はじめに
JSON データは文字列でそれっぽく編集すればできるけど、なんか芸がない...(誰でもシステム開発者になれるという意味では良いところなんだ)
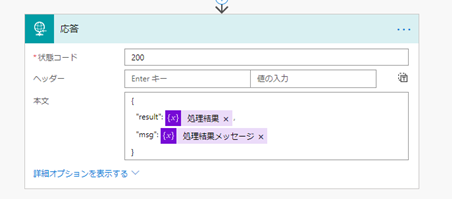
けど、もうちょっと賢く作りたい...(いちおうシステム屋さんという葛藤)
で、処理フローとその内容を忘れそうなので、備忘録として残しておこう。
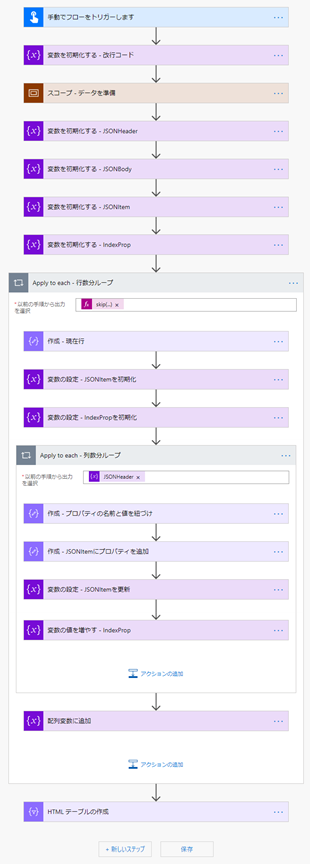
処理の手順
- データを用意する (今回は CSV 形式のデータを用意)
- JSON 形式に変換する際に必要な変数を定義する
- 基となるデータの行数分ループ
- 行単位で編集する際に必要な変数を初期化する
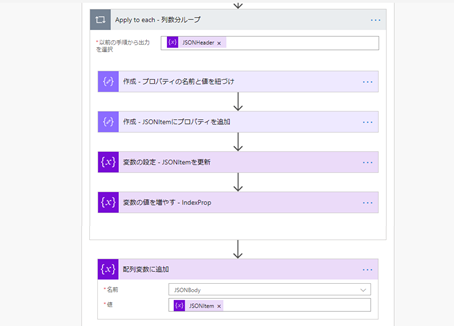
- 基となるデータの列数分ループ
- 列の値を取り出す
- 列の名前と列の値を紐づける
- 処理結果を確認する (今回は HTML テーブルを出力)
1. データを用意する
今回は文字列で CSV 形式のデータを用意しました。
1 行目はヘッダー、2 行目以降にレコードを格納します。
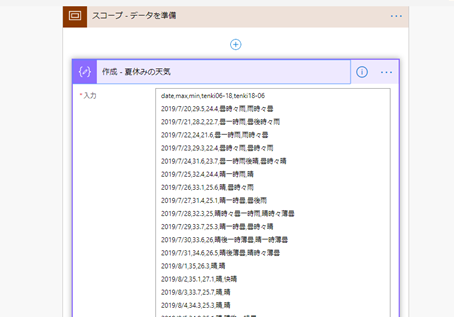
そして、上記の CSV データを行ごとに分割します。
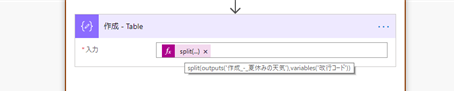
split(outputs('作成_-_夏休みの天気'),variables('改行コード'))
区切り文字として改行コード (\n) を指定してもうまく分割してくれないので、改行コードだけの文字列変数を用意してそれを指定します。
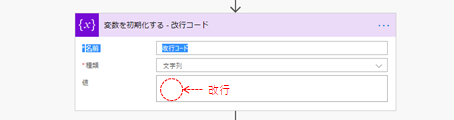
参考:Microsoft Flow上で複数行文字列を改行で分割する
2. JSON 形式に変換する際に必要な変数を定義する
大きく分けて以下に関する変数を定義します。
- ヘッダー行
- データ部

ヘッダー行
行ごとに分割した配列の 1 番目の要素をカンマ区切りで分割して配列に入れます。これが列の名前となります。
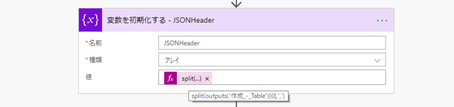
split(outputs('作成_-_Table')[0],',')
データ部
行単位に編集するために使う変数 (JSONItem) とその編集した結果を格納する配列 (JSONBody) を用意します。
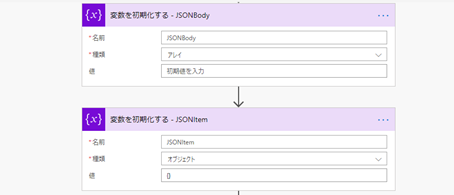
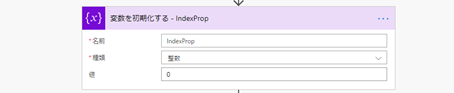
それと、列単位に編集するので現在の列位置を把握するためのインデックスを用意します。
3. 基となるデータの行数分ループ
行ごとに分割した配列の 2 番目の要素から繰り返します。
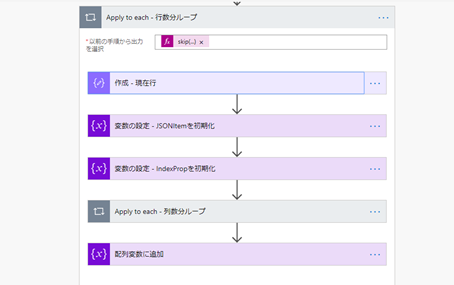
skip(outputs('作成_-_Table'),1)
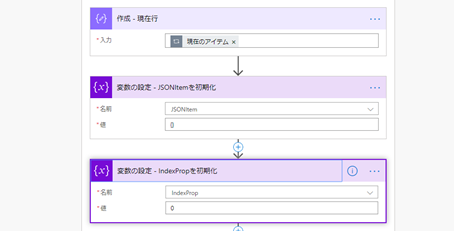
3-1. 行単位で編集する際に必要な変数を初期化する
- 現在行を取り出す
- 行単位に編集するために使う変数 (JSONItem) を初期化する (初期値は「'{}'」)
- 現在の列位置を把握するためのインデックスを初期化する (初期値は「0 (ゼロ)」)
3-2. 基となるデータの列数分ループ
行ごとに分割した配列の 1 番目の要素をカンマ区切りで分割した配列の要素 (列の名前) 数分、繰り返します。
ループ終了後、行単位で編集した結果を配列に格納します。
3-2-1. 列の値を取り出す
列の名前とそれに一致する値を取り出します。

split(outputs('作成_-_現在行'),',')[int(variables('IndexProp'))]
3-2-2. 列の名前と列の値を紐づける
列の名前と値を紐づけるためには「addProperty 関数」を使い、行単位に編集するために使う変数 (JSONItem) を更新します。
そして、現在の列位置を把握するためのインデックスに「1」加算して次のループを行います。
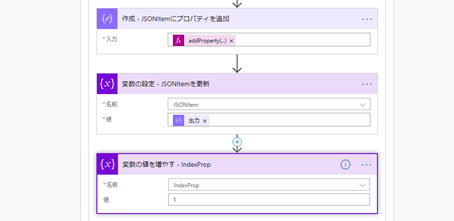
addProperty(variables('JSONItem'),item(),outputs('作成_-_プロパティの名前と値を紐づけ'))
参考:Azure Logic Apps および Microsoft Flow でのワークフロー定義言語の関数リファレンス > addProperty
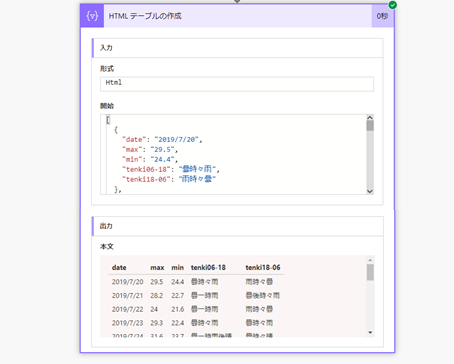
4. 処理結果を確認する
このフローをテスト実行すると、以下のように JSON 配列が出力され、無事 HTML テーブルに変換されていることが確認できます。
参考:MICROSOFT FLOW (ADVANCED) TUTORIAL : CREATING A CSV TO JSON CONVERTER FROM SCRATCH