はじめに
「バイアスとバリアンスのトレードオフ」という言葉を聞いたことがあるだろうか?
統計学や機械学習の文脈でよく出てくる言葉だ。
「なんとなくは知ってるけど、詳細はあまり...」
という人も多いのではないだろうか。
しかし、この問いは転職の面接などで聞かれることも多く、また統計学や機械学習の理解度を深める上でとても重要だ。
この記事ではこの問いを0から始めて"完全に理解する"ことを目的とする。
それに関連して以下の問いに答えられるだろうか?
- バイアスとバリアンスのトレードオフとは何か?
- 機械学習における過学習とはどのような状態か?モデルの複雑さとどのような関係にあるか?
- 統計学における不偏推定と最尤推定の関係はバイアスとバリアンスの観点からどうなっているか?
もし答えられるのであればこの記事を読む必要はないと思う。
だが少しでも曖昧な点があれば、この記事が理解をする上での助けになればと思う。
簡単な多項式の例
まずは例として簡単な多項式のfittingについて考えてみよう。
(図は[1]より引用)
僕たちは観測したデータからその裏にある真の分布、あるいはその分布を決定するパラメータを知りたいことが多い。
ここでは実験データを再現するために$\rm{sin}(2\pi{x})$の曲線を考え、そこからノイズを加えた10点のデータ点を生成してみよう。
ノイズはガウス分布に従うものとしている。

さて、我々の目標は観測値として得られる青い点から真の曲線である黄緑の線を予測することである。
予測するために以下のようなM次の多項式を考える。
y(x, \mathbf{w})=w_0+w_1 x+w_2 x^2+\ldots+w_M x^M=\sum_{j=0}^M w_j x^j
ここで$w_{j}$は$j$次のパラメータを表しているため、wを決定すれば予測関数も一意に定まることになる。。
この多項式で、以下で定義される最小二乗誤差が小さくなるようにwを決定し、予測関数を計算することにする。
E(\mathbf{w})=\frac{1}{2} \sum_{n=1}^N\left\{y\left(x_n, \mathbf{w}\right)-t_n\right\}^2
今N=10点のデータがあり、観測したデータのうちn番目のデータが$t_{n}$であり、xとwで決まる予測値が$y(x_n, \mathbf{w})$である。
$t_{n}$をうまく予測できているほどこの誤差は小さくなる。
M=0,1,3,9での結果が以下である。
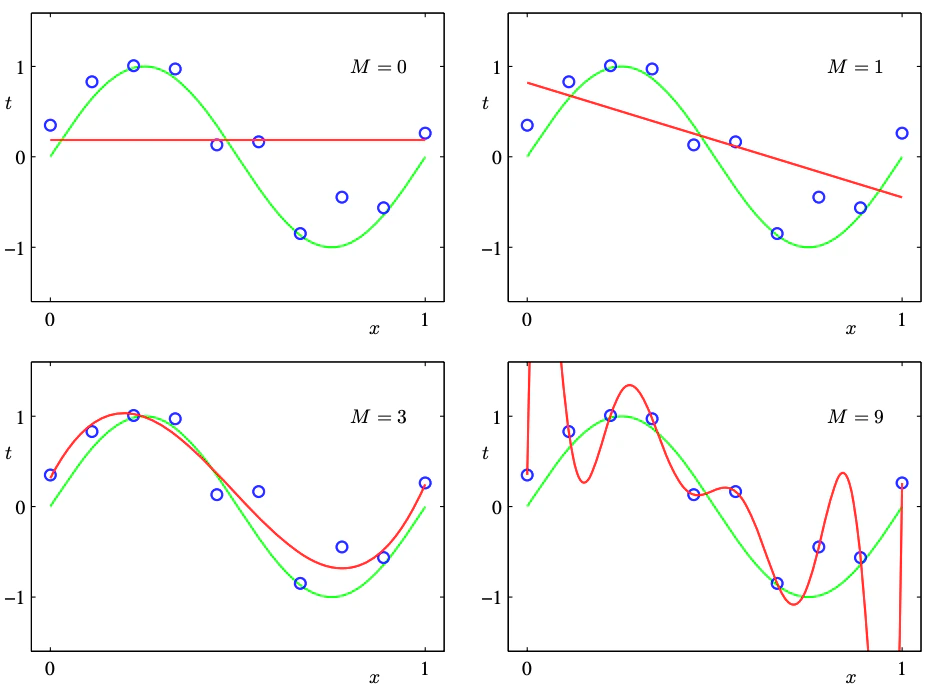
左上は$M=0$、つまりただのy=(定数)の直線による予測になっている。
そのためsinカーブを全然正確に捉えきれていない。
$M=3$くらいになるといい感じにsinカーブを再現できているように見える。
一方で$M=9$になるとデータ点の細かいノイズを拾いすぎて明らかに汎化性能を失っているように見える。
ここでいう汎化性能とは、10点のデータ点をもう一度生成しなおした場合に同じような結果が得られるか?をイメージするといいだろう。
$M=9$の結果は明らかに"たまたま"生じたノイズに過剰に適合してしまっている。
これを 過学習 (over fitting) と呼ぶ。
過学習を考える
この過学習の問題は多項式のfittingだけでなくなまざまな問題で考えることができる。
上記のM=9は言い換えれば
「予測モデルが複雑になりすぎて汎化性能を失っている」状態、
M=0は
「予測モデルが単純すぎて予測性能が低い」状態
を表していると言える。
機械学習でも同じだ。
決定木ベースの手法であれば木の本数や深さが増えて複雑になりすぎてしまった場合、
Deep Learningであれば層を深くしすぎた場合などは過学習に陥りやすい。
これを防ぐために 正則化項 (reguralization factor) と呼ばれる項を加えて先ほどの誤差の式を以下のように修正する。
\widetilde{E}(\mathbf{w})=\frac{1}{2} \sum_{n=1}^N\left\{y\left(x_n, \mathbf{w}\right)-t_n\right\}^2+\frac{\lambda}{2}\|\mathbf{w}\|^2
ここで、
$|\mathbf{w}|^2 \equiv \mathbf{w}^{\mathrm{T}} \mathbf{w}=w_0^2+w_1^2+\ldots+w_M^2$
である。
モデルが複雑になるほどwは高次まで大きな値を持つことになるためこの$|\mathbf{w}|^2$は大きくなる。
一方で式全体である$E(\mathbf{w})$をできるだけ小さくするようにパラメータwを決定するため、この項を加えることでモデルが複雑になりすぎないように調節することができる。
言い換えれば、モデルが複雑になりすぎた場合にペナルティを与えることができる。
$\lambda$は正則化をどれくらい強くするかを決定するパラメータである。
このようなパラメータは外部から設定してあげる必要があり、 ハイパーパラメータ (hyper parameter) と呼ばれる。
バイアスとバリアンス
では先ほどの例で、モデルの複雑さを調節しながら「10点のデータを生成して予測する」という動作を100繰り返してみよう。
以下の図の左の赤線は100回繰り返した結果のうち、見やすさを考慮して20パターンを選んで表示したものだ。
右側の赤線は100パターンの予測の平均値を表示しており、黄緑は真の直線である。
正則化の強さを$\lambda$で調節しているのに注目。
3段縦に並んでいるが、上の図にいくほど正則化の強さが強くなる = モデルが単純になる。
つまり下の図は複雑な多項式で予測していることになる。

さて、まずは左の図の3段に注目してみよう。
先ほどの例からも分かる通り、モデルが複雑になるほどデータの細かいノイズを拾ってしまう傾向にある。
そのため下に行くほど赤線同士がばらついていることがわかる。
一方で上の方がばらつきが少ない。
このばらつきを バリアンス (Variance) と表現する。
バリアンスは小さい方が望ましいが、モデルが複雑になるほどバリアンスが大きくなってしまっている。
次に右の図に注目してみよう。
上の図はモデルが単純すぎるため、100回分の平均値は緑の線をうまく表現できていない。
一方で下の図はうまく表現できていることがわかる。
このように平均値が真の値からどれくらい離れているかを バイアス (Bias) と表現する。
つまり、
- モデルが複雑すぎる場合: 低バイアス、高バリアンス
- モデルが単純すぎる: 高バイアス、低バリアンス
となっており、正則化項をどういじってもバイアスとバリアンスを同時に小さくすることはできない。
この関係を「バイアスとバリアンスのトレードオフ」と呼ぶ。
この図の中段のように、バイアスとバリアンスのバランスがちょうどよくなるような点を見つけるのが重要となる。
機械学習におけるバイアスとバリアンス
先ほどの例はシミュレーションだったため、10点のデータを生成するのを100回繰り返すことでバイアスとバリアンスの
関係を簡単に可視化できた。
機械学習、特に教師あり学習の場合、学習に使えるデータ全体を学習データ (training data)と検証データ (validation data)に分割して学習することが多い。
データ全体を使って学習すると過学習に陥りやすくなるため、学習自体は学習データを使って学習し、誤差の評価にはバリデーションデータを使うというわけだ。これをout-of-fold法と呼ぶ。
さらに汎化性能を高めるため、実際には 交差検証(クロスバリデーション: cross validation) と呼ばれる方法がよく用いられる。
例えば全体の分割数を4つにする場合を考える。[1]
(「4つのfoldに分割する」という言い方をする)
以下のように赤い部分のデータをバリデーションに使い、残りの白い部分3つを学習に使う。
これを全部の4パターンで計算して、最終的にはその平均値を採用するというものだ。

それぞれのfoldでの結果のばらつきが大きければバリアンスが大きい = 過学習気味になっていると判断できるかもしれない。
ただし、それぞれのfoldですでに学習データと検証データに分割して学習しているため、すでにある程度過学習は抑制できていることが多い。
数式で考えるバイアスとバリアンス
さて、ここまででなんとなくのイメージはできてきたと思うが、今度は数式を使って考えてみる。
より一般化して、真のパラメータを$\theta$、予測したパラメータを$\hat{\theta}$と置くことにしよう。
$\theta$は任意のパラメータを考えることができる。
例えば真の分布がガウス分布に従っている場合、期待値$\mu$や分散$\sigma^2$などがパラメータとして考えられるだろう。
(先ほどの回帰の例でも、データ点は真の値を中心にガウス分布で生成していたことを思い出そう)
予測したパラメータが真のパラメータからどれくらいばらついているを知りたい場合、
$E\left[(\hat{\theta}-\theta)^2\right]$ のような量、つまり分散を考えればよさそうだ。
ここでE[]は期待値を表す。
ここで$\theta$は真のパラメータであるため観測値から直接知ることはできない。
一方で、観測値$\hat{\theta}$の期待値$E[\hat{\theta}]$であれば上記のシミュレーションのように何度もデータの生成を繰り返すことで、計算することができそうだ。
これを使って分散の式を書き換えてあげよう。
\begin{aligned}
E\left[(\hat{\theta}-\theta)^2\right] & =E\left[(\hat{\theta}-E[\hat{\theta}]+E[\hat{\theta}]-\theta)^2\right] \\
& =E\left[(\hat{\theta}-E[\hat{\theta}])^2\right]+E\left[(E[\hat{\theta}]-\theta)^2\right]+2 E[(\hat{\theta}-E[\hat{\theta}])(E[\hat{\theta}]-\theta)] \\
& =E\left[(\hat{\theta}-E[\hat{\theta}])^2\right]+(E[\hat{\theta}]-\theta)^2
\end{aligned}
ここで2行目から3行目においては
$E[E[\hat{\theta}]]=E[\hat{\theta}]$
であることを用いている。
ここで最後の式に注目してみよう。
最初の項は観測値$\hat{\theta}$の観測値の期待値$E[\hat{\theta}]$からのばらつき(=分散)を表しており、$V[\hat{\theta}]$と書くことができる。
これがバリアンスの正体だ。
2つ目の項は真のパラメータから観測値の期待値のズレをに2乗したものである。
このズレがバイアスの正体だ。
従ってこの式は
\begin{aligned}
E\left[(\hat{\theta}-\theta)^2\right]
& =V[\hat{\theta}]+b(\theta)^2
\end{aligned}
と書くことができる。
つまり、観測したパラメータの真のパラメータからの分散はバイアスとバリアンスの和で表すことができるということだ。
これをバイアス-バリアンス分解という。
もしバイアスを小さくしようと思えば2項目中の$E[\hat{\theta}]-\theta$が小さくなるように$\hat{\theta}$を選べばよさそうだが、このように選んだ皺寄せとして1項目のバリアンスが大きくなってしまう。
逆に1項目のバリアンスが最も小さくなるように$\hat{\theta}$を設定してしまうと、今度は2項目のバイアスが大きくなってしまうというわけだ。
不偏推定量と最尤推定量
最後に少し異なるアプローチからバイアスとバリアンスの関係を理解していく。
統計学において点推定を行う場合、不偏推定と最尤推定という2つのアプローチがある。
ある真のガウス分布があるとして、期待値、分散を表すパラメータをそれぞれ$\mu, \sigma^2$と表すとする。
そこからいくつかの点を標本として得たとして、そこから真のパラメータを予測したい。
言い回しはやや異なるものの、最初に出した回帰の例とほぼ同じような状況だ。
不偏推定量、最尤推定量として予測した期待値、分散はそれぞれ次のようになる。
- 不偏推定量
\hat{\mu} = \frac{1}{n}\Sigma{X_{i}}\\
S^2=\frac{1}{n-1}\Sigma{(X_{i}-\hat{X})^2}
- 最尤推定量
\hat{\mu} = \frac{1}{n}\Sigma{X_{i}}\\
\hat{\sigma}^2=\frac{1}{n}\Sigma{(X_{i}-\hat{\mu})^2}
期待値に関してはどちらも同一だが、分散に関しては異なる。
不偏推定ではn-1で割っており、最尤推定ではnで割っている。
自分は最初この違いが全然わからなかった。
不偏推定量とは
不偏推定量は英語だと"unbiased estimator"。
つまり、バイアスがゼロになるように定義されている。
$E[\hat{X}]=\mu$, $E[S^2]=\sigma^2$なるということだ。
計算は省略するが、確かに実際に計算すると等しくなることが示せるので、興味のある人はやってみてほしい。
定義上バイアスは0だが、バリアンスが小さくなることは保証されていない。
そのため複数回実験を繰り返すことができればその期待値は真のパラメータと一致するが、
「10回データ生成するのを1回のみ行う」のような場合は真の値からずれる確率が大きい。
ではなぜn-1で割るのだろうか?
直感的には分散においては自由度がn-1個になるため、と考えることができる。
もし真の$\mu$がわかっていれば、10個の独立な分散を計算することが可能だが、実際の計算では観測値の$\hat{\mu}$を使うことになる。
つまり、10個のパラメータのうち9個を決めれば残りの一個は自動的に決まってしまう。
そこで、自由度も考慮してn-1で割ることでバイアスを取り除いているというわけだ。
最尤推定量とは
最尤推定とは尤度、つまり確率が最大になるようにパラメータを計算する方法だ。
ガウス分布を仮定して10個のデータを生成した場合、それぞれのデータは同一のガウス分布から確率にしたがって抽出されたと考えることができるだろう。
そこから10個の確率の積が定義できるため、その値が実現される確率を最大化するようにパラメータを予測するのだ。
確率を最大化する、と言う観点から"バリアンスが小さくなる"ように計算されているとも言える。
だが不偏性は保証されていないため、バイアスはゼロにはならない。
最尤推定においてはとにかく観測された値が得られる確率が最大になることだけを重視するため、不偏推定のような自由度の調節は行わず、データ点nでそのまま割り算する。
そのため不偏推定で求めた分散よりもやや小さい値が得られる。
実験して可視化してみよう
直感的に理解するために、Pythonで可視化してみよう。
$mu=5, \sigma=20$に従うガウス分布から10個のサンプルを抽出して分散の不偏推定量、最尤推定量をそれぞれ計算する。
この作業を10000回繰り返してplotしてみる。
import numpy as np
import matplotlib.pyplot as plt
# 平均と分散の設定
mu = 0
sigma_squared = 1
# 標本数と試行回数
sample_size = 10
num_trials = 10000
# 不偏推定量と最尤推定量を格納するリスト
unbiased_estimates = []
mle_estimates = []
# 試行回数分繰り返し
for _ in range(num_trials):
# ガウス分布から標本を抽出
samples = np.random.normal(loc=mu, scale=np.sqrt(sigma_squared), size=sample_size)
# 不偏推定量を計算
unbiased_estimate = np.var(samples, ddof=1)
mle_estimate = np.var(samples, ddof=0)
# 結果をリストに追加
unbiased_estimates.append(unbiased_estimate)
mle_estimates.append(mle_estimate)
# 不偏推定量と最尤推定量の平均値を計算
mean_unbiased_estimate = np.mean(unbiased_estimates)
mean_mle_estimate = np.mean(mle_estimates)
# バイアスとバリアンスを計算
bias_unbiased = mean_unbiased_estimate - sigma_squared
variance_unbiased = np.var(unbiased_estimates)
bias_mle = mean_mle_estimate - sigma_squared
variance_mle = np.var(mle_estimates)
fig, (ax1, ax2) = plt.subplots(nrows=2, ncols=1, figsize=(6, 8))
# 不偏推定量のヒストグラム
ax1.hist(unbiased_estimates, bins=30, density=True, alpha=0.5, color='blue', edgecolor='black')
ax1.axvline(x=sigma_squared, color='red', linestyle='--', label='True Variance')
ax1.axvline(x=mean_unbiased_estimate, color='blue', linestyle='-', label='Mean Unbiased Estimate')
ax1.set_xlabel('Unbiased Variance Estimates')
ax1.set_ylabel('Density')
ax1.set_title('Histogram of Unbiased Variance Estimates (n=10, 10000 trials)')
ax1.legend([f'True Variance',
f'Mean Unbiased Estimate\nBias: {bias_unbiased:.3f}\nVariance: {variance_unbiased:.3f}'])
# 最尤推定量のヒストグラム
ax2.hist(mle_estimates, bins=30, density=True, alpha=0.5, color='green', edgecolor='black')
ax2.axvline(x=sigma_squared, color='red', linestyle='--', label='True Variance')
ax2.axvline(x=mean_mle_estimate, color='green', linestyle='-', label='Mean MLE Estimate')
ax2.set_xlabel('MLE Variance Estimates')
ax2.set_ylabel('Density')
ax2.set_title('Histogram of MLE Variance Estimates (n=10, 10000 trials)')
ax2.legend([f'True Variance',
f'Mean MLE Estimate\nBias: {bias_mle:.3f}\nVariance: {variance_mle:.3f}'])
plt.tight_layout()
plt.show()

上の図は不偏推定、下の図は最尤推定で求めた分散である。
両者の違いはn-1で割るかnで割るかだけである。
コード中ではnp.var()で分散を計算する際にddof=0/1でこれらを制御している。
真の分散パラメータ$\sigma^2$を赤の波線で同時にplotしている。
ヒストグラムで分布を表示しているが、平均値を直線で重ね書きしている。
また、legendの中に真のパラメータと推定値から計算したbiasとvarianceを表示している。
上の不偏推定の図では平均値である青の線と赤の波線がほぼ一致しており、バイアスが小さい一方でバリアンスは大きい。
一方で下の最尤推定の図ではバイアスがある一方でバリアンスが小さいことがわかる。
最尤推定はn-1ではなくnで割っているため全体的に分布が左寄りになっていおり、それによりバイアスが発生していることがわかる。
一方で分布は右にtailを引くようになっており、分布が全体的に左寄りになる->外れ値の値も左側に寄るため、バリアンスが小さくなっていると考えることができて面白い。
分散は定義上0以上であるため左側にはtailは存在したないが、大きな値は低確率で発生するため左にtailができていると考えることができる。
サンプル数は正義
さて、散々バイアスとバリアンスのトレードオフの話をしていたが、これらは"限られたサンプル数しか使えない"という仮定を置いていた。
もしサンプル数を増やせるのであれば増やすに越したことはない。
サンプル数が無限にあれば理論上バイアスもバリアンスもゼロにできる。
実際の実験ではそんなことは稀なのだが、もしシミュレーションなどで簡単にサンプル数を増やせるのであれば、そうすることで全て解決可能かもしれない。
次の図は最初の例で過学習になってしまったM=9での多項式fittingの例だ。[1]
左がN=15,右がサンプル数をN=100まで増やした時のものだ。
同じ$M=9$の字数でもサンプル数が増えることで過学習が抑制されていることがわかる。

まとめ
バイアスとバリアンスについて、自分自身ふわっとして理解しかなかったためこれを機にまとめてみた。
統計や機械学習など幅広い分野で必要な知識であるため、しっかりと身につけたい。
ちなみにこの記事に出てくる可視化コードはすべてchat-GPTさんに書いてもらった。
めちゃくちゃ便利だね。
参考文献
[1] パターン分析と機械学習 上