はじめに
アンジャッシュ渡部さん(以下敬称略)の記者会見が世間を賑わせましたね。
この記者会見を見て皆さんいろいろと思うところがあるとは思いますが、僕は以下の記事が気になりました。
https://sn-jp.com/archives/22422
今回の記者会見の受け答えで、渡部が特定のワードを連発していたというものです。
特に「本当に」というワードに限っては100回以上使われていました。
これだけ偏った語彙の言葉が連発された記者会見を見て、僕はこう思いました
渡部のセリフをディープラーニングで学習して、渡部っぽい文章を自動生成する渡部AIを作りたい!
そうして勢いのままにこの記事を書いています。
結構長くなってしまったので、手っ取り早く結果だけ知りたい人は最後の「実際にやってみた」だけでも読んでもらえればと思います。
自然言語処理の勉強をしながら書いたので間違ってる箇所や正確でない箇所があるかもしれません。
変なところがあったら教えてもらえると喜びます。(そしてひっそりと直します)
この記事でやること、やらないこと
- この記事では最終的に
RNNという手法を使って渡部のAIを作り、それを通じてディープラーニングの仕組みを学びます - 近年ではさらに精度の高い手法が多く出ています(
Transformer、BERTといったAttentionをベースとした手法など)が、それらについては触れません - 記者会見はインタビュアーの質問と渡部の答えがセットになっていますが、今回は渡部の発言のみを扱います
- 受け答えを実装するにはseq2seqと呼ばれるさらに高度な実装が必要となるため
環境
-
Mac OSXで動かしてますが、Linux環境でも動くと思います -
Pythonで動かします - ここで紹介するコードはすべて「ゼロから始めるDeep Learning 2」のコードを参考にしています
- https://github.com/oreilly-japan/deep-learning-from-scratch-2
- クラスや関数の実装について、この記事に書いてない部分は上の
GitHubと同様のものを使っています
下準備 - 渡部のデータを用意する -
さて、渡部っぽい文章を自動生成するにはまず学習のベースとなる文章が必要です。
これをコーパスといいます。
今回は「記者会見における渡部の全発言」を文字に起こしたものがコーパスになります。
ありがたいことに、以下のサイトに受け答えの全文が書いてあったので、渡部の受け答えの部分だけをコピペしてコーパスとします。
本当は学習するときにはもっと大量の文章が必要なのですが、今回はこれで頑張ってみます。
基本的にインタビュアーが一回喋って渡部が一回答えて...といった流れとなります。
渡部の一回の回答を1行にしてwatabe.txtとしてテキストファイルにまとめます。
最初の3行は以下です。
本日は大変お忙しい中お集まりいただき、コロナ感染対策にご協力いただき、ありがとうございます。このたび私がしてしまった大変軽率な行動により、関係者のみなさまにご迷惑をおかけし、多くの視聴者の皆様に大変不快な思いをさせてしまったことを心より深くおわび申し上げます。本当に申し訳ございませんでした。会見が遅くなってしまったこと、不適切な場所での不貞行為、深く深くお詫び申し上げたいと思います。本当に申し訳ございませんでした。
概ね、報道にあった通りです。
最低な行為だったと思います。
...以下略
さて、このままで学習に使えるかというと、実は使えません。
日本語の場合、コンピュータに読み込ませる際に単語の切れ目がわからないからです。
その点英語は分かりやすいです。
もともと単語の間にスペースがあるので、スペースで区切ってあげれば勝手に単語に分割できます。
したがって、まずはこの文章を単語ごとに分割してあげる必要があります。
これを分かち書きといい、このよう品詞ごとに分解して解析することを形態素解析と言ったりします。
日本語の場合はMeCabという形態素解析エンジンを使うことで分解できます。
import MeCab
# 前準備
word_list = []
for line in open("./watabe.txt", 'r'):
wakati = MeCab.Tagger("-Owakati")
words = wakati.parse(line).split() # 分かち書きする
joined_words = " ".join(words) # 分解した単語をスペースを間に入れて繋げる
word_list.append(joined_words) # 一つの文章にする
print(line) # 例:概ね、報道にあった通りです。
print(words) # 例:['概ね', '、', '報道', 'に', 'あっ', 'た', '通り', 'です', '。']
print(joined_words) # 例: 概ね 、 報道 に あっ た 通り です 。
単語ごとに分解できたらdataset以下に保存します。
ちなみにディレクトリ構造は上に貼ったGitHubのリポジトリと同じにしており、このコードはch07/で書いて実行しています。
with open("../dataset/watabe.train.txt", mode='w') as f:
for i, line in enumerate(word_list):
new_line = word_list[i]
f.write(new_line+"\n")
これで、下準備ができました。
どうやってコンピュータに言葉を理解させるか
さて、データの準備ができましたが、そもそもコンピュータに言語を理解させるにはどうしたらいいでしょう?
このあたりは自然言語処理という分野でよく研究されており、近年では分布仮説と呼ばれる考え方が主流となっています。
これは「単語の意味は周囲の単語によって決まる」という考え方です。
例えば以下の文章を考えてみましょう。
本当に もう バカ な こと を した と
これ だけ 騒動 に なっ て 、 バカ な ん です けど
本当に いい加減 な こと を し て バカ な こと を し て しまっ た
記者会見の内容からの抜粋です。
この3つの文には全て「バカ」という言葉が出てきます。
このような文章を大量に学習していけば、前後の文脈から
「バカというのは愚かというニュアンスの意味だな」
ということが分かるわけです。
ここでの重要なポイントは、「バカ」という言葉自体に辞書のような意味付けをしなくても、前後の文脈によって自然と意味が決まってくるということです。
ニューラルネットワークではこれを推論ベースの問題に置き換えます。
推論ベースとは、例えばコーパスが
本当に いい加減 な こと を し て バカ な こと を し て しまっ た
であり、「バカ」という言葉の意味を学習したければ
本当に いい加減 な こと を し て ◯ な こと を し て しまっ た
という穴埋め問題にすり替えてしまうのです。
前後の文脈から◯に入る単語を推論して、答えあわせをしながら学習を進めていくのです。
ではニューラルネットワークやディープラーニングとはなんなのかをざっくり説明していきます。
ニューラルネットワークとディープラーニング
タイトルに「AI」というかなりふわっとした言葉が入ってますが、ここでは機械学習を用いた自然言語処理を指します。
機械学習とは、かなり大雑把に言えば学習データを用いて学習し、未知の問題を分類したり予測したりする方法です。
YouTubeの動画のレコメンドやGoogleの自動翻訳、Siriの音声解析、迷惑メールのフィルタイングなどなど、あらゆる分野に応用されています。
その中の一つの手法としてニューラルネットワークがあります。
ニューラルネットワークは以下のようにたくさんのニューロン(◯で書かれてるやつ)が繋がったような構造をしています。
人間の脳が情報を伝達する仕組みに似ています。(シナプスとかいうやつ)
入力信号が伝達されていくつかの層を通って最終的に出力層に到達します。
このニューラルネットワークにおいて層を何層にも深く重ねたものがディープラーニングと呼ばれるもので、自然言語処理の他に画像認識などの分野でよく用いられます。
 wikipediaより
wikipediaより
単純なニューラルネットワークの例
では、何度も出てきた以下のコーパスをもう一度使ってCBOWと呼ばれる2層から成る単純なニューラルネットワークを考えてみます。
本当はコーパスといえば文章の全体を指すのですが、ここでは簡単のため以下の文章を全コーパスと仮定します。
本当に いい加減 な こと を し て バカ な こと を し て しまっ た
単語のままだと扱いづらいので、一つ一つの単語をベクトル化することを考えます。
まずは出てくる単語ごとにIDを振ります。
一つのIDにつき一つの単語が紐づくようにしたいので、重複は除きます。
本当に:0
いい加減:1
な:2
こと:3
を:4
し:5
て:6
バカ:7
しまっ:8
た:9
これで出てくる単語全てにIDを付けられました。
今度はこれをone-hotベクトルと呼ばれる形にします。
本当に :[1,0,0,0,0,0,0,0,0,0]
いい加減 :[0,1,0,0,0,0,0,0,0,0]
な:[0,0,1,0,0,0,0,0,0,0]
こと :[0,0,0,1,0,0,0,0,0,0]
を :[0,0,0,0,1,0,0,0,0,0]
し:[0,0,0,0,0,1,0,0,0,0]
て :[0,0,0,0,0,0,1,0,0,0]
バカ :[0,0,0,0,0,0,0,1,0,0]
しまっ :[0,0,0,0,0,0,0,0,1,0]
た:[0,0,0,0,0,0,0,0,0,1]
これで単語をベクトルで書けたので、ニューラルネットワークのinputとします。
このように単語をベクトルで表現することを分散表現と言ったりします。
さて、これらを使って「バカ」の前後の単語である「て」「な」から正解である「バカ」を推測するニューラルネットワークを考えます。

「て」、「な」はそれぞれ10個の要素を持つベクトルです。
出力と入力の間には中間層があります。
ここでは中間層の要素の数を3つに設定してみます。
このときinputのベクトルにWinの行列を掛け合わせたものが中間層になります。
ここでは要素数が7->3になっているので、Winは7×3の要素を持つ行列です。
中間層にさらにWoutを掛けることで最終的な出力になります。
このとき、正解となるベクトルは「バカ」なので、答えあわせをして正解に近くなるようにパラメータWを更新していきます。
これがニューラルネットワークにおける「学習」です。
Wを重みと言います。
学習の目的は適切は重みWを求めることです。
適切なWを求めることができれば、新しい入力に対してどのような出力が適切か「予測」することができます。
ここでは単純な2層のモデルを考えていますが、層を重ねれば精度も上がっていきます。(ディープラーニング)
単純なニューラルネットの問題点
実は上であげた単純なニューラルネットワークの例にはいくつかの問題があります。
まず、上の例だと、注目している単語(=target)の前後1単語の文脈しか見れていないということです。
実際には2つ前や3つ前...と入力のベクトルを増やす(これをwindowサイズを増やすという)ことも可能ですが、どこまで広げればいいのか?という疑問が残ります。
また、windowサイズを広げただけだと実は前後関係が把握できないという問題もあります。
上の例では「て」ベクトルと「な」ベクトルは重みWinを掛けた後に平均をとったものが中間層に出力されます。
平均というのは要は足し算なので「て」が前で「な」が後、といった前後関係の情報が失われてしまっています。
RNNとLSTM
ここでRNN(Recurrent Neural Network)と呼ばれる手法を使います。
Recurrentとは「再帰的」という意味です。
今までは入力から出力へ一方向へ流れていたものを、ぐるぐると循環させるのです。
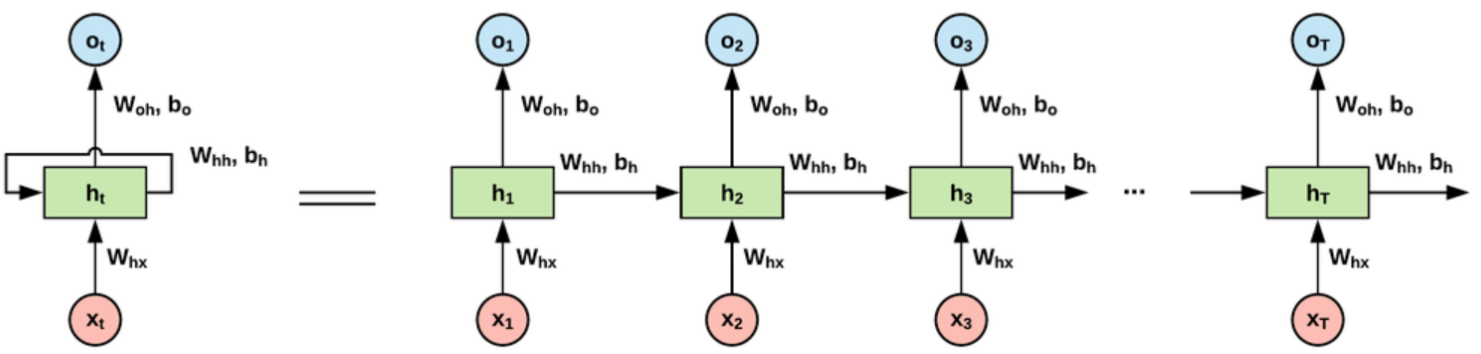
上の図のxは入力、hが中間層、oが出力です。
左側をみるとぐるぐると循環していますね。
これを展開すると図の右側のように書けます。
本当に いい加減 な こと を し て バカ な こと を し て しまっ た
の例だと、
x1="本当に"
x2="いい加減"
...
となります。
何が言いたいかと言うと、まずx1として"本当に"をinputとして入力します。
こうして得られた結果と、次の入力であるx2である"いい加減"を再度同じ層にinputとして入力するのです。
これは言語モデルと呼ばれる考え方で、非常に理にかなっています。
つまり、単純に前後の単語だけから学習するのではなく、
- "本当に"の後に"いい加減"がくる確率
- "本当にいい加減"の後に"な"がくる確率
- "本当にいい加減な"の後に"こと"がくる確率
と順番に伝搬させていくことで、文章の前後関係を考慮することができるのです。
実際にはこの一番単純なRNNは文章が長くなると伝搬が長くなりすぎて勾配爆発や勾配消失といった、
途中で情報が0になったり発散してしまったりといった問題を抱えています。
これにゲートと呼ばれる機能を持たせることでこれを改良したものがLSTMです。
ここでは単純なRNNだけでなくLSTMも含んで広義のRNNと呼びます。
他にも勾配爆発を避けるために勾配クリッピングと呼ばれる手法が行われていたり、モデルの複雑さを抑えるためにランダムにニューロンを無視するDropoutなど様々な工夫が行われています。
実装する
いよいよLSTMを使った実装を見ていきます。
ここでは「ゼロDeep2」のGitHub上で公開されているBetterRnnlmクラスを使います。
-
https://github.com/oreilly-japan/deep-learning-from-scratch-2/blob/master/ch06/better_rnnlm.py
これは単純なRNNにLSTMなどを用いて様々な改良を加えたものです。
(lm = Language Model = 言語モデル)
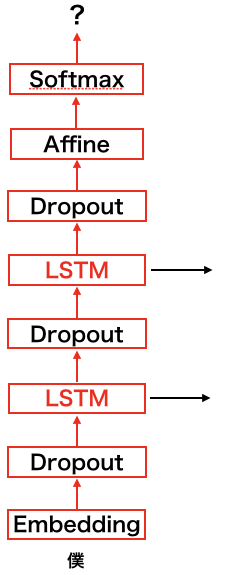
今回の実装は以下のような構造になっています。
コードはGitHubにあるものを使ってるのでここでは載せません。
より精度をあげるためにLSTMを2層に重ねており、Dropoutを間にそれぞれ3箇所挟むことで複雑さを軽減します

各層の説明は以下です。
-
Embedding
- 入力の単語を重み
Wと掛けて得られる単語の分散表現を計算する層
- 入力の単語を重み
-
Dropout
- ニューロンをランダムに切断することで複雑さを減らす
-
LSTM
-
RNNにゲートを加えて勾配消失を抑える工夫などをしたもの
-
-
Affine
- 中間層の出力結果と
Woutを掛けて出力する層 - WinとWoutに同一の行列を用いる「重み共有」を行う
- 中間層の出力結果と
-
Sofmax with Loss
-
Sofmax層とLoss層をくっつけたもの -
Sofmaxでは出力スコアを確率に変換する -
Lossでは正解ラベルと出力結果からLossを計算する
-
このような流れでLossを計算し、Lossが最小になるようにパラメータを更新していきます。
ここでいう正解は次にくる単語になります。
先ほどの例で言うと「本当に」の次は「いい加減」なので、最初の「本当に」がinputの時の正解は「いい加減」になります。
学習する
さて、説明が長くなってしまいましたが、準備したコーパスを用いて学習していきます。
まずはMeCabで形態素分析したdataset/watabe.train.txtを読み込む必要があります。
読み込むための関数は
dataset/watabe.pyで実装しています。
もともとのコードではtrainやvalid用のテキストも読み込んでますが、今回はコーパスが小さすぎるのでtrainだけを読み込みます。
# coding: utf-8
import sys
import os
sys.path.append('..')
try:
import urllib.request
except ImportError:
raise ImportError('Use Python3!')
import pickle
import numpy as np
url_base = 'https://raw.githubusercontent.com/tomsercu/lstm/master/data/'
key_file = {
'train':'watabe.train.txt'
}
save_file = {
'train':'watabe.train.npy'
}
vocab_file = 'watabe.vocab.pkl'
dataset_dir = os.path.dirname(os.path.abspath(__file__))
def load_vocab():
vocab_path = dataset_dir + '/' + vocab_file
if os.path.exists(vocab_path):
with open(vocab_path, 'rb') as f:
word_to_id, id_to_word = pickle.load(f)
return word_to_id, id_to_word
word_to_id = {}
id_to_word = {}
data_type = 'train'
file_name = key_file[data_type]
file_path = dataset_dir + '/' + file_name
words = open(file_path).read().replace('\n', '<eos>').strip().split()
for i, word in enumerate(words):
if word not in word_to_id:
tmp_id = len(word_to_id)
word_to_id[word] = tmp_id
id_to_word[tmp_id] = word
with open(vocab_path, 'wb') as f:
pickle.dump((word_to_id, id_to_word), f)
return word_to_id, id_to_word
def load_data(data_type='train'):
'''
:param data_type: データの種類:'train'
:return:
'''
save_path = dataset_dir + '/' + save_file[data_type]
word_to_id, id_to_word = load_vocab()
if os.path.exists(save_path):
corpus = np.load(save_path)
return corpus, word_to_id, id_to_word
file_name = key_file[data_type]
file_path = dataset_dir + '/' + file_name
words = open(file_path).read().replace('\n', '<eos>').strip().split()
corpus = np.array([word_to_id[w] for w in words])
np.save(save_path, corpus)
return corpus, word_to_id, id_to_word
if __name__ == '__main__':
for data_type in ('train', 'val', 'test'):
load_data(data_type)
次にパラメータを設定して学習用RNNのモデルを生成します。
学習データを読み込むクラスは
# coding: utf-8
import sys
sys.path.append('..')
from common import config
from common.optimizer import SGD
from common.trainer import RnnlmTrainer
from common.util import eval_perplexity, to_gpu
from dataset import watabe
from ch06.better_rnnlm import BetterRnnlm
# ハイパーパラメータの設定
batch_size = 10 # バッチサイズ(いくつ同時に学習するか)
wordvec_size = 100
hidden_size = 100 # 隠れ層の数
time_size = 5 # 時系列方向にいくつ考慮するか
lr = 10 # 学習率 = でかいほどパラメータが一気に更新される
max_epoch = 40 # 学習の繰り返し回数
max_grad = 0.25
dropout = 0.5 # dropoutの比率
# 学習データの読み込み
corpus, word_to_id, id_to_word = watabe.load_data('train')
vocab_size = len(word_to_id)
xs = corpus[:-1]
ts = corpus[1:]
model = BetterRnnlm(vocab_size, wordvec_size, hidden_size, dropout)
optimizer = SGD(lr) # SGDと呼ばれる最適化手法を使う
trainer = RnnlmTrainer(model, optimizer)
学習の過程で評価のために**パープレキシティ(Perplexity)**という値を計算しています。
これはイメージ的には「次にくる単語の候補をいくつに絞り込めたか?」という量です。
なので、学習を繰り返すたびにパラメータが更新されてパープレキシティが減っていけばいいわけです。
ただ注意しなければならない点が一点あります。
本当は学習用データで学習して評価用には別のデータを用意するのですが、今回はコーパスサイズが小さすぎるのでどちらも同じデータを使っています。(要は素材不足)
したがって過学習によりパープレキシティの値が本来より良く見えてしまっている可能性が高いです。
best_ppl = float('inf')
for epoch in range(max_epoch): # 学習の繰り返し回数
trainer.fit(xs, ts, max_epoch=1, batch_size=batch_size,
time_size=time_size, max_grad=max_grad)
model.reset_state()
ppl = eval_perplexity(model, corpus)
print('valid perplexity: ', ppl)
if best_ppl > ppl:
best_ppl = ppl
model.save_params("Watabe.pkl") # 学習結果のパラメータをオブジェクトとして保存
else: # パープレキシティが小さくならなかった場合学習率を小さくするテクニックだが、今回のコーパスサイズで意味があるのかは不明
lr /= 4.0
optimizer.lr = lr
model.reset_state()
print('-' * 50)
RNNを使った文章生成のやり方
すでに学習済みのパラメータがpklファイルとして保存されました。
なので、後は適当な単語を与えてあげて、次に来る確率が高そうな単語を確率分布で発生させてあげればいいですね。
これを繰り返すことで文章を自動生成することができます。
以下の図のようなイメージです。
↑Lossは学習時に必要だったが、予測するときはSofmaxまで
では、先ほどの学習で生成されたpklファイルを読み込んで、BetterRnnlmGen()からモデルを生成します。
BetterRnnlmGen()の中身はここでは載せませんが、github上にあるものと同じです。
中身はsotmaxの確率分布にしたがって次に来そうな単語を生成しているだけです。
# coding: utf-8
import sys
sys.path.append('..')
from common.np import *
from ch07.rnnlm_gen import BetterRnnlmGen
from dataset import watabe
# txtデータの読み込み
corpus, word_to_id, id_to_word = watabe.load_data('train')
# 語彙のサイズ
vocab_size = len(word_to_id)
# コーパスのサイズ
corpus_size = len(corpus)
# RNN(LSTM)のモデルを生成
model = BetterRnnlmGen()
# 学習したpklファイルを読み込む
model.load_params('../ch06/Watabe.pkl')
実際にやってみた
それでは、実際に渡部っぽい文章を生成させてみましょう。
まずは「僕」というワードを最初の言葉に設定し、自動生成してみます。
# start文字とskip文字の設定
start_word = '僕' # 文章の最初の文字
start_id = word_to_id[start_word] # 最初の文字のid
# 文章生成
word_ids = model.generate(start_id)
txt = ' '.join([id_to_word[i] for i in word_ids]) # idをwordに変換
txt = txt.replace(' ', '') # 読みづらいのでスペースを埋める
print(txt)
以下の文章が出力されました。
僕で言われても仕方ないかなと思います。
謹慎するということ以外。
こんなことを相談しなきゃおります。文春の報道でしかるべきだということもあったので、復帰に申し上げることはありました。
まずは誠心。
携帯ことは責任ですし、たいへん反省しております。僕が遅くいうかというよりも、まず改めてやる月の声を見てしまいました。
「月の声をみてしまいました」ってなんだろう?怖い。。
実行するたびに結果が変わるのでもう一回だけ回しててみました。
僕をしててというよりも、協力してですし、話し合いに謝罪をいただけていしたのではないかということを変わったので、もちろん謝罪先輩にこういうことなのではないかという思いもありますけれども、番組の番組判断も総合的にもオファーれてですねね。本当に大きなタイミングを謝って間違っているという、総合的にやりたいと思う。。
謝罪先輩って誰
とにかく、
それっぽい文章が出力されている!
なんとなく渡部の記者会見の雰囲気を匂わせつつも、よくよく読んでみると全然意味のわからない文章が生成されました。
渡部AI誕生の瞬間です。
回すたびに結果が異なるのは、文章を生成するときにある単語の次に来やすい単語を確率分布にしたがって決めてるからですね。
次に、100回以上発言したと話題の「本当に」から始まる文章を生成してみます。
本当に復帰のことは本当にこの人にやっぱり子供な考えだったので、そうですね。とにかく、僕場所があることかねると思っておりますが。本当に厳しく申し訳ない。
唯一、そのこと不貞僕ではなくて、謝罪を会見するかというのから、改めて検討しております。今後。
それがこれだけなって、申し訳ないというか、申し上げられないかもしれないですけれども、一連の報道をしました。
「本当に厳しく申し訳ない」という言葉から反省が伝わってきます。
妻をしました。文春がしたのどうしていたし、当然様の声を向いて行って、じゃあ放送月の勝手な行動をしたというよりも、申し訳ないです。
それに関してに改めてなので復帰を時間集まり聞いて馬鹿な行動を心かよくということに関しては仕事仕事しっかりなかったということを持って、媒体ことになるのではないけど、そう思われても仕方かねるというよりも
やはり出てくるのは謝罪の言葉。
次に、単語ではなく文章から始めてみましょう。
「本当に妻に申し訳」から始まる文章を生成します。
model.reset_state()
start_words = '本当に 妻 に 申し訳'
start_ids = [word_to_id[w] for w in start_words.split(' ')]
for x in start_ids[:-1]:
x = np.array(x).reshape(1, 1)
model.predict(x)
word_ids = model.generate(start_ids[-1])
word_ids = start_ids[:-1] + word_ids
txt = ' '.join([id_to_word[i] for i in word_ids]) # idをwordに変換
txt = txt.replace(' ', '') # 読みづらいのでスペースを埋める
print(txt)
本当に妻に申し訳ない復帰、至らないところで、復帰に関しての皆様に関しても上がって仕方ないかということで信頼を示してご混乱会見をしてしまったことなので、こういうこともいろいろはないということはあった通りだと思いますかわかてるいますことという思いで今日もあれなところをしたと思います。
とにかく申し訳ないという思いを向いていました。謝罪子供と騒動を回復して済むんだと思います
「申し訳」の後にはきちんと「ない」が来ているので、ちゃんと学習できてそうですね。
混乱会見をしてしまったそうです。
まとめと考察
- 渡部の記者会見の言葉をRNNで学習させた結果、それっぽいけど意味がわからない文章が生成させた
- いかんせん学習のベースとなったコーパスのサイズが小さすぎる
- あと10回くらい似たような謝罪会見をして学習データが溜まればもっと高性能な渡部AIができると思う
- 今回はあくまで勉強する目的で実装したので、精度の向上を目指せばもっといいモデルが作れるかも
-
Attentionを使うとか
-
おわりに
- めちゃくちゃどうでもいい話ですが、この記事をアドベントカレンダーに間にあわせるために僕は会社の半休をとりました。
- 会社を休んでまで僕は何をやっているんだと言う気持ちになりましたが、自然言語処理を勉強するきっかけを与えてくれたアンジャッシュ渡部に感謝(ちなみに僕は別に復帰していいんじゃないかとと思ってる派です)
以上です。みなさんも是非作ってみてください!