この記事について
本記事はHUIT Advent Calendar 2018における24日目の記事です。
製作した言語処理系の紹介と言語の作り方、拡張方法を簡単に説明します。初心者向けの記事なので界隈でよくある型推論がどうとか最適化がどうとかいう話は出てきません。専門的なことはともかく、これから言語を作ってみたい人の参考程度になればと思います。
Sheep言語について
Sheepは「2週間でできる!スクリプト言語の作り方」で紹介されているstone言語を元に拡張、修正した動的型付け言語です。stone言語では字句解析器、パーサ・コンビネータを用いた構文解析器と各構文の実装を行いました。stoneで実装した言語機能や構文は以下の通りです。
- 各種演算子(+, -, * , /, %, <, >, ==)
- if-else文
- while文
- 関数
- クロージャ
- クラスとオブジェクト
- 配列
- Javaのstatic関数呼び出し(System.out.println()など)
Sheepに追加した機能は以下の通りです。
- for文
- var文
- const文
- ブロックレベルスコープ
- return文
- if-elif-else文
- break, continue文
- 複合代入演算子(+=, -=, *=, /=)
- その他の演算子(<=, >=, &&, ||)
大抵の言語には備わっている機能を追加しました。
以下は簡単なデモになります。
class Sheep {
def sheep() {
return "sheep"
}
def hoge(n) {
var r = n
const closure = fun() {
r += 1
return r
}
return closure
}
}
class Lamb extends Sheep {
// Override
def sheep() {
return "lamb"
}
def foo() {
for(var i=0, var k=1; i<300; i += 1) {
k *= 2
if(i == 2) {
continue
} elif(i == 3) {
return k
}
}
}
def fibonacci(n) {
if n == 0 || n == 1 {
return n
} else {
return fibonacci(n-1) + fibonacci(n-2)
}
}
}
lamb = Lamb.new
print(lamb.sheep() + "\n")
const h = lamb.hoge(-3)
print(h())
print(h() + "\n")
print(lamb.foo() + "\n")
print(lamb.fibonacci(6))
h = 0 // cannot assign to a constant
lamb
-2
-1
16
8
Exception in thread "main" sheep.SheepException: cannot assign to a constant at line 53
at sheep.core.BasicEvaluator$NameEx.assign(BasicEvaluator.java:92)
at sheep.operator.AssignOperator.assignObject(AssignOperator.java:14)
...
var文はJavaScriptのletと同じで、var付きで定義した変数のスコープは現在のブロック内に限定されます。逆にvar無しだと定義場所に関わらずグローバル変数扱いになります。
GitHub
stone言語と同様Javaで実装しました。
https://github.com/teru01/Sheep
言語製作について
私が辿ってきたstone言語とその拡張であるSheep言語製作の流れと基礎について記述します。言語作りと聞くとハードルが高く、仕組みを想像するのが難しいかもしれませんが、Sheep言語ほどのものならそこまで難しくはありません。
プログラムが実行されるまで
言語製作のためには、プログラムがどのようにして実行されるのかを知る必要があります。下の図は、Sheepのようなインタプリタ型言語の実行フローを表しています。
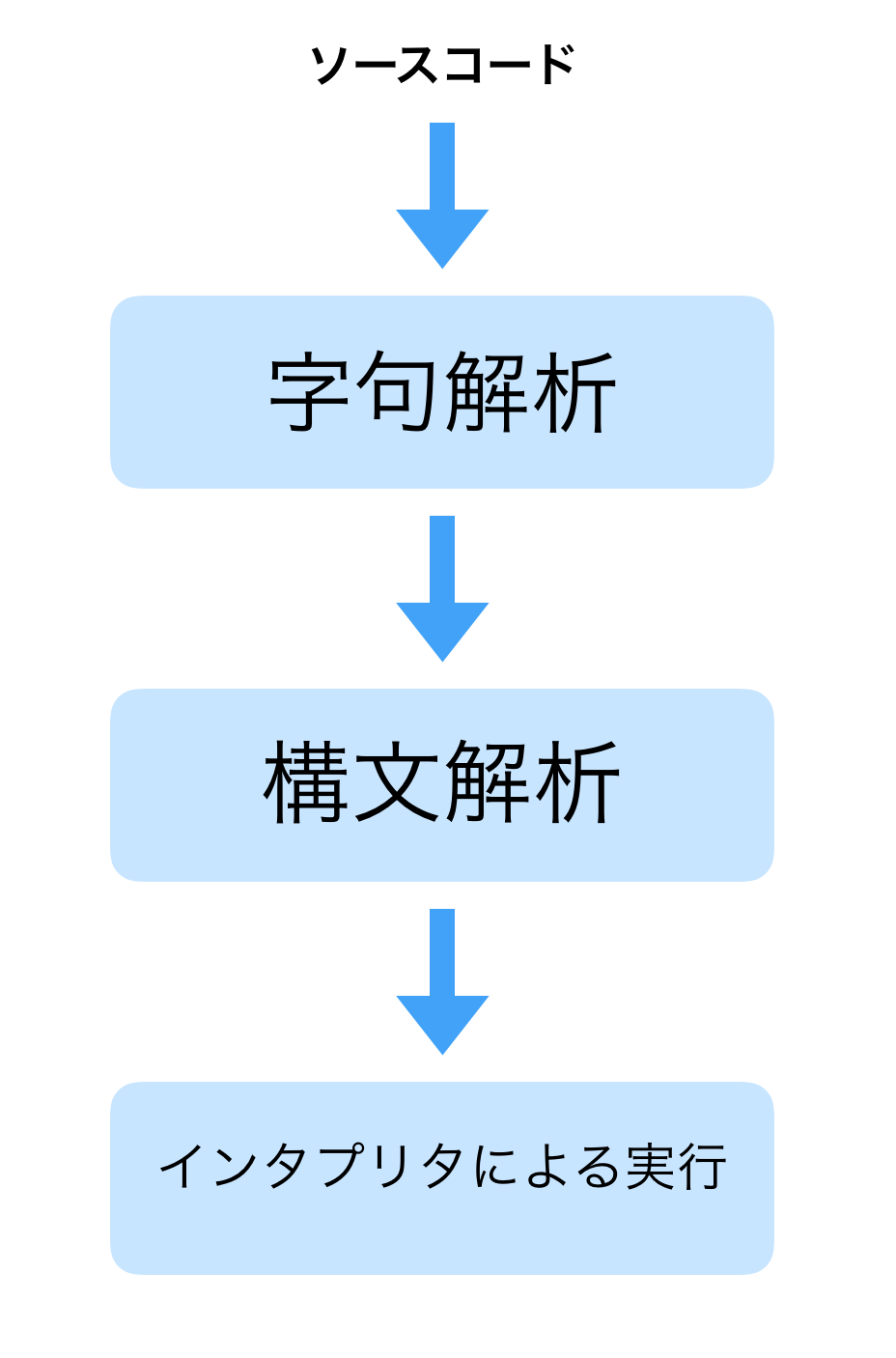
ざっくりと3段階に分かれます。
字句解析
概要
私たちにとってソースコードはスペースや改行で区切られているように見えますが、コンピュータにとってみればそれは1つの文字列に過ぎません。それを、1まとまりの文字列や記号ごとに区切る作業が字句解析です。区切られた1まとまりの文字列はトークンと呼ばれます。与えられたソースコードに関して字句解析を行い、意味のあるトークンを作成するプログラムが**字句解析器(Lexer)**です。
例えば、以下のようなプログラムがあるとします。
var sheep = "hitsuji"
// ⊂((・x・))⊃
sheep+="aaa"
これを字句解析器に渡すと、次のようにトークンに分割されます。
var , sheep , = , hitsuji , \n , \n , sheep , += , aaa , \n
表記上カンマ区切りで書いていますが、実際にはこれらトークンは字句解析器内のリストに格納されます。この時、stoneではTabやトークン間のスペース、コメント("//"以降の文字列)は重要な意味を持たないため字句解析の時点で除去されています。
トークンの種類
トークンに区切る際に区切るだけでなく分類も行います。そうしないと数値なのか文字列なのか分からなくなってしまうからです。stoneでは「整数リテラル」、「文字列リテラル」、「識別子」という3種類のトークンを定義しました。識別子は前者2つ以外の全てのトークンです。sample.sheepの例で言えば先頭からvar, sheep, =, sheep, +=が識別子となります。
Sheepでもそれをそのまま利用し、それぞれJavaのクラスとして表現しています。
トークンへ分割、分類
sample.sheepの3行目をみればわかる通り、プログラムをスペースで分割すれば良いという訳ではありません。そこで、トークンに分割しそれを分類するために正規表現を利用します。ソースコードの中から数値、文字列、識別子の正規表現にマッチする部分を抽出し、それぞれそのトークンのクラスとします。
Sheepに用いた正規表現は以下の通りです。
\s*((//.*)|([0-9]+)|("(\\"|\\\\|\\n|[^\"])*")|[A-Z_a-z][A-Z_a-z0-9]*|==|!=|\+=|-=|\*=|/=|<=|>=|&&|\|\||\p{Punct})?
ごつい感じですが、よく見ると
\s*((//.*)|整数リテラル|文字列リテラル|識別子)?
このようになっています。マッチした位置に応じてトークンオブジェクトを作成し、分類しています。
字句解析器の実装について
ここまででプログラムをトークンに分割、分類する方法は述べたので、stoneの字句解析器の実装について触れておきます。stoneの字句解析器の出力は基本的にはストリームです。つまりソースコード内を行ったり来たりするのではなく、先頭から順番に最後の方向へプログラムを読み込みトークンを出力します。なんだ当たり前じゃないのかと思うかもしれませんが、次節で述べる構文解析の際、「ある条件を満たした際にトークン列を巻き戻して先ほどと同じトークンを出力する」ということが必要になる場合があります。しかしそれをすると実装が煩雑になるため、字句解析器によるトークンの先読みを行います。つまり、先ほどの「ある条件」が満たされないように先読みを行う機能が必要になるのです。詳しくは構文解析の節で述べることにします。
構文解析
概要
字句解析によりトークン列が得られたので、抽象構文木を作成します。この作業を構文解析と言います。構文解析をすることによって、代入文の左辺と右辺は何かということや括弧の対応がどうなっているかなどが決定され、もしプログラムに文法エラーがあればここで判明します。構文解析を行うプログラムを、**構文解析器(Parser)**と言います
抽象構文木(Abstract Syntax Tree)
プログラムの構造を木構造で表したものです。例えば、
hoge = 2 + 4
このプログラムに対する字句解析の結果は以下のようになります。
hoge , = , 2 , + , 4
そしてプログラムに対応する抽象構文木は以下のようになります。
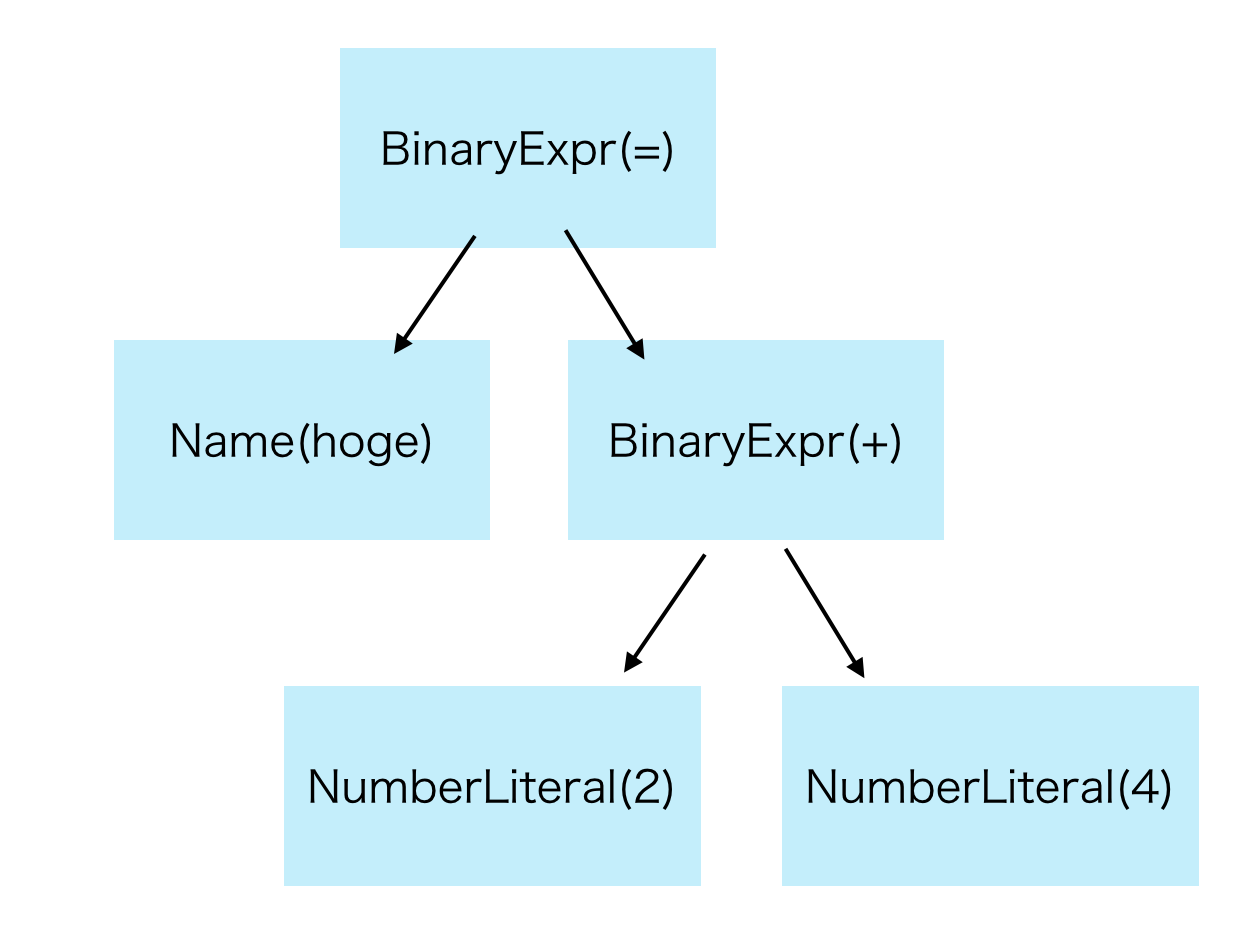
このような木構造にすることで、この代入文の左辺、右辺がはっきりします。すなわちこのプログラムは、「hogeに2を代入したものに4をたす」のでなく、「2 + 4したものをhogeに代入する」という構造を明確に表すことができます。
stone言語の実装において上図の抽象構文木(以下AST)の節に書かれているのは、節のオブジェクトを生成するクラス名です。具体的に言うと、BinaryExprは2項演算を表すクラスで、NumberLiteralは整数リテラルを表すクラスです。構文解析器が行う主な仕事は、このように字句解析結果のトークン列から適切なASTのクラスを選択し、そのオブジェクトを生成することにあります。
文法規則
トークン列からASTを構成するには、まず文法規則を定める必要があります。文法規則とはざっくり言うと「このオブジェクトの後にはこのオブジェクトが続く必要がある」のようにオブジェクトの並びを定める規則のことです。stone言語の文法規則で少しだけ例を出すと、primaryの定義はこのようになっています。
primary: "(" expression ")" | NUMBER | IDENTIFIER | STRING
|はorを表していて、expressionは別の定義です。primaryはexpressionを含むことができると言えます。expressionは「式」のことで、簡単にいうと「代入文の右辺になれるもの」のことです。従ってprimaryには、「(2*3)」や「(myObj.getNumber(2))」や「"SHEEP"」や「hoge」(変数名)などがマッチすることになります。
primaryの文法規則を図で表すと下のようになり、矢印が分岐しているところがorを表しています。このような文法規則を表す図のことをレールロード・ダイアグラムと言います。
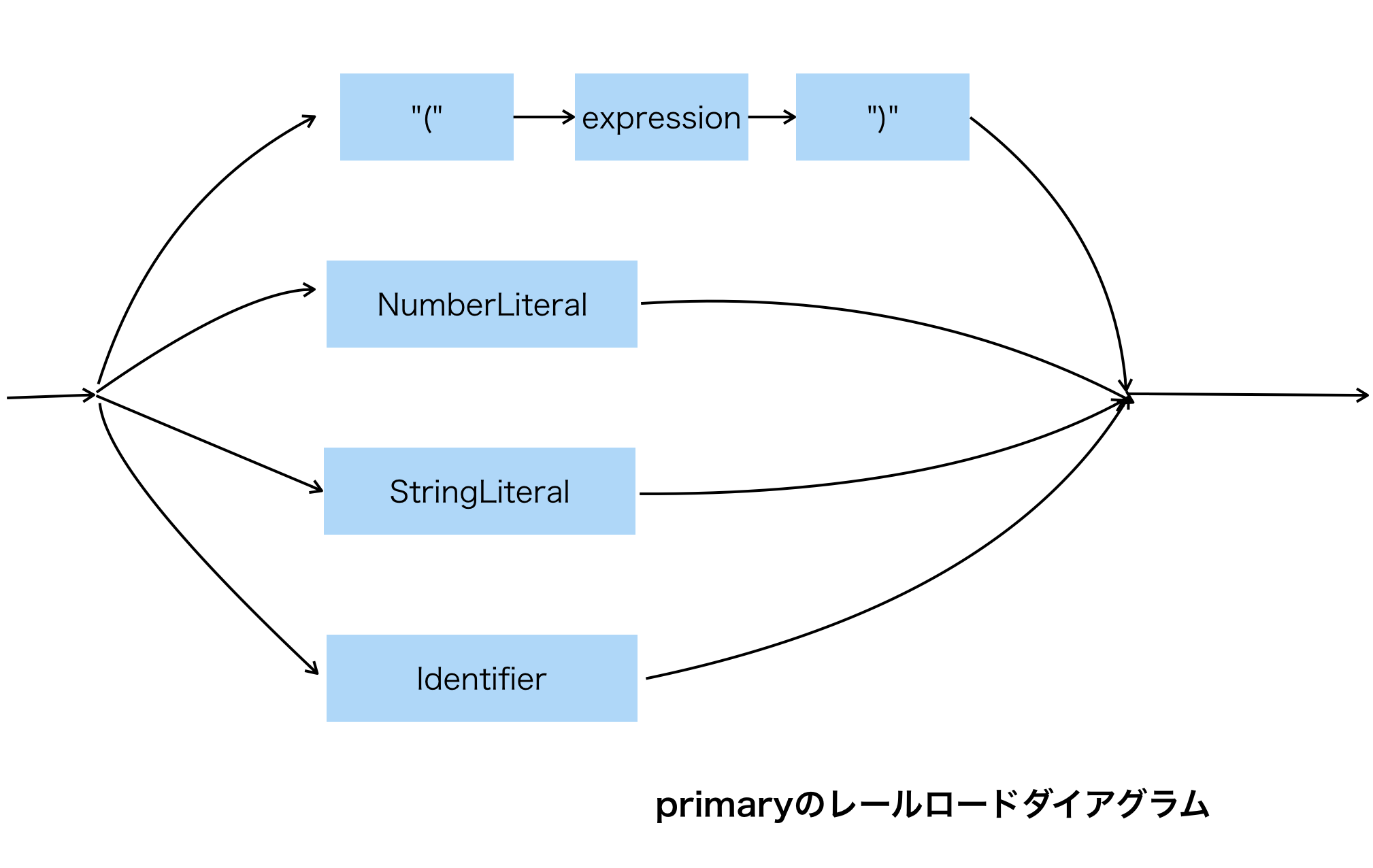
構文解析は、字句解析器から1つづつトークンを取り出してはレールロードダイアグラムを矢印に沿って辿り、文法規則にマッチするか調べる作業であるとも言えます。最後まで辿りつけたら解析成功で、途中移動先がなくなると文法エラーとなります。
トークン先読みについてもう一度
ここで、前節の「字句解析器の実装について」で述べた字句解析器の先読み機能についてもう一度触れておきましょう。先読み機能はprimaryのように分岐が存在する時に必要になります。トークンを読み出しながらレールロードダイアグラムを進む際、分岐のどの方向に進めば構文解析が成功するかは読み込んで見なければわかりません。しかしそれでは失敗するたびにトークン列を巻き戻して分岐の手前に戻り、以前とは違う分岐を試す必要があります。(これをバックトラックという)バックトラックは解析速度や実装しやすさの点でやや劣ってしまうため、stoneの構文解析ライブラリではトークンを先読みしてレールロードダイアグラムの進むべき道を決めてから解析を行っています。
Sheep言語の構文解析器について
著者様がパーサーを組み合わせたパーサー・コンビネータという形で、トークンを読み出しASTを作成する機能をライブラリとして提供してくださっているので、Sheepでもそれをお借りしました。そのため私がやることは文法を定義することだけです。例えば、Sheepで新たに追加したfor文は次のようにして定義することができます。
Parser iterControl = rule(ForIterExpr.class)
.sep("(")
.maybe(rule().ast(this.simple.repeat(rule().sep(",").option(this.simple)))).sep(";")
.maybe(rule().ast(this.simple)).sep(";")
.maybe(rule().ast(this.simple))
.sep(")");
Parser forBody = rule(BlockStmnt.class)
.sep("{")
.option(this.statement0)
.repeat(rule().sep(";", Token.EOL).option(this.statement0))
.sep("}");
Parser sheepfor = rule(ForStmnt.class)
.sep("for")
.ast(iterControl)
.ast(forBody);
this.statement.insertChoice(sheepfor);
このように記述するとざっくりとこんなASTを作成してくれます。(ところどころ端折ってますが)
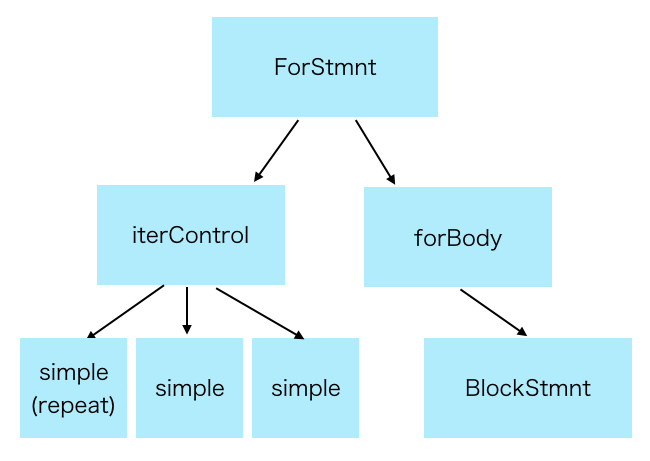
for文の文法規則であるsheepforは、下位のより細かな構造としてiterControlとforBodyを持ちます。またそれらもそれぞれsimpleやBlockStmntといった下位の構造を持っています。そのことをふまえて、stoneの構文解析では、上位にある大きな構造から、下位にある小さな構造の方向へ向かって構文解析が行われます。レールロードダイアグラムの例で言うと、初めの方に行う構文解析は次に現れる文がif文なのかfor文なのかはたまた別の文なのかという分岐の進路決定を行い、進路がfor文であると決定した後にさらに次に現れるのがiterControlになりうるか?といったより細かくて下位にある構造に対して構文解析を順次行なっていきます。このような構文解析アルゴリズムを、トップダウン構文解析と言います。stoneではトップダウン構文解析の1つであるLL構文解析を主に利用しています。
インタプリタによる実行
概要
構文解析でASTが得られたので、次はASTの根から葉の方向に向かって評価、実行していきます。ASTの節を評価するとは、その節を根とする小さな木(部分木)がどのような値を返すのかを計算することです。ASTの根となっているクラスに定義されている評価メソッドの処理中に、根の子を再帰的に評価することでプログラムを実行することができます。このようなインタプリタの実現方法をtree-walk型のインタプリタと言います。
具体例
前節で挙げたhoge=2+4の例であれば、ASTの根である=を表す2項演算子の評価処理の中で子の両辺を評価します。右辺は+を根とする部分木と解釈することができるため、まずこの部分木に対して評価を行います。整数リテラルのようなASTの葉は自身がもつ値をそのまま評価値として返却するので、+を根とする部分木は評価されて6となります。このようにインタプリタはASTを巡回しながら左辺と右辺それぞれを評価し、最終的に代入の処理が行われます。このようなある節の評価処理の中で子の評価処理を呼び出す木の巡回方法は深さ優先探索に似ています。
環境(Environment)
2+4のような整数リテラルだけの式であれば計算結果を求めるだけで良いので楽なのですが、これでは電卓とできることは変わりません。せっかくなので変数(や定数)を利用したいところです。それらを利用するためには、変数と代入されているオブジェクトを対応づける必要があり、それらのスコープ(可視範囲)やエクステント(生存期間)も管理する必要があります。そこで、変数に対する読み書きは環境と呼ばれるオブジェクトに対して行います。環境の内部構造をハッシュテーブルとすることで、変数名でその変数に代入されているオブジェクトを容易に操作することができます。
変数のスコープ
変数の管理はスコープごとに行うため、環境はスコープに入るたびにインスタンス化されます。そして環境をネストさせ、外側スコープが持つ環境に対する参照を持つことで変数のスコープを実現します。例えば下記の図では、myFunc(10)のように呼び出すと4, 2, 10のように出力されます。これは、変数が参照される際に最も内側の環境から最も外側の(グローバルの)環境へ向かって環境内の変数名を検索しているからです。Sheepではif文がブロックスコープをもつため、if文内のprint(b)ではif文の外で定義されているbが参照され、最後のprint(a)ではif文内のaではなく、引数として渡されたaを参照することができます。
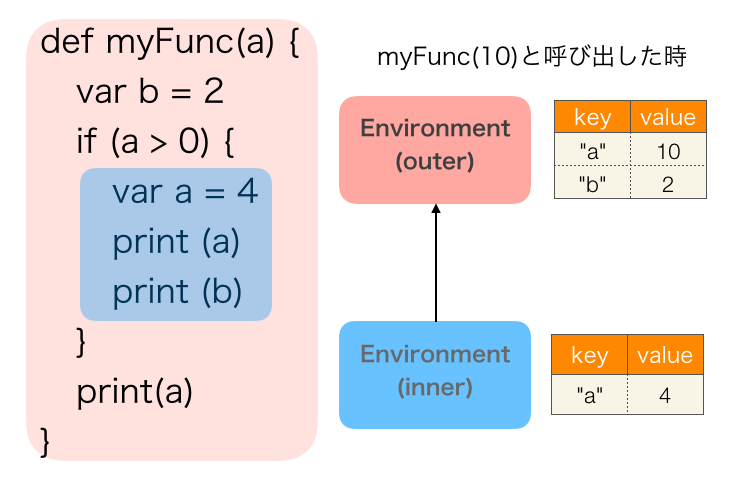
Sheepのインタプリタ
Sheepインタプリタの主な処理は以下のようになっています。
Lexer lexer = new Lexer(reader);
while(lexer.peek(0) != Token.EOF) {
ASTree t = bp.parse(lexer);
if(t instanceof NullStmnt) {
continue;
}
Object r = ((BasicEvaluator.ASTreeEx)t).eval(env);
if(r instanceof ReturnObject) {
return;
} else if(r == Statements.CONTINUE || r == Statements.BREAK) {
throw new SheepException("This statement is not permitted: " + ((Statements)r).getValue());
}
}
この部分に今まで解説してきた部分が凝縮されています。字句解析(1行目)、構文解析(3行目)を経てASTの根に対して評価メソッドを呼び出しています(7行目)。構文解析と実行はprogramという関数定義やif文、for文がマッチする文法規則ごとに行われ、sheepソースファイルの終端まで実行を繰り返します。以上のようにして、stoneやSheepが実行されています。
Sheep開発あれこれ
Sheep開発におけるツールや実装面の話と所感、与太話を色々書いて行きます。
ビルドツール
stone製作の途中ぐらいまではjavacコマンドの実行スクリプトでしたが、パッケージが増えるに従っていちいちコマンドを変更するのが面倒になってきたのでGradleを選択しました。初めての利用でしたが公式のドキュメントが見やすくて充実しているので良い選択だったと思います。
テストとCIについて
Pythonでテスト
言語処理系はそれなりに規模が大きくなってしまうので、テストコードは必要不可欠と言えます。ただ、stone言語の段階では動くとわかっているものを作っていたのでテストは書いておらず、Sheepの独自実装を実装する際に書き始めました。そのためメソッドごとにテストを書くわけにもいかず、.sheepのソースコード(Javaのソースではなく、Sheep言語処理系上で動作するコード)を読みこんで、最終的な出力だけをテストすることにしました。
JUnitもよく分からんので最初はBashで書こうとしたのですが、Bashもよく分からんのでPythonでこんなテストを書いていました。
import subprocess
import sys
class Color:
RED = '\033[31m'
GREEN = '\033[32m'
YELLOW = '\033[33m'
cmd = ["java", "-cp", "./bin/build:./lib/gluonj.jar", "sheep.array.ArrayRunner"]
testfiles = [
"tests/assign.sheep",
"tests/class_test.sheep",
"tests/if_test.sheep",
"tests/while_test.sheep",
"tests/closure_test.sheep",
"tests/for_test.sheep",
"tests/const_test.sheep",
"tests/ary_test.sheep",
]
answer = [
"21\n2\n9\n32\n",
"21\n18\n-7\n",
"5\n",
"1\n2\n3\n",
"5\n3\n8\n",
"0\n1\n2\n0\n1\n1\n1\n10\n",
"20\n2\n11\n",
"2\nhoge\nbar\nfoo\n"
]
if not subprocess.run(["gradle", "compileJava"]):
print("compile error")
exit()
for f, ans in zip(testfiles, answer):
try:
result = subprocess.run(cmd + ["run", f], stdout=subprocess.PIPE, check=True, text=True, encoding='utf-8')
if result.stdout == ans:
print(f"{f} : " + Color.GREEN + "OK" + Color.END)
else:
print(f"{f} : " + Color.RED + "TEST FAILED!!" + Color.END)
except:
print(f"{f} : " + Color.YELLOW + "EXCEPTION" + Color.END)
PythonからテストケースごとにJavaのプロセスを起動しているため、パフォーマンス的には最悪ですがテストケースもそんなに多くないので初期はこれで十分でした。
そしてJUnitへ
しかしこれでは困ることがあるのです。例外のテストです。constを実装している時に、constで定義された変数は再代入された際にそれを示す例外を送出する必要があることに気付きました。PythonでJavaのプロセスを立ち上げてテストする以上はJavaの例外を捕捉することはできないので(インタプリタ内部で捕捉すればできないこともないですが)ちょうど良い機会だと思いJUnitを用いたテストを導入しました。
CircleCI
せっかくなので何かCIサービスにも触れて見たいと思い導入しました。そんな軽い気持ちで導入したのですが、ローカルではテストまで通るのにCircleCIではビルドすら成功しないという自体が生じて驚いたことがあり、その原因は後に述べるGuonjの使い方とGradleのキャッシュシステムの相性の問題でした。キャッシュを削除(rm -rf .gradle)することでローカルでもコンパイルエラーを吐いたので、このようなローカルでは発現しにくい問題を検出するために、個人開発であってもCIサービスを導入する意義はあると思います。
GitHubにCircleCIのバッチがつくとそれだけでテンションが上がるのでそれ目当てにテストを書くのも良いでしょう
Gluonjについて
Javaでアスペクト指向プログラミングを可能にするシステムであり、書籍中でも一部の機能を開発に用います。言語の機能に関連したものではなく、rubyでいうopen classを実現するために利用しています。
なぜ使うのか
ASTの節を巡回して評価するメソッドは全ての節クラスに実装する必要がありますが、その際直接節クラスに対して評価メソッドを書くと一覧性がやや劣ってしまいます。
そこで、それぞれの評価メソッドを切り出して1つのクラスにまとめてしまおうというのが書籍中で紹介されているアイディアです。このような場合はVisitorパターンを使うと解決できるのですが、Visitorパターンはデザインパターンの中でも難解な部類に入るため、より簡単に実現する方法としてGluonjを利用しました。例えば整数リテラルクラスの拡張であればこのようになります。
@Reviser
public static class NumberEx extends NumberLiteral {
public NumberEx(Token t) {
super(t);
}
public Object eval(Environment e) {
return value();
}
}
evalというのが評価メソッドであり、オブジェクトが保持する値をそのまま返しています。@ReviserというアノテーションによりNumberExはNumberLiteralを直接改訂するので、evalメソッドはNumberLiteralクラスに直接書いても同じ挙動になります。
実際使ってみたところ
Visitorパターンの恩恵を特に複雑な実装をすることなく受けられるためSheep開発でも便利に利用しています。ただ、利用者数の関係で公式チュートリアル以外の情報がネットに落ちていないため、glounjのお作法を意図せず破ってしまいバグが出た際にかなり困ります・・・Gluonjの内部で捕捉された例外はエラーメッセージを読めばわかるのですが、場合によってはよく分からない場所でInstantiationExceptionが出たり、リバイザのアノテーションが見つからないと怒られたりしました。
演算子の実装とオブジェクト指向
もともとstoneでは演算子の評価は以下のように行われていました。
@Reviser
public static class BinaryEx extends BinaryExpr {
/* omitted */
public Object eval(Environment env) {
String op = operator();
if("=".equals(op)) {
/* omitted */
} else {
Object left = ((ASTreeEx)left()).eval(env);
Object right = ((ASTreeEx)right()).eval(env);
return computeOp(left, op, right);
}
}
protected Object computeOp(Object left, String op, Object right) {
if(left instanceof Integer && right instanceof Integer) {
return computeNumber((Integer)left, op, (Integer)right);
} else {
if(op.equals("+")) {
return String.valueOf(left) + String.valueOf(right);
} else if(op.equals("==")) {
if(left == null) {
return right == null ? TRUE : FALSE;
} else {
return left.equals(right) ? TRUE : FALSE;
}
} else {
throw new SheepException("bad type", this);
}
}
}
protected Object computeNumber(Integer left, String op, Integer right) {
int a = left.intValue();
int b = right.intValue();
if (op.equals("+"))
return a + b;
else if (op.equals("-"))
return a - b;
else if (op.equals("*"))
return a * b;
else if (op.equals("/"))
return a / b;
else if (op.equals("%"))
return a % b;
else if (op.equals("=="))
return a == b ? TRUE : FALSE;
else if (op.equals(">"))
return a > b ? TRUE : FALSE;
else if (op.equals("<"))
return a < b ? TRUE : FALSE;
else throw new SheepException("bad operator", this);
}
}
演算子をStringで判定して処理をしていますが、これだと演算子を新しく追加したり、演算前に特殊な処理をごちゃごちゃ書かなくてはいけなくなるので見通しがあまり良くありません。そこで各演算子をクラスに切り出してポリモーフィズムを使うことにより処理を分けました。
以下は改良した2項演算子の評価処理です。
public static class BinaryEx extends BinaryExpr {
/* omitted */
public Object eval(Environment env) {
ASTLeaf op = operator();
if(op instanceof BinaryOperator) {
return ((BinaryOperator)op).calc(left(), right(), env);
} else if(op instanceof AssignOperator) {
return ((AssignOperator)op).assignTree(left(), right(), env);
}
throw new SheepException("bad operator", this);
}
}
例えばAnd演算子(&&)のクラスであれば以下のようになります。左辺がfalseなら即returnという短絡評価を行なっていますが、これは改良前のメソッドにelse if (op.equals("&&"))...のような形で書いていればプログラムが見辛くなっていたはずです。
package sheep.operator;
import sheep.Token;
import sheep.ast.ASTree;
import sheep.core.BasicEvaluator.ASTreeEx;
import sheep.core.Environment;
import sheep.util.SheepUtil;
public class AndOperator extends BinaryOperator {
public AndOperator(Token t) {
super(t);
}
@Override
public Object calc(ASTree left, ASTree right, Environment env) {
Object leftObj = ((ASTreeEx)left).eval(env);
if(!SheepUtil.isTrue(leftObj)) {
return false;
}
Object rightObj = ((ASTreeEx)right).eval(env);
if(SheepUtil.isTrue(rightObj)) {
return true;
} else {
return false;
}
}
}
普段オブジェクト思考を意識してコードを書くことはほとんどないのですが、Sheepは自分が今まで作ってきたプログラムの中では一番規模の大きい作品であるため、再利用性や拡張性をある程度考える必要がありました。このようなところで活用できたのは良かったのですが、オブジェクト指向周りはアンチパターンも多いようなので、もし「これアンチパターン踏んでる」というのがあればコメントやtwitterでこっそり教えてください・・。
開発期間について
参考にした本のタイトルは、「2週間でできる!スクリプト言語の作り方」です。そう、これらのことは言語について全く知らなくても2週間でできるのです。ここで私のGitHubをご覧ください
本を買ったのは割と前なのですが、まともに読み始めたのが10月の終わりくらい、実装を本格的に始めたのが11月中頃なので大体2ヶ月丸々かかっています。 自分以外の全てを光速の97%で移動させれば特殊相対性理論により自分にとっての2ヶ月は自分以外にとっての2週間くらいになるので、おそらくそういう開発手法を利用するのでしょうね。
2週間で終わる人いるのかこれ・・・。
終わりに
言語製作はいいぞ。
言語作りはマニアックすぎるのか友人に勧めても全力で拒絶されます。しかし、見かけはマニアックであっても、データ構造やアルゴリズム、再利用可能な設計を考えると言った基本的な姿勢が身につくのでSheep言語くらいの規模であれば割と色々な方にお勧めです。そして、言語作りすると決めたらスクリプト言語の作り方本はとてもいい本なので全力でお勧めします。
参考文献/webサイト
千葉 滋 (2012)「2週間でできる! スクリプト言語の作り方」技術評論社
中田 育男 (2017)「コンパイラ 作りながら学ぶ」オーム社
http://d.hatena.ne.jp/hyuki/20060818/junit