どういう記事か?
- 最近「ゼロから作るニューラルネットワーク」という本を読んで学んだニューラルネットワークの4つの最適化手法についてまとめようと思います
- 基本的には本がベースになっていますが、**どうイメージしたらわかりやすいか?**ということに重点を置いて個人的な解釈をまとめた記事です。なので、厳密な数式や応用などは載せていません。
- ネットで調べるとこの記事よりももっと詳しい説明が腐るほど出てきますが、一方で本とほぼ同じ説明をそのまんまQiitaにまとめた記事も散見されたので、自分なりの解釈をまとめておく意味も少しはあるかなと思い、記事を書くに至りました
- Momentumという手法の説明にかなり偏ってしまいましたが、ご容赦ください。。
- 僕はニューラルネットワークについては初学者、初心者なので、間違っている箇所やアドバイスなどがあればコメントもらえると喜びます
ゼロから作るニューラルネットワーク
今や機械学習の専門でない一般の人でも名前だけは知っている「ニューラルネットワーク」「ディープラーニング」。
機械学習の1つで、画像認識などによく使われているやつですね(Google画像検索みたいなやつ)
このニューラルネットワークを勉強する際におそらく最も日本で読まれている本が「ゼロから作るDeep Learning」です。
よく読まれているだけあって、入門書としては非常に良書だと思います。(何様なんだ)
機械学習における"学習"
ニューラルネットワークに限らず、機械学習の目的は学習データ(教師データ)をもとに学習し、未知のデータの予測を行う、というものです。
例えば画像認識で言えば猫の画像を大量に学習させて、新しく画像を見せた時に「その画像か猫かどうか?」を答えさせる、というものですね。
通常の機械学習であれば「特徴量を指定して学習しなければならない」 という制約がありますが、ディープラーニングの場合は学習する中で画像から勝手に特徴量を見つけてくれるという利点があります。
最適化ってなーに?
学習とはいったい何をしているのか?というと、最適な重みパラメータを探す作業に当たります。
最適なパラメータが求まればそれを元に未知のデータから正解を予測できるようになります。
これを最適化(optimize)と言います。
最適化のためには損失関数(コスト関数)と呼ばれる関数を定義し、最小になるパラメータを探します。
損失関数としては最小二乗誤差やLogLoss (交差エントロピー誤差)などが用いられ、いずれも小さい値を取るほどうまく分類(or 回帰)できているということになります。
ではどうやって損失関数の最小の場所を探すか?を考えます。
この本では以下の4種類の最適化手法が紹介されています。
- SGD(勾配降下法)
- Momentum
- AdaGrad
- Adam
SGD
勾配降下法(Gradient Stochastic Descent)の略。
最適化手法の中で一番スタンダードなやつで、以下の式で重みを更新します
\boldsymbol{W} \leftarrow \boldsymbol{W} - \eta\frac{\partial{L}}{\partial{\boldsymbol{W}}}
損失関数の傾きを計算して損失関数が小さくなるように更新していきます。
「坂道を下に下っていけばいつかは一番低いところに辿りつけるだろう」という考えです。
$\eta$は学習率と呼ばれるやつで、小さすぎるとなかなかたどり着かず、大きすぎると一度に大きく動きすぎてとんでもない方向に飛んで行ってしまったりします。
なので、適切な値を最初に設定してあげる必要があります。
個人的にはゴルフのようなものだと思っていて、ちょこっとの力でしか打たないといつまでたってもホールにたどり着かないし、かといって力任せに打ちすぎるとホールを通り越してとんでもない方向にいってしまいます。
そんなSGDですが、常にうまくいくとは限りません。例えば$f(x,y)=\frac{1}{20}x^{2}+y^{2}$のような関数を考えます。お椀型をx軸方向にビヨっと引き伸ばしたような形ですね。
この関数でSGDをやってみた結果が以下です。
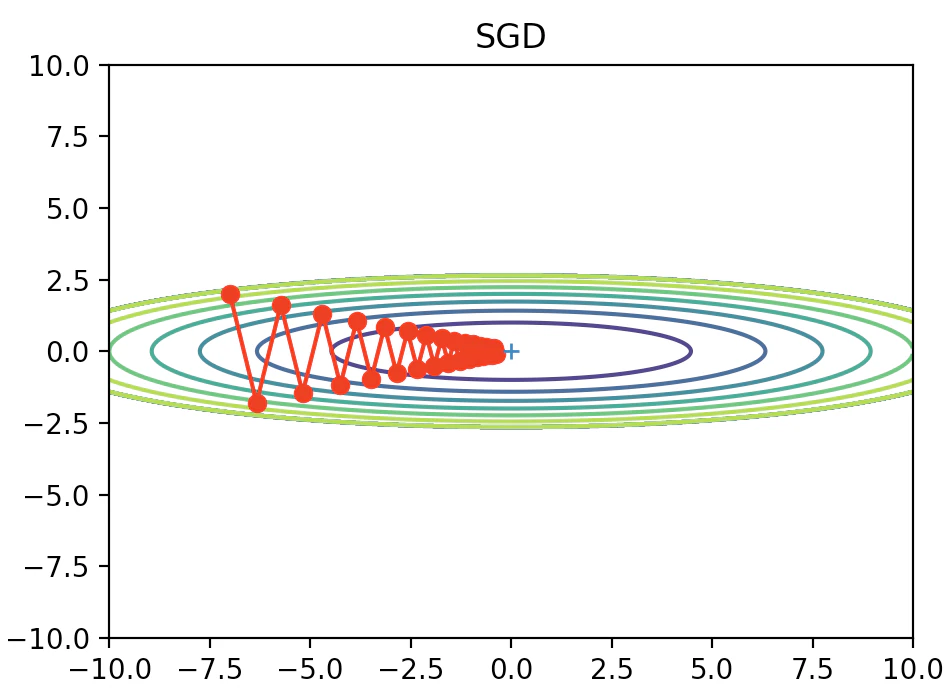
縦方向の勾配が急なので縦にギザギザしながら原点(損失関数が最小の点)に向かっていってるのがわかります。かなり効率の悪い動きをしていますね。これを改善したのが以下に出てくる3つの方法です。
Momentum
Momentumとは物理学で出てくる運動量のことです。まずは重みの更新式を見てみましょう。
\boldsymbol{v} \leftarrow \alpha\boldsymbol{v} - \eta\frac{\partial{L}}{\partial{\boldsymbol{W}}}\\
\boldsymbol{W} \leftarrow \boldsymbol{W} +\boldsymbol{v}
式を見ただけだとピンと来ないかもしれないので、まずは先ほどの関数に適用した結果を見てみましょう。
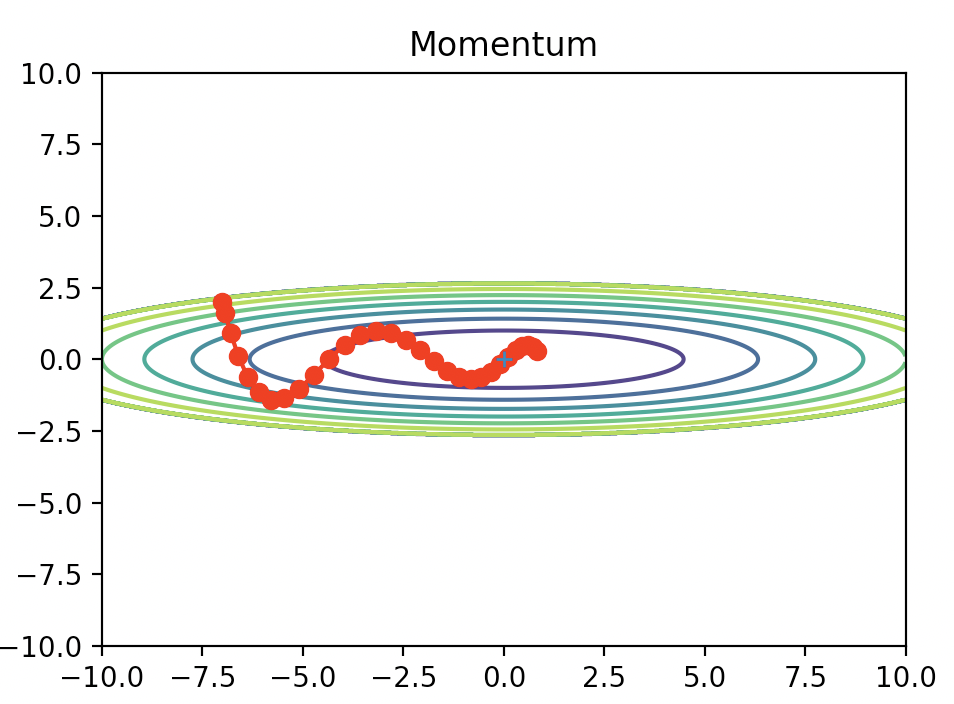
滑らかな動きになりましたね。なんとなくお椀の中をボールが転がったような軌跡を描いていて、自然です。
なぜ滑らかな動きになるのか?以下に簡単な概念図を書いてみました。
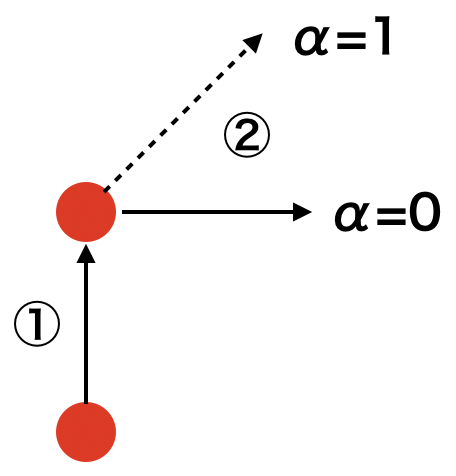 一つの例を考えてみましょう。①が最初の学習、②が2回目の学習を表すとします。
最初に$\frac{\partial{L}}{\partial{\boldsymbol{W}}}$を計算した結果、①のように上方向のベクトルとなったとします。その方向にしたがって$\eta$の大きさを掛けた分だけ移動したとします。
ここで②の重みを更新を考えます。再度Lの微分を計算した結果、今度は斜面の下り坂の方向が上ではなく右方向に変化していたとしましょう。SGDの場合だと①と同じように今度は②で右方向に進みます。
結果として直角に右に移動していますね。これがSGDのガタガタの原因で、不自然は軌道になってしまっています。
ここでMomentumの式を確認してみましょう。更新式の中に$\alpha\{v}$の項がありますね。
これは①の時の$\frac{\partial{L}}{\partial{\boldsymbol{W}}}$にあたります。
簡単のため$\alpha=1$だったとしましょう。
すると$\alpha\boldsymbol{v}-\eta\frac{\partial{L}}{\partial{\boldsymbol{W}}}$の部分は①と②のベクトルの和になっていることがわかります。
すると②の方向は右ではなく斜め45度で右上に進むことになります。
このように、**前回の重み更新時の傾きを次回の重み更新に反映させることで、動きが滑らかになります。**
αは前回の更新時の傾きをどれくらい影響させるかというパラメータになります。
αが0なら前回の重み更新時の傾きは一切反映しないので右方向、つまりSGDと同じになります。
一つの例を考えてみましょう。①が最初の学習、②が2回目の学習を表すとします。
最初に$\frac{\partial{L}}{\partial{\boldsymbol{W}}}$を計算した結果、①のように上方向のベクトルとなったとします。その方向にしたがって$\eta$の大きさを掛けた分だけ移動したとします。
ここで②の重みを更新を考えます。再度Lの微分を計算した結果、今度は斜面の下り坂の方向が上ではなく右方向に変化していたとしましょう。SGDの場合だと①と同じように今度は②で右方向に進みます。
結果として直角に右に移動していますね。これがSGDのガタガタの原因で、不自然は軌道になってしまっています。
ここでMomentumの式を確認してみましょう。更新式の中に$\alpha\{v}$の項がありますね。
これは①の時の$\frac{\partial{L}}{\partial{\boldsymbol{W}}}$にあたります。
簡単のため$\alpha=1$だったとしましょう。
すると$\alpha\boldsymbol{v}-\eta\frac{\partial{L}}{\partial{\boldsymbol{W}}}$の部分は①と②のベクトルの和になっていることがわかります。
すると②の方向は右ではなく斜め45度で右上に進むことになります。
このように、**前回の重み更新時の傾きを次回の重み更新に反映させることで、動きが滑らかになります。**
αは前回の更新時の傾きをどれくらい影響させるかというパラメータになります。
αが0なら前回の重み更新時の傾きは一切反映しないので右方向、つまりSGDと同じになります。
次に、なぜこの手法がMomentumと呼ばれるのかを考えてみます。物理学(ニュートン力学)では運動量は質量(m)と速度のベクトル($\boldsymbol{v}$)の積になります。
運動量と力積($F\Delta{t}$)の関係という以下のような関係式が成り立ちます。
m\boldsymbol{v_{before}}+F\Delta{t} = m\boldsymbol{v_{after}}
これも図で考えてみましょう
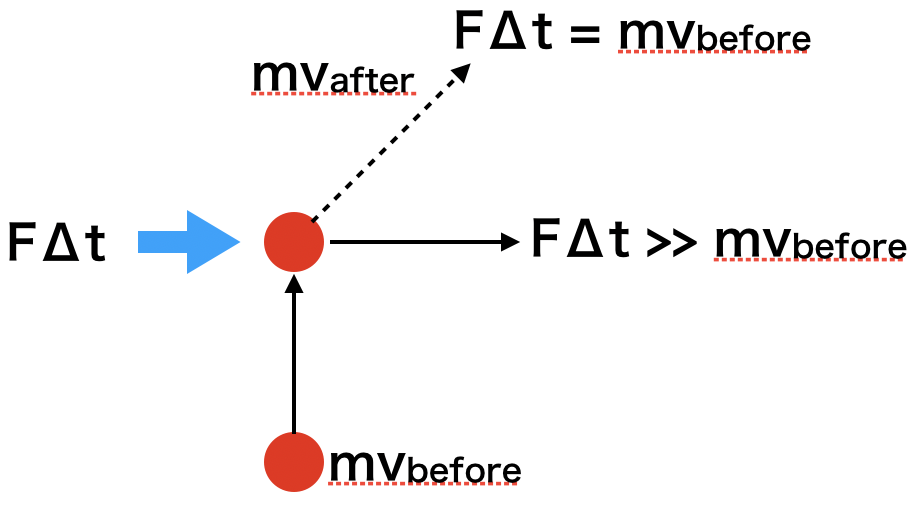
上方向に運動量$m\boldsymbol{v_{before}}$で運動している物体が右方向に力積を受けた場合に物体の運動がどう変化するかを表します。
もし力積の大きさが最初の運動量と同じであれば斜め45度に右上に、力積の大きさがそれより大きくなると、より右側に物体は弾き飛ばされます。
これはさっきの概念図と非常に似ているということがわかると思います。
Momentumによって描かれた軌跡のことを先ほどお椀の中をボールが転がるようにと表現しましたが、実際の力学の物理法則と似たような式になっているためこのような軌跡になるということがわかると思います。
イメージ的には**上に進んでいるところに急に右方向に力がかかっても急に直角には曲がれないよ!**というのを重みの更新に適用したという感じですかね。
AdaGrad
Momentumの説明が非常に長くなってしまいましたが、残りの方法についてもさらっと説明したいと思います。
SGDの説明の時に、重みの更新をゴルフに例えました。SGDでは毎回の学習で同じ学習率で更新します。つまりゴルフで言えば毎回同じ強さで球を打っていることになります。
しかし、ゴルフの場合、一打目は強く打って飛距離を伸ばし、ホールが近づいてきたらだんだん弱く打って微調整していきますよね?
同様のことがニューラルネットワークでも適用可能です。つまり最初の学習時は大きく重みを更新し、だんだんと更新する大きさを減らしていくという方法です。
この手法をAdaGradといいます。
以下の式をみてみましょう。
\boldsymbol{h} \leftarrow \boldsymbol{h} + \left(\frac{\partial{L}}{\partial{\boldsymbol{W}}}\right)^{2}\\
\boldsymbol{W} \leftarrow \boldsymbol{W} -\frac{1}{\sqrt{\boldsymbol{h}}}\eta\frac{\partial{L}}{\partial{\boldsymbol{W}}}
下の式で$\sqrt{\boldsymbol{h}}$で割っていますね。これは毎回重みを更新するごとに更新する大きさが小さくなっていくことを意味します。
上の式の$\left(\frac{\partial{L}}{\partial{\boldsymbol{W}}}\right)^{2}$は行列の全要素を2乗したものを意味します。(内積ではないので、スカラーにはならない)
つまり、傾きが急であるほど大きく重みを更新し、だんだん小さくしていくということですね。
非常に理にかなっています。
これを実際に先ほどの関数に適用したのが以下になります。
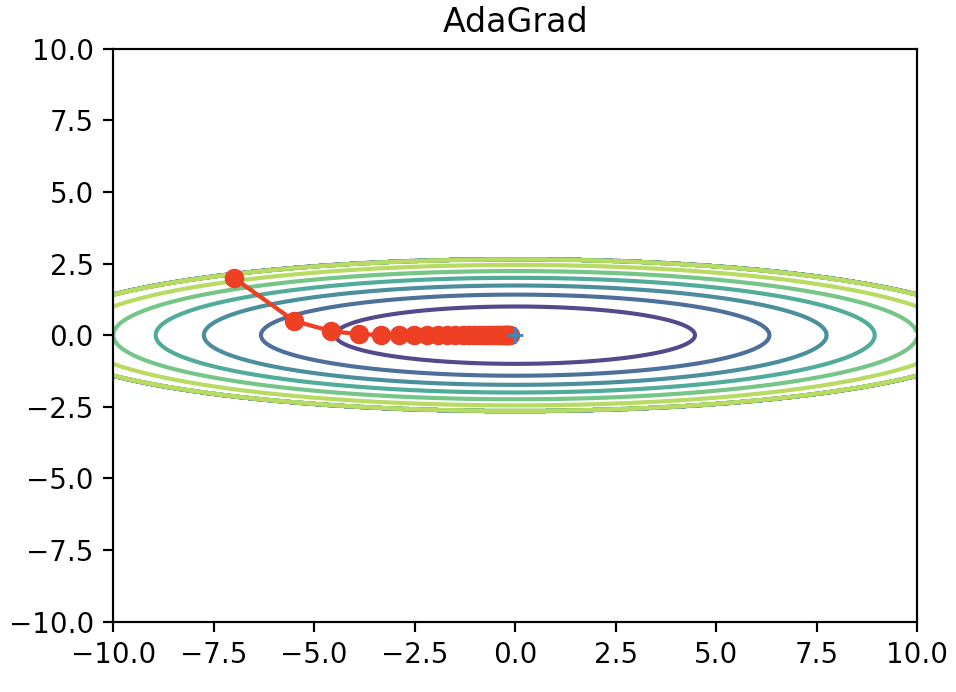
今回の例だと非常にうまくいっているように見えますね。
Adam
最後にAdamについて紹介します。
Adamは簡単に言えばMomentumとAdaGradのいいこと取りしたやつです。
数式含め、ここでは詳しく触れません。
例によって関数に当てはめると以下のような図になります。
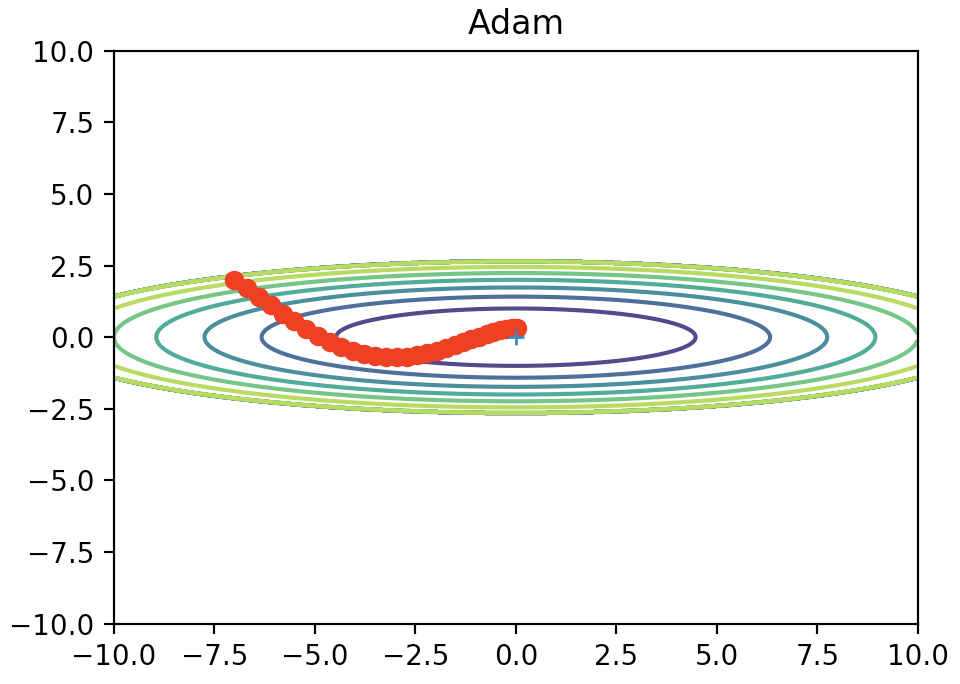 これもSGDと比べるといい感じに最小値にたどり着けてますね。
これもSGDと比べるといい感じに最小値にたどり着けてますね。
まとめ
- ニューラルネットワークで用いる4つの最適化手法を(かなりざっくり)紹介しました
- 「結局どれ使いばいいの?」という疑問ですが、万能な方法は存在しないので臨機応変に使い分ける必要がありそうです
- SGDは今でもよく用いられていますが、最近ではAdamが人気なようです
備考
- 今回図をplotするのに使ったコードは以下のgitで公開されています
- https://github.com/oreilly-japan/deep-learning-from-scratch