はじめに
IBM Watson Studioでは、Jupyter Notebookの利用者のために標準のソフトウェア構成を提供しており、多くのケースでそのままそれをお使い頂ければ結構ですが、それに追加パッケージを導入したり、特定レベルのパッケージを導入したりした環境を用意することもできます。
この記事では、IBM Watson Studioが提供しているJupyter NotebookのRuntimeイメージをベースに、新しいカスタム・イメージを作成し、それを利用する方法をご紹介します。

図1 Watson Studioのカスタマイズ
Notebookを起動してから、足りないパッケージを導入したり、目的のレベルにあうように導入作業をする必要が無いように環境を事前にカスタマイズしておく(必要なパッケージを事前導入してから利用者に渡す)方法を、こちらの記事では紹介しました。
今回は、製品が提供するイメージをカスタマイズし、そのカスタム・イメージを利用させるようにする手順を紹介します。
カスタム・イメージを利用することで、管理者はそのチームで標準となるソフトウェア・パッケージの構成を統制できるだけではなく、以下のようなメリットがあります。
- インターネットへの接続を禁止しているエアギャップ環境でも必要なパッケージを速やかに使用できる
- pipやcondaなどの導入では不可能なコンパイルの必要なモジュールなどが導入できる
- リソースやリソース定義も共通のものがつかえる。
- 環境起動時にダウンロード、導入を行わないため、環境を速く起動できる
環境
- IBM Cloud Pak for Datab 3.5.2 (Watson Studio)
- 作業マシン(Red Hat 7.8)
カスタム・イメージの作成
こちらのマニュアル記述に沿って必要な構成を行います。
カスタム・イメージの作成
以下の順番に操作します。
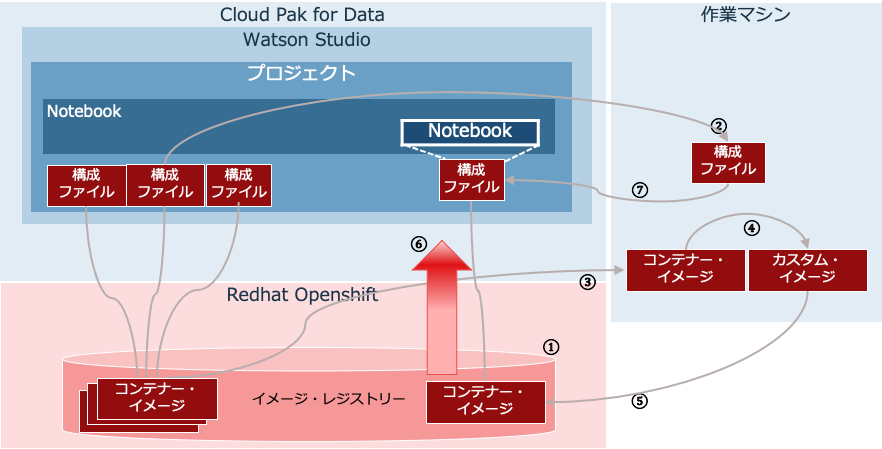
図1 Watson Studioで利用するカスタム・イメージの作成
- イメージ・レジストリーのアクセス
- ランタイム構成のダウンロード
- ランタイム・イメージのダウンロード
- ランタイム・イメージのカスタマイズ
- カスタムイメージのアップロード
- 新しいイメージの各ワーカーへのダウンロード
- 変更した構成のアップロード
詳細を順番に見ていきます。
1. イメージ・レジストリーのアクセス
Watson Studio ランタイム・イメージは、Docker イメージ・レジストリーに保管されます。
Cloud Pak for Dataを内部レジストリーを利用して導入した場合以下のようにします。
・Cloud Pak for Data on OpenShift Container Platform 4.5 の場合
# oc -n openshift-image-registry get route
レジストリーへのプライベート・エンドポイントを記録します。以下に例を示します。
image-registry.openshift-image-registry.svc:5000
Cloud Pak for Data on OpenShift Container Platform 3.11 の場合にはoc get routes --all-namespaces |grep -i docker-registryと実行します。
Cloud Pak for Dataを導入したときに外部レジストリーを利用したときには、そのURLが後続で利用するレジトリーのURLです。
2. ランタイム構成のダウンロード
Watson Studioは標準のNotebookイメージとして複数のものを提供しています。マニュアルに一覧をのせています。
ここから自分がベースとしたいイメージの構成を定義しているJSONファイルを選択します。
ランタイム構成のダウンロード
今回は、Python3.7ベースのJupyter Notebookの構成であるjupyter-py37-server.jsonを選びました。取得するJSON構成ファイルは以下の形式になっています。これを入手します。
<CloudPakforData_URL>/zen-data/v1/volumes/files/%2F_global_%2Fconfig%2F.runtime-definitions%2Fibm%2F<runtime-config-server.json>
我々の例では以下をブラウザーで参照しました(Manualにあるようにcurlコマンドを用いても結構です。)
https://<CloudPakforDara_URL>/zen-data/v1/volumes/files/%2F_global_%2Fconfig%2F.runtime-definitions%2Fibm%2Fjupyter-py37-server.json
3. ランタイム・イメージのダウンロード
入手した構成ファイルを参照し、imageとある行を参照します。これが取得すべきイメージです。
[...]
"replicas": 1,
"image": "<image-registry-host>/<namespace>/wslocal-runtime-py37main:3.5.2011.1800-amd64",
"command": ["/usr/sbin/tini", "--", "/opt/ibm/ws/bin/setup_container.sh"],
[...]
loginします。
# podman login -u <username> -p <password> <image-registry-url>
以下、pullの実行例です。
# podman pull <image-registry-host>/<namespace>/wslocal-runtime-py37main:3.5.2011.1800-amd64
4. ランタイム・イメージのカスタマイズ
カスタマイズするランタイムのイメージをダウンロードしたら、ダウンロードしたイメージをベースに新しいカスタム・イメージを作成できます。これを行うには、カスタマイズ内容をDockerfileに追加します。
4-1. Dockerfileの編集
提供されたサンプルのDockerfileをベースとして使用し、それに基づいて、カスタマイズしたDockerfileを作成します。サンプルの後ろの方にcondaでパッケージ導入する箇所とpipでパッケージ導入する箇所があるかと思います。
ARG base_image_tag
FROM ${base_image_tag}
# Operating system packages must be installed as root.
USER root:root
# If you don't need to install additional operating system packages from the
# default repositories, remove the "microdnf install" command and package list,
# but keep the rest of this RUN statement. This will install security updates.
# The chown and chmod commands are needed when system certificates get updated.
RUN microdnf update \
&& microdnf install --nodocs \
poppler-utils \
&& microdnf clean all \
&& rm -rf /var/cache/yum \
&& chown -cR :wsbuild \
/etc/pki/ca-trust/source/anchors/ \
/etc/pki/ca-trust/extracted/ \
&& chmod -cR g+w \
/etc/pki/ca-trust/source/anchors/ \
/etc/pki/ca-trust/extracted/
# =========================================
# Change display name of the Jupyter kernel
# =========================================
# The kernel spec is in /opt/ibm/run/kernels/<name>/
# It must be modified as root.
RUN sed -i -e '/display_name/{s/",/ with modifications",/}' \
/opt/ibm/run/kernels/*/kernel.json
# ==================================================
# Modify the conda environment of the Jupyter kernel
# ==================================================
# The name of the kernel conda environment is given by $DSX_KERNEL_CONDENV.
# The examples assume that you are modifying the conda environment of the
# base image. If you prefer to create and use a different conda environment
# from scratch, set DSX_KERNEL_CONDENV to the name of that environment.
#
# The conda environment should be changed with user and group "wsbuild".
# In each layer, call fix-conda-permissions to ensure group write permission,
# because some files may get installed without respect for the umask.
USER wsbuild:wsbuild
# If you need to add files to the image, use
# COPY --chown=wsbuild:wsbuild ...
# ===========================
# Install packages with conda
# ===========================
# If you don't need to install packages with conda, remove this RUN statement.
RUN umask 002 \
&& conda install -n $DSX_KERNEL_CONDENV \
basemap=1.3.0 \
py4j \
&& source /opt/ibm/build/bin/installutils.sh \
&& fix-conda-permissions
# =========================
# Install packages with pip
# =========================
# If you don't need to install packages with pip, remove this RUN statement.
RUN umask 002 \
&& conda run -n $DSX_KERNEL_CONDENV pip install \
astrotools==1.4.2 \
scikit-multilearn \
scikit-plot \
seawater \
fuzzy \
&& source /opt/ibm/build/bin/installutils.sh \
&& fix-conda-permissions
# ======================================
# change from build user to runtime user
# ======================================
USER $DSX_USERNAME:wsbuild
4-2. カスタム・イメージのビルド
新規イメージを作成します。以下のコマンドでは、wslocal-runtime-py37main:3.5.2011.1800-amd64に基づいて新規イメージが作成されます。
# docker build -t <new-image-name>:<new-image-tag> --build-arg base_image_tag= <image-registry_
host>/<name_space>/wslocal-runtime-py37main:3.5.2011.1800-amd64 -f <path_to_dockerfile> .
以下実行例です。私たちはdockerではなくpodmanを利用し、--format dockerオプションを指定しました。また「イメージ名=cp4dimagetest」、「タグ=3301410」を指定しています。カスタマイゼーションを含んだDockerfileは./cp4dimagetestにて提供しました。
# podman build -t cp4dimagetest:3301410 --build-arg base_image_tag=<image-registry-host>/<name_space>/wslocal-runtime-py37main:3.5.2011.1800-amd64 ---format docker -f ./cp4dimagetest .
新しいイメージができました。
# podman images
REPOSITORY TAG IMAGE ID CREATED SIZE
localhost/cp4dimagetest 3301410 925036b3f611 5 minutes ago 6.54 GB
5. カスタム・イメージのアップロード
イメージを作成したら、そのイメージをレジストリー・サーバーにプッシュして、イメージを登録する必要があります。(マニュアルでは新イメージ・タグをつけてpushしていますが、我々はイメージIDを指定してpushしました。どちらでも結構です。)
podman push 925036b3f611 <image-registry-host>/<name_space>/cp4dimagetest:3301410
6. 新しいイメージの各ワーカーへのダウンロード
新しいイメージは、ターゲット・レジストリーにアップロードされた後で、Cloud Pak for Dataクラスターのすべてのワーカー・ノードに自動的にはダウンロードされません。マニュアルが提供しているYAMLファイルを編集しJOBを起動することで、新しいイメージを各ワーカーにPullします。
以下のYAMLのサンプルのなかでimageとある行を修正し、先ほど作成したイメージを記載します。(マニュアルに掲載のサンプルはインデントがずれているので注意してください)
apiVersion: batch/v1
kind: Job
metadata:
labels:
app: imagePrepull
run: jupyter-py36
name: jupyter-py36-pull
spec:
completions: 20
parallelism: 20
template:
metadata:
labels:
app: imagePrepull
run: jupyter-py36
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: beta.kubernetes.io/arch
operator: In
values:
- amd64
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: run
operator: In
values:
- jupyter-py36
topologyKey: kubernetes.io/hostname
containers:
- command:
- echo
- Image new-image-name preloaded
image: new-image-name
imagePullPolicy: Always
name: jupyter-custom-container
restartPolicy: OnFailure
修正例です。
Image: image-registry.openshift-image-registry.svc:5000/<name_space>/cp4dimagetest:3301410cp4dimagetest:3301410
JOBを実行します。上記サンプルのYAMLファイルをここではprepull.yamという名称で作りました。
また、指定したレジストリーの名称としてここでは内部レジストリーとしての名称(image-registry.openshift-image-registry.svc:5000)を指定していることに注意してください。
oc create -f prepull.yam
JOBを実行したら、get podsコマンドで状態を確認してください。リストされたすべてのポッドでCompleteが表示されたら、事前プルは正常に完了しています。
oc get pods | grep pull
7. 変更構成のアップロード
先ほどダウンロードしたJSON構成ファイルを更新してアップロードします。
まずJSON構成ファイルを任意の名称-server.jsonの様な名称に名前変更します。(例;custom-runtime-def-1-server.json)
7-1. JSON構成ファイルの変更
imageとある行を見つけます。この行を修正し、カスタム・イメージを登録したときに使用したものに変更します。
変更例
"image": "image-registry.openshift-image-regisry.svc:5000/<namespace>/cp4dimagetest:3301410",
7-2. JSON構成ファイルのアップロード
修正したJSON構成ファイルをアップロードするためのトークンを取得します。
Cloud Pak for Dataのユーザーとパスワードを指定して以下を実行します。
curl <CloudPakforData_URL>/v1/preauth/validateAuth -u <username>:<password>
出力されたトークンを指定して、JSONのアップロードを行います。以下、とある箇所を入手したトークンに置き換えて実行します。
curl -X PUT \
'https://<CloudPakforData_URL>/zen-data/v1/volumes/files/%2F_global_%2Fconfig%2F.runtime-definitions%2Fibm' \
-H 'Authorization: Bearer <platform-access-token>' \
-H 'content-type: multipart/form-data' \
-F upFile=@/path/to/runtime/def/<custom-def-name>-server.json
カスタム・イメージの使用
1. 環境の作成
既存のプロジェクトの画面から「環境」タブを開きます。ここでは「test03」という分析プロジェクトを利用しています。
Python 3.6とPython 3.7の2つのデフォルト環境が製品によって提供されていることがわかります。また、カスタム・イメージとして製品提供の環境をベースとしたPython3.7の環境が見えています。アップロードで利用したJSON構成ファイルの名称であるcustom-runtime-def-1が表示されています。
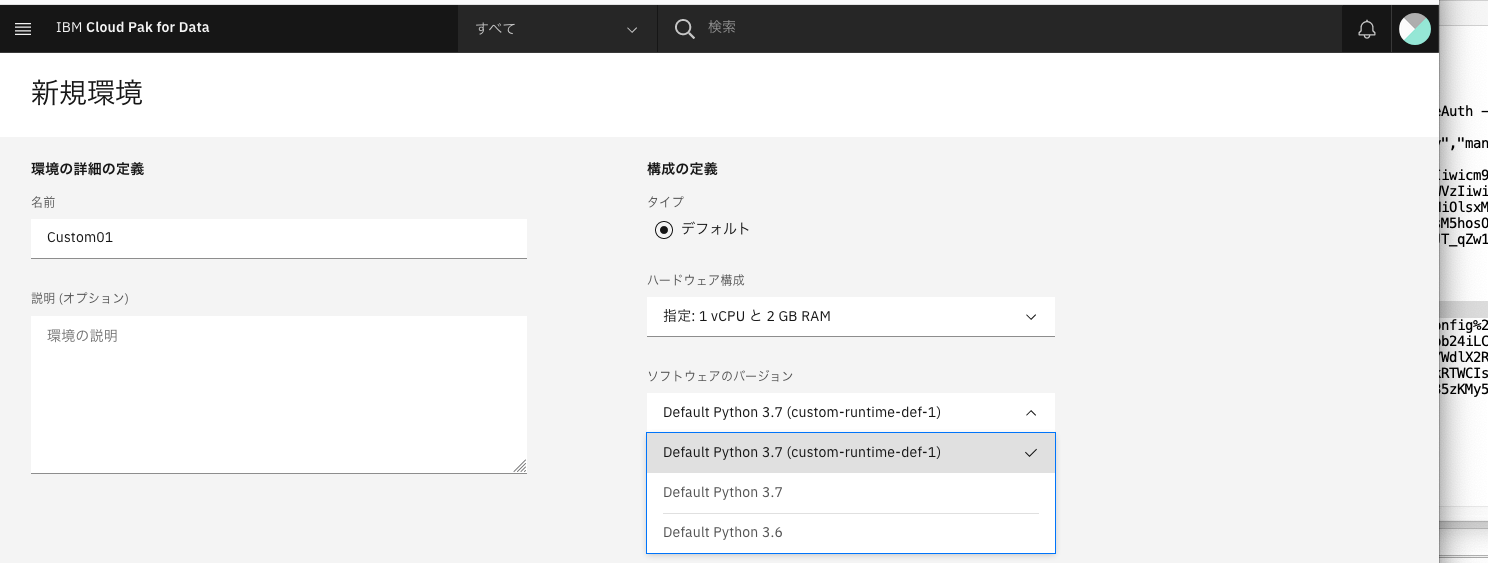
こちらを選択して新しい環境を作ります。(ここではCustom01と名付けました。)
2. Notebookの作成
カスタマイズした環境を利用して新しいNotebookを作ってみます。
当プロジェクトに新しいNotebookを作成します。このときランタイムとして先ほど新しく作成したもの(Custom01)を選択します。
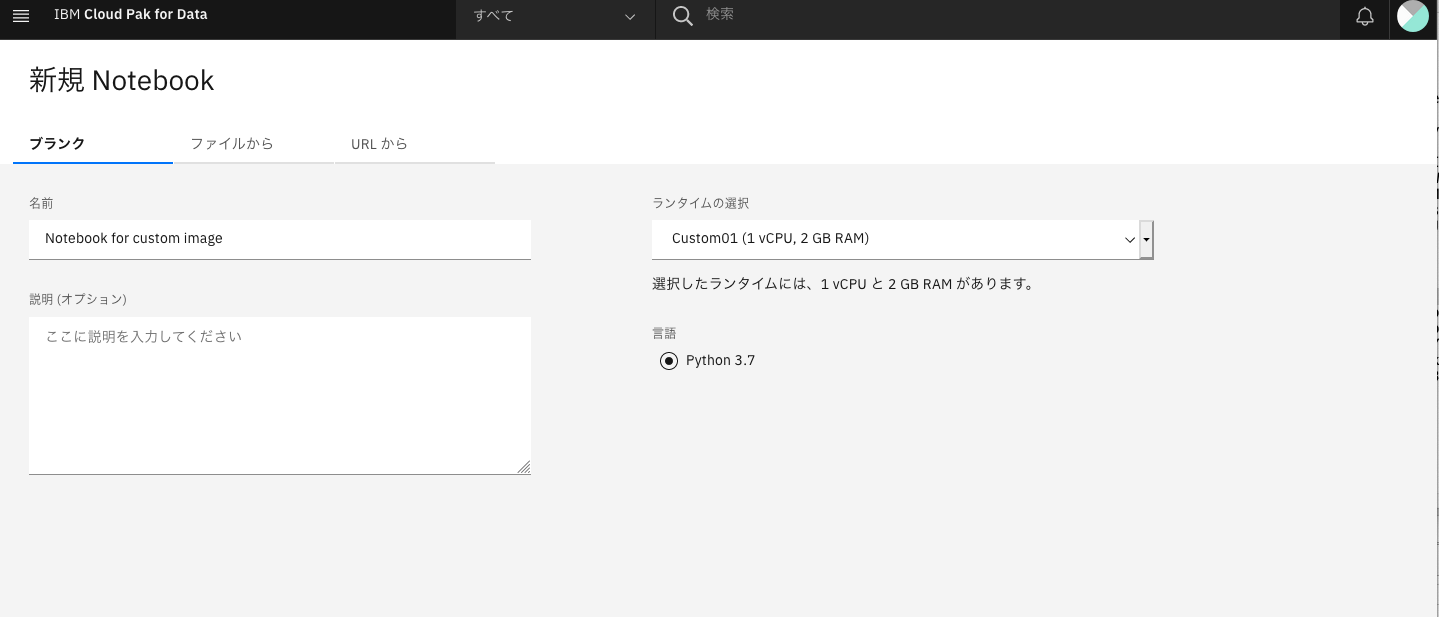
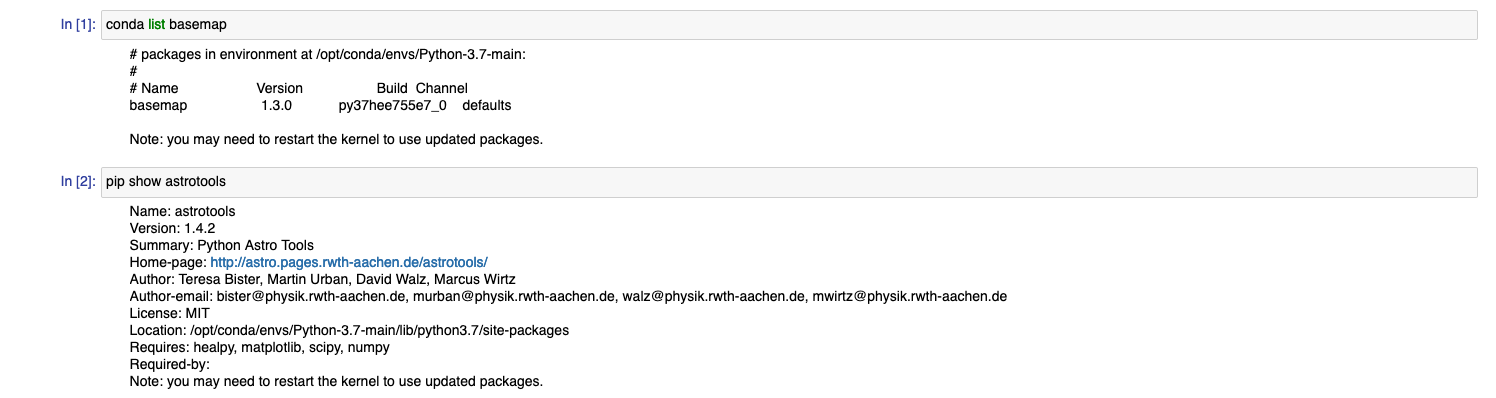
出来上がった Notebookはカスタム・イメージのほうで動作します。
カスタマイズでDockerファイルに加えたcondaパッケージとpipパッケージが入っていることがわかります。
おわりに
必要なソフトウェアやそのレベルをチーム内で合わせるだけでしたら、こちらの記事で紹介した方法が簡便ですが、都度installが走ることになります。インターネットへの接続を禁止しているエアギャップ環境などでは今回のような方法もあると知っておくとよいでしょう。