はじめに
Anaconda Repository for IBM Cloud Pak for Data サービスは、IBM Cloud Pak for Dataのカタログにはリストされない、カタログ外部のサービスです。
Anaconda Repository for IBM Cloud Pak for Dataを利用すると、データ・サイエンティストがWatson StudioでJupyter Notebookを作成する際に利用するパッケージのリポジトリーを制御、管理することができるようになります。
特に以下のような利点が挙げれらます。
ー 所属企業の基準に応じたパッケージのブロック、除外、組み込み
ー チームがダウンロードできるパッケージや、それらにアクセスできるユーザーの指定
ー 機械学習のパイプラインからの脆弱性や信頼できないソフトウェアの排除
ー 依存パッケージの管理と、ユーザーへの迅速なアクセスの提供
分析プロジェクトのデータ・サイエンティストは、インターネットにアクセスしなくてもCondaチャネルやリポジトリーのパッケージなどが含まれるカスタム環境定義を作成でき、それらの環境を使用してJupyter Notebook やスクリプトを実行できます。
やってみる
以下の記事では予め用意したAnaconda RepositoryのチャネルをLocal PCのminicondaから接続しています。
Anaconda Repository for IBM Cloud Pak for DataはRed Hat Open Shiftのノードには導入できないことに注意してください。Anaconda Repository for Cloud Pak for Data は、別のLinuxシステムに導入する必要があります。
今回はWatson Studioの環境からAnaconda Repositoryのチャネルに接続してみます。
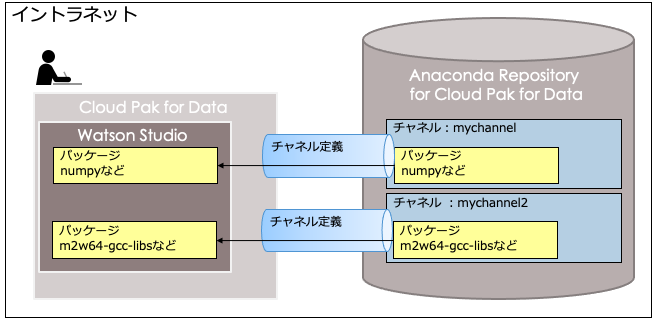
図1. Anaconda Repositoryを利用する
環境
ー Anaconda Team Edition 6.1.3(OEM版のIBM Anaconda Repository for IBM Cloud Pak for Dataを導入)
ー IBM Cloud Pak for Data 3.5.2(Watson Studio)
Condaの構成
こちらのマニュアル記述に沿って必要な構成を行います。
Anaconda Repository for Cloud Pak for Data の管理
Anacondaで作成したチャネルを使用するよう、Cloud Pak for Dataの conda 構成( .condarc ファイル)を変更します。
1. 開始
まず端末ウィンドウで、Open Shift クラスターに対しoc loginを行い、oc project <projectname> と入力して、Cloud Pak for Data がインストールされているプロジェクト (名前空間) に移動します。
2. 構成ファイルの識別
2-1 /user-home/_global_/config/conda/ディレクトリーをマウントする nginx ポッドを判別します。
ibm_nginx_pod=`oc get pods -l component=ibm-nginx -o jsonpath='{.items[0].metadata.name}'`
2-2.既存の.condarc ファイルをローカルのユーザーのホーム・ディレクトリーにコピーするか、新しい .condarcファイルを作成します。
(1) .condarc ファイルが サーバー上の/user-home/_global_/config/conda/に存在するかどうかを確認します。
oc exec ${ibm_nginx_pod} -- ls -la /user-home/_global_/config/conda/
(2) .condarcファイルが存在しない場合、ローカル・ファイル・システムの/home/<username>/に .condarcファイルを作成します。
(3) .condarcファイルが /user-home/_global_/config/conda/に存在する場合、このファイルをローカル・ファイル・システムの/home/<username>/ にコピーします。
oc cp ${ibm_nginx_pod}:/user-home/_global_/config/conda/.condarc /home/<username>/.condarc
3. 構成ファイルの編集
(1) Anaconda RepositoryのチャネルとそのURLを.condarcファイルに追加します。
以下のフォーマットに従ってください。
channel_alias: http://<AnacondaRepositorywithIBM_URL>/api/repo
channels:
- <channel_names>
default_channels:
- http://<AnacondaRepositorywithIBM_URL>/api/repo/<channel_names>
以下修正例です。
channel_alias: http://myhost.com/api/repo
channels:
- mychannel
- mychannel2
default_channels:
- https://myhost.com/api/repo/mychannel
- https://myhost.com/api/repo/mychannel2
(2)/home/<username>/にあるローカルで変更された.condarcファイルを、クラスターの/user-home/_global_/config/conda/にコピーして戻します。
oc cp /home/<username>/.condarc ${ibm_nginx_pod}:/user-home/_global_/config/conda/.condarc
これで指定したレポジトリーを利用できるようになりました。
Anaconda Repositoryの利用
1. Notebookの作成
Watson Studioの画面で新しいNotebookを作成します。
出来上がった Notebookが利用するレポジトリーを確認してみましょう。condaの構成を確認します。Notebookからconda infoを実行します。
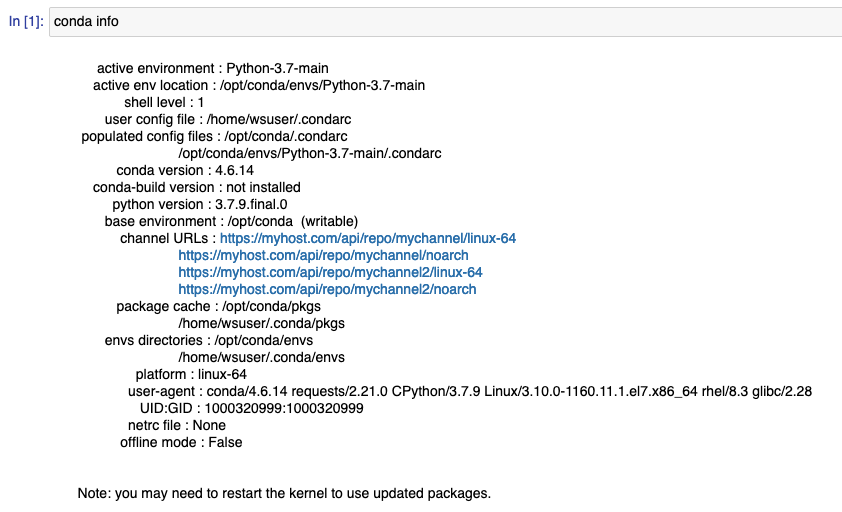
channel URLs部分では.condaファイルで指定した、Anacondaのプライベートリポジトリを参照していることがわかります。
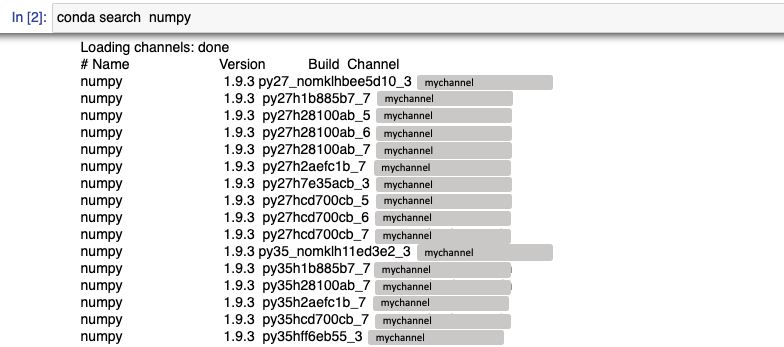
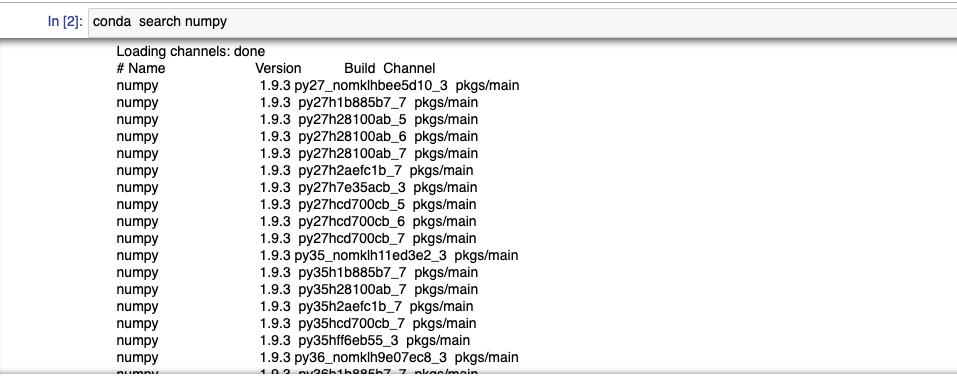
次にnumpyパッケージをsearchしてみます。
Anacondaのチャネルから探していることがわかります。
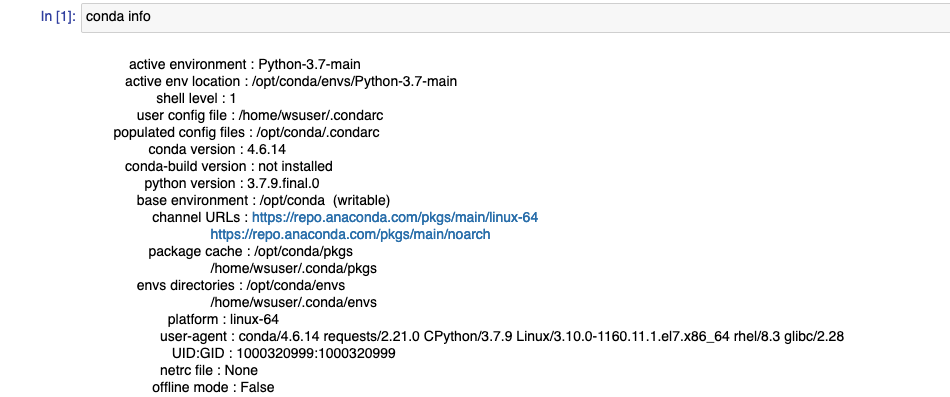
下記は.condarcファイルを編集しない場合にNotebookに表示される構成とパッケージ入手の様子です。
接続先チャネルを明示的に.condarcファイルで指定しない場合、デフォルトのチャネルとしてrepo.anaconda.comにあるpkgs/mainが利用されていることがわかります。
おわりに
Anaconda Repository for IBM Cloud Pak for Dataを利用すると、データ・サイエンティストがWatson StudioでJupyter Notebookを作成する際、利用するパッケージのリポジトリーを制御、管理することができるようになります。
インターネットへのアクセスが制限される環境など、自分でパッケージのレポジトリーを用意する必要がある場合など利用を検討すると良いでしょう。