はじめに
この記事は、NTTテクノクロス Advent Calendar 2024 シリーズ1の19日目の記事になります。
こんにちは、NTTテクノクロスの照喜名です。社内では、Amazon EMRを利用した分析アプリケーションの開発を担当しています。
今回は、業務で使用しているAmazon EMRに関して、EMRを定期実行する際の選択肢の一つであるStep FunctionsとEMRを組み合わせた構成のメリットと構築方法を紹介したいと思います。
前提条件
今回のワークロードの前提条件として、中規模以上のワークロード(実行時間が1日4hくらい~、読み込みがGB~数TB)を想定します。このくらいの規模になるとGlueやEMR Serverlessを使用するよりもEMR on EC2を使用した方がコスト削減につながります。
EMR ServerlessやGlueでStep Functionsを使用するのが有効かどうかはまた詳細な条件によりますので、今回はEMR on EC2に限った話をさせていただければと思います。
※ちなみに業務ではなるべく処理時間を少なくしてコスト削減するために並列処理を入れたり、エラー時にすぐ終了するようにエラー処理を入れたりしているこんな感じのステートマシンを作成しています(機密情報のため実際のものではありません)。

Amazon EMRとは
- Apache HadoopやApache SparkなどのビッグデータフレームワークをAWS上で実行する分散アプリケーションプラットフォーム
- 分散ファイルシステム(HDFS)を使用し、大規模なデータを処理するのに向いている
- コンピューティングリソースとしてEC2を使用
- リザーブドインスタンスやスポットインスタンスを使用可能
- オートスケーリングも可能
- ストレージとしてS3が使用可能(EMRFS)
- 3つのノードタイプが存在
- プライマリノード
- EMRクラスター全体を管理するノード
- コアノード
- HDFSにデータを保存するソフトウェアを持つノード
- 少なくとも一つ必要
- タスクノード
- タスクを実行するのみに利用されるノード
- HDFSにデータを保存しない
- 0個でもよい
- プライマリノード

AWS Step Functionsとは
- 220以上のAWSサービスについてワークロードを自動化することが可能
- 2通りの作成方法
- Workflow studioで視覚的にワークフローを作成する
- JSONベースの構造化言語Amazonステートメント言語で記述する
- 状態遷移ごとに課金
- 1000回で0.025USD(東京リージョン)

Step Functions+EMR構成のメリット
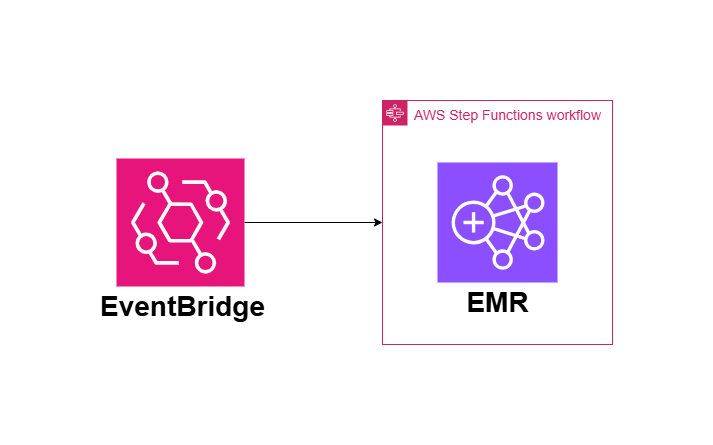
メリット① 定期実行が可能となる
EventBridgeのスケジュール実行と組み合わせることにより、ワークフローを自動的に定期実行させることができる。EMR単体だと自動実行することはできないので、EMRクラスターを定期実行する方法の一つの選択肢となる。
メリット② 試験や実行が行いやすい
構成をStep Functionsで作成しておくことにより、特定の構成の試験や実行、検証作業を行うことが容易になる。
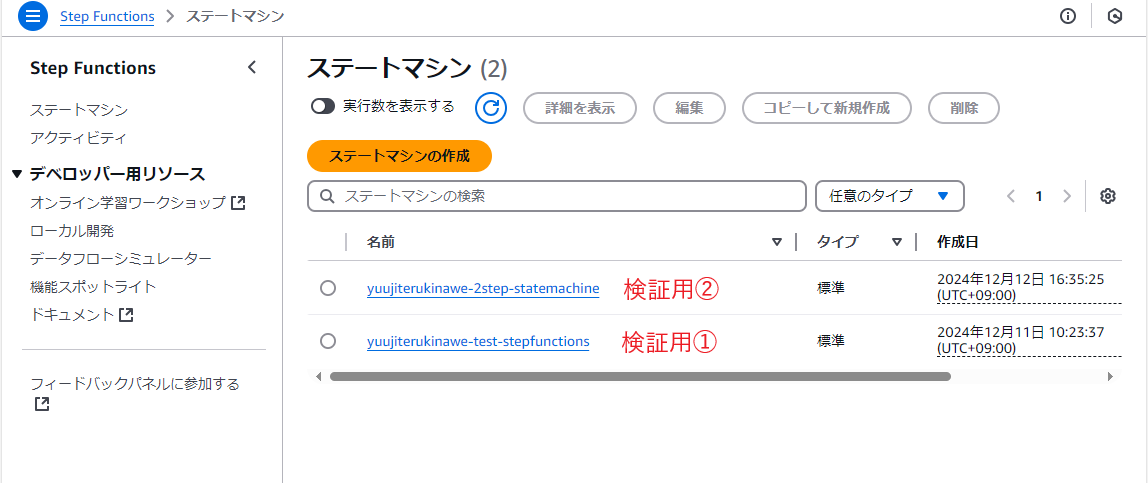
EMR単体でもクローンにより実行することは可能だが、以前のクラスター設定を探す際に他のクラスター実行により埋もれてしまったり、実行から2か月経っていて参照できなかったりすることがある。
そこで、Step Functionsにより構成をステートマシンとして保存しておけば、いつでも編集、実行が可能になるため設定を探す手間を省くことができる(名前は構成がわかりやすいものを)。
メリット③ 別のリソースをステートマシンに組み込むことができる
EMRだけでなく、GlueやLambda、SNSをステートマシンに組み込むことが可能となる。EventBridgeのトリガーを使わないと自動実行できないような箇所もワークフローとして実行することが可能となる(トリガーを使うのが良いのか、ワークフロー内で実行するのが良いかは要件に合わせて)。

Step Functions+EMR構成の構築方法
※先にEMRでの実行方法が確立されており、ロールやVPC等の環境が整っていることを前提とする。
-
Step Functionsのコンソールからステートマシンを作成する。テンプレートは目的に合ったものがなければ選択せずに開始で良い。

-
設定タブでステートマシン名を変更し、ロールを割り当てる(作成後に名前を変えることはできない)。

-
デザインタブでCreate Cluster、AddStep、Terminate Clusterを追加する(慣れていたらJSONで直接書いても良い)。

-
コードタブでJSONを編集し、参照するファイルや起動するインスタンス等の細かい設定を施す。
- 設定がわからなくなった際はAmazon Qに聞くか、EMRの公式ドキュメントのRunJobFlowを参照すると大体わかる
- それでもわからない場合はサポートへ

-
細かい部分が設定できたら作成。右上の実行から実行可能。

役に立った設定
案件中で役に立った設定をいくつかピックアップして紹介しておきます。
1. Auto Termination Policyを記載
"AutoTerminationPolicy": {
"IdleTimeout": 60
}
- 何も設定しないと、エラーが発生した際にクラスターが動き続けてしまう
- EMRはインスタンスによっては放置しておくと料金がとんでもないことになるので設定を強く推奨
2. ErrorをCatchした際にTerminate Clusterが起動するように設定

- Auto Termination Policyを設定していればやらなくてもよいがエラー時即終了でコスト削減になるため推奨
- エラーの原因特定はEMRコンソールからログを見て行うことが可能(終了したEMRクラスターであってもログからエラー解析可能)
3. CloudWatchエージェントのインストール
"Applications": [
{
"Name": "AmazonCloudWatchAgent"
}
],
- EMR7.0.0以降であれば下記の設定を入れるだけでクラスターで使用されるEC2のメトリクス(CPU使用率、ディスク使用率、メモリ使用率等)を取ることが可能
- 失敗した時の分析に使用可能
- ブートストラップアクションを使用すると名前空間を指定可能(詳細は別の記事で…)
4. 割り当て戦略の設定
- スポットインスタンスの使用時に
- 設定しても取れないときは取れないが、念のため設定しておくのがよい
- 設定値は4種類
- price-capacity-optimized(推奨)
- 価格とキャパシティの最適化。中断される可能性が最も低く、価格ができるだけ低いスポットインスタンスのプールを選択する。
- capacity-optimized
- 可用性の最も高いプールを予測し、スポットインスタンスをリクエストする。
- capacity-optimized-prioritized
- 設定しているインスタンスの優先順位の高いものからキャパシティに合わせて最適化する。
- lowest-price
- インスタンスの価格のみが考慮される
- 中断の可能性が高い
- price-capacity-optimized(推奨)
おわりに
最後まで読んでいただきありがとうございます。EMRを使用する際には、ぜひStep Functionsとの併用を試していただければと思います。慣れたらEMRコンソールよりもわかりやすいです(たぶん)。
明日は、NTTテクノクロスアドベントカレンダー20日目の記事となります。明日の記事もお楽しみに。