Classiアドベントカレンダー24日目です。
(*タイトルからわかるように当記事はアニメ「進撃の巨人」よりインスパイアをうけております。)
どうも、エルヴィン(Classi データAI部の平田です。)です。
当報告内容は、昨年の結果報告の続きになります。
https://qiita.com/tetsuya0617/items/73fc69bcf1fc889097af
壁外調査結果報告とは
我々、壁外調査兵団による食の都である新宿の美味しいレストランを奪還していった2019年の軌跡をふりかえる調査報告書になる。今年度の報告内容のアジェンダは、以下。
- 実績報告: 調査兵団のメンバー数の増員と奪還数
- 調査結果振り返り: 奪還先の画像収集 from Google Chrome .feat Chrome Driver
- 調査結果振り返り: 画像データの整備 .feat Google Vision API
- 調査結果振り返り: Google Auto ML Vision API によるラベルつき分類モデルの構築。
- 奪還先の画像郡をDCGANにかけて、新しいカレーを創造し、2020年の新しい奪還先をみつけるための手がかりをみつける。
(学習時間が長すぎて間に合わなかった。。。)
実績報告: 調査兵団メンバーの増員
昨年は、壁外調査兵団第一部隊の5名 + 17名の憲兵団だった。
現在、壁外調査兵団第一部隊と憲兵団の増員に加え、駐屯兵団の増員が見られた。
slackチャンネルには、42名の隊員がおり、そのうちメンバーが入れ替りで大体5名の陣営を組み、調査している。
新しいメンバーを紹介する。
1.エレン・イェーガー
新卒フロントエンドエンジニア
2. ミカサ アッカーマン
常に顧客を守る。
3.サシャ・ブラウス
はしおばざーるへの調査のときにのみ現れる。
4.ジャン・キルシュタイン
牡蠣のカレーがでるときは、戦闘力があがる。
5.コニー・スプリンガー
エルヴィンとよくfishに食べにいく。
6. ハンネス
たまに先人をきったり、あとから遅れて調査に加わったり、突発的に助っ人にはいってくれる。
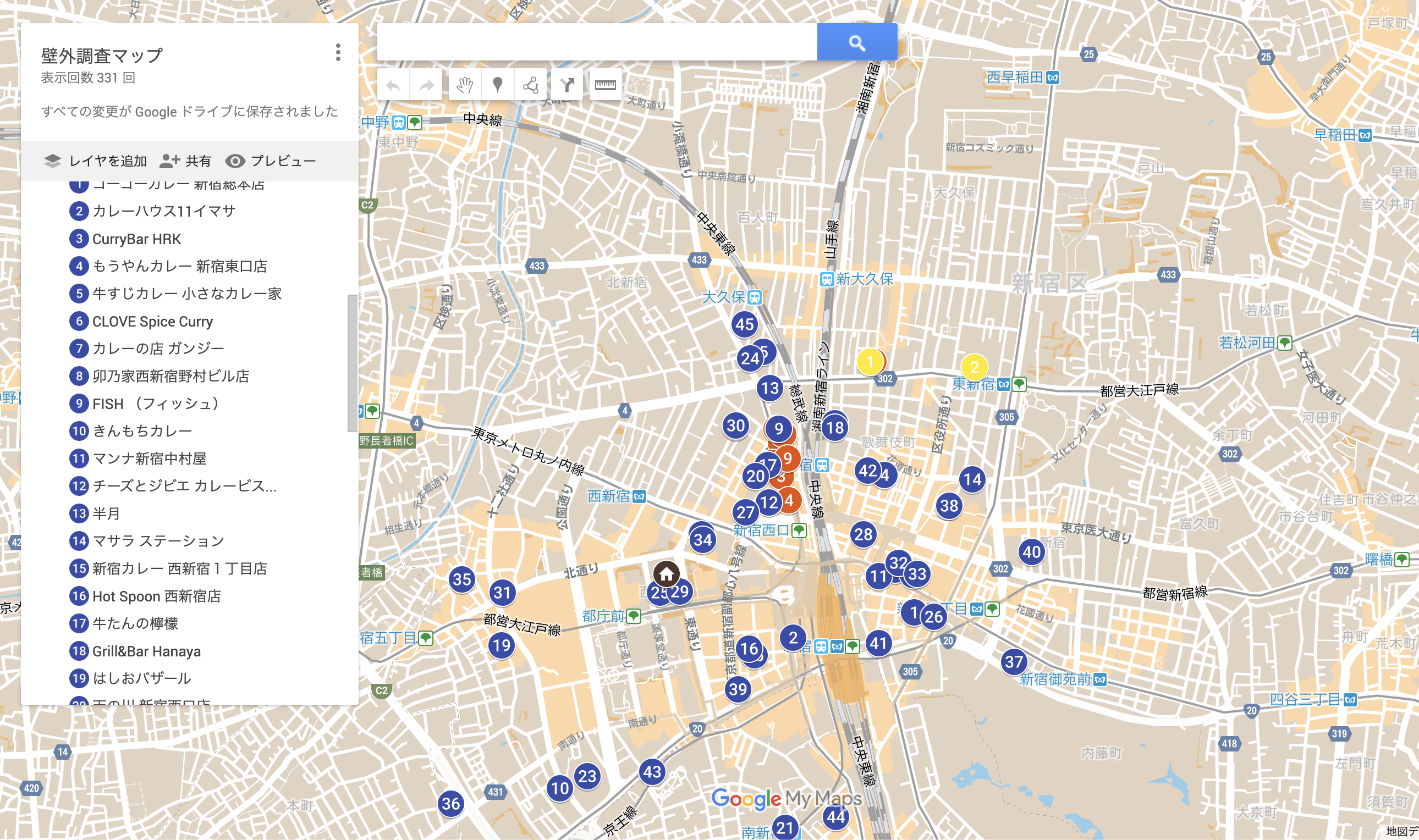
実績報告: 2019年の奪還数の報告
昨年度の調査結果では、12店舗だったのだが、今年は、累計45店舗の奪還をすることができました。
調査結果振り返り方法の概要
- 去年と今年で手応えのあったカレー屋の画像を収集する。
- 余分な画像を取り除き分類する。
- その中でも特徴量の多そうな画像をgoogle auto mlに学習をさせ、新たなラベルによる分類を行う。
- 次に調査しにいくカレー屋さんの画像をモデルにインプットし、どんなラベルがつき、どんなカレーかを推定し、調査判断の一助とする。
では、はじめていこう!
奪還先の画像収集 from Google Chrome .feat Chrome Driver
1. chromedriverをインストールする。
https://chromedriver.chromium.org/downloads
2. 以下のコマンドをターミナル上で実行。
googleimagesdownload --keywords "カレー" --suffix_keywords "ハイチ" -l 10000 --chromedriver /usr/local/bin/chromedriver
*注意点は、chromedriver.exeを/usr/local/bin/配下に配置し直すこと。
やってることは、以下のように検索するのと同じ。
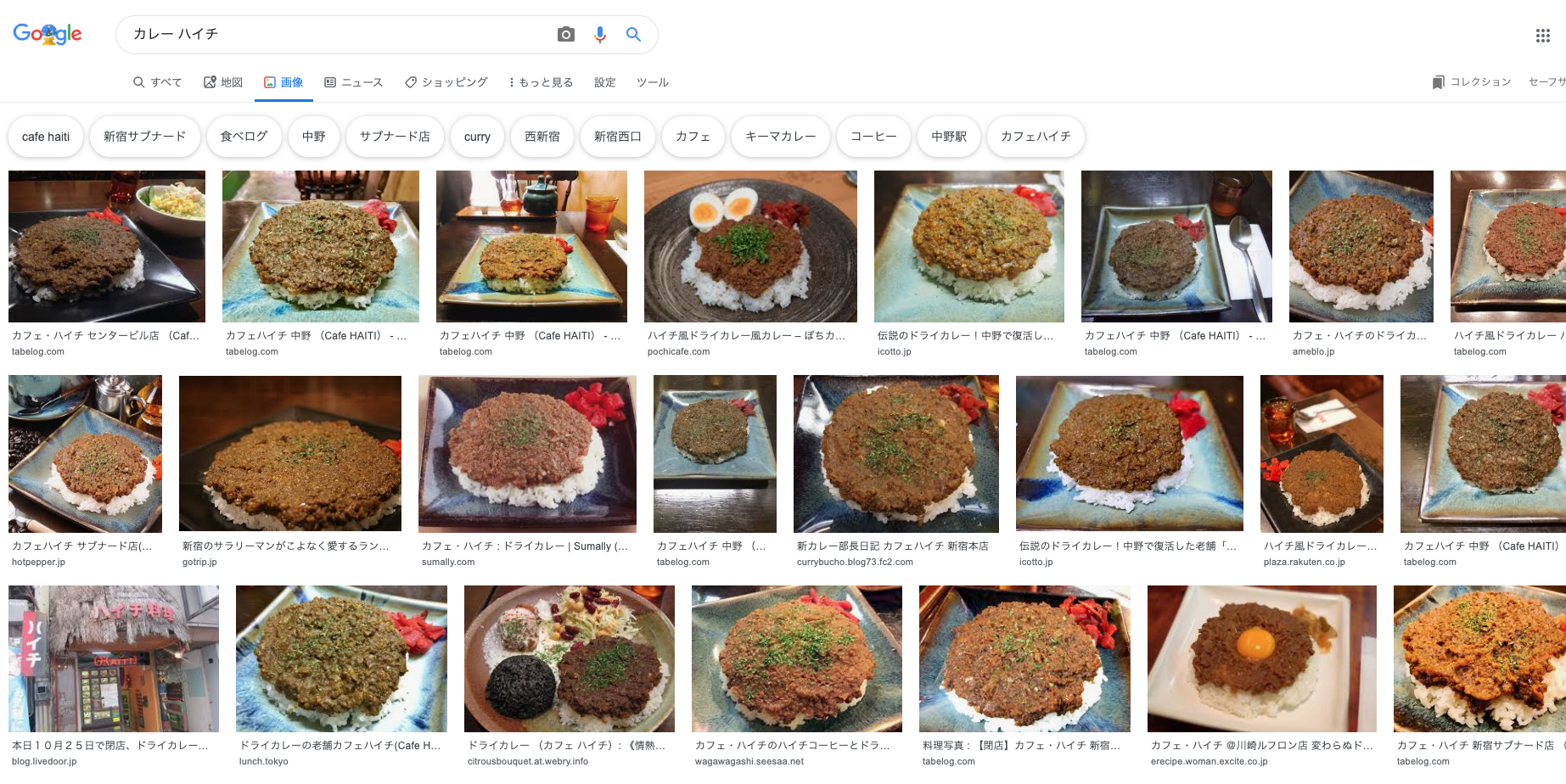
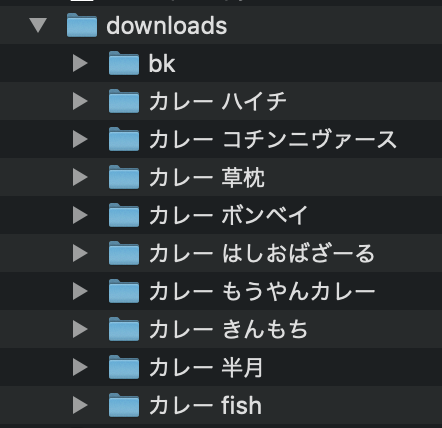
3.キーワードごとにdownloadsディレクトリが勝手にできているのでそこを探して確認
画像データの整備 .feat Google Vision API
Web上からかき集めた画像には、人の画像やカレー以外の画像も当然含まれていた。
それら、余計な画像を取り除きたい、本当であればCNNでどうにかしたいところだったがニューラルネットの構造定義が面倒であったため、Google Vision APIを利用することにした。
下記の画像をインプットとし、Google Vision APIを叩くと、以下のレスポンスが得られる。(detectator.pyについては、後ほど中のコードをみていく)

(myvenv) 69 ~/local/adventcalender2019 (master) $ python detectator.py xxxx 半月
{
"labelAnnotations": [
{
"mid": "/m/02q08p0",
"description": "Dish",
"score": 0.9934035,
"topicality": 0.9934035
},
{
"mid": "/m/02wbm",
"description": "Food",
"score": 0.9903261,
"topicality": 0.9903261
},
{
"mid": "/m/01ykh",
"description": "Cuisine",
"score": 0.9864208,
"topicality": 0.9864208
},
{
"mid": "/m/07xgrh",
"description": "Ingredient",
"score": 0.9207317,
"topicality": 0.9207317
},
{
"mid": "/m/02slfb",
"description": "Rice and curry",
"score": 0.8866451,
"topicality": 0.8866451
}
]
}
そこで、score(そのdeescriptionが何をさしているかの信頼度合い)が一番高いものでカレーの共通因子である"Dish"とかかれたものだけを抽出して、別ファルダに束ねることをした。
detectator.pyの中身
(adventカレンダー用に急ぎで準備したのでだいぶ汚いがご了承頂きたい。)
1 from base64 import b64encode
2 from sys import argv
3 import json
4 import requests
5 import shutil
6 import os
7 import glob
8
9 ENDPOINT_URL = 'https://vision.googleapis.com/v1/images:annotate'
10
11 if __name__ == '__main__':
12 api_key, directory = argv[1:]
13
14 image_filenames = glob.glob("./reshaped_data/%s/*" % directory)
15 os.mkdir('./reshaped_data/filtered_%s' % directory)
16 img_requests = []
17 for image_file in image_filenames:
18 with open(image_file, 'rb') as f:
19 ctxt = b64encode(f.read()).decode()
20 img_requests.append({
21 'image': {'content': ctxt},
22 'features': [{
23 'type': 'LABEL_DETECTION',
24 'maxResults': 5
25 }]
26 })
27
28 response = requests.post(ENDPOINT_URL,
29 data=json.dumps({"requests": img_requests}).encode(),
30 params={'key': api_key},
31 headers={'Content-Type': 'application/json'})
32
33 if response.json()['responses'][0]:
34 print(image_file)
35 print(response.json()['responses'][0])
36 obj = response.json()['responses'][0]['labelAnnotations'][0]['description']
37 score = response.json()['responses'][0]['labelAnnotations'][0]['score']
38 print(obj)
39 if obj == 'Dish':
40 shutil.copy(image_file, './reshaped_data/filtered_%s' % directory)
41 print('OK')
42 else:
43 print('False')
44 img_requests = []
下記を実行すれば、うちこんだディレクトリ名ができ、そのディレクトリ名ごとにカレーだけの画像にまとめられる。
$ python detectator.py APIキー ディレクトリ名
Google Auto ML Vision API によるラベルつき分類モデルの構築
では、最後、学習用の画像データも集まったので、やってみよう。

ここから先は、全てGCPのコンソール画面からいけます。データさえ準備できたら、あとは楽勝です。
1. 先程、準備した画像データをインポートします。
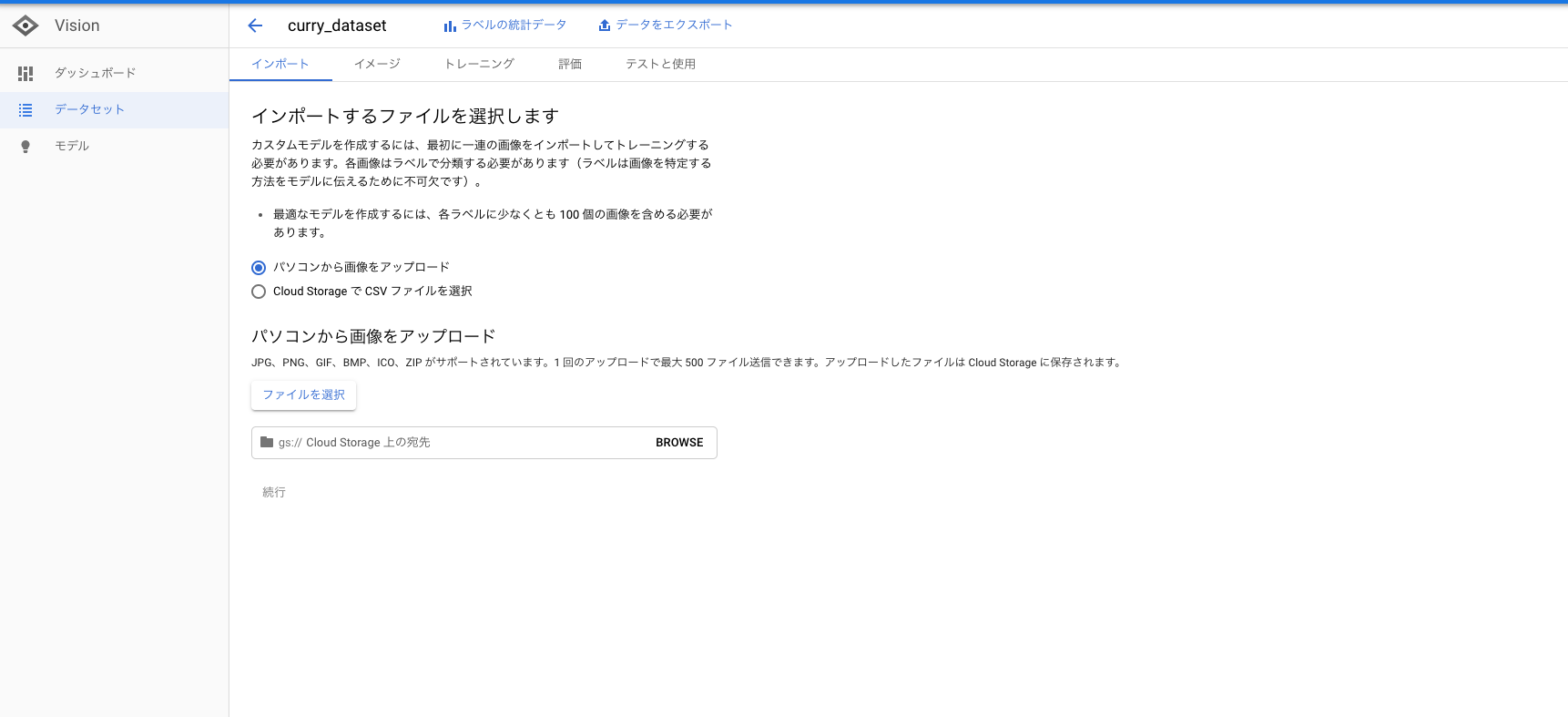
GCSにファルダが作成するバケットのパスもちゃんと指定してください。画像は、GCSにアップロードされます。
2. インポートした画像にラベルをつけます。
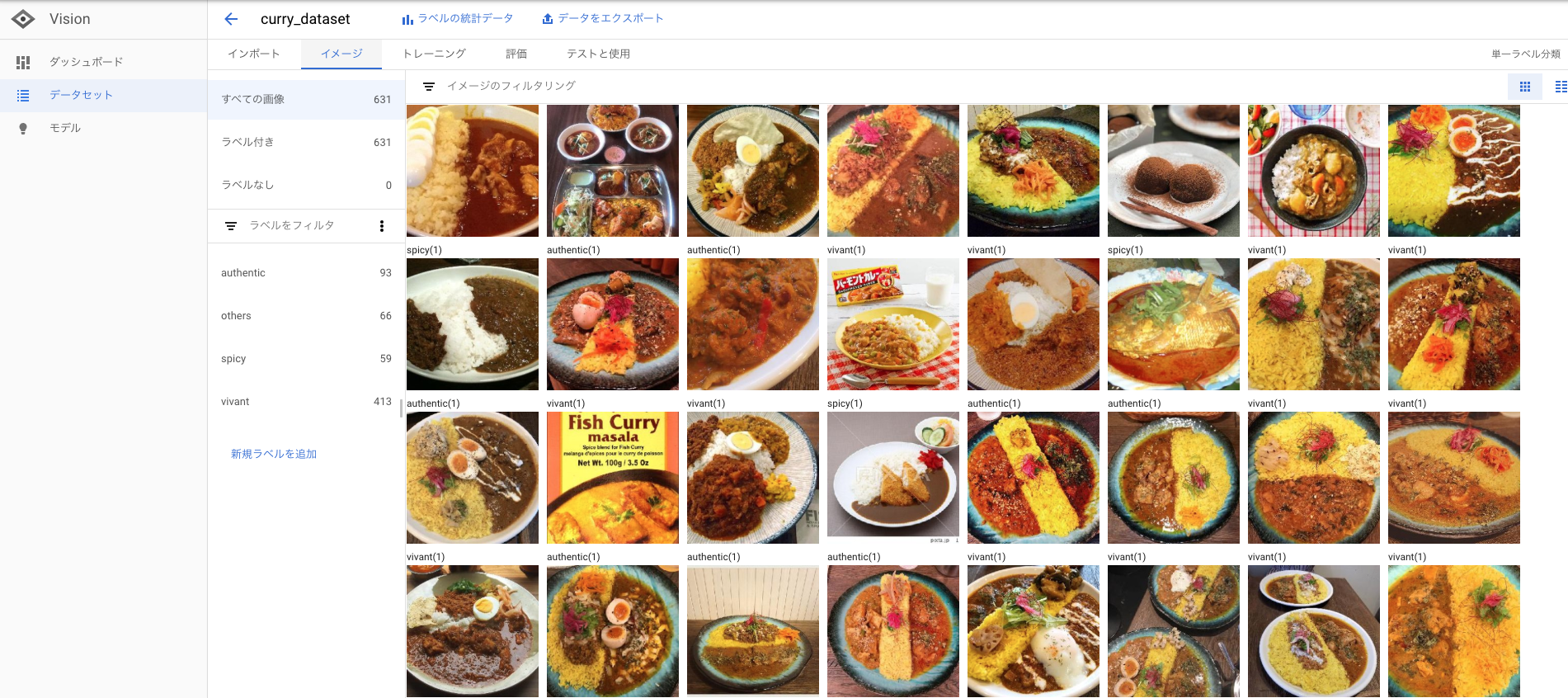
今回は、spicy(辛い), authentic(本物志向の味), vivant(インスタ映えするカレー), others という意味合いで各カレー屋さんごとのカレーに私、エルヴィン独自の判断でラベルづけをしていきました。
3. モデル構築するのにデータ足りているか確認。
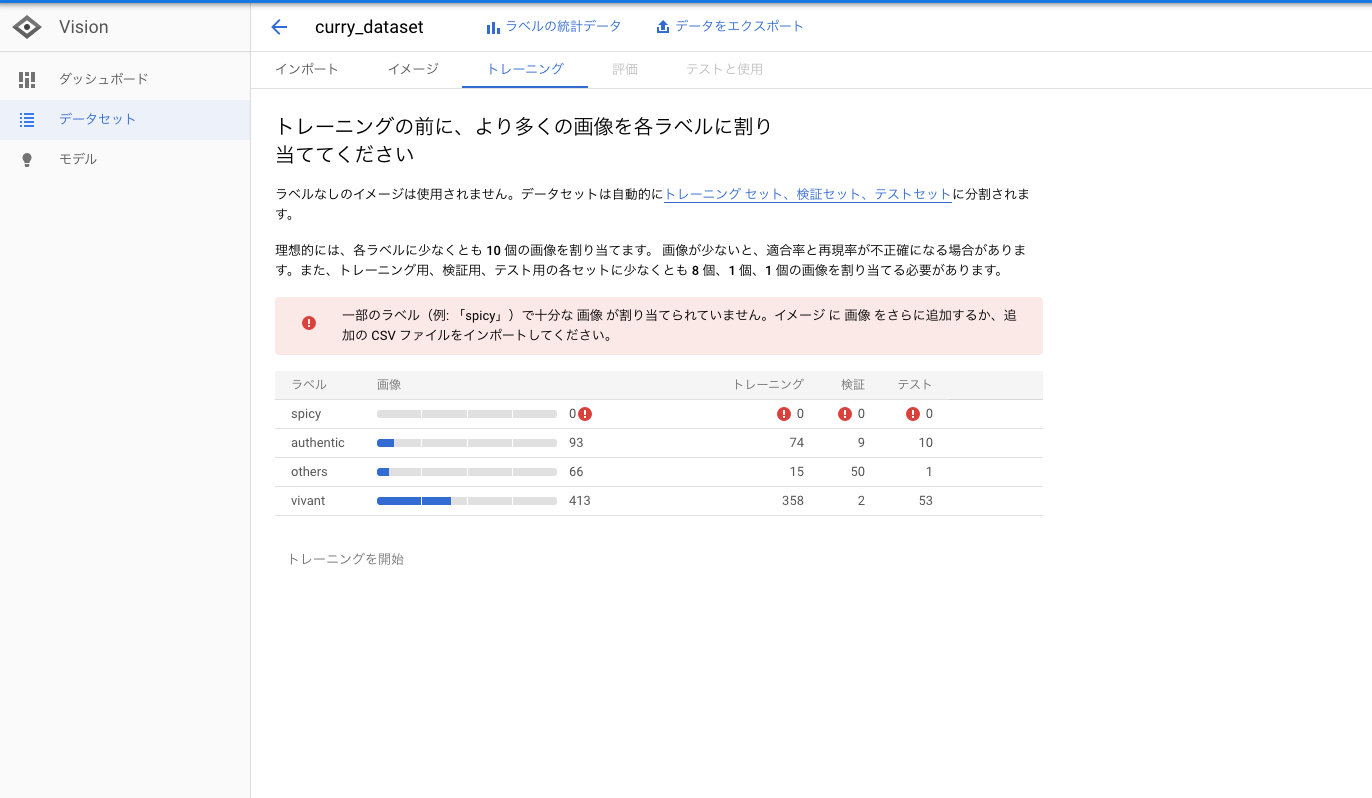
足りていないと怒られてトレーニングできないので画像をもっと追加していきましょう。 100枚で足りるといっていますが、足りる印象はありませんでした。
4. ラベル付き画像データが準備できたらトレーニング実行して待つだけ
トレーニング終了したら以下の評価結果がみれます。
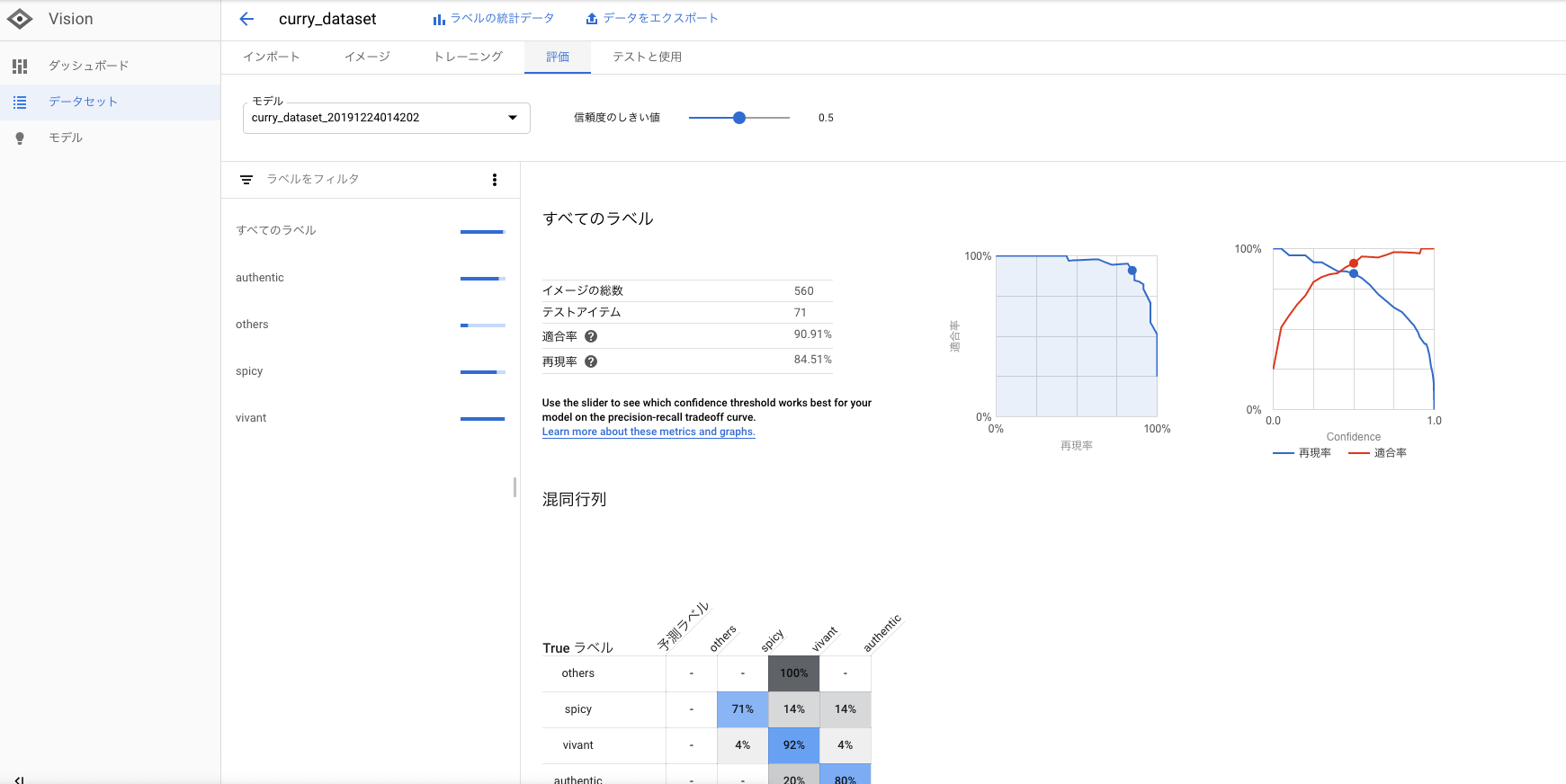
これで画像識別のモデルをつくることができました。画像分類をすることができます。
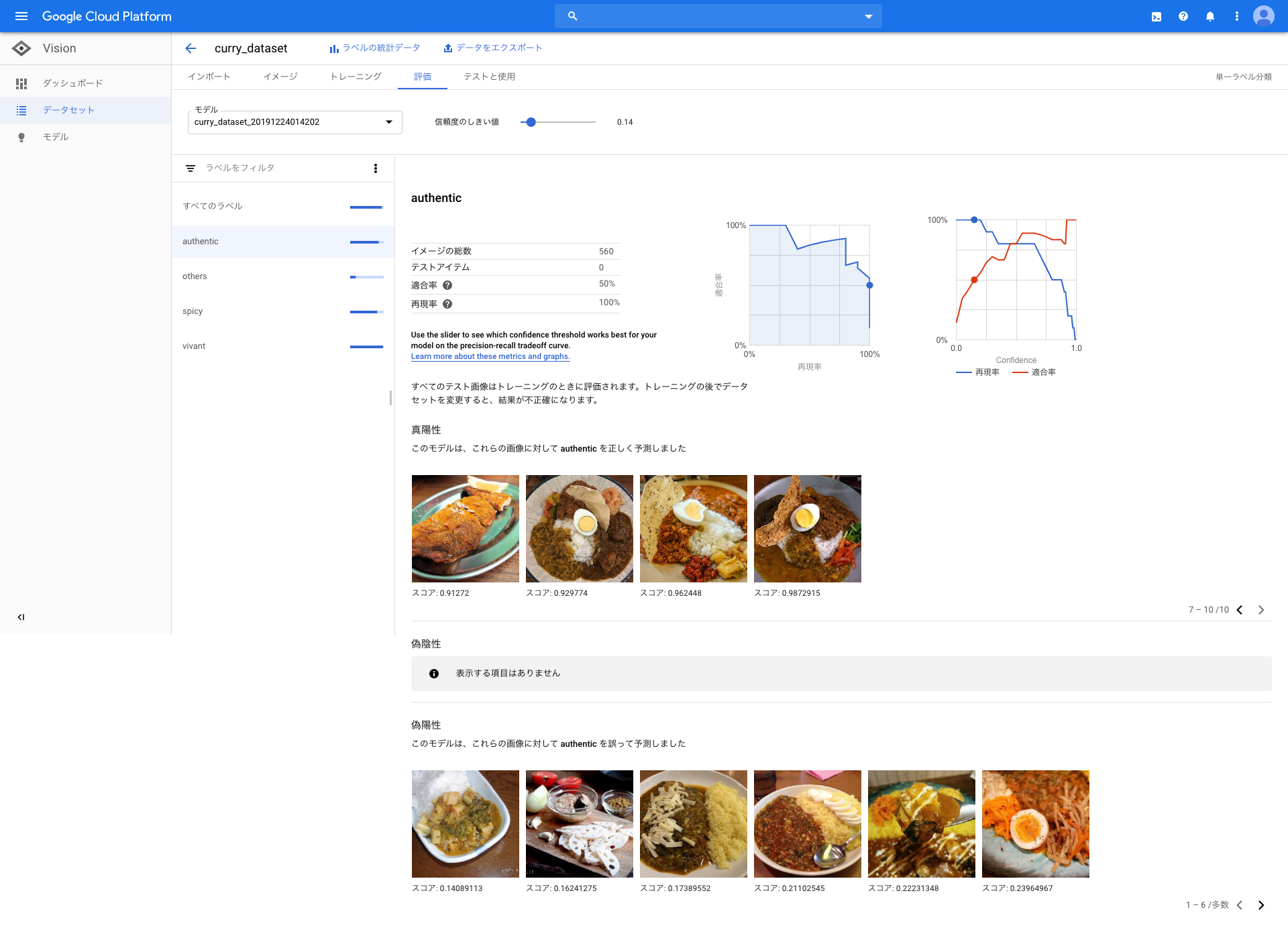
5. 今度は、画像検知の精度をみるために、オンライン検証します。
これまで、インプットデータとして活用してきたのは、「半月」、「fish」、「きんもち」の3つのカレーの画像です。
さて、今度は、当モデルに違うお店のカレーの画像をインプットし、どのラベルを検出するか、つまり、spicy(辛い), authentic(本物志向の味), vivant(インスタ映えするカレー) のどのタイプのカレーのなのかをみてみます。
以下のカレー屋さんのカレーのタイプをみてみましょう!
「はしおばざーる」、「もうやんカレー」、「草枕」を上から順番にみていきます。
vivant(インスタ映えするカレー)が0.84
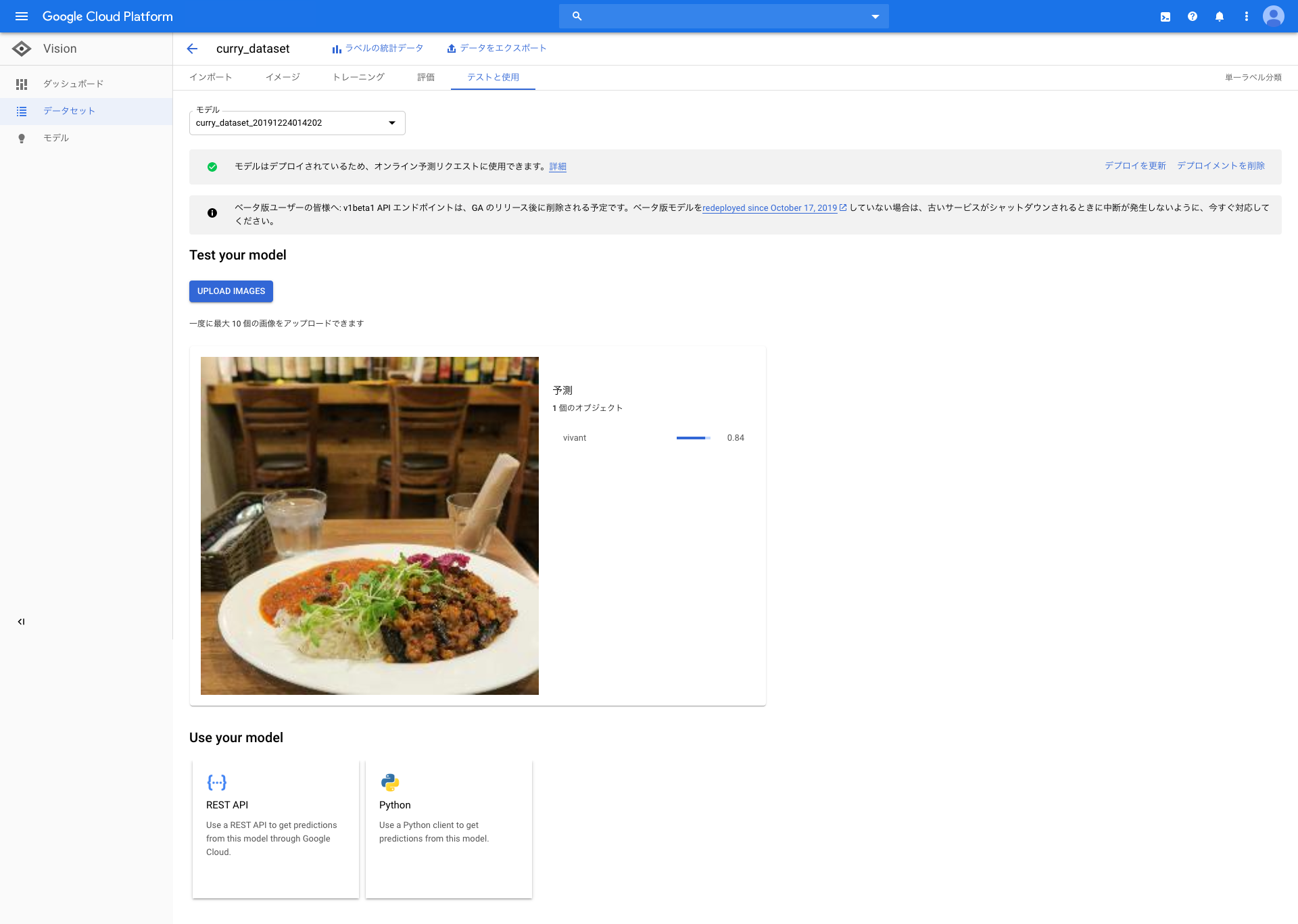
はしおばざーるのカレーは、インスタ映えしやすいんだよなーと前から思っていたので数値通りかなと思いました。
オブジェクトがありません
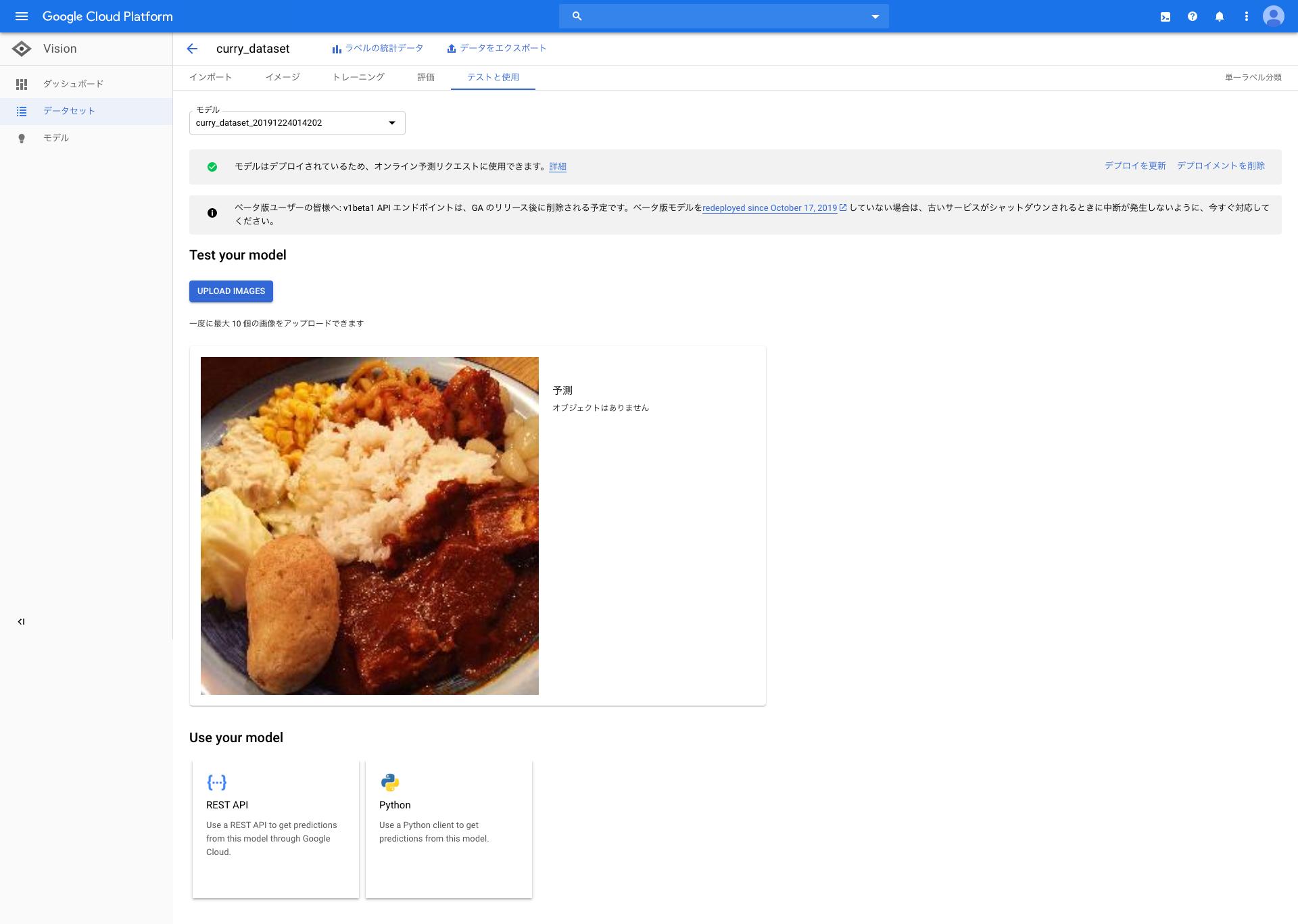
こういったmixのカレーの画像を学習させていなかったのが原因かなと思いましたが、これはこれで学びのある結果です。
vivant(インスタ映えするカレー)が0.60
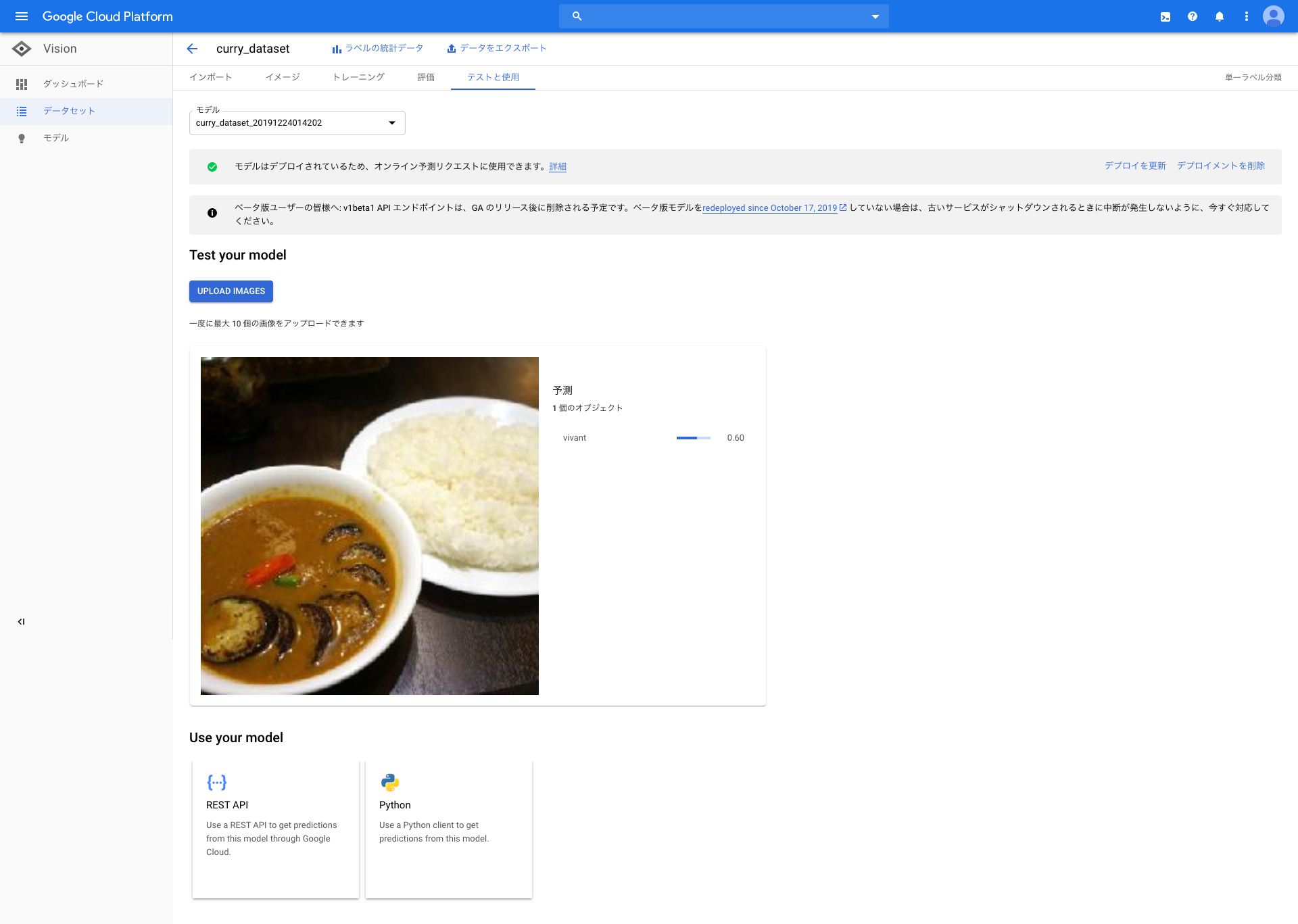
確かに、はしおばざーるの画像よりは、インスタ映えしなそうな画像ですね。しかし、草枕さんのカレーは、カレー界隈では有名でとても美味なので、ぜひっ!!
最後に
これで、次に調査しにいくカレー屋さんを決めるため際に役たちそうなツールをつくることができました。今後、ラベルやインプットの画像データも増やし、精度を高めていき、スマートグラスなどのエッジデバイスにも組み込んでいきたいですね。
あしたは、@sasata299 さんです。(ささたつさんも壁外調査隊員のはず。) お楽しみにっ!