Motivation
・word2vecは大量のテキストを与えるだけで、単語の意味をイイ感じに表現できるベクトルが得られる
・そのイイ感じのベクトルを特徴量に使えば、様々なタスクにおいて精度向上が期待できる
・・情報推薦の精度を上げたい
・・FXの予測タスクに特徴量として使って精度上げるなど
・・可視化
・(deep learningの一端に触れる)
スタンス
・word2vecの理解はともかく、それを使って面白いことをやったり、タスクの精度を上げたりしたい
Agenda | Plan
・word2vecによって得られるベクトルがどのくらいイイかを体感する (今日はこれ)
・word2vecによって得られるベクトルを情報推薦タスクに応用して、普通のベクトルの結果と比較する
・word2vecによって得られるベクトルを為替予測タスクに応用して、普通のベクトルの結果と比較する
・word2vecによって得られるベクトルをキャラクター分析等の可視化に応用して、人の主観を借りずにテイストを可視化する
・・擬態語の可視化の例

http://techlife.cookpad.com/entry/2015/02/27/093000
word2vecとは
・入力として大量のテキストを与えると、各単語についての意味をイイ感じに表現できるベクトルを作ってくれるブラックボックスな何か
いろいろ試す
まずはword2vecでベクトルを作ってみる
入力:100MB分の英文
↓
word2vec
↓
出力:あらゆる単語についてベクトル表現(200次元)
ソースコードはとてもシンプルに書ける
import gensim
sentences = gensim.models.word2vec.Text8Corpus("/tmp/text8")
model = gensim.models.word2vec.Word2Vec(sentences, size=200, window=5, workers=4, min_count=5)
model.save("/tmp/text8.model")
print model["japan"]
(例)“japan”という単語のベクトル
[-0.17399372 0.138354 0.18780831 -0.09954771 -0.05048304 0.140431
-0.08839419 0.0392667 0.267914 -0.05268065 -0.04712765 0.09693304
-0.03826345 -0.11237499 -0.12375604 0.15184014 0.09791548 -0.0411933
-0.26620147 -0.14839527 -0.07404629 0.14330374 -0.15179957 0.00764518
0.01670248 0.15400286 0.03410995 -0.32461527 0.50180262 0.29173616
0.17549005 -0.13509558 -0.20063001 0.50294453 0.11713456 -0.1423867
-0.17336504 0.09798998 -0.22718145 -0.18548743 -0.08841871 -0.10192692
0.15840843 -0.12143259 0.14727007 0.2040498 0.30346033 -0.05397578
0.17116804 0.09481478 -0.19946894 -0.10160322 0.0196885 0.11808696
-0.04913231 0.17468756 -0.14707023 0.02459025 0.11828485 -0.01075778
-0.13718656 0.05486668 0.25277957 -0.16104579 0.0396373 0.14481564
0.22176275 -0.17076172 -0.038408 0.29362577 -0.13069664 0.04339954
0.00451817 0.16272108 0.02541053 -0.14659256 0.16529948 0.13884881
-0.1113431 -0.09699004 0.07190027 -0.04339439 0.17680296 -0.21379708
0.1572576 0.03031984 -0.21495718 0.03347488 0.22941446 -0.13862187
0.21907888 -0.13375367 -0.13810037 0.09477621 0.13297808 0.25428322
-0.03635533 -0.1352797 -0.13009973 -0.01995344 0.05807789 0.34588996
0.10643663 -0.02748342 0.00877294 0.10331466 -0.02298069 0.26759195
-0.24946833 0.0619933 0.06216418 -0.20149906 0.0586744 0.16416067
0.34322274 0.25680053 -0.03443218 -0.07131385 -0.08819276 -0.02436011
0.01131095 -0.11262415 0.08383768 -0.17228018 -0.04570909 0.00717434
-0.04942331 0.01721579 0.19824736 -0.14876001 0.10319072 0.10815206
-0.24551305 0.02878521 0.17684355 0.13430905 0.03504089 0.14440946
-0.12238772 -0.09751064 0.22464643 -0.00364726 0.30931923 0.04332043
-0.00956943 0.40026045 -0.11306871 0.07663886 -0.21093726 -0.24558903
-0.11918587 -0.11373471 -0.04725014 0.16204022 0.06828773 -0.09220605
-0.04137927 0.06957231 0.29234451 -0.20949519 0.24574679 -0.14875519
0.24135616 0.13015954 0.03091074 -0.45729914 0.14642039 0.1330456
0.09597694 0.19738108 -0.08785061 0.15975344 0.11823107 0.10955801
0.43996817 0.22706555 -0.01743319 0.06030531 -0.08983251 0.43928599
0.07300217 -0.31112081 0.25329435 -0.02628026 -0.0781511 -0.03673798
0.01265055 -0.08048201 -0.0556048 0.25650752 0.02342006 -0.17268351
0.06641581 -0.04409864 0.02202901 -0.12416532 0.08068784 0.12611917
0.00144407 -0.24265616]
このベクトルだけ見ても良いのか悪いのかよくわからないので、このベクトルを何かに応用してみる
応用を試す1:類似する単語の検索
“japan"に類似する単語上位5単語を表示してみる。
(word2vecのベクトルとcos類似度を使って得る)
china 0.657877087593
india 0.605986833572
korea 0.598236978054
thailand 0.584705531597
singapore 0.552470624447
関係の近い国が上位にきている。
比較として、word2vecを用いずに普通のベクトル(着目する単語に共起する単語の出現頻度が成すベクトル)で同様に上位5単語を求めると、
in 0.617413123609
pensinula 0.604392809245
electification 0.602260135469
kii 0.5864838915
betrayers 0.575804870177
となり、微妙な結果。
tf-idfなどかませればマシにはなると思う。
応用を試す2:意味の可視化
word2vecから得られたベクトルを可視化して、その位置関係に意味が表現されていることが確かめられる
例えば下の例では、いくつかの国と首都のペアの2単語をプロットしている。
国と首都の位置関係がすべての例で成立している → 国と首都という関係の概念を捉えることができている
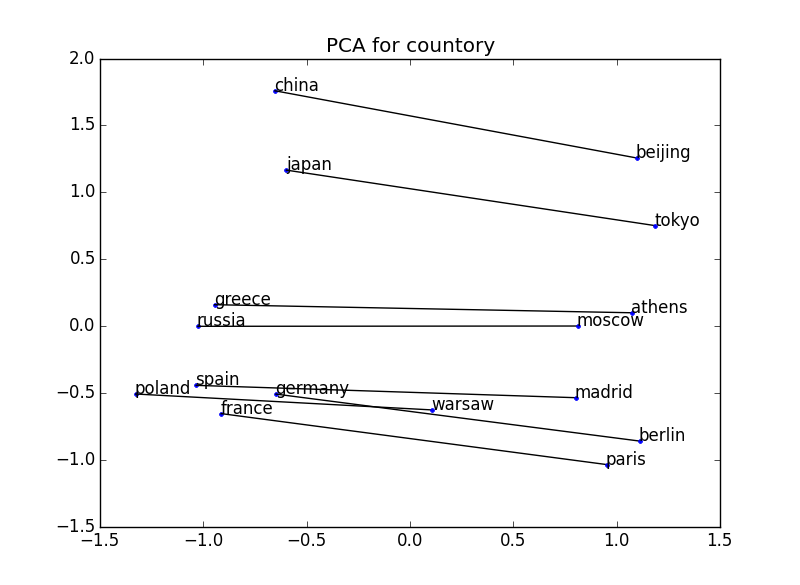
200次元 → 2次元
比較のために、word2vecを用いずに普通のベクトル(着目する単語に共起する単語の出現頻度が成すベクトル)で同様にプロットした。これも正規化すればもう少しマシになるとは思う。
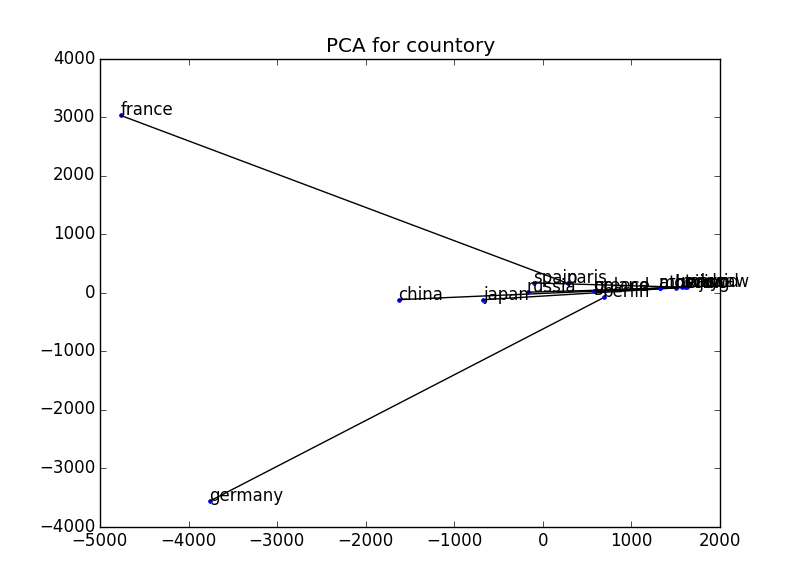
22973次元 → 2次元
※可視化の際には、主成分分析を用いてベクトルの次元を2次元に削減している。参考:http://breakbee.hatenablog.jp/entry/2014/07/13/191803
本にのってた例:
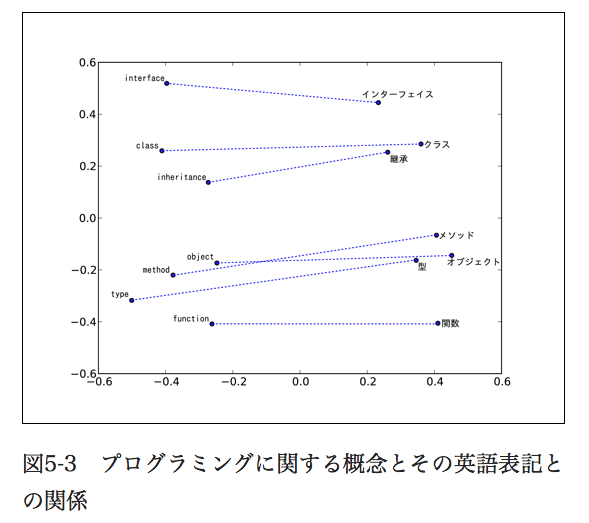
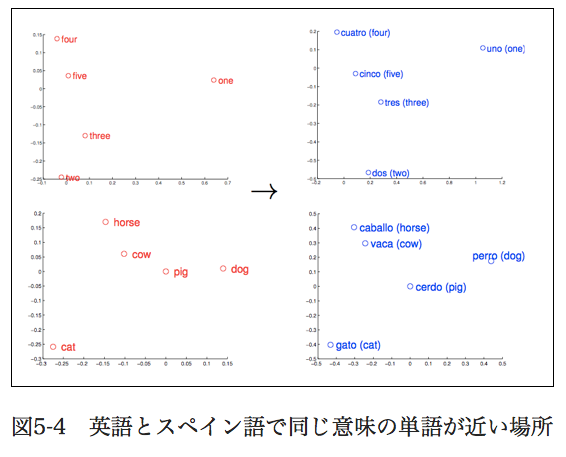
応用を試す3:意味の演算
意味がベクトルとしてちゃんと表現されているなら、意味の演算も行えるはず。
・king - man + woman = queen(Q: 男性にとっての王は女性にとって何? A:女王)
・Paris - France + Italy = Roma (Q:フランスにとってのパリは イタリアにとっては何? A: ローマ)
ベクトルを上のように足したり引いたりすると、実際にこういう演算結果が得られる
その他従来手法 vs word2vec のちゃんとした情報
“Mikolovらの研究によれば、この足し引きの能力を測るために「Athene - Greece + Oslo が Norway になれば正解」などのテストを行った結果、従来手法では正解率が 9% や 23% だったのに、word2vecで実装されているSkip-gramモデルでは 55% と正解率が大きく向上したそうです。”
抜粋:: 西尾泰和. “word2vecによる自然言語処理”
word2vecの仕組み
略
word2vecの仕組みのイメージ
この画像と説明がすごくイメージの手助けになった。
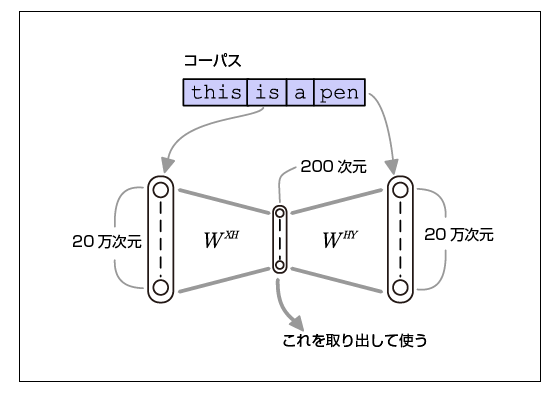
"特徴は入力にも出力にも同じデータを入れることです。そんな学習をさせたら入力と同じものを出力するだけのつまらないニューラルネットワーク(恒等写像)が育つのではないかと思うかもしれません。
この方法のキモは「隠れ層のサイズが恒等写像を学習することができないくらい小さく設定されている」という点にあります。そのためAutoencoderは限られた隠れ層になるべくたくさんの情報を詰め込もうと学習し、結果として入力層→隠れ層の重みは入力データの特徴を低次元のベクトルで表現したものになります。ニューラルネットワークに学習させている問題が解きたい問題なのではなく、無理難題をニューラルネットワークに解かせることでニューラルネットワークが作り出す分散表現に価値があるのです。
中略
語彙数が20万次元だとすれば、200次元の中間層では1000分の1の次元しかないわけです。この厳しい状況の下で「周囲の単語を当てろ」という予測問題の正解率を上げるように学習が行われます。こうやって「周辺の単語の出現頻度が似ている度合い」が近い単語が距離の近いベクトルになるような変換が行われるわけです。”
抜粋:: 西尾泰和. “word2vecによる自然言語処理”
実装
・word2vecまわり:gensim
・可視化の際には、主成分分析を用いてベクトルの次元を2次元に削減している。参考:http://breakbee.hatenablog.jp/entry/2014/07/13/191803