きっかけ(2023/4/1)
ツイッター社がTwitterのレコメンドの仕組みを公開して話題になっている。
以下が公式に公開された技術ブログとGiuHub上のソースコードである。
技術ブログ:https://blog.twitter.com/engineering/en_us/topics/open-source/2023/twitter-recommendation-algorithm
GitHub:https://github.com/twitter/the-algorithm
この記事ではGitHubのコードの解説は行わず、技術ブログの要約をメインとする。
なお、自分はTwitterの中の人ではないため100%正しく理解できている自信はない。
そのあたりはご容赦いただきたい。
TwitterのUIとレコメンド
TwitterのUIはたびたび変更されているが、2023/04/01 現在web/appに限らず以下の2つのタブで構成されている。
-
Following (フォロー中)
- 自分がフォローしているユーザーのツイートが時系列順に流れてくる
-
For you (あなたへのおすすめ)
- Twitterが独自のアルゴリズムで選定したおすすめツイートが流れてくる
「フォロー中」については昔ながらの機能なので説明不要だろう。
自分がフォローしているユーザーのツイートが新しい順に表示される。
いっぽうで「おすすめ」についてはどのような基準でツイートが選ばれているのか不透明な部分も多く、何かと議論の対象にもなっていた。
今回Twitterが公式に発表したアルゴリズムはこの「おすすめ」欄に関するものであり、非常に興味深い。
Twitterでは毎日5億ものツイートが投稿されており、その中から好みのツイートを選んで表示するのは大変骨の折れる作業である。
基本戦略
まず、「おすすめ」で表示するべきツイートとはどのようなツイートだろうか?
単純にユーザーが将来的に見たいと思っているユーザーおよびツイートを表示することができればよさそうである。
Twitterにおけるレコメンドは以下の手順で行われる。
- candidate(候補)の選択
- 抽出した候補のranking
- フィルタリングやビジネスロジック
1で候補となるレコメンド候補を大雑把に選び、2でそれらをrank付けして並び替える。
3はフィルタリングの処理であり、すでに見たツイートやさまざまな観点から表示するのに相応しくないツイートを除外する役割だ。
3は単なるフィルタリング処理であるため、大まかには1-> 2の二段階のレコメンドが行われていることになる。
なぜ二段階?
ツイッターはタイムライン上に上から順に表示される仕様であるため、「順番」という概念が存在し、おすすめのツイートほど上位に表示したいはずだ。
だが、毎日投稿される5億ツイートすべてにrankをつけて並び替えをするのはとても大変だ。
そこで、最初の段階で数十~数百の候補に絞り、その後にrankingの処理を行うことで効率的にレコメンドを行うことができるというわけだ。
このような二段階のレコメンドは他の多くのサービスで使われており、ECサイトなどでも一般的な手法だ。
1. Candidate(候補)の選定
レコメンドの候補となるツイートは複数のデータソースから抽出される。
あるユーザーにとって、他のユーザーは「フォローしているユーザー」or「していないユーザー」の二種類に分けられる。
フォローしているユーザーを"In-Network"と呼び、していないユーザーを"Out-of-Network"と呼ぶ。
このフェーズではIn-NetworkとOut-of-Networkから約50%ずつツイートを抽出し、最終的にユーザーごとに1500ツイートをレコメンド候補として次のフェーズに渡す。
1-1. In-Network
In-Networkのツイート選定は比較的イメージしやすい。
というのもあるユーザーが「フォローしているユーザー」に絞って考えれば良いからだ。
ユーザーごとに関連度が高そうなツイートをロジスティック回帰を使って抽出し、次のフェーズに回す。
ここでReal Graphというアルゴリズムを使ってユーザー間のエンゲージメントの確率を予測している。
Real Graphという手法は知らなかったのだが、以下に論文としてまとまっている。
https://www.ueo-workshop.com/wp-content/uploads/2014/04/sig-alternate.pdf
1-2. Out-of-Network
さて、フォローしていないユーザーの中から関連度の高いツイートを見つけるにはどうしたら良いだろうか?
ここでは2つの方法を取り上げる。
Social Graph
一つ目はsocial graphを使う方法だ。
ツイッターのようなSNSはフォローする/されるの関係によって成り立っているためグラフ構造を考えることができる。
そこで以下のような問いを考えることができる。
- フォローしているユーザーが、最近どんなツイートにエンゲージ(いいね、リプライなど)をしたか
- 同じようなツイートを「いいね!」しているユーザー最近どんなツイートにエンゲージ「いいね」しているか
いずれにせよフォロー外のユーザーにもリーチすることができる。
ブログ内では明言されていないが、このような手法は協調フィルタリングのアプローチとよく似ている。
協調フィルタリングは例えばAmazonとかによく出てくる「あなたと似たようなユーザーはこちらの商品もチェックしています」というアプローチである。
自分と属性の近いユーザーがどのような商品を好むかを調べることでレコメンド候補を絞り込むことができ、多くのサービスのcandidate phaseで用いられている。
昔からあるヒューリスティックな手法なのだが効果的であることが多く、Twitterにおいてもタイムラインの15%がこの手法によって得られたツイートらしい。
In-Networkと同じくロジスティック回帰を使ってスコアをつけて優先度の高いツイートを次のステップへ回す。
Embedding Spaces
もう一つはembeddingを使う方法だ。
上記の協調フィルタリングに近い方法は、直接類似度を計算するのではなくあくまで「おなじツイートをいいねした」などのエンゲージメントをベースに推定していた。
一方でembeddingの方法ではユーザーやツイートをそれぞれembedding (ベクトル化)することで直接類似度の計算が可能となる。
これもレコメンドではよく用いられる手法であり、Matrix Factorizationなどの時限削減の手法が有名だ。
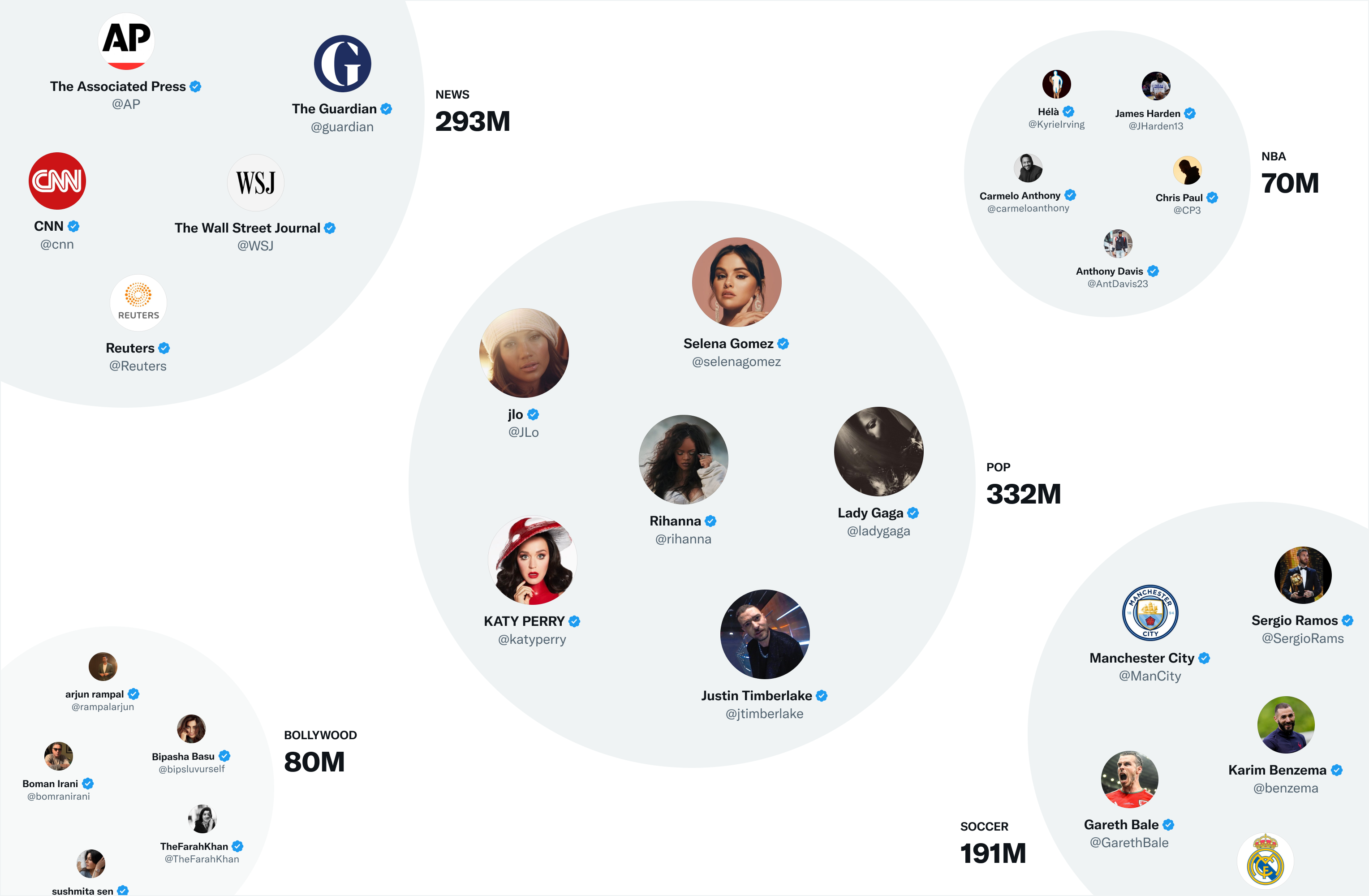
TwitterではSimCluster (https://dl.acm.org/doi/10.1145/3394486.3403370) という仕組みを使ってインフルエンサーを中心としたクラスターを生成し、その中でembeddingの計算を行っているようだった。
インフルエンサーを中心にクラスタリングを行っているというのはとても面白いアイディアだ。
なぜ最初にクラスタリングを行なう必要があるのだろうか?
最初からユーザーと全てのツイートとの類似度を計算すると膨大な時間がかかるから、まず最初にクラスターを生成し、その中で類似度計算することで計算工数を削減しているのかな?
ブログでは明言されていないのでこれは想像なのだけど。(有識者教えて!)
以下はブログから引っ張ってきたクラスタリングの例。
2. 抽出した候補のranking
さて、ここまででユーザーごとにレコメンド候補となる1500件のツイートを抽出できたことになる。
この後はこれらのツイートにスコアをつけて並び替えるrankingの工程に入る。
ここではどのデータソース出身のツイートかはいったん忘れ、全てのツイートを平等にスコアリングして並べ替える。
rankingにはニューラルネットワーク (以下NN)を用いる。
パラメータの数は48Mにものぼる。
featureの数は~1000個ほど。
正解ラベルとしては「いいね」「リツイート」「リプライ」などのエンゲージメントを用いる。
出力は10個のラベルとなっており、それがスコアに対応する。
出力が10個のラベル、というのが個人的にはちょっと意外だった。
1,0の分類問題にして、1の確率が高い順に並べるとかじゃだめなのかな?
3. フィルタリングやビジネスロジック
最後にフィルタリングやTwitter特有のビジネスロジックなどを考慮して手を加えて完成する。
例としては
- ブロック、ミュートしたユーザーのツイートの除外
- 同じユーザーのツイートばかり並ばないようにする(多様性の確保)
- ネガティブフィードバックを考慮
- 過去に「このユーザーのツイートに興味がない」とかの反応があった場合のことかな?
などなど、Twitterのサービス特有のロジックの反映がメインとなる。
また、単純にNNでスコア順に並べただけだと多様性が失われるという問題もレコメンドにおいては往々にしてあり、それらもルールベースで頑張って対応しているようだ。
まとめ
他のサービスのレコメンドによくある2段階の手法を用いている。
大まかな流れは以下。
- grapnを使った協調フィルタリングに近い手法やembeddingを使って1500個の候補を抽出
- ~1000個のfeatureを使ってNNで10個の出力、スコアリングを行う
- フィルタリング、ビジネスロジックの適用を行う
感想
細かい手法については知らないものあったが、大まかな流れは他のサービスと似ている点も多かった。
SNSということもありグラフのアルゴリズムを使っている点が面白かった。
ECサイトなどだとGBDTなどの決定木ベースの手法が強いのだけど、TwitterだとNNベースの手法が効果的なようだ。
機械学習のスコアリングまではあまり人間の意識が介入する意図はなさそうだが、最後のフィルタリングやビジネスロジックの設定次第でいろいろ印象変わりそうだなーと思った。