurred` >= 1700 and
d.`Time Occurred` <= 2000 and
d.`Victim Age` >= 20 and
d.`Victim Age` <= 35 and
l.latitude != 0.0000 and
l.longitude != 0.0000
""".format(data_source)
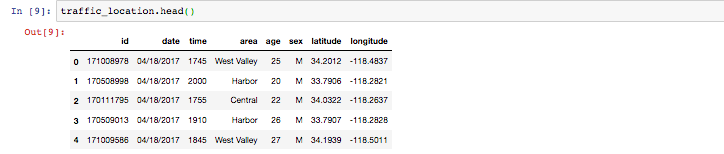
traffic_location = sqlClient.run_sql(query)

traffic_location.head()
期待通り位置データが緯度と経度に分割できています。
最後にこのデータをPixiedustで地図に描画します。
display(traffic_location)
チャートボタン(Vの形状のボタン)にてどのタイプのグラフにするのか選択することができます。「map」を選択します。

緯度と経度(latitudeとlongitude)をKeysに指定し、Valuesにageとidを選択します。また、表示件数がデフォルトで100件になっているようなので適当に数をふやしてから最後にOKをクリックします。

ロスアンジェルス付近の地図が表示され、発生件数のデータが描画される様子がわかります。また自在に結果をズームイン/アウトできると思います。

まとめ
ICOSのデータをSQLで自在に参照できるSQL Queryを試して見ました。列や行の選択はもちろんのこと、結合や共通テーブル式などの複雑な処理も(SQLに慣れた人なら)手軽に行うことができます。
ICOS上のファイルをクイックに参照する目的には最適だと思います。
参照
IBM Cloud SQL Query
ICOS上のファイルを簡単にSQL検索できる「SQL Query」を使ってみた
Analyzing Data with IBM Cloud SQL Query
Data Skipping for IBM Cloud SQL Query