Peter Anderson,Xiaodong He,Chris Buehler,Damien Teney,Mark Johnson,Stephen Gould,Lei Zhang
CVPR2018
pdf , arXiv , git
どんなもの?
ボトムアップとトップダウンを組み合わせたアテンションメカニズムを提案.
MSCOCOテストサーバーでCIDEr / SPICE / BLEU-4スコアはそれぞれ117.9,21.5,36.9を獲得.
2017年のVQAチャレンジで第1位を獲得.
先行研究との差分
典型的なアテンションモデルでは,等サイズの画像領域の均一グリッド(下図左)に対応する CNN 特徴上で動作するのに対して,提案手法ではオブジェクトおよび他の顕著な画像領域(下図右)のレベルでアテンションを計算することができる.

モデルの説明
$k$個の画像特徴を $V =\{v_1,...,v_k\}, v_i \in \mathbb{R}^D$とする.
bottom-up attention model
Faster R-CNNを使用.プリトレインするために,ImageNetで学習済みのResNet-101を用いてFaster R-CNNを初期化する.その後,Visual Genome データセットで訓練する.トレーニングに98K,validationとテストにそれぞれ5Kの画像を使う.
下図は Faster R-CNN ボトムアップアテンションモデルの出力例.

caption model
2層の LSTM を用いる.1層でトップダウンアテンションを学習(attention LSTM),2層で言語モデルを学習(language LSTM).
モデルの図
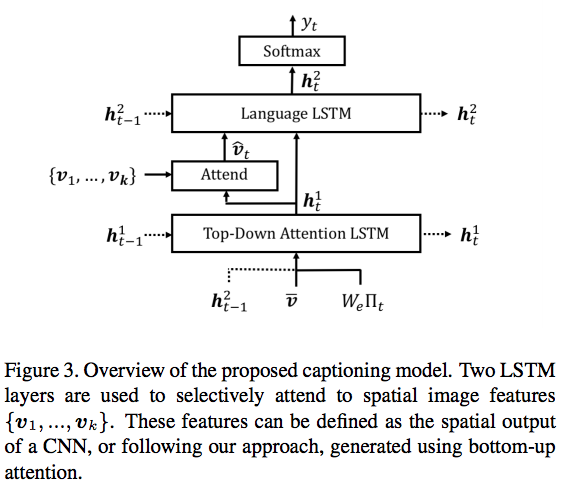
attention LSTM
各時間ステップでの attention LSTM の入力ベクトルは,平均プール画像特徴 $\bar{v}=\frac{1}{k}\sum_iv_i$,前の時間ステップの language LSTM の出力$h_{t-1}^2$,前の時間ステップで生成された単語からなる.
x_t^1 = [h_{t-1}^2 , \overline{v} , W_e\Pi_t]
$W_e \in \mathbb{R}^{E \times | \Sigma |}$ は語彙集合$\Sigma$の word embedding matrix
$\Pi_t$ は時間ステップ$t$の入力単語の one-hot ベクトル
attention LSTMの出力$h_t^1$が得られると,各時間ステップ$t$において,$k$個の画像特徴$v_i$の各々に対して正規化された attention 重み$\alpha _{i,t}$を生成する.
a_{i,t} = \omega_a^T \tanh(W_{va}v_i+W_{ha}h_t^1)
\alpha_t = softmax(a_t) \tag{1}
$W_{va} \in \mathbb{R}^{H \times V} , W_{ha} \in \mathbb{R}^{H \times M} , \omega_a \in \mathbb{R}^H$は学習したパラメータ
言語LSTMの入力に使う attention 重み付き画像特徴は次のように計算される.
\widehat{v}_t = \sum_{i=1}^K \alpha_{i,t}v_i \tag{2}
language LSTM
language LSTM への入力は,attention LSTM の出力と attention 重み付き画像特徴からなる.
x_t^2 = [\widehat{v}_t , h_t^1]
文の単語($y_1,...,y_t$)を参照する表記を$y_{1:T}$をすると,各時間ステップ$t$において,可能な出力単語に対する条件付き分布は次のように計算される.
p(y_t|y_{1:t-1}) = softmax(W_p h_t^2 + b_p)
$W_p \in \mathbb{R}^{|\Sigma|\times M} , b_p \in \mathbb{R}^{|\Sigma|}$は学習した重みとバイアス
最終的な出力文に対する分布は条件付き分布の積として計算される.
p(y_{1:T}) = \prod_{t=1}^T p(y_t|y_{1:t-1})
真の文$y_{1:T}^\ast$とキャプションモデルのパラメータ$\theta$を用いて交差エントロピーロスを計算.
L_{XE}(\theta) = - \sum_{t=1}^T \log(p_\theta ( y_t^\ast | y_{1:t-1}^\ast))
最近の研究との比較のために,CIDErに最適化された結果も提示する.クロスエントロピーで訓練されたモデルから初期化することで,次のスコアを最小限に抑える.
L_R(\theta) = - E_{y_{1:T}~p_\theta}[r(y_{1:T})]
\nabla_\theta L_R(\theta) \approx -(r(y_{1:T}^s) - r(\widehat {y}_{1*T})) \nabla_\theta \log p_\theta (y_{1:T}^s)
$r$はCIDErのスコア関数.
vqa model
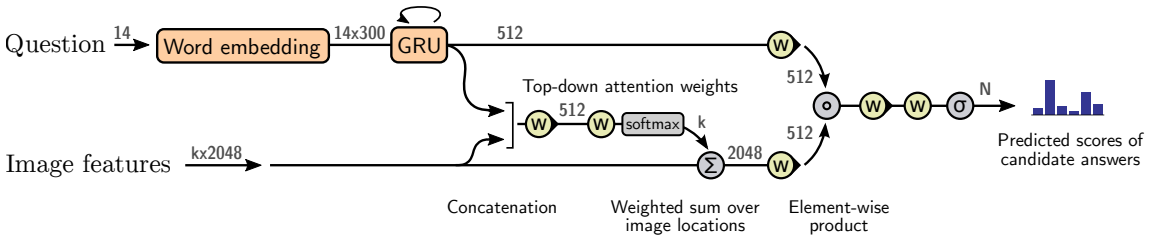
キャプションモデルと同様にソフトトップダウンアテンションメカニズムを使用する.
提案手法では,各質問は学習された単語埋め込みを用いて表現されたGRUの隠れ状態$q$として最初に符号化される。 方程式3と同様に、GRUの出力$q$が与えられると、以下のように、$k$個の画像特徴$v_i$のそれぞれについて非標準化されたアテンション重み$a_i$を生成する。
a_i = \omega_a^Tf_a([v_i,q])
キャプションモデルと同様に式(1),(2)を用いて画像特徴$\widehat{v}$を計算する.
可能な出力応答$y$に対する分布は次のように計算される.
h=f_q(q) \circ f_v(\widehat{v})
p(y) = \sigma(W_of_o(h))
VQAモデルの詳細については Tips and Tricks for Visual Question Answering を参照
評価実験
ボトムアップのアテンションの影響を評価するために,キャプショニングとVQAの両方の実験で,ベースライン(ResNet)と完全モデル(Up-Down)を評価する.ベースラインは、ボトムアップアテンションメカニズムの代わりに ImageNet で学習済みのResNet CNNを使用.
画像キャプショニング実験では,Resnet-101の出力をバイリニア補間を使用して10×10の固定サイズにリサイズする.VQA実験では,サイズを変更した入力画像をResNet-200でエンコードする.別の実験では,元のサイズ14×14から7×7,1×1の空間出力のサイズを変化させる効果を評価する.
キャプションの実験結果
MSCOCO 2014キャプションデータセットを使用.
キャプションの品質をSPICE,CIDEr,METEOR,ROUGE-L,BLEUで評価.
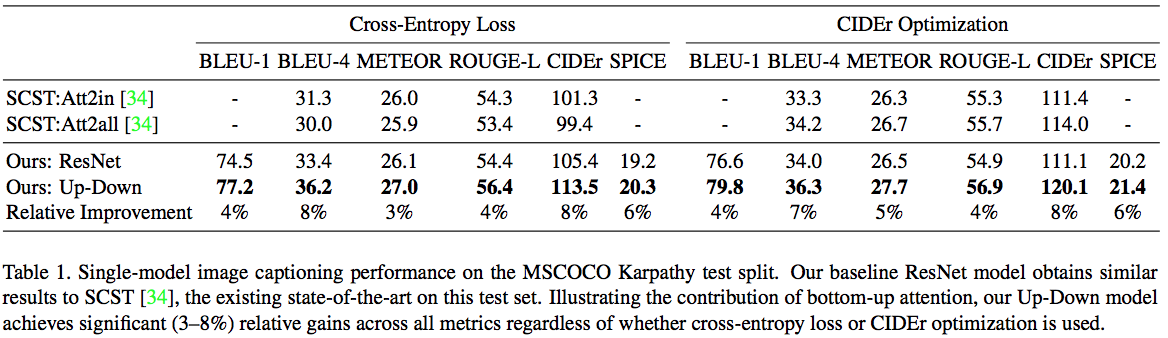
MSCOCO Karpathy split テスト結果.
MSCOCO Karpathy split テストに関する SPICE Fスコアの内訳.

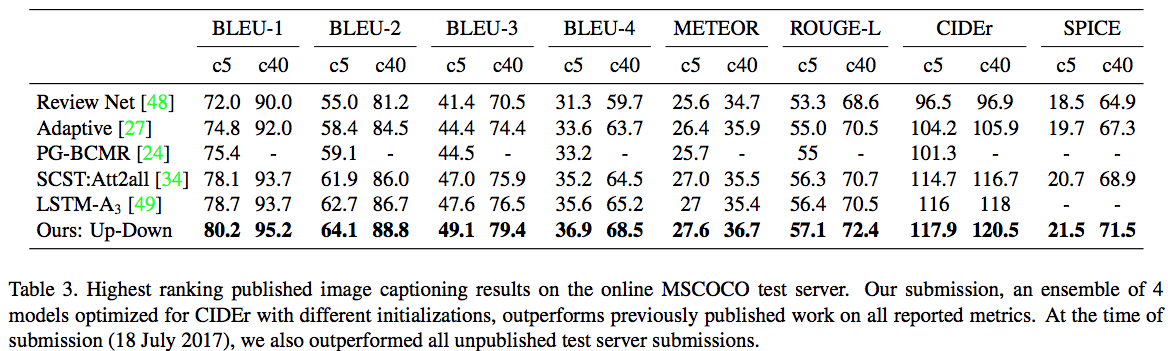
オンライン MSCOC テストサーバでのキャプション結果.提出時(2017年7月18日)にはテストサーバーに提出されていた他の手法よりも優れていた.
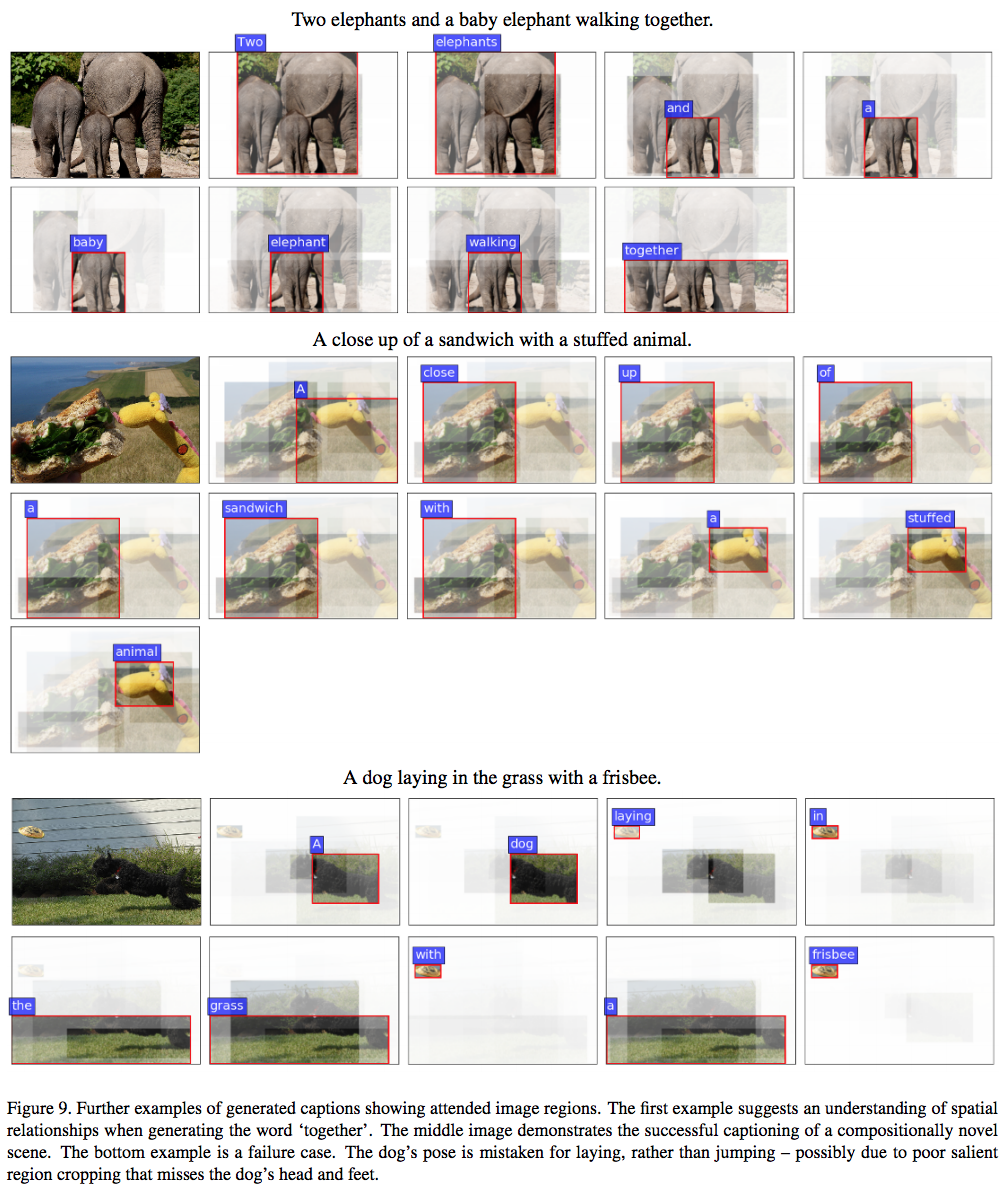
キャプション例

VQAの実験結果
VQA v2.0データセットを使用.質問は最大14語に制限.回答候補の集合は訓練集合において8回以上出現する正解に限定し,その結果出力語彙サイズは3,129だった.
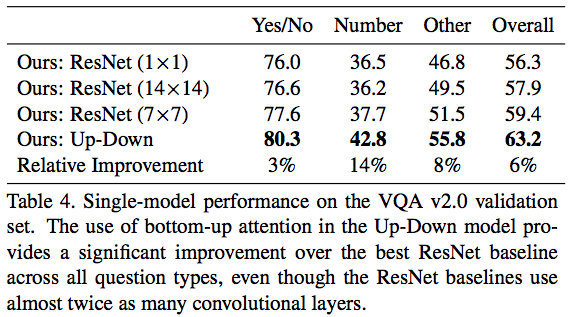
VQA v2.0の validation セットでの結果.
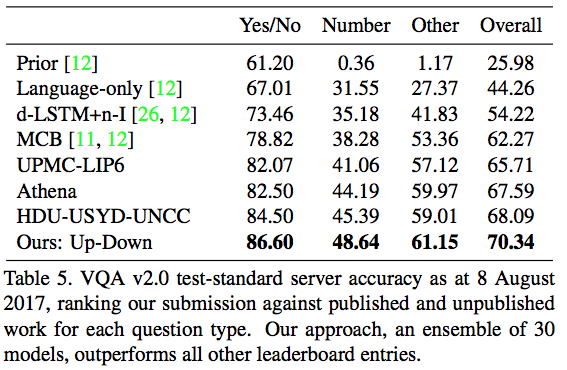
VQA 2.0テストサーバでの結果.2017年のVQAチャレンジにおいて第1位を達成.
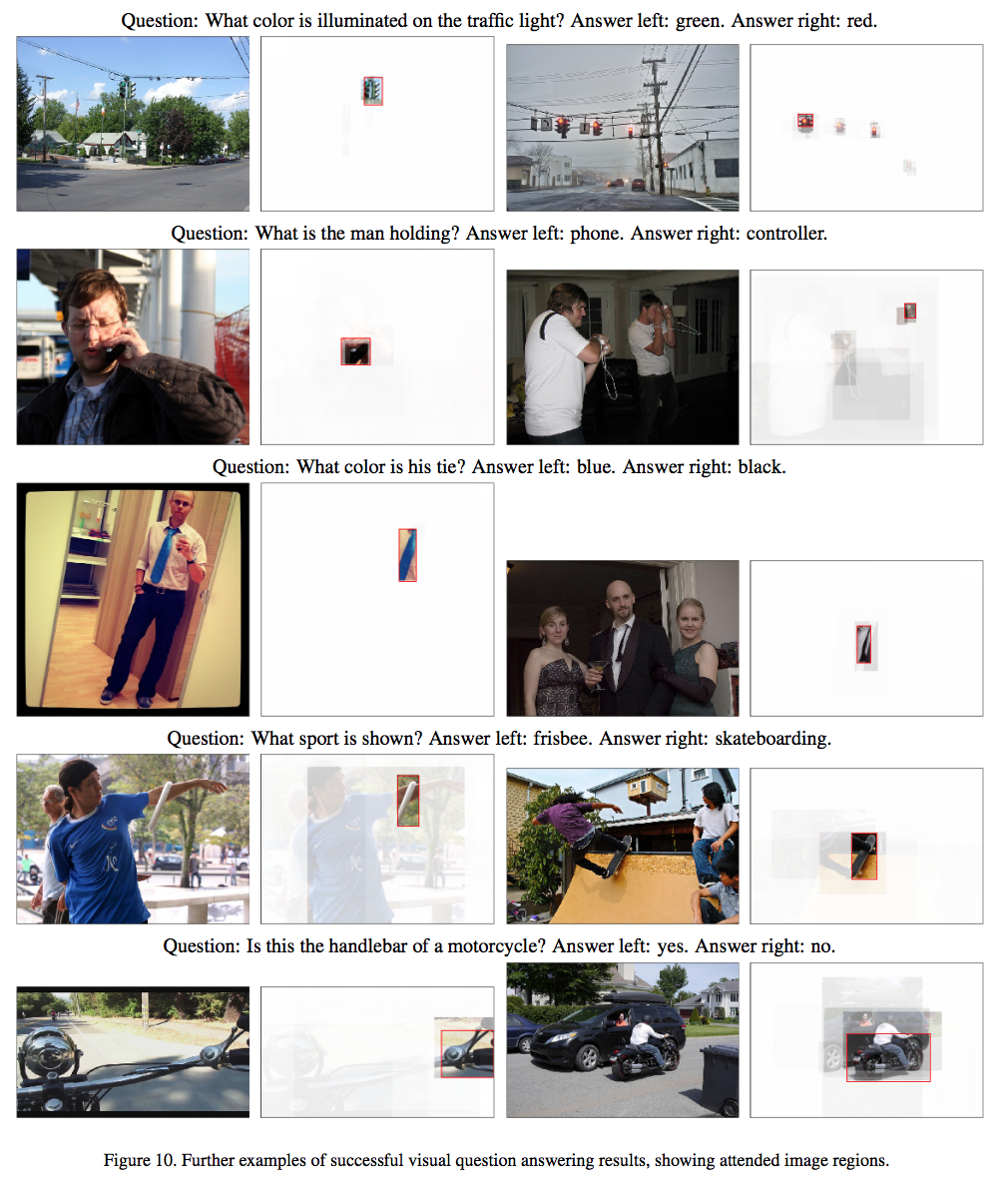
VQAの出力例

定性的評価
attentionの差
上がベースライン,下が提案手法.ベースラインではバスルームからトイレを連想して間違えているが,提案手法ではソファーを認識して正しいキャプションを生成している.

キャプション

VQA
成功例
失敗例.
